

linux内存源码分析 - 内存碎片整理(实现流程)
2016-03-23 11:06 tolimit 阅读(14239) 评论(8) 编辑 收藏 举报本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
概述
本文章最好结合linux内存管理源码分析 - 页框分配器与linux内存源码分析 -伙伴系统(初始化和申请页框)一起看,会涉及里面的一些知识。
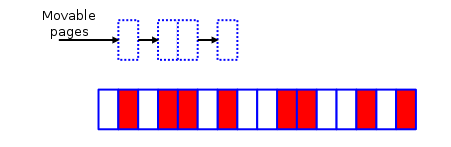
我们知道内存是以页框为单位,每个页框大小默认是4K(大页除外),而在系统运行时间长后就会出现内存碎片,内存碎片的意思就是一段空闲页框中,会有零散的一些正在使用的页框,导致此段页框被这些正在使用的零散页框分为一小段一小段连续页框,这样当需要大段连续页框时就没办法分配了,这些空闲页框就成了一些碎片,不能合并起来作为一段大的空闲页框使用,如下图:

白色的为空闲页框,而有斜线的为已经在使用的页框,在这个图中,空闲页框都是零散的,它们没办法组成一块连续的空闲页框,它们只能单个单个进行分配,当内核需要分配连续页框时则没办法从这里分配。为了解决这个问题,内核实现了内存碎片整理功能,其原理很简单,就是从这块内存区段的前面扫描可移动的页框,从内存区段后面向前扫描空闲的页框,两边扫描结束后,将可移动的页框放入到空闲页框中,最后最理想的结果就如下图:

这样移动之后就把前面的页框整理为了一大段连续的物理页框了,当然这只是理想情况,因为并不是所有页框都可以进行移动,像内核使用的页框大部分都不能够移动,而用户进程的页框大部分是可以移动了。
内存碎片整理
对于内存碎片整理来说,只会正对三种类型的页进行整理,分别是:MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE、MIGRATE_CMA。并且内存碎片整理是耗费一定的内存、CPU和IO的。
在内存碎片整理中,可以移动的页框有MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE与MIGRATE_CMA这三种类型的页框,而因为内存碎片整理分为同步和异步,在异步过程中,只会移动MIGRATE_MOVABLE和MIGRATE_CMA这两种类型的页框。因为这两种类型的页框处理,是不会涉及到IO操作的。而在同步过程中,这三种类型的页框都会进行移动,因为MIGRATE_RECLAIMABLE基本上都是文件页,在移动过程中,有可能要将脏页回写,会涉及到IO操作,也就是在同步过程中,是会涉及到IO操作的。
内存碎片整理模式
内存碎片整理分为三种模式,三种模式耗费的资源和对整个系统的压力不一样,如下:

enum migrate_mode { /* * 异步模式的意思是禁止阻塞,遇到阻塞和需要调度的时候直接返回,返回前会把隔离出来的页框放回去 * 在内存不足以分配连续页框时进行内存碎片整理,默认初始是异步模式,如果异步模式后还不能分配连续内存,则会转为轻同步模式(当明确表示不处理透明大页,或者当前进程是内核线程时,就会转为请同步模式) * 而kswapd内核线程中只使用异步模式,不会使用同步模式 * 所以异步不处理MIRGATE_RECLAIMABLE类型的页框,因为这部分页框很大可能导致回写然后阻塞,只处理MIGRATE_MOVABLE和MIGRATE_CMA类型中的页 * 即使匿名页加入到了swapcache,被标记为了脏页,这里也不会进行回写,只有匿名页被内存回收换出时,才会进行回写 * 异步模式不会增加推迟计数器阀值 */ MIGRATE_ASYNC, /* 在内存不足以分配连续页框并进行了异步内存碎片整理之后,有可能会进行轻同步模式,轻同步模式下处理MIRGATE_RECLAIMABLE、MIGRATE_MOVABLE和MIGRATE_CMA类型的页 * 此模式下允许进行大多数操作的阻塞,比如在磁盘设备繁忙时,锁繁忙时,但不会阻塞等待正在回写的页结束,对于正在回写的页直接跳过,也不会对脏页进行回写 * 轻同步模式会增加推迟计数器阀值 */ MIGRATE_SYNC_LIGHT, /* 同步模式意味着在轻同步基础上,可能会对隔离出来需要移动的脏文件页进行回写到磁盘的操作(只会对脏文件页进行回写,脏匿名页只做移动,不会被回写),并且当待处理的页正在回写时,会等待到回写结束 * 这种模式发生有三种情况: * 1.cma分配 * 2.通过alloc_contig_range()尝试分配一段指定了开始页框号和结束页框号的连续页框时 * 3.将1写入sysfs中的vm/compact_memory * 同步模式会增加推迟计数器阀值,并且在同步模式下,会设置好compact_control,让同步模式时忽略pageblock的PB_migrate_skip标记 */ MIGRATE_SYNC, };
- 异步模式:内存碎片整理最常用的模式,在此模式中不会进行阻塞(但是时间片到了可以进行主动调度),也就是此种模式不会对文件页进行处理,文件页用于映射文件数据使用,这种模式也是对整体系统压力较小的模式。
- 轻同步模式:当异步模式整理不了更多内存时,有两种情况下会使用轻同步模式再次整理内存:1.明确表示分配的不是透明大页的情况下;2.当前进程是内核线程的情况下。这个模式中允许大多数操作进行阻塞(比如隔离了太多页,需要阻塞等待一段时间)。这种模式会处理匿名页和文件页,但是不会对脏文件页执行回写操作,而当处理的页正在回写时,也不会等待其回写结束。
- 同步模式:所有操作都可以进行阻塞,并且会等待处理的页回写结束,并会对文件页、匿名页进行回写到磁盘,所以导致最耗费系统资源,对系统造成的压力最大。它会在三种情况下发生:1.从cma中分配内存时;2.调用alloc_contig_range()尝试分配一段指定了开始页框号和结束页框号的连续页框时;3.通过写入1到sysfs中的/vm/compact_memory文件手动实现同步内存碎片整理。
在内存不足以分配连续页框后导致内存碎片整理时,首先会进行异步的内存碎片整理,如果异步的内存碎片整理后还是不能够获取连续的页框(这种情况发生在很多离散的页的类型是MIGRATE_RECLAIMABLE),并且gfp_mask明确表示不处理透明大页的情况或者该进程是个内核线程时,则进行轻同步的内存碎片整理。
在kswapd中,永远只进行异步的内存碎片整理,不会进行同步的内存碎片整理,并且在kswapd中会跳过标记了PB_migrate_skip的pageblock。相反非kswapd中的内存碎片整理,当推迟次数超过了推迟阀值时,会将pageblock的PB_migrate_skip标记清除,也就是会扫描之前有PB_migrate_skip标记的pageblock。
在同步内存碎片整理时,会忽略所有标记了PB_migrate_skip的pageblock,强制对这段内存中所有pageblock进行扫描(当然除了MIGRATE_UNMOVEABLE的pageblock)。
异步是用得最多的,它整理的速度最快,因为它只处理MIGRATE_MOVABLE和MIGRATE_CMA两种类型,并且不处理脏页和阻塞的情况,遇到需要阻塞的情况就返回。而轻同步的情况是在异步无法有效的整理足够内存时使用,它会处理MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE、MIGRATE_CMA三种类型的页框,在一些阻塞情况也会等待阻塞完成(比如磁盘设备回写繁忙,待移动的页正在回写),但是它不会对脏文件页进行回写操作。同步整理的情况就是在轻同步的基础上会对脏文件页进行回写操作。
这里需要说明一下,非文件映射页也是有可能被当成脏页的,当它加入swapcache后会被标记为脏页,不过在内存碎片整理时,即使匿名页被标记为脏页也不会被回写,它只有在内存回收时才会对脏匿名页进行回写到swap分区。在脏匿名页进行回写到swap分区后,基本上此匿名页占用的页框也快被释放到伙伴系统中作为空闲页框了。
内存碎片整理算法
先说一下内存碎片整理的算法,首先,内存碎片整理是以zone为单位的,而zone中又以pageblock为单位。在内存碎片整理开始前,会在zone的头和尾各设置一个指针,头指针从头向尾扫描可移动的页,而尾指针从尾向头扫描空闲的页,当他们相遇时终止整理。下图就是简要的说明图:
初始时内存状态(默认所有正在使用的页框都为可移动):

从头扫描可移动页框:
从尾扫描空闲页框:

结果:

但是实际情况并不是与上面图示的情况完全一致。头指针每次扫描一个符合要求的pageblock里的所有页框,当pageblock不为MIGRATE_MOVABLE、MIGRATE_CMA、MIGRATE_RECLAIMABLE时会跳过这些pageblock,当扫描完这个pageblock后有可移动的页框时,会变为尾指针以pageblock为单位向前扫描可移动页框数量的空闲页框,但是在pageblock中也是从开始页框向结束页框进行扫描,最后会将前面的页框内容复制到这些空闲页框中。

需要注意,扫描可移动页框是要先判断pageblock的类型是否符合,符合的pageblock才在里面找可移动的页框,当扫描了一个符合的pageblock后本次扫描可移动页框会停止,转到扫描空闲页框。而扫描空闲页框时也会根据pageblock进行扫描,只是从最后一个pageblock向前扫描,而在每个pageblock里面,也是从此pageblock开始页框向pageblock结束页框进行扫描。当需要的空闲页框数量=扫描到的一个pageblock中可移动的页框数量时,则会停止。
内存碎片整理发生时机
现在再来说说什么时候会进行内存碎片整理。它会在四个地方调用到:
- 内核从伙伴系统以min阀值获取连续页框,但是连续页框又不足时。
- 当需要从指定地方获取连续页框,但是中间有页框正在使用时。
- 因为内存短缺导致kswapd被唤醒时,在进行内存回收之后会进行内存碎片整理。
- 将1写入sysfs中的/vm/compact_memory时,系统会对所有zone进行内存碎片整理。
而内存碎片整理是一个相当耗费资源的事情,它并不会经常会执行,即使因为内存短缺导致代码中经常调用到内存碎片整理函数,它也会根据调用次数选择性地忽略一些执行请求,见内存碎片整理推迟。
系统判定是否执行内存碎片整理的标准是
- 在分配页框过程中,zone显示是有足够的空闲页框供于本次分配的,但是伙伴系统链表中又没有连续页框段用于本次分配。原因就是过多分散的空闲页框,它们没办法组成一块连续页框存放在伙伴系统的链表中。
- 在kswapd唤醒后会对zone的页框阀值进行检查,如果可用页框少于高阀值则会进行内存回收,每次进行内存回收之后会进行内存碎片整理。
即使满足标准,也不一定会执行内存碎片整理,具体见后面的内存碎片整理推迟和compact_zone()函数。
内存碎片整理结束时机
在内存碎片整理中,一次zone的内存碎片整理结束条件有三条:
