
《Dynamic Topic Detection and Tracking: A Comparison of HDP, C-Word, and Cocitation Methods》笔记
原文地址:http://onlinelibrary.wiley.com/doi/10.1002/asi.23134/abstract
黄色背景是我认为比较重要的,红色字体是我自己的话。
动态主题监测与跟踪:HDP、共词与共引分析方法的比较
Introduction
主题监测与跟踪在文献计量学、数据挖掘以及其他多个领域中都发挥重要作用。主题监测旨在从文档集合中识别重要主题,而主题跟踪旨在对一个已经识别到的主题演化过程进行跟踪。识别主题及其内在模式对于理解主题来说至关重要。
共引分析和共词分析是文献计量学中广泛使用的传统方法。共引分析可以揭示文档间的语义关系,可以用于监测文档集合中具体的主题。但是也有局限性,例如共引分析将学术交流严格限制在特定的类型(引文),并且相对于成熟的科研领域来说,对新兴的领域揭示效果不明显。
共词分析(1983年提出)可以直接研究文档的内容,在揭示科技文献的寓意关系方面已经成为一个强大的工具,并且至今仍然被广泛应用。但是共词分析也存在局限,例如由于该方法主要依赖于词的外在形式,缺少对同义词及有歧义词的有效处理机制,因此考虑到后期的聚类分析,共词分析方法并非一个理想的工具。
随着概率统计方法的快速发展,生成概率模型(generative probabilistic models)引起了研究者的兴趣。自从David Blei提出LDA模型以来,许多研究者都将LDA模型用于了主题监测和跟踪领域。许多研究已经表明LDA在发现领域中的主题与学科有很好的效果。但是LDA要求研究人员预先指定类的数目,如果用户对所分析数据没有很好的理解,确定类数是很困难的。尤其在动态的主题分析情况下,该问题变得更加突出,随着时间的发展,新主题可能出现,已有的主题可能消亡,主题个数也在随之变化,因此对于用户来说一开始就要指定类数变得异常困难。为了解决该问题,研究人员提出了下面三种方法:
- 尝试不同的主题个数,选择精确度最佳的一个。(不知道如何确定精度最佳?)
- 开始时设置一个非常大的类数,然后将相似的主题聚合到一起作为最佳结果。(凝聚的层次聚类?)
- 对生成概率模型自身进行优化,使用非参数方法自动生成主题个数。
在第三种方法中,HDP(2006)是最常用的方法。
尽管可以不断重复LDA方法,不断检查精度,最终得到最优值,但是在实际应用中,不断进行重复实验存在很多限制,而且LDA本身不提供这种这种实验方法。
第二种方法严重依赖所使用的聚类方法,并且已经证明该方法不优于LDA方法。因此,在这篇文章中,陈先生选择了第三种方法HDP方法,对文档集合进行主题监测和跟踪。
从理论上来说,HDP相对于共词分析和共引分析有很多优势。
- HDP基于具体的内部信息而非外部信息(参考文献)来发现主题,相对于共引分析来说,HDP可以更直接的从文本中识别主题,和共引分析中主题范围较多相比,HDP可以更加聚焦到特定的主题。
- HDP通过Dirichlet prior将词映射到语义空间,在一定程度上缓解了共词分析中的同义词问题。
陈教授说以前没有研究通过实验来证明HDP在实践中的这些优点,所以写了这篇文章来进行比较。他还说这是首次将生成概率模型与传统的方法进行比较。(不知道是不是真的,不过我确实没看到过)
Related Work
共引分析和供词分析是两个主题监测与跟踪的经典方法,共引分析通过引文关系构建引用和被引用文档之间的网络,当然,构建网络之后,还需要使用聚类方法识别网络中大量的类,每一个类相当于一个潜在的主题。共词分析不同于共引分析,基于词的共现频次构建矩阵,然后应用矩阵分解方法将矩阵分解成大量子矩阵,每一个子矩阵表示一个主题(这个方法我以前理解错了,我还以为是通过词聚类来实现的,原来是通过聚类分解实现的,需要好好研究一下)。这两种方法都已经在地球上应用了几十年了(可见这个学科发展的多么的慢!!),虽然很好用,也很有效,但是也有一些问题。
最近,LDA方法也被用于到文献计量学中进行主题监测,但是LDA的一些缺点也限制了它的使用。
- 第一个缺点是LDA要求预先输入类数。(前面已经讨论过)
- 第二个缺点:LDA趋向于将主题均匀分布,但是现实中,均匀分布并不常见。
HDP方法是一个非参数的贝叶斯模型(1973年),可以自动确定主题个数;同时,HDP根据帕累托法则(二八定律)对主题进行分布,如图1b所示,从1b中可以看到有两个主要的主题,同时有很多次要主题。因此,HDP相对于LDA更适用于主题监测和跟踪。

图1
HDP是基于Dirichlet process(DP)的概率模型,关于DP的解释有很多种,在这篇文章中陈老师将DP作为一个Chinese restaurant process(CRP)(中国餐馆模型?Blei在2007年提出),在CRP中,将一篇文档看做一个餐馆,将文档中的每个词作为一个顾客,餐馆中的顾客会一个接一个的到来,每个人都会选择一个桌子坐下,每个桌子都代表一个主题。DP的具体执行过程如下:
- 第一个顾客总是选择第一个桌子坐下。
- 第n个顾客选择一个空桌子(没有人坐)的概率是α/(n-1+α),选择一个已经有人坐的桌子的概率是c/(n-1+α),c是已经进入到餐馆并坐下来的人数,α是控制餐桌分配的参数。(n到底是什么,是第当前顾客的顺序数还是总人数?)