- 可移动页框扫描的位置是否已经超过了空闲页框扫描的位置,超过则结束整理,并且会重置zone->compact_cached_free_pfn和zone->compact_cached_migrate_pfn,并且不是kswap时,会设置zone->compact_blockskip_flush为真
- zone的空闲页框数量满足了 (zone的low阀值 + 1<<order + zone的保留页框) 条件。
- 判断伙伴系统中是否有比order值大的空闲连续页框块,有则结束整理,如果order为-1,则忽略此条件
不过有例外,通过写入到/proc/sys/vm/compact_memory进行强制内存碎片整理的情况,则判断条件只有第1条。对于zone来说,可移动页扫描和空闲页扫描交汇,也就是第一种情况时,才算是对zone进行了一次完整的内存碎片整理,这个完整的内存碎片整理并不代表一次内存碎片整理就能实现,也有可能是对zone进行多次内存碎片整理才达到的,因为每次内存碎片整理结束时机还有另外两种。当zone达到一次完整的内存碎片整理时,会重置两个扫描的起始为zone的第一个页和最后一个页,并且不是处于kswap中时,会设置zone->compact_blockskip_flush为真,这个zone->compact_blockskip_flush在kswapd准备睡眠时,会将zone的所有pageblock的PB_migrate_skip标志清除。
内存碎片整理推迟
内存碎片整理虽然是针对每个zone的,但是执行的时候传入的是一个zonelist,这样就会有一种情况,就是可能某个zone刚进行过内存碎片整理,而系统因为内存不足又进行了内存碎片整理,导致这个刚进行内存碎片整理的zone又要执行内存碎片整理,为了避免这种情况,内核会为每个zone做一个整理推迟计数,这个计数是每个zone都会有的,在struct zone里:
struct zone { ...... /* 这两个用于推迟内存碎片整理处理,只有当内存碎片整理时使用的order大于compact_order_failed才会推迟 * 只有一种情况会重置这两个值:在zone执行内存碎片整理后,从此zone中分配到了内存,会重置 */ /* 用于判断是否需要推迟,每次推迟会++,然后判断是否超过 1UL << compact_defer_shift,超过了则要进行内存碎片整理 */ unsigned int compact_considered; /* 用于定量推迟计数,主要用于内存碎片整理分为compact_considered < compact_defer_shift和compact_considered >= compact_defer_shift两种情况,当次管理区的内存碎片整理成功后被置0,不会大于COMPACT_MAX_DEFER_SHIFT * 只有在同步和轻同步模式下进行内存碎片整理后,zone的空闲页框数量没达到 (low阀值 + 1<<order + 保留内存) 时,才会增加此值 */ unsigned int compact_defer_shift; /* * 表示zone内存碎片整理失败时使用的最大order值,此值会影响是否推迟内存碎片整理 * 当进行内存碎片整理时,使用的order小于此值,则允许进行内存碎片整理,否则记一次推迟 * 当内存碎片整理完成时,此值为使用的order值+1,意思是假设大一级的order在整理中会失败 * 当内存碎片整理失败时,此值则是等于order值,表示使用此大小的order值,有可能会导致失败 */ int compact_order_failed; ...... }
- compact_considered:称为内存碎片整理推迟计数器,每次zone的内存碎片整理推迟了,此值会+1
- compact_defer_shift:称为内存碎片整理推迟阀值,内存碎片整理推迟计数器达到 1 << compact_defer_shift 后,就不能对zone进行内存碎片整理推迟了。
- compact_order_failed:称为内存碎片整理失败最大order值,记录着此zone进行内存碎片整理失败时使用的最大的order值
当一个zone要进行内存碎片整理时,首先会判断本次整理需不需要推迟,如果本次内存碎片整理使用的order值小于zone内存碎片整理失败最大order值时,不用进行推迟,可以直接进行内存碎片整理;但是当order值大于zone内存碎片整理失败最大order值时,会增加内存碎片整理推迟计数器,当内存碎片整理推迟计数器未达到内存碎片整理推迟阀值,则会跳过本次内存碎片整理,如果达到了,那就需要进行内存碎片整理。也就是当order小于zone内存碎片整理失败最大order值时,不用进行推迟,而order大于zone内存碎片整理失败最大order值时,才考虑是否进行推迟。
在对一个zone进行内存碎片整理时,结果一般分为三种:
- 整理结束后,zone的空闲页框数量达到了 (low阀值 + 1 << order + 保留的页框数量),这种情况就称为内存碎片整理半成功
- 整理结束后,顺利从zone中获取到链入1 << order个连续页框,这种情况称为内存碎片整理成功
- 整理结束后,zone的空闲页框数量没达到 (low阀值 + 1 << order + 保留的页框数量),这种情况称为内存碎片整理失败
当内存碎片整理实现半成功时,如果使用的order大于等于zone的内存碎片整理失败最大order值,则将内存碎片整理失败最大order值设置为本次内存碎片整理使用的order值+1。
当内存碎片整理实现成功时,重置内存碎片整理推迟计数器和内存碎片整理推迟阀值计数为0并且如果使用的order大于等于zone的内存碎片整理失败最大order值,则将内存碎片整理失败最大order值设置为本次内存碎片整理使用的order值+1。
当内存碎片整理失败时,在轻同步和同步模式下,会对内存碎片整理推迟阀值计数+1,因为计算内存碎片整理推迟量时,是使用1 << zone->compact_defer_shift计算的,所以这个+1,实际上是让原来的推迟量*2。
如上,代码中只有一个地方会让zone重置推迟计数器,就是在内存碎片整理完成后,从此zone中分配到2^order个连续页框,那么就会重置zone->compact_considered和zone->compact_defer_shift为0,但zone->compact_order_failed并不会被重置也永远不会被重置。
内存碎片整理扫描起始位置与pageblock的跳过
在系统初始化过程中,就会将zone的可移动页扫描起始位置设置为zone的第一个页框,而空闲页扫描起始位置设置为zone的最后一个页框,这两个数值保存在struct zone中的:
struct zone { ...... /* 以下两个参数保存的是内存碎片整理的两个扫描的起始位置 */ /* 空闲页框扫描起始位置,开始设置时是管理区的最后一个页框 * 在内存碎片整理扫描可以移动的页时,从本次内存碎片整理开始到此pageblock结束都没有隔离出可移动页时,会将此值设置为pageblock的最后一页 * 此值默认是zone的结束页框 */ unsigned long compact_cached_free_pfn; /* pfn where async and sync compaction migration scanner should start */ /* 0用于异步,1用于同步,用于保存管理区可移动页框扫描起始位置 * 在内存碎片整理扫描空闲页时,从本次内存碎片整理开始到此pageblock结束都没有隔离出空闲页时,会将此值设置为pageblock的最后一页 * 此值默认是zone的开始页框 */ unsigned long compact_cached_migrate_pfn[2]; ...... }
每次对zone进行内存碎片整理,都是使用这两个值初始化本次内存碎片整理的可移动页扫描起始位置和空闲页扫描起始位置。
对于保存可移动页扫描起始位置,同步和异步是分开保存到。这两个值在初始化时会被设置为zone的结束页框和开始页框,之后从内存碎片整理开始到pageblock结束时,都没有隔离出页的情况下,会被更新为pageblock结束页框。
之前说了,内存是以一个一个连续的pageblock组织起来的,当进行内存碎片整理时,一次扫描是以一个pageblock为单位,比如系统正在对zone进行内存碎片整理,首先,会从可移动页框开始位置向后扫描一个pageblock,得到一些可移动页框,然后空闲页框从开始位置向前扫描一个pageblock,得到一些空闲页框,然后将可移动页框移动到空闲页框中,之后再继续循环扫描。对一个pageblock进行扫描后,如果无法从此pageblock隔离出一个要求的页框,这时候就会将此pageblock标记为跳过,主要通过设置pageblock在zone的pageblock位图中的PB_migrate_skip标志实现的。而标记之后会有两种情况:
- 本次内存碎片整理在之前的pageblock已经隔离出了此种页框(可移动页/空闲页),这种情况就是设置pageblock的PB_migrate_skip标记。
- 本次内存碎片整理在之前的pageblock中没有隔离出过此种页框(可移动页/空闲页),说明之前的pageblock都被标记了跳过,这种情况不止设置pageblock的PB_migrate_skip标记,还会设置对于的内存碎片整理扫描起始位置。
对于第二种情况,以扫描可移动页为例子,本次内存碎片整理可移动页扫描是从zone的第一个页框开始,扫描完一个pageblock后,没有隔离出可移动页框,则标记此pageblock的跳过标记PB_migrate_skip,然后将zone->compact_cached_migrate_pfn设置为此pageblock的结束页框,这样,在下次对此zone进行内存碎片整理时,就会直接从此pageblock的下一个pageblock开始,把此pageblock跳过了。同理,对于空闲页扫描也是一样。如下图:
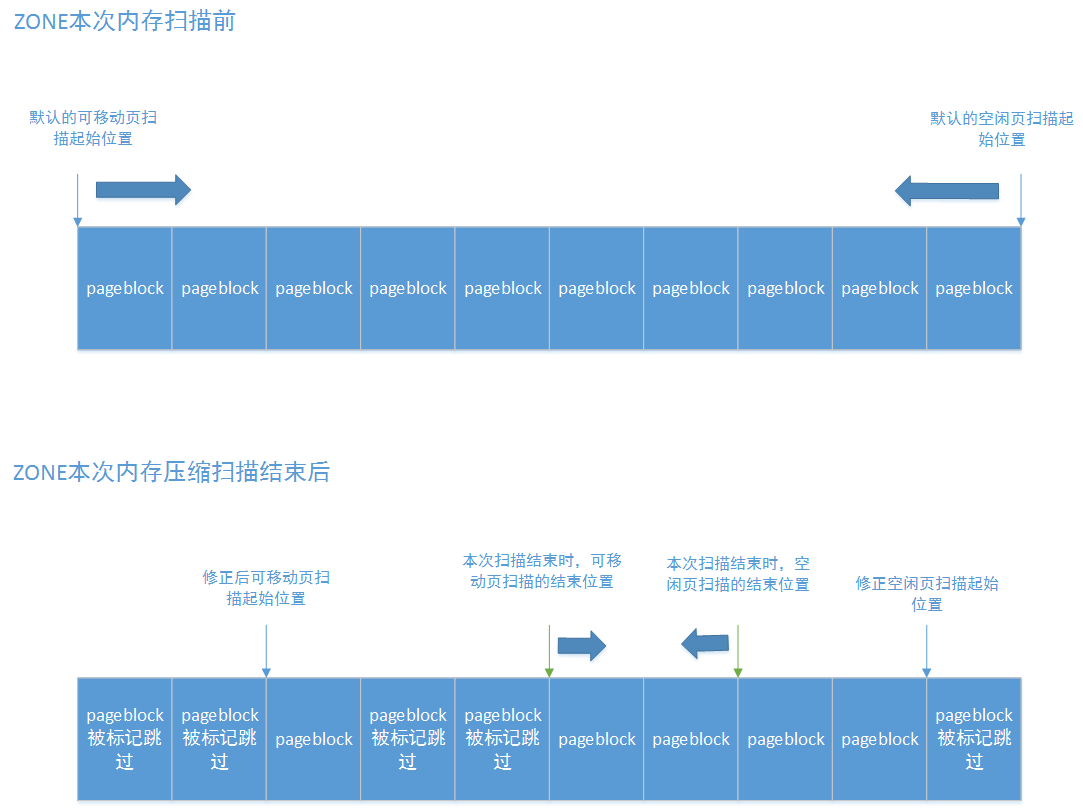
在贴着扫描起始位置的pageblock被连续标记为跳过时,就会将扫描起始位置设置到这段连续被标记为跳过的pageblock的最后一个一页,而当从pageblock隔离出需要页框时,pageblock就不会被标记为跳过,之后又有pageblock被标记跳过时,就不会修正扫描起始位置了,因为中间有pageblock隔离出了页框。本次整理结束后,如上图,修正了可移动页扫描起始位置和空闲页扫描起始位置,当下一次对此zone进行内存碎片整理时,则从这两个位置开始:

可以看到,再次对此zone进行内存碎片整理时,就会从修正后的扫描起始位置开始,并且扫描过程中会跳过被标记了跳过的pageblock。
如果一直这样,那不是那些被标记为跳过的pageblock在进行内存碎片整理时都会被跳过,然后一直不能够对它们进行扫描?实际上并不是,当进行同步内存碎片整理时,都会设置忽略pageblock的PB_migrate_skip标记,也就是会对跳过的pageblock进行扫描。但是仅仅只有在同步内存碎片整理时才对跳过的pageblock进行扫描也不行,毕竟同步内存碎片整理只是一些特殊情况下才会使用。所以,在一些情况下,内核会将zone的所有pageblock的PB_migrate_skip清除,也就是之后的内存碎片整理扫描,又会从最开始的状态开始进行,有以下两种情况会发生,如下:
- 在可移动页扫描和空闲页扫描碰头时,会设置zone->compact_blockskip_flush标志,此标志会导致kswapd准备睡眠时,对此zone的所有pageblock清除PB_migrate_skip
- 在非kswapd调用中,如果此zone的推迟次数达到最大值时(zone->compact_defer_shift == COMPACT_MAX_DEFER_SHIFT并且zone->compact_considered >= 1UL << zone->compact_defer_shift)导致的内存碎片整理,则清除zone所有pageblock的PB_migrate_skip
第一种情况,这个对zone的所有pageblock的PB_migrate_skip清除的工作是异步的,而第二种情况,则是同步的。
总结来说,就是zone完成了一次完整内存碎片整理(两个扫描相会)和此zone内存碎片整理推迟次数达到最大值这两种情况下,会清除zone所有pageblock的PB_migrate_skip。而清除时,都会将两个扫描起始位置重置为zone的开始页框和结束页框位置。
实现代码
先看看内存碎片整理控制结构struct compact_control,当需要进行内存碎片整理时,总是需要初始化一个这个结构:
struct compact_control { /* 扫描到的空闲页的页的链表 */ struct list_head freepages; /* List of free pages to migrate to */ /* 扫描到的可移动的页的链表 */ struct list_head migratepages; /* List of pages being migrated */ /* 空闲页链表中的页数量 */ unsigned long nr_freepages; /* Number of isolated free pages */ /* 可移动页链表中的页数量 */ unsigned long nr_migratepages; /* Number of pages to migrate */ /* 空闲页框扫描所在页框号 */ unsigned long free_pfn; /* isolate_freepages search base */ /* 可移动页框扫描所在页框号 */ unsigned long migrate_pfn; /* isolate_migratepages search base */ /* 内存碎片整理使用的模式: 同步,轻同步,异步 */ enum migrate_mode mode; /* Async or sync migration mode */ /* 是否忽略pageblock的PB_migrate_skip标志对需要跳过的pageblock进行扫描 ,并且也不会对pageblock设置跳过 * 只有两种情况会使用 * 1.调用alloc_contig_range()尝试分配一段指定了开始页框号和结束页框号的连续页框时; * 2.通过写入1到sysfs中的/vm/compact_memory文件手动实现同步内存碎片整理。 */ bool ignore_skip_hint; /* Scan blocks even if marked skip */ /* 本次内存碎片整理是否隔离到了空闲页框,会影响zone的空闲页扫描起始位置 */ bool finished_update_free; /* True when the zone cached pfns are * no longer being updated */ /* 本次内存碎片整理是否隔离到了可移动页框,会影响zone的可移动页扫描起始位置 */ bool finished_update_migrate; /* 申请内存时需要的页框的order值 */ int order; /* order a direct compactor needs */ const gfp_t gfp_mask; /* gfp mask of a direct compactor */ /* 扫描的管理区 */ struct zone *zone; /* 保存结果,比如异步模式下是否因为需要阻塞而结束了本次内存碎片整理 */ int contended; /* Signal need_sched() or lock * contention detected during * compaction */ };
结构体中每个成员变量的作用都在注释中写明了。
实际上无论唤醒kswapd执行内存碎片整理还是连续页框不足执行内存碎片整理,它们的入口都是alloc_pages()函数,因为kswapd不是间断性自动唤醒,而是在分配页框时页框不足的情况下被主动唤醒,在内存足够的情况下,kswapd是不会被唤醒的,而分配页框的函数入口就是alloc_pages(),会在此函数里面判断页框是否足够。所以从alloc_pages往下跟,可以看到内存碎片整理的代码主要函数是try_to_compact_pages(),在这个函数中,需要传入一个zonelist,然后对zonelist中的每个zone都进行内存碎片整理:
/* 尝试zonelist中的每个zone进行内存碎片整理 * order: 2的次方,如果是分配时调用到,这个就是分配时希望获取的order,如果是通过写入/proc/sys/vm/compact_memory文件进行强制内存碎片整理,order就是-1 */ unsigned long try_to_compact_pages(struct zonelist *zonelist, int order, gfp_t gfp_mask, nodemask_t *nodemask, enum migrate_mode mode, int *contended, struct zone **candidate_zone) { enum zone_type high_zoneidx = gfp_zone(gfp_mask); /* 表示能够使用文件系统的IO操作 */ int may_enter_fs = gfp_mask & __GFP_FS; /* 表示可以使用磁盘的IO操作 */ int may_perform_io = gfp_mask & __GFP_IO; struct zoneref *z; struct zone *zone; int rc = COMPACT_DEFERRED; int alloc_flags = 0; int all_zones_contended = COMPACT_CONTENDED_LOCK; /* init for &= op */ *contended = COMPACT_CONTENDED_NONE; /* Check if the GFP flags allow compaction */ /* 如果order = 0或者不允许使用文件系统IO和磁盘IO,则跳过本次整理,因为不使用IO有可能导致死锁 */ if (!order || !may_enter_fs || !may_perform_io) return COMPACT_SKIPPED; #ifdef CONFIG_CMA /* 在启动了CMA的情况下,如果标记了需要的内存为MIGRATE_MOVABLE,则添加一个ALLOC_CMA标志 */ if (gfpflags_to_migratetype(gfp_mask) == MIGRATE_MOVABLE) alloc_flags |= ALLOC_CMA; #endif /* Compact each zone in the list */ /* 遍历zonelist中的每一个zone */ for_each_zone_zonelist_nodemask(zone, z, zonelist, high_zoneidx, nodemask) { int status; int zone_contended; /* 检查管理区设置中是否需要跳过此次整理,当order < zone->compact_order_failed时是不需要跳过的 * 判断标准是: * zone->compact_considered是否小于1UL << zone->compact_defer_shift * 小于则推迟,并且zone->compact_considered++,也就是这个函数会主动去推迟此管理区的内存碎片整理 * 本次请求的order值小于之前失败时的order值,那这次整理必须要进行 * zone->compact_considered和zone->compact_defer_shift会只有在内存碎片整理完成后,从此zone获取到了连续的1 << order个页框的情况下会重置为0。 */ if (compaction_deferred(zone, order)) continue; /* 对遍历到的zone进行内存碎片整理 */ status = compact_zone_order(zone, order, gfp_mask, mode, &zone_contended); rc = max(status, rc); all_zones_contended &= zone_contended; /* If a normal allocation would succeed, stop compacting */ /* 判断整理后此zone 分配1 << order个页框后剩余的页框数量 是否 大于 此zone的低阀值 + 保留的页框数量 */ if (zone_watermark_ok(zone, order, low_wmark_pages(zone), 0, alloc_flags)) { *candidate_zone = zone; /* 当zone内存满足low阀值 + (1 << order) + 保留的内存 时,则将compact_order_failed设置为本次整理的order + 1 * 因为这里还不确定内存碎片整理是否成功了,只是此zone的剩余页框满足了要求 */ compaction_defer_reset(zone, order, false); /* 异步情况下需要被调度时会设置 */ if (zone_contended == COMPACT_CONTENDED_SCHED) *contended = COMPACT_CONTENDED_SCHED; /* 当zone中空闲内存达到 low阀值 + (1 << order) + 保留的内存 时,就不对下面的zone进行内存碎片整理了 */ goto