如果我们认为文档中的词是一个接一个、有顺序的到来,那么就可以根据Θ1,Θ2...Θn,构建第n个词的连续条件分布Θn,Θn的计算公式如下(词分布):

其中,cl 是已经有桌子的顾客数,δl是改桌子所属主题的词的分布,G是为新桌子生成主题的概率。
为新桌子生成一个主题时,有两种选择,(1)从已有的主题中选择一个主题,(2)生成一个全新的主题。因此需要一个分布来控制这种主题分配,在上面的公式1中,作者在桌子分布上面又加入了另一个分布,(主题分布),如公式2所示:

其中,m表示已经分配到主题的桌子的个数,mk表示分配到主题k的桌子的个数,δk表示该主题上的词的分布。H是基准分布,用来生成新的主题。
上面是关于DP的说明,几个公式不是很理解,需要看其他资料,再补充详细知识。
HDP是两层的DP模型,HDP的图模型如图2所示,其中H和γ控制主题分布G0,作为全局变量被整个文档集合共享使用。对于每个文档j,局部分布Gj从G0获取,控制已存在的主题中的词分布。
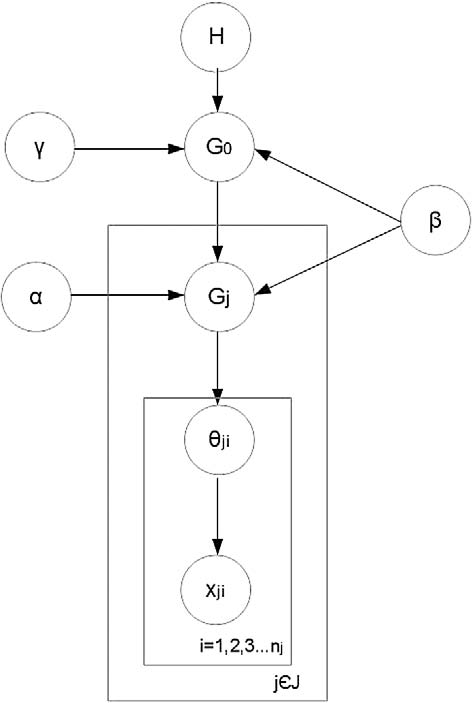
图2
通过控制参数α、β、γ,可以得到不同的分布,包括词-主题分布,词-桌分布,桌-主题分布,已经文档-主题分布等。基于这些分布,我们可以将HDP生成的结果与共词和共引方法的结果进行比较。
(这个方法的原理及公式还是不大理解)
Data and Method
数据收集
针对上述研究目标,数据集应该包含引文内容用于引文分析,应该包含文本的各个部分用于共词分析及主题建模。陈老师应用了之前经常应用的恐怖主义的研究数据集。检索方法如下,从Web of Science(WoS)用主题检索,检索词为“terrorism”,时间选择“1995-2012”,结果为9033条。
作者这样选择是可以包含Oklahoma City bombing事件及911等其他重大恐怖事件,数据集虽然不是非常标准,但是任何人可以随时使用检索式从数据库中获取。
陈老师分析了文档中的3类字段信息,包括标题、关键词和摘要。由于摘要中包含太多噪音,影响生成结果的可解释性,所以没有使用摘要字段(其实摘要中还有很多有用信息,如何过滤掉摘要中的常用词、通用词、无意义词是一个值得研究的问题,博主在《基于生命周期的热点发现方法》中有讨论,而且还涉及到词表构建等问题,这一块是一个重要的研究点,很有研究意义),在关键词的选择上,9033篇文档中共有4978个文档含有关键词,由于一些文档中关键词缺失,因此不能全面描述整个文档集合,最终陈老师直选择了标题作为分析对象。(选择的有点少,其实是怕数据不均匀的问题,如果对前面的摘要进行很好的解决,这一点不难)。
工具与方法
共引分析和共词分析使用CiteSpace,HDP分析自己编程解决。传统的HDP方法都使用一个词作为一个分析单元,老陈使用名词短语(这个名词短语是怎么得到的?)作为分析单元。名词短语的优点是相对于单个的词可以提供更具体的信息。例如,posttraumatic-stress-disorder(创伤后应激障碍)表示由创伤造成的心理状态的一个完整概念,如果将其拆分成单个的词,词间的关系及潜在的概念将会表示不明确。除此之外,作者预先对所有的标题进行了POS-tagged(词性标注),并为HDP方法保留了所有的短语。
如图2所示,HDP的效果随着三个参数α、β、γ的不同组合而不同,因此需要找到产生最优的HDP效果的参数设置。对此设置了两个HDP效果的指标:结果的perplexity(复杂度,混乱度,可解释度?)和主题个数。
perplexity基于熵理论来定义,测度概率模型的质量,perplexity的值越小,结果就越好。Perplexity的计算公式如下:
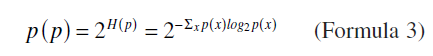
在HDP中主题的个数是自动生成的,共词和共引分析方法中,主题个数选择方法如下:根据CiteSpace的生成结果,共词分析和共引分析方法对每年的数据都平均生成10-20个类。为了确保结果的可比性,因此选择HDP主题结果个数在10-20范围内的α、β、γ的参数设置,如果有多个,则选择主题个数最少的那个参数设置作为最优的。
根据上面的两个指标,设置了HDP的结果测度函数,见公式4,选择生成S值最低的参数设置作为HDP的最佳参数设置。
(两种设置方法,到底是哪个?)
然后比较三种方法在主题监测和主题跟踪两个任务上的执行情况,对于不同的的任务,使用不同的比较和可视化方法。
主题监测方法
在主题监测中,如果一个方法可以找到其他方法找到的最多的主题,这个方法就被认为是强大的,其强度通过“coverage”(覆盖范围)来测度,见公式5。覆盖范围的得分越高,该方法在主题监测中就越强大。
陈老师在这篇文章中也引入了与单独方法有关的重要主题概念。一个主题的重要性是该主题在所有通过该方法识别到的主题中所占的比例(具体怎么计算,文档个数?)。另外,在每年的时间片中高比例的主题相对于低比例的主题更值得我们关注。coverage测度方法不仅可以应用在整个主题集合上,也可以用于重要的主题集合中,从而可以判断HDP是否在这两种类型的coverage中效果都较好。

TA表示被A方法识别到的主题,TB表示被B方法识别到的主题。TA交TB表示被A方法和B方法都识别到的相似的主题。两个主题间的相似性根据二者词的重叠度来计算,在标准化之后,该论文只保留了相似性大于0.2的主题作为相似主题。
然后通过层次连接线束(Hierarchical Edge Bundles,2006年提出)图来表示由三种方法监测到的主题间的关系。如果两个主题相似,在图中他们之间将会有一个连线,否则则无。另外,为了更加清晰的可视化,陈老师将连接系数设置为0.85。层次连接线束见图3。
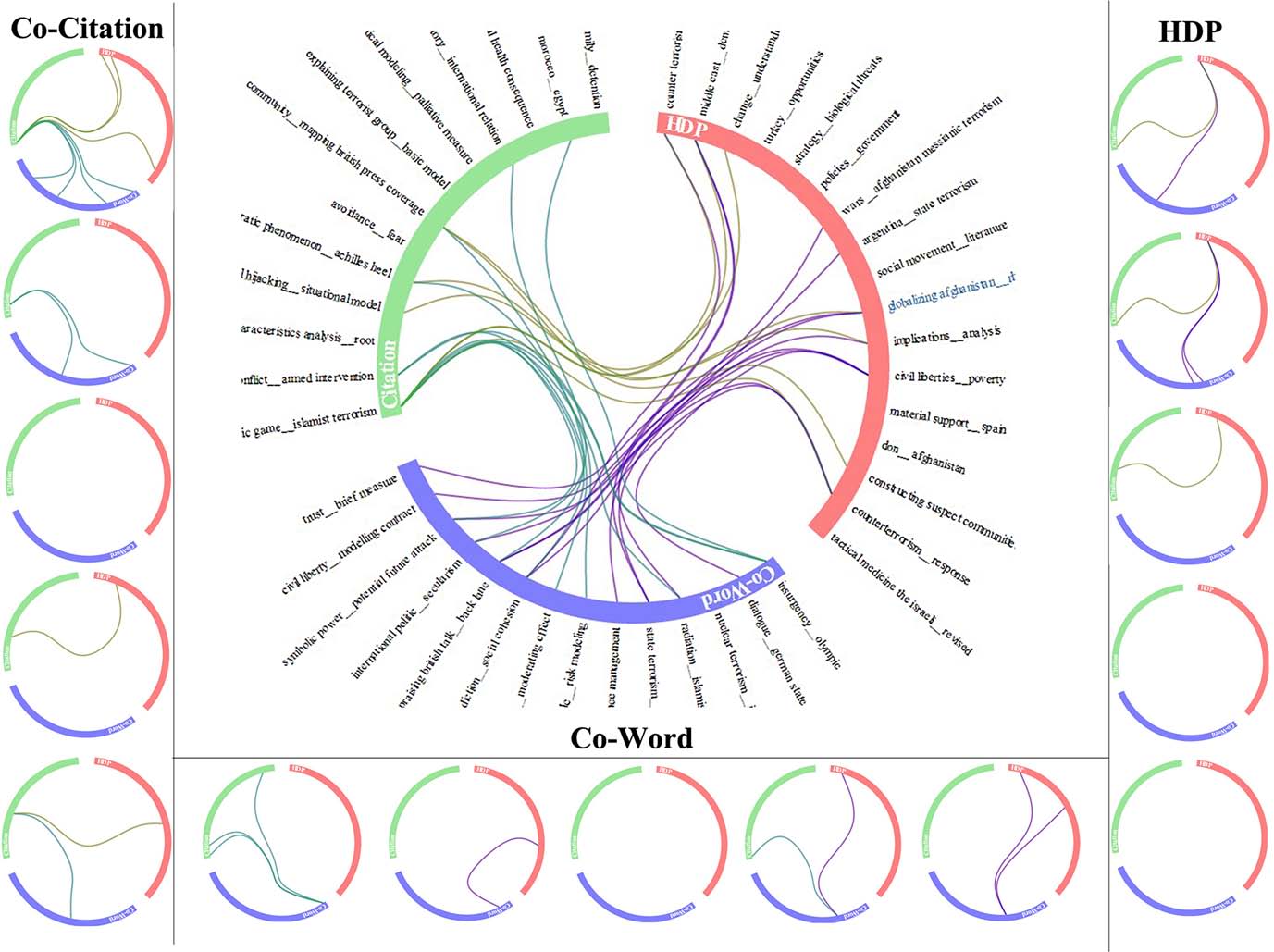
图3 被3种方法识别到的主题间的关系
图3的可视化揭示了三类模式。三种方法都能监测到的主题称为significant(显著的),可以被两种方法监测到的主题称为ordinary(普通的),仅仅能被一种方法监测到的主题称为exclusive(独有的),图4是三种模式的主题示意。