break_loop; } /* 以下的代码就是zone本次内存碎片整理后,剩余页框数量还是没达到 zone的low阀值 + 本次需要分配的页框数量 + zone的保留页框数量 */ /* 如果是同步整理或者轻同步整理,则增加推迟计数器阀值zone->compact_defer_shift */ if (mode != MIGRATE_ASYNC) { /* 提高内存碎片整理计数器的阀值,zone的内存碎片整理计数器阀值 ,也就是只有同步整理会增加推迟计数器的阀值 * 重置zone->compact_considered = 0 * 如果zone->compact_defer_shift < COMPACT_MAX_DEFER_SHIFT,那么zone->compact_defer_shift++ * 如果order < zone->compact_order_failed,那么zone->compact_order_failed = order */ defer_compaction(zone, order); } if ((zone_contended == COMPACT_CONTENDED_SCHED) || fatal_signal_pending(current)) { *contended = COMPACT_CONTENDED_SCHED; goto break_loop; } continue; break_loop: all_zones_contended = 0; break; } if (rc > COMPACT_SKIPPED && all_zones_contended) *contended = COMPACT_CONTENDED_LOCK; return rc; }
在此函数中,遍历zonlist中的每个zone,对每个zone都进行内存碎片整理处理,在内存碎片整理处理中,第一件首要事情就是判断此zone的内存碎片整理是否需要推迟,不需要推迟可以进行内存碎片整理的两个情况是:
- 本次内存碎片整理使用的order值小于zone->compact_order_failed。
- 如果order值大于zone->compact_order_failed,那么对zone的内存碎片整理推迟计数器++,如果zone的内存碎片整理推迟计数器++后数值大于等于了(1 << zone的内存碎片整理最大推迟计数),那么也会对zone进行内存碎片整理。但是这种情况会清除zone所有pageblock的PB_migrate_skip标志和重置扫描起始位置。
在上述两种情况下,可以对此zone进行内存碎片整理,之后,compact_zone_order(),这个函数里主要初始化一个struct compact_control结构体,然后调用compact_zone():
static unsigned long compact_zone_order(struct zone *zone, int order, gfp_t gfp_mask, enum migrate_mode mode, int *contended) { unsigned long ret; struct compact_control cc = { /* 整理结束后空闲页框数量 */ .nr_freepages = 0, /* 整理结束后移动的页框数量 */ .nr_migratepages = 0, .order = order, /* 表示需要移动的页框类型,有movable和reclaimable两种,可以同时设置 */ .gfp_mask = gfp_mask, /* 管理区 */ .zone = zone, /* 同步或异步 */ .mode = mode, }; /* 初始化一个空闲页框链表头 */ INIT_LIST_HEAD(&cc.freepages); /* 初始化一个movable页框链表头 */ INIT_LIST_HEAD(&cc.migratepages); /* 进行内存碎片整理 */ ret = compact_zone(zone, &cc); VM_BUG_ON(!list_empty(&cc.freepages)); VM_BUG_ON(!list_empty(&cc.migratepages)); *contended = cc.contended; return ret; }
这里面又调用了compact_zone(),这个函数里首先会在此判断是否进行内存碎片整理,有三种情况:
- COMPACT_PARTICAL: 此zone内存足够用于分配要求的2^order个页框,不用进行内存碎片整理。
- COMPACT_SKIPPED: 此zone内存不足以进行内存碎片整理,判断条件是此zone的空闲页框数量少于 zone的低阀值 + (2 << order)。
- COMPACT_CONTINUE: 此zone可以进行内存碎片整理。
所以,对一个zone能否进行内存碎片整理有两个判断,一个是是否需要推迟的判断,一个是zone的内存页数量是否满足进行内存碎片整理。
判断完zone能否进行内存碎片整理后,还需要判断是否要重置所有pageblock的PB_migrate_skip和扫描起始位置,只有当不处于kswapd内存碎片整理时,并且zone的内存碎片整理推迟次数超过了最大值的情况下,才会重置。之后会初始化可移动页框扫描和空闲页框扫描的起始位置,这个位置就是使用zone->compact_cached_migrate_pfn和zone->compact_cached_free_pfn决定,需要注意同步和异步的可移动页扫描使用的是不同的位置。之后如上面所说,循环扫描pageblock,对每个pageblock进行可移动页的扫描和空闲页的扫描,将可移动页的数据和页描述符复制到空闲页中,最后就将已经完成移动的可移动页释放掉,如下:
/* 对zone进行内存碎片整理主要实现函数 */ static int compact_zone(struct zone *zone, struct compact_control *cc) { int ret; /* 管理区开始页框号 */ unsigned long start_pfn = zone->zone_start_pfn; /* 管理区结束页框号 */ unsigned long end_pfn = zone_end_pfn(zone); /* 获取可进行移动的页框类型(__GFP_RECLAIMABLE、__GFP_MOVABLE) */ const int migratetype = gfpflags_to_migratetype(cc->gfp_mask); /* 同步还是异步 * 同步为1,异步为0 * 轻同步和同步都是同步 */ const bool sync = cc->mode != MIGRATE_ASYNC; /* 根据传入的cc->order判断此次整理是否能够进行,主要是因为整理需要部分内存,这里面会判断内存是否足够 */ ret = compaction_suitable(zone, cc->order); switch (ret) { /* 内存足够用于分配,所以此次整理直接跳过 */ case COMPACT_PARTIAL: /* 内存数量不足以进行内存碎片整理 */ case COMPACT_SKIPPED: /* Compaction is likely to fail */ return ret; /* 可以进行内存碎片整理 */ case COMPACT_CONTINUE: /* Fall through to compaction */ ; } /* 如果不是在kswapd线程中并且此zone的内存碎片整理推迟次数超过了最大推迟次数 */ if (compaction_restarting(zone, cc->order) && !current_is_kswapd()) /* 只有不是在kswapd线程中并且此zone的内存碎片整理推迟次数超过了最大推迟次数的时候才会执行如下操作 * zone->compact_cached_migrate_pfn[sync/async]设置为此zone的起始页框,compact_cached_free_pfn设置为此zone的结束页框 * zone->compact_blockskip_flush = false * 将zone中所有pageblock的PB_migrate_skip清空 */ __reset_isolation_suitable(zone); /* 将可移动页框扫描起始页框号设为zone->compact_cached_migrate_pfn[sync/async] */ cc->migrate_pfn = zone->compact_cached_migrate_pfn[sync]; /* 空闲页框扫描起始页框号设置为zone->compact_cached_free_pfn */ cc->free_pfn = zone->compact_cached_free_pfn; /* 检查cc->free_pfn,如果空闲页框扫描起始页框不在zone的范围内,则将空闲页框扫描起始页框设置为zone的最后一个页框 * 并且也会将zone->compact_cached_free_pfn设置为zone的最后一个页框 */ if (cc->free_pfn < start_pfn || cc->free_pfn > end_pfn) { cc->free_pfn = end_pfn & ~(pageblock_nr_pages-1); zone->compact_cached_free_pfn = cc->free_pfn; } /* 同上,检查cc->migrate_pfn,如果可移动页框扫描起始页框不在zone的范围内,则将可移动页框扫描起始页框设置为zone的第一个页框 * 并且也会将zone->compact_cached_free_pfn设置为zone的第一个页框 */ if (cc->migrate_pfn < start_pfn || cc->migrate_pfn > end_pfn) { cc->migrate_pfn = start_pfn; zone->compact_cached_migrate_pfn[0] = cc->migrate_pfn; zone->compact_cached_migrate_pfn[1] = cc->migrate_pfn; } trace_mm_compaction_begin(start_pfn, cc->migrate_pfn, cc->free_pfn, end_pfn); /* 将处于pagevec中的页都放回原本所属的lru中,这一步很重要 */ migrate_prep_local(); /* 判断是否结束本次内存碎片整理 * 1.可移动页框扫描的位置是否已经超过了空闲页框扫描的位置,超过则结束整理,并且会重置zone->compact_cached_free_pfn和zone->compact_cached_migrate_pfn * 2.