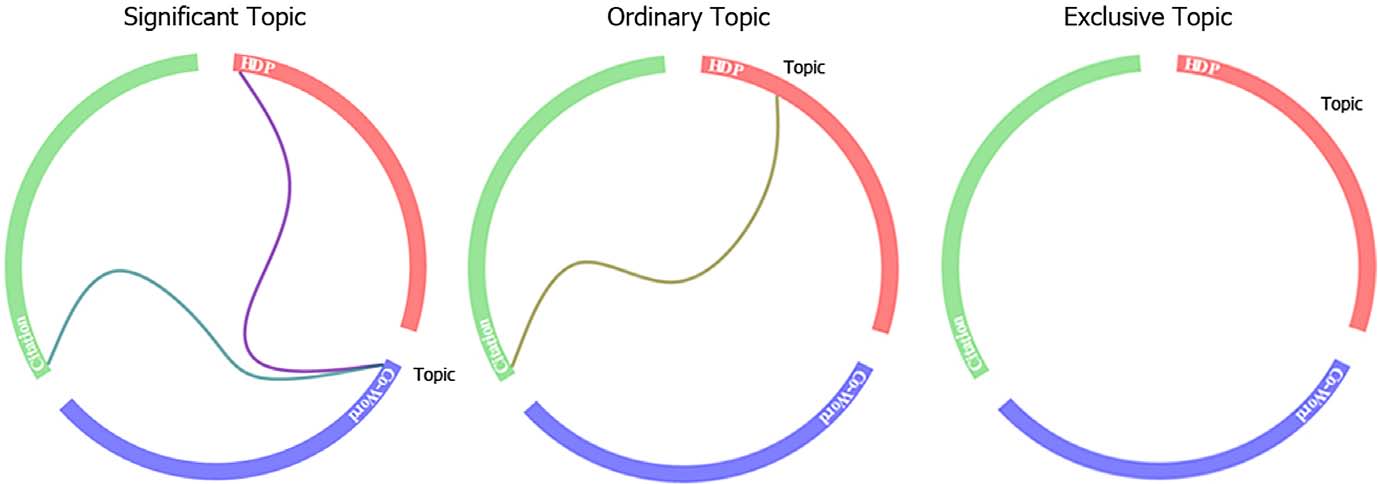
图4 三种模式的主题
主题跟踪方法
在主题跟踪阶段,陈老师开发了时间流图对主题随时间延后进行描述(见图5),每种颜色表示一年,每年内的主题按照在整个主题中的比例大小进行排序,最重要的主题在矩形的顶部,最不重要的在底部。主题间的连线表示其相似性,线条越粗,相似度越大。

图5 三种方法识别的主题演化
在这部分中,对连续的两年间的主题进行连接,因此可以对主题进行跟踪。主题间的相似性计算通过Kullback-Leibler (KL) divergence,计算方法见公式6:

对于每个方法的主题跟踪能力,作者设计了2个指标进行测度:主题敏感性(topic sensitivity)和主题持续性(topic persistence)。
主题敏感性用于测度方法对主题是否敏感。通过lead time来衡量,lead time是从主题被监测到的时间到主题变为关键主题持续的时间(turned out to be a critical topic)。
主题持续性用于测度方法随时间对主题进行跟踪的能力。通过对一个主题从出生到消亡的消亡的时间间隔来计算。时间间隔越长,该方法的主题跟踪持续性就越强。
除了上述内容,陈老师还定义了主题演化模式(见图6)。有一对一、一对多、多对一三种。一般来说,这三种都是很普通的,所以一个卓越的方法必须能够发现所有者三种主题演化模式。
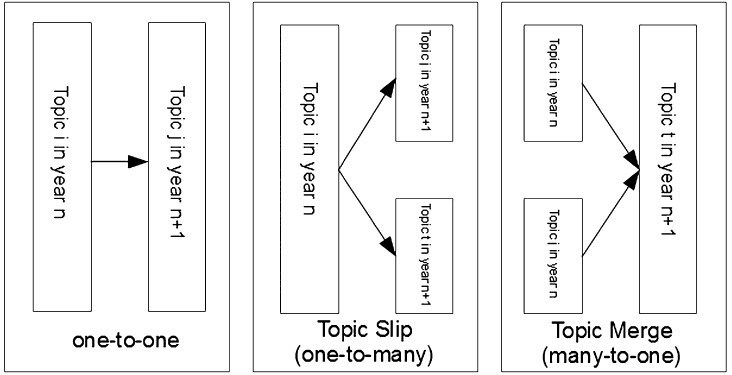
图6 三种演化模式
Results and Discussion
主题监测
共引、共词和HDP方法在主题监测中的比较