判断zone的空闲页框数量是否达到标准,如果没达到zone的low阀值标准则继续 * 3.判断伙伴系统中是否有比order值大的空闲连续页框块,有则结束整理 * 如果是管理员写入到/proc/sys/vm/compact_memory进行强制内存碎片整理的情况,则判断条件只有第1条 */ while ((ret = compact_finished(zone, cc, migratetype)) == COMPACT_CONTINUE) { int err; /* 将可移动页(MOVABLE和CMA和RECLAIMABLE)从zone->lru隔离出来,存到cc->migratepages这个链表,一个一个pageblock进行扫描,当一个pageblock扫描成功获取到可移动页后就返回 * 一次扫描最多32*1024个页框 */ /* 异步不处理RECLAIMABLE页 */ switch (isolate_migratepages(zone, cc)) { case ISOLATE_ABORT: /* 失败,把这些页放回到lru或者原来的地方 */ ret = COMPACT_PARTIAL; putback_movable_pages(&cc->migratepages); cc->nr_migratepages = 0; goto out; case ISOLATE_NONE: continue; case ISOLATE_SUCCESS: ; } /* 将隔离出来的页进行迁移,如果到这里,cc->migratepages中最多也只有一个pageblock的页框数量,并且这些页框都是可移动的 * 空闲页框会在compaction_alloc中获取 * 也就是把隔离出来的一个pageblock中可移动页进行移动 */ err = migrate_pages(&cc->migratepages, compaction_alloc, compaction_free, (unsigned long)cc, cc->mode, MR_COMPACTION); trace_mm_compaction_migratepages(cc->nr_migratepages, err, &cc->migratepages); /* All pages were either migrated or will be released */ /* 设置所有可移动页框为0 */ cc->nr_migratepages = 0; if (err) { /* 将剩余的可移动页框返回原来的位置 */ putback_movable_pages(&cc->migratepages); if (err == -ENOMEM && cc->free_pfn > cc->migrate_pfn) { ret = COMPACT_PARTIAL; goto out; } } } out: /* 将剩余的空闲页框放回伙伴系统 */ cc->nr_freepages -= release_freepages(&cc->freepages); VM_BUG_ON(cc->nr_freepages != 0); trace_mm_compaction_end(ret); return ret; }
隔离可移动页框
每次进行隔离可移动页框是以一个pageblock为单位,也就是从一个pageblock中将可以移动页进行隔离,最多也就只能隔离出一个pageblock中的所有页框,主要实现函数为isolate_migratepages():
/* 从cc->migrate_pfn(保存的是扫描可移动页框指针所在的页框号)开始到第一个获取到可移动页框的pageblock结束,获取可移动页框,并放入到cc->migratepages */ static isolate_migrate_t isolate_migratepages(struct zone *zone, struct compact_control *cc) { unsigned long low_pfn, end_pfn; struct page *page; /* 保存同步/异步方式,只有异步的情况下能进行移动页框ISOLATE_ASYNC_MIGRATE */ const isolate_mode_t isolate_mode = (cc->mode == MIGRATE_ASYNC ? ISOLATE_ASYNC_MIGRATE : 0); /* 扫描起始页框 */ low_pfn = cc->migrate_pfn; /* Only scan within a pageblock boundary */ /* 以pageblock大小对齐 */ end_pfn = ALIGN(low_pfn + 1, pageblock_nr_pages); for (; end_pfn <= cc->free_pfn; low_pfn = end_pfn, end_pfn += pageblock_nr_pages) { /* 由于需要扫描很多页框,所以这里做个检查,执行时间过长则睡眠,一般是32个1024页框休眠一下,异步的情况还需要判断运行进程是否需要被调度 */ if (!(low_pfn % (SWAP_CLUSTER_MAX * pageblock_nr_pages)) && compact_should_abort(cc)) break; /* 获取第一个页框,需要检查是否属于此zone */ page = pageblock_pfn_to_page(low_pfn, end_pfn, zone); if (!page) continue; /* If isolation recently failed, do not retry */ /* 获取页框的PB_migrate_skip标志,如果设置了则跳过这个1024个页框 */ if (!isolation_suitable(cc, page)) continue; /* 异步情况,如果不是MIGRATE_MOVABLE或MIGRATE_CMA类型则跳过这段页框块 */ /* 异步不处理RECLAIMABLE的页 */ if (cc->mode == MIGRATE_ASYNC && !migrate_async_suitable(get_pageblock_migratetype(page))) continue; /* Perform the isolation */ /* 执行完隔离,将low_pfn到end_pfn中正在使用的页框从zone->lru中取出来,返回的是可移动页扫描扫描到的页框号 * 而UNMOVABLE类型的页框是不会处于lru链表中的,所以所有不在lru链表中的页都会被跳过 * 返回的是扫描到的最后的页 */ low_pfn = isolate_migratepages_block(cc, low_pfn, end_pfn, isolate_mode); if (!low_pfn || cc->contended) return ISOLATE_ABORT; /* 跳出,说明这里如果成功只会扫描一个pageblock */ break; } /* 统计,里面会再次遍历cc中所有可移动的页,判断它们是RECLAIMABLE还是MOVABLE的页 */ acct_isolated(zone, cc); /* 可移动页扫描到的页框修正 */ cc->migrate_pfn = (end_pfn <= cc->free_pfn) ? low_pfn : cc->free_pfn; return cc->nr_migratepages ? ISOLATE_SUCCESS : ISOLATE_NONE; }
注意上面代码里循环最后的break,当获取到可移动页框时,就break跳出循环。之后主要看isolate_migratepages_block(),里面是针对一个pageblock的扫描:
/* 将一个pageblock中所有可以移动的页框隔离出来 */ static unsigned long isolate_migratepages_block(struct compact_control *cc, unsigned long low_pfn, unsigned long end_pfn, isolate_mode_t isolate_mode) { struct zone *zone = cc->zone; unsigned long nr_scanned = 0, nr_isolated = 0; /* 待移动的页框链表 */ struct list_head *migratelist = &cc->migratepages; struct lruvec *lruvec; unsigned long flags = 0; bool locked = false; struct page *page = NULL, *valid_page = NULL; /* 检查isolated是否小于LRU链表的(inactive + active) / 2,超过了则表示已经将许多页框隔离出来 */ while (unlikely(too_many_isolated(zone))) { /* async migration should just abort */ if (cc->mode == MIGRATE_ASYNC) return 0; /* 进行100ms的休眠,等待设备没那么繁忙 */ congestion_wait(BLK_RW_ASYNC, HZ/10); if (fatal_signal_pending(current)) return 0; } /* 如果是异步调用,并且当前进程需要调度的话,返回真 */ if (compact_should_abort(cc)) return 0; /* Time to isolate some pages for migration */ /* 遍历每一个页框 */ for (; low_pfn < end_pfn; low_pfn++) { /* 这里会释放掉zone->lru_lock这个锁 */ if (!