陈老师以年为单位,将这3种方法应用到恐怖主义数据中进行监测主题,然后使用hierarchical edge-bundling graphs对主题间的关系进行可视化,见图3。在环形中,红色的弧线表示HDP,绿色弧线表示共引方法,蓝色表示共词。环形外面的标签表示用相应的方法识别到的主题。在每个弧线的起点,其主题最重要,越远离起点,主题就越不重要。两个主题之间的连线表示这两个主题是相似的,连线的粗细与相似度大小成比例。相似性根据两个主题的词的重叠度,使用Jaccard coefficient计算。
图7是对从1995-2012年的三种方法的相似度的比较。从图中可知,这三种方法是密切相关的,但是仍然存在不同之处:
- 在主题监测中,理想的方法可以将主题彼此分开。用其他的话说就是理想的方法可以使组内关联最小化。共引和共词分析都有这种关联(见图7中1998年的结果中,共引和共词分析都有这种关联),但是HDP却没有。从这个方面来说,HDP在主题的区分性上优于其他两种方法。
- HDP与共引和共词分析都有密切的相似性连接,但是,共引分析与HDP方法的连线比共词分析与HDP的连线更密集。这种现象说明相对于共词分析方法,HDP与共引方法有更多的重叠主题。换句话说,被共词分析监测到的重要被HDP监测到的可能性更大,反之亦然。因此,HDP的结果与共引分析方法的结果更相似。
- 共引分析和共词分析连接紧密,但是相似性相对较弱。这种现象可能由于这个领域中的词表变化导致的(不理解???),从这个视角来说,可以推测HDP对一个领域内的词表的变化是不敏感的,但是语义特征维持的更好。
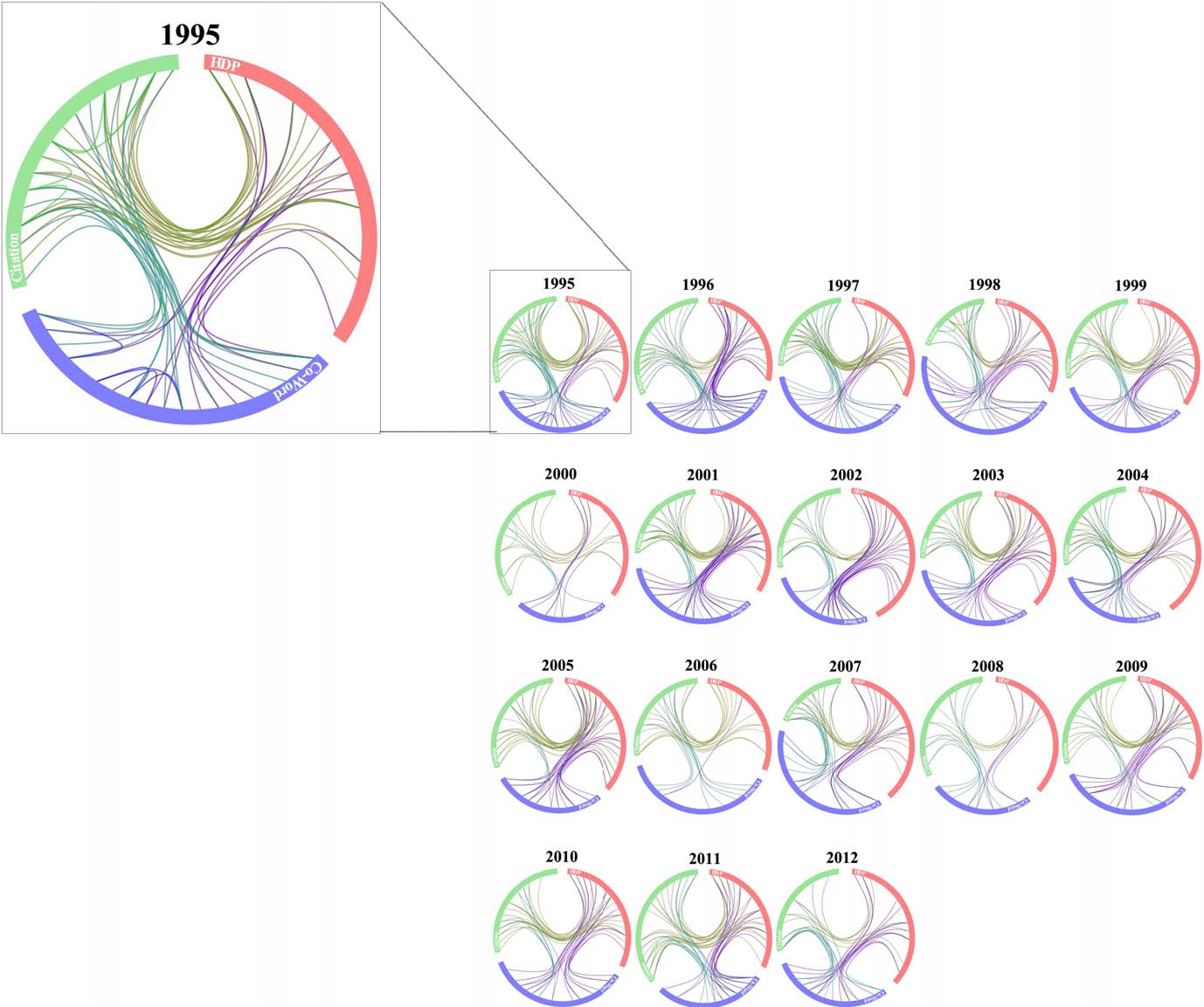
图7 不同方法识别的主题间的关联
图7表明这三种方法识别的主题明显不同但是相似,这是因为它们分别给予不同的理论生成主题。但是,尽管方法不同,结果却很相关。由一种方法监测到的主题可以与另一种方法监测到的主题相似。如果一种方法可以发现另一种方法发现的所有主题,我们认为该方法在主题监测方面表现出色,通过coverage进行测度。表1是每种方法的coverage值,由于每种方法生成的主题个数不同,因此coverage函数是不对称的,Coverage(A,B)可能和Coverage(B,A)不相等。
表1表明HDP与共词和共引的Coverage值最大。说明HDP可以发现更多的主题,进一步表明HDP很可能作为一个综合的主题监测工具。

除了一般比较外,我们可能对重要主题和其他主题的相关性更感兴趣,图8显示了不同方法间重要主题的覆盖度。CW表示共词,CC表示共引。
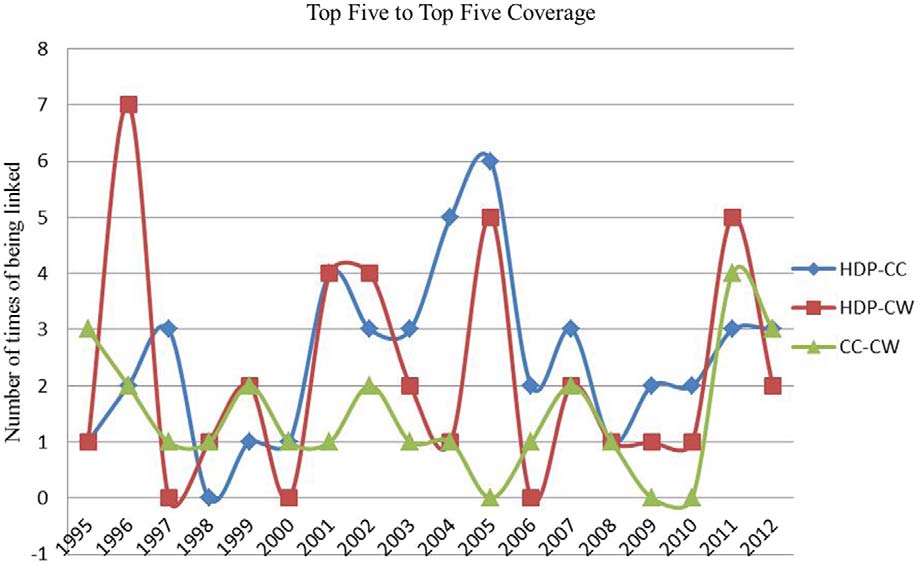
图8 三种方法中 top5主题的覆盖度
图8表明HDP的覆盖度更高,因此我们认为HDP在监测重要主题的能力优于其他两种方法。
简而言之,通过Coverage计算,HDP在对整个主题的发现和重要主题的发现上都优于其他两个方法。
监测不同类型的主题
上文中提到将主题分为3类,significant topics(明显主题)、ordinary topics(普通主题)和exclusive topics(独有主题),对于exclusive topics可以从两个方面来解释。独有主题可以表明一种方法能监测到一个主题但是其他方法却监测不到。或者说,该这些主题是噪音。在不同的情况下,我们采用不同的解释。与此相反,明显的主题可以作为衡量主题监测能力的优秀指标,如果一个方法监测到的明显主题越多,该方法就越优秀,因为significant topics(明显主题)反映了三种方法一致的结果。三种方法生成的主题中,每种主题类型的比例如图9所示。图9的顶部表示重要主题的比例,中部表示普通主题的比例,底部是独有主题的比例。