(low_pfn % SWAP_CLUSTER_MAX) && compact_unlock_should_abort(&zone->lru_lock, flags, &locked, cc)) break; if (!pfn_valid_within(low_pfn)) continue; /* 扫描次数++ */ nr_scanned++; /* 根据页框号获取页描述符 */ page = pfn_to_page(low_pfn); /* 设置valid_page */ if (!valid_page) valid_page = page; /* 检查此页是否处于伙伴系统中,主要是通过page->_mapcount判断,如果在伙伴系统中,则跳过这块空闲内存 */ if (PageBuddy(page)) { /* 获取这个页开始的order次方个页框为伙伴系统的一块内存 */ unsigned long freepage_order = page_order_unsafe(page); if (freepage_order > 0 && freepage_order < MAX_ORDER) low_pfn += (1UL << freepage_order) - 1; continue; } /* 以下处理此页不在伙伴系统中的情况,表明此页是在使用的页*/ /* 如果页不处于lru中的处理,isolated的页是不处于lru中的,用于balloon的页也不处于lru中? * 可移动的页都会在LRU中,不在LRU中的页都会被跳过,这里就把UNMOVABLE进行跳过 */ if (!PageLRU(page)) { if (unlikely(balloon_page_movable(page))) { if (balloon_page_isolate(page)) { /* Successfully isolated */ goto isolate_success; } } continue; } /* 如果此页是透明大页的处理,也是跳过。透明大页是在系统活动时可以实时配置,不需要重启生效 */ if (PageTransHuge(page)) { if (!locked) low_pfn = ALIGN(low_pfn + 1, pageblock_nr_pages) - 1; else low_pfn += (1 << compound_order(page)) - 1; continue; } /* 如果是一个匿名页,并且被引用次数大于page->_mapcount,则跳过此页,注释说此页很有可能被锁定在内存中不允许换出,但不知道如何判断的 */ if (!page_mapping(page) && page_count(page) > page_mapcount(page)) continue; /* If we already hold the lock, we can skip some rechecking */ /* 检查是否有上锁,这个锁是zone->lru_lock */ if (!locked) { locked = compact_trylock_irqsave(&zone->lru_lock, &flags, cc); if (!locked) break; /* 没上锁的情况,需要检查是否处于LRU中 */ /* Recheck PageLRU and PageTransHuge under lock */ if (!PageLRU(page)) continue; /* 如果在lru中,检查是否是大页,做个对齐,防止low_pfn不是页首 */ if (PageTransHuge(page)) { low_pfn += (1 << compound_order(page)) - 1; continue; } } lruvec = mem_cgroup_page_lruvec(page, zone); /* Try isolate the page */ /* 将此页从lru中隔离出来 */ if (__isolate_lru_page(page, isolate_mode) != 0) continue; VM_BUG_ON_PAGE(PageTransCompound(page), page); /* Successfully isolated */ /* 如果在cgroup的lru缓冲区,则将此页从lru缓冲区中拿出来 */ del_page_from_lru_list(page, lruvec, page_lru(page)); isolate_success: /* 隔离成功,此页已不处于lru中 */ cc->finished_update_migrate = true; /* 将此页加入到本次整理需要移动页链表中 */ list_add(&page->lru, migratelist); /* 需要移动的页框数量++ */ cc->nr_migratepages++; /* 隔离数量++ */ nr_isolated++; /* Avoid isolating too much */ /* COMPACT_CLUSTER_MAX代表每次内存碎片整理所能移动的最大页框数量 */ if (cc->nr_migratepages == COMPACT_CLUSTER_MAX) { ++low_pfn; break; } }
if (unlikely(low_pfn > end_pfn)) low_pfn = end_pfn; /* 解锁 */ if (locked) spin_unlock_irqrestore(&zone->lru_lock, flags); /* 如果全部的页框块都扫描过了,并且没有隔离任何一个页,则标记最后这个页所在的pageblock为PB_migrate_skip,然后 * if (pfn > zone->compact_cached_migrate_pfn[0]) zone->compact_cached_migrate_pfn[0] = pfn; if (cc->mode != MIGRATE_ASYNC && pfn > zone->compact_cached_migrate_pfn[1]) zone->compact_cached_migrate_pfn[1] = pfn; * */ if (low_pfn == end_pfn) update_pageblock_skip(cc, valid_page, nr_isolated, true); trace_mm_compaction_isolate_migratepages(nr_scanned, nr_isolated); /* 统计 */ count_compact_events(COMPACTMIGRATE_SCANNED, nr_scanned); if (nr_isolated) count_compact_events(COMPACTISOLATED, nr_isolated); return low_pfn; }
到这里,已经完成了从一个pageblock获取可移动页框,并放入struct compact_control中的migratepages链表中。从之前的代码看,当调用isolate_migratepages()将一个pageblock的可移动页隔离出来之后,会调用到migrate_pages()进行可移动页框的移动,之后就是详细说明此函数。
可移动页框的移动
我们先看看migrate_pages()函数原型:
static inline int migrate_pages(struct list_head *l, new_page_t new, free_page_t free, unsigned long private, enum migrate_mode mode, int reason)
比较重要的两个参数是
- new_page_t new: 是一个函数指针,指向获取空闲页框的函数
- free_page_t free: 也是一个函数指针,指向释放空闲页框的函数
我们要先看看这两个指针指向的函数,这两个函数指针分别指向compaction_alloc()和compaction_free(),compaction_alloc()是我们主要分析的函数,如下:
static struct page *compaction_alloc(struct page *migratepage, unsigned long data, int **result) { /* 获取cc */ struct compact_control *cc = (struct compact_control *)data; struct page *freepage; /* * Isolate free pages if necessary, and if we are not aborting due to * contention. */ /* 如果cc中的空闲页框链表为空 */ if (list_empty(&cc->freepages)) { /* 并且cc->contended没有记录错误代码 */ if (!cc->contended) /* 从cc->free_pfn开始向前获取空闲页 */ isolate_freepages(cc); if (list_empty(&cc->freepages)) return NULL; } /* 从cc->freepages链表中拿出一个空闲page */ freepage = list_entry(cc->freepages.next, struct page, lru); list_del(&freepage->lru); cc->nr_freepages--; /* 返回空闲页框 */ return freepage; }
代码很简单,主要还是里面的isolate_freepages()函数,在这个函数中,会从cc->free_pfn开始向前扫描空闲页框,但是注意以pageblock向前扫描,但是在pageblock内部是从前向后扫描的,最后遇到cc->migrate_pfn后或者cc->nr_freepages >= cc->nr_migratepages的情况下会停止,如下:
/* 隔离出空闲页框 */ static void isolate_freepages(struct compact_control *cc) { struct zone *zone = cc->zone; struct page *page; unsigned long block_start_pfn; /* start of current pageblock */ unsigned long isolate_start_pfn; /* exact pfn we start at */ unsigned long block_end_pfn; /* end of current pageblock */ unsigned long low_pfn; /* lowest pfn scanner is able to scan */ int nr_freepages = cc->nr_freepages; struct list_head *freelist = &cc->freepages; /* 获取开始扫描页框所在的pageblock,并且设置为此pageblock的最后一个页框或者管理区最后一个页框 */ isolate_start_pfn = cc->free_pfn; block_start_pfn = cc->free_pfn & ~(pageblock_nr_pages-1); block_end_pfn = min(block_start_pfn + pageblock_nr_pages, zone_end_pfn(zone)); /* 按pageblock_nr_pages对齐,low_pfn保存的是可迁移页框扫描所在的页框号,但是这里有可能migrate_pfn == free_pfn */ low_pfn = ALIGN(cc->migrate_pfn + 1, pageblock_nr_pages); /* 开始扫描空闲页框,从管理区最后一个pageblock向migrate_pfn所在的pageblock扫描 * block_start_pfn是pageblock开始页框号 * block_end_pfn是pageblock结束页框号 */ /* 循环条件, * 扫描到low_pfn所在pageblokc或者其后一个pageblock,low_pfn是low_pfn保存的是可迁移页框扫描所在的页框号,并按照pageblock_nr_pages对齐。 * 并且cc中可移动的页框数量多于cc中空闲页框的数量。由于隔离可移动页是以一个一个pageblock为单位的,所以刚开始时更多是判断cc->nr_migratepages > nr_freepages来决定是否结束 * 当扫描到可移动页框扫描所在的pageblock后,则会停止 */ for (; block_start_pfn >= low_pfn && cc->nr_migratepages > nr_freepages; block_end_pfn = block_start_pfn, block_start_pfn -= pageblock_nr_pages, isolate_start_pfn = block_start_pfn) { unsigned long isolated; if (!(block_start_pfn % (SWAP_CLUSTER_MAX * pageblock_nr_pages)) && compact_should_abort(cc)) break; /* 检查block_start_pfn和block_end_pfn,如果没问题,返回block_start_pfn所指的页描述符,也就是pageblock第一页描述符 */ page = pageblock_pfn_to_page(block_start_pfn, block_end_pfn, zone); if (!page) continue; /* Check the block is suitable for migration */ /* 判断是否能够用于迁移页框 * 判断条件1: 如果处于伙伴系统中,它所代表的这段连续页框的order值必须小于pageblock的order值 * 判断条件2: 此pageblock必须为MIGRATE_MOVABLE或者MIGRATE_CMA类型,而为MIGRATE_RECLAIMABLE类型的pageblock则跳过 */ if (!suitable_migration_target(page)) continue; /* If isolation recently failed, do not retry */ /* 检查cc中是否标记了即使pageblock标记了跳过也对pageblock进行扫描,并且检查此pageblock是否被标记为跳过 */ if (!isolation_suitable(cc, page)) continue; /* Found a block suitable for isolating free pages from. */ /* 扫描从isolate_start_pfn到block_end_pfn的空闲页框,并把它们放入到freelist中,返回此pageblock中总共获得的空闲页框数量 * 第一轮扫描可能会跳过,应该第一次isolate_start_pfn是等于zone最后一个页框的 */ isolated = isolate_freepages_block(cc, &isolate_start_pfn, block_end_pfn, freelist, false); /* 统计freelist中空闲页框数量 */ nr_freepages += isolated; /* 下次循环开始的页框 */ cc->free_pfn = (isolate_start_pfn < block_end_pfn) ? isolate_start_pfn : block_start_pfn - pageblock_nr_pages; /* 设置cc->finished_update_free为true,即表明此次cc获取到了空闲页框链表 */ if (isolated) cc->finished_update_free = true; /* 检查contended,此用于表明是否需要终止 */ if (cc->contended) break; } /* split_free_page does not map the pages */ /* 设置页表项,设置为内核使用 */ map_pages(freelist); /* 保证free_pfn不超过migrate_pfn */ if (block_start_pfn < low_pfn) cc->free_pfn = cc->migrate_pfn; cc->nr_freepages = nr_freepages; }
对于单个pageblock里的操作,就在isolate_freepages_block()中:
/* 扫描从start_pfn到end_pfn的空闲页框,一般都是一个pageblock的开始页框ID和结束页框ID,并把它们放入到freelist中,返回此pageblock中总共获得的空闲页框数量 */ static unsigned long isolate_freepages_block(struct compact_control *cc, unsigned long *start_pfn, unsigned long end_pfn, struct list_head *freelist, bool strict) { int nr_scanned = 0, total_isolated = 0; struct page *cursor, *valid_page = NULL; unsigned long flags = 0; bool locked = false; unsigned long blockpfn = *start_pfn; cursor = pfn_to_page(blockpfn); /* Isolate free pages. */ /* 从pageblock的start向end进行扫描 */ for (; blockpfn < end_pfn; blockpfn++, cursor++) { int isolated, i; /* 当前页框 */ struct page *page = cursor; if (!(blockpfn % SWAP_CLUSTER_MAX) && compact_unlock_should_abort(&cc->zone->lock, flags, &locked, cc)) break; nr_scanned++; /* 检查此页框号是否正确 */ if (!pfn_valid_within(blockpfn)) goto isolate_fail; /* valid_page是开始扫描的页框 */ if (!valid_page) valid_page = page; /* 检查此页是否在伙伴系统中,不在说明是正在使用的页框,则跳过 */ if (!PageBuddy(page)) goto isolate_fail; /* 获取锁 */ if (!locked) { locked = compact_trylock_irqsave(&cc->zone->lock, &flags, cc); if (!locked) break; /* Recheck this is a buddy page under lock */ if (!PageBuddy(page)) goto isolate_fail; } /* Found a free page, break it into order-0 pages */ /* 将page开始的连续空闲页框拆分为连续的单个页框,返回数量,order值会在page的页描述符中,这里有可能会设置pageblock的类型 */ isolated = split_free_page(page); /* 更新总共隔离的空闲页框数量 */ total_isolated += isolated; /* 将isolated数量个单个页框放入freelist中 */ for (i = 0; i < isolated; i++) { list_add(&page->lru, freelist); page++; } /* If a page was split, advance to the end of it */ /* 跳过这段连续空闲页框,因为上面把这段空闲页框全部加入到了freelist中 */ if (isolated) { blockpfn += isolated - 1; cursor += isolated - 1; continue; } isolate_fail: if (strict) break; else continue; } /* Record how far we have got within the block */ *start_pfn = blockpfn; trace_mm_compaction_isolate_freepages(nr_scanned, total_isolated); if (strict && blockpfn < end_pfn) total_isolated = 0; /* 如果占有锁则释放掉 */ if (locked) spin_unlock_irqrestore(&cc->zone->lock, flags); /* Update the pageblock-skip if the whole pageblock was scanned */ /* 扫描完了此pageblock,如果此pageblock中没有隔离出空闲页框,则标记此pageblock为跳过 */ if (blockpfn == end_pfn) update_pageblock_skip(cc, valid_page, total_isolated, false); /* 统计 */ count_compact_events(COMPACTFREE_SCANNED, nr_scanned); if (total_isolated) count_compact_events(COMPACTISOLATED, total_isolated); /* 返回总共获得的空闲页框 */ return total_isolated; }