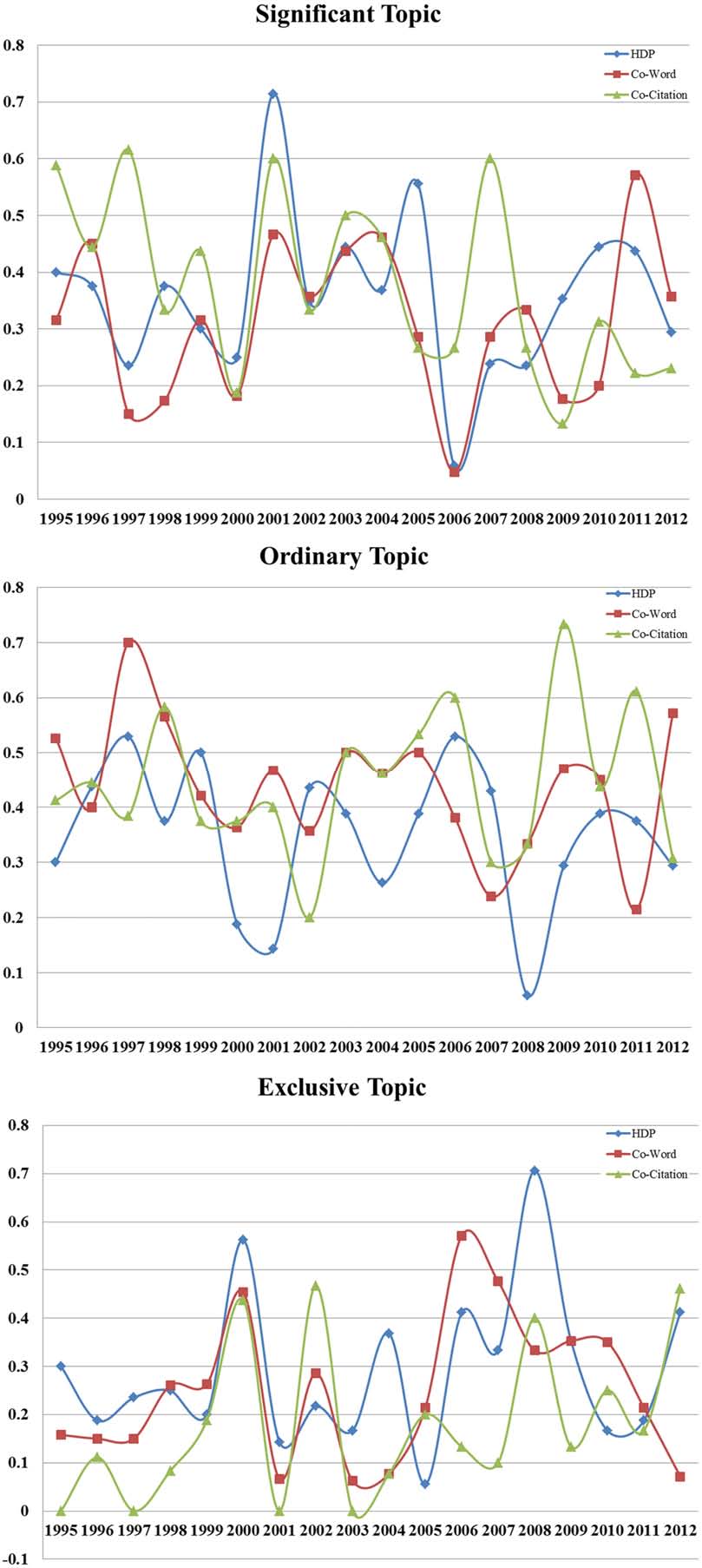
图9 不同类型的主题在三种方法生成结果中的比例
图9表明,一般情况下HDP和共引在监测明显主题上优于共词分析。尽管共引分析在2000年之前比HDP表现优秀,在2000年之后HDP超过了共引分析。尤其在2008年之后,HDP明显优于共引分析。
在一般主题监测中,共引分析和共词分析都优于HDP方法,而共引分析和共词分析表现相当。
在独有主题中,HDP稍微优于其它两种方法,而共词也要相对优于共引分析。
总之,HDP在监测明显主题和独有主题上比较有优势。共引分析在监测明显主题和普通主题上表现较好。共词分析善于监测普通主题和独有主题。
在明显主题中,我们可以发现另一种主题——“重要主题”,这种主题由三种方法监测到,而且排在前5位以内。图10是该主题的示意图,这种主题在主题领域中非常重要。
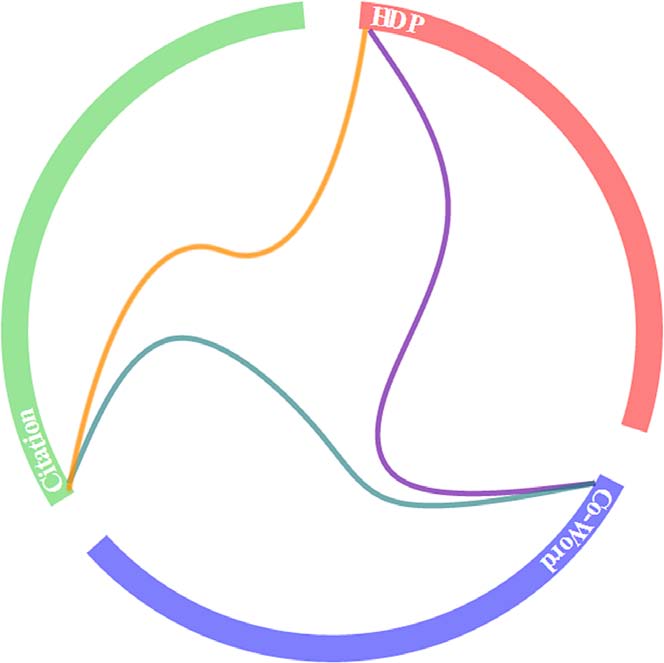
图10 重要主题示意图
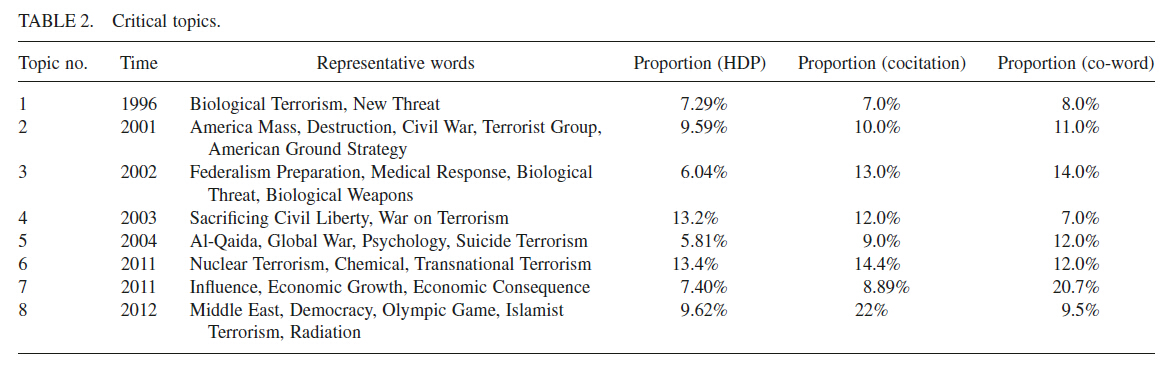
本次试验中监测到的重要主题有8个。
1. Biological Terrorism (1996)
2. American Terrorism Strategy (2001)
3. Biological Threat (2002)
4. War on Terrorism (2003)
5. Al-Qaida and Suicide Terrorism (2004)
6. Nuclear and Chemical Terrorism (2011)
7. Influence of Terrorism (2011)
8. Islamist Terrorism and Olympic Game (2012)
这些主题想详细信息见表2.