这里结束就是从一个pageblock中获取到了空闲页框,最后会返回在此pageblock中总共获得的空闲页框数量。这里看完了compaction_alloc()中的调用过程,再看看compaction_free()的调用过程,这个函数主要用于当从compaction_alloc()获取一个空闲页框用于移动时,但是因为某些原因失败,就要把这个空闲页框重新放回cc->freepages链表中,实现也很简单:
/* 将page释放回到cc中 */ static void compaction_free(struct page *page, unsigned long data) { struct compact_control *cc = (struct compact_control *)data; list_add(&page->lru, &cc->freepages); cc->nr_freepages++; }
看完了compaction_alloc()和compaction_free(),现在看最主要的函数migrate_pages()此函数就是用于将隔离出来的可移动页框进行移动到空闲页框中,在里面每进行一个页框的处理前,都会先判断当前进程是否需要调度,然后再进行处理:
/* 将from中的页移到新页上,新页会在get_new_page中获取 * from = &cc->migratepages * get_new_page = compaction_alloc * put_new_page = compaction_free * private = (unsigned long)cc * mode = cc->mode * reson = MR_COMPACTION */ int migrate_pages(struct list_head *from, new_page_t get_new_page, free_page_t put_new_page, unsigned long private, enum migrate_mode mode, int reason) { int retry = 1; int nr_failed = 0; int nr_succeeded = 0; int pass = 0; struct page *page; struct page *page2; /* 获取当前进程是否允许将页写到swap */ int swapwrite = current->flags & PF_SWAPWRITE; int rc; /* 如果当前进程不支持将页写到swap,要强制其支持 */ if (!swapwrite) current->flags |= PF_SWAPWRITE; for(pass = 0; pass < 10 && retry; pass++) { retry = 0; /* page是主要遍历的页,page2是page在from中的下一个页 */ list_for_each_entry_safe(page, page2, from, lru) { /* 如果进程需要调度,则调度 */ cond_resched(); if (PageHuge(page)) /* 大页处理 * 这里看得不太懂,不知道怎么保证从from中拿出来的页就一定是大页 */ rc = unmap_and_move_huge_page(get_new_page, put_new_page, private, page, pass > 2, mode); else /* 此页为非大页处理 */ rc = unmap_and_move(get_new_page, put_new_page, private, page, pass > 2, mode); /* 返回值处理 */ switch(rc) { case -ENOMEM: goto out; case -EAGAIN: /* 重试 */ retry++; break; case MIGRATEPAGE_SUCCESS: /* 成功 */ nr_succeeded++; break; default: /* * Permanent failure (-EBUSY, -ENOSYS, etc.): * unlike -EAGAIN case, the failed page is * removed from migration page list and not * retried in the next outer loop. */ nr_failed++; break; } } } rc = nr_failed + retry; out: /* 统计 */ if (nr_succeeded) count_vm_events(PGMIGRATE_SUCCESS, nr_succeeded); if (nr_failed) count_vm_events(PGMIGRATE_FAIL, nr_failed); trace_mm_migrate_pages(nr_succeeded, nr_failed, mode, reason); /* 恢复PF_SWAPWRITE标记 */ if (!swapwrite) current->flags &= ~PF_SWAPWRITE; return rc; }
大页的情况下有些我暂时还没看懂,这里就先分析常规页的情况,常规页的情况的处理主要是umap_and_move()函数,具体看函数实现吧,如下:
/* 从get_new_page中获取一个新页,然后将page取消映射,并把page的数据复制到新页上 */ static int unmap_and_move(new_page_t get_new_page, free_page_t put_new_page, unsigned long private, struct page *page, int force, enum migrate_mode mode) { int rc = 0; int *result = NULL; /* 获取一个空闲页,具体见compaction_alloc() */ struct page *newpage = get_new_page(page, private, &result); if (!newpage) return -ENOMEM; /* 如果页的page_count == 1,说明此页必定是非文件页而且没有进程映射了此页,此页可以直接释放掉 */ if (page_count(page) == 1) { /* page was freed from under us. So we are done. */ goto out; } /* 此页是透明大页则跳过 */ if (unlikely(PageTransHuge(page))) if (unlikely(split_huge_page(page))) goto out; /* 将page取消映射,并把page的数据复制到newpage中 */ rc = __unmap_and_move(page, newpage, force, mode); out: if (rc != -EAGAIN) { /* 迁移成功,将旧的page放回到LRU链表中,为什么放入lru链表,因为旧的page已经是一个空闲的page了 */ list_del(&page->lru); dec_zone_page_state(page, NR_ISOLATED_ANON + page_is_file_cache(page)); /* 在这里会把新页放回到原来的地方 */ putback_lru_page(page); } /* 迁移不成功 */ if (rc != MIGRATEPAGE_SUCCESS && put_new_page) { ClearPageSwapBacked(newpage); /* 将新页放回到cc的空闲页链表中,具体见compaction_free() */ put_new_page(newpage, private); } else if (unlikely(__is_movable_balloon_page(newpage))) { /* drop our reference, page already in the balloon */ /* 如果新页是属于balloon使用的页,则放回到相应地方 */ put_page(newpage); } else /* 在这里会把新页放回到原来的地方 */ putback_lru_page(newpage); if (result) { if (rc) *result = rc; else *result = page_to_nid(newpage); } return rc; }
这里面,调用传入的compaction_alloc()函数获取扫描到的空闲页框中的一个页框,之后最重要的就是会调用__unmap_and_move()函数进行将page的页描述符数据和页内数据移动到new_page上,调用结束,如果迁移成功了,则会将旧页释放到伙伴系统中的每CPU页高速缓存中。
对于_umap_and_move()函数的分析,可以见linux内存源码分析 - 内存碎片整理(同步关系),。
触发内存页迁移
注意区分内存页迁移和内存碎片整理,内存页迁移是将内存页数据copy到另一个内存页的方法(同时保证内存页属性不变,映射到此内存页的进程也会映射到新的内存页),内存页迁移是可以跨zone和node的。
而内存碎片整理是使用的内存页迁移的方式进行的,它只会在当前zone中执行。
在内核中,以下行为会触发内存页面迁移
- CMA:CMA(Contiguous Memory Allocator)内存区域是kernel用于预留给设备做dma使用的,因为有一些设备在做DMA时,必须需要连续足够长的物理内存,所以kernel支持在启动阶段设置CMA区域的长度。但是系统会在CMA区域的内存在没有被设备使用时,将其当做MIGRATE_MOVEABLE分配出去(也必须保证一定是MOVEABLE的),当内核模块调用dma_alloc_coherent()需要更多的CMA内存时,就会对已经分配出去的page做内存迁移操作,将这段物理内存释放回CMA区域。
- /proc/sys/vm/compact_memory:这个文件允许用户主动去做内存碎片整理的,可以通过echo 1主动让kernel进行内存碎片整理。
- alloc_page:就是当连续内存不足时,就会触发内存迁移。
- 设置transparent hugepage可用数量:transparent hugepage中文是透明大页,意思是用户不需要显式地告诉kernel,程序需要使用大页,而是程序能够自己向kernel申请到大页。mmap()+MAP_HUGEPAGE这个flag。不过前提是用户需要提前先设置好系统中可供使用的大页数量,echo <nums> > /sys/kernel/mm/hugepages/hugepages-<size>/nr_hugepages。在用户这样设置的过程中,就会可能进行页迁移。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南