为了更直观的理解三种方法监测到的重要主题。图11是三种方法监测到的重要主题随时间的变化。从中可以看出HDP和共引分析在重要主题监测中的趋势较为相似,但是共词分析却与这两者都不同。三分之二的方法的相似性变化趋势相同,第三种方法不同,我们可以暂时推测HDP和共引分析比共词分析更可靠。

图11 重要主题所占比例
主题跟踪
共引、共词和HDP比较
如果我们将连续两年的相似主题连接起来,就可以看到主题的随时间的演化。使用KL Divergence测度主题间的相似度,线的粗细表示相似度大小。
通过共词分析和共引分析生成的主题间的强相似度较少,且随时间逐渐减少,HDP则较多,且关系数较稳定,从这个方面来说,HDP在主题监测中更稳定。
共词分析和共引分析中的连线基本上都聚集在图形的底部,但是HDP一般出现在图形的中部或者更高的位置。这表示HDP在发现重要主题的关系方面比共词和共引分析表现更好。在实际应用中,人们对重要主题更感兴趣,因此HDP是更适合的工具。
我们在前文中定义了两个指标来对主题跟踪能力进行评价,分别是主题敏感性和主题持久性。下面将使用这两个指标对三种方法进行比较,另外我们将还将对三种方法的主题变化模式识别能力进行评价。
为了测量主题敏感度,选择了表2中的重要主题作为对象。然后计算其lead time(即从第一次被监测到变为重要主题期间经历的时间)作为敏感度。lead time越长,主题监测能力就越强,因为可以在主题被广泛识别之前帮助我们探测到主题。因此我们跟踪表2中的主题,计算每种方法的平均 lead time,结果见表3。
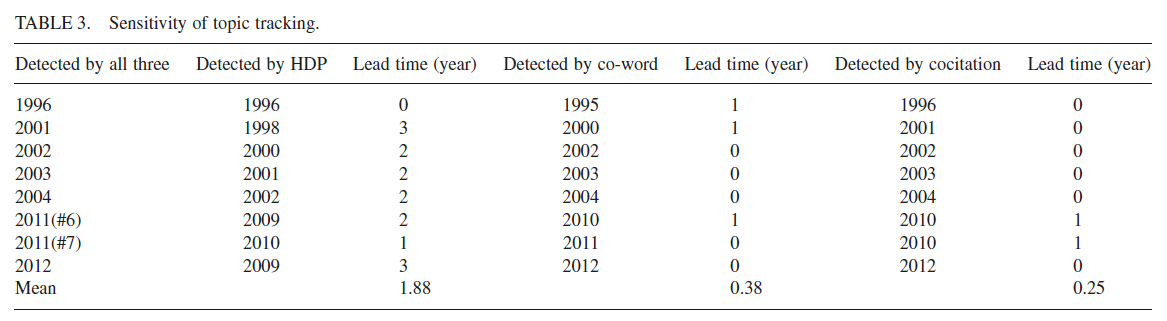
从表3可以看出,HDP的lead time平均值最大,为1.88年,而共词分析为0.38年,共引分析最短0.25年。HDP可以对重要主题提前两年进行监测,共词和共引的时间都少于半年。但是,相对来说,共词分析比共引分析稍微敏感一点点。这个结果表明HDP是最敏感的主题监测方法,共引分析方法敏感度最低。这个结论与“共引分析在主题跟踪上存在严重的延迟性”的观点也一致。
主题的持久性是指主题从出现到消亡的时间。图12是对三种方法的所有主题的持续时间的描述。尽管共词分析有更多的主题连接,大部分开始于1995年并结束语1997年,这可能是由于1995年的许多主题在1996年合并为一个主题,并在1997年又分类成多个主题的原因造成的。然而,我们关注的是主题连接的长度而不是主题连接的个数。
图12表明在共引分析中,没有一个主题可以持续超过5年时间,但是在HDP和共词分析中一个主题最长可以持续8年。和共词分析相比,在长度大于4年的连接中,HDP检测到的更多。所以在持久性方面,HDP和共词方法优于共引方法,同时HDP优于共词分析。
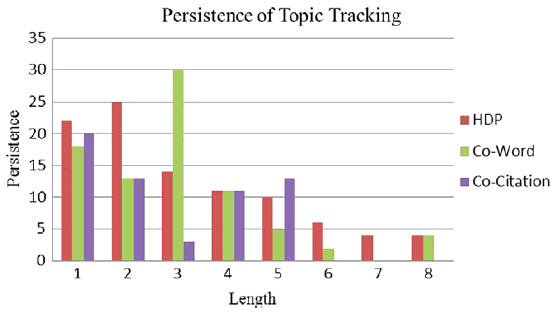
图12 主题跟踪的持久性
此外,在数据和方法部分我们提到了三种类型的演化模式(见图6),这三种模式在3中方法中的统计结果见表4,从中可以看出这三种方法尤其是共引方法更善于发现一对一的模式,超过60的关系都是一对一关系。

表4显示共词方法监测到了更多的合并(多对一)和分裂(一对多)关系,但是大部分都在1995-1997年之间。正如上文提到的,许多1995的主题在1996年合并为一个主题,并在1997年重新分类为多个主题。如果我们去掉1995-1997年间的关系,共词分析检测到的结果(Co-Word(*)列中)就很少了。相反,HDP在监测一对多和多对一关系方面更加稳定和有力。所以在不同的情况下,我们要采用不同的方法进行主题跟踪。如果想要追踪一对一关系,共引分析是最佳选择,但是如果想发现主题间的分化与合并,HDP是最好的选择。
总之,HDP在主题跟踪踪表现最佳,共词方法次之,共引分析排名最后。
跟踪重要的主题演化过程
上文提到HDP擅长于主题跟踪,我们使用HDP找到了文档集合中的重要主题演化过程,为了清晰的查看演化过程,我们保留了每个主题的前20个词,并对重新绘制了图5(在图5中只有5个词),得到了图13,图13中的时间范围和图5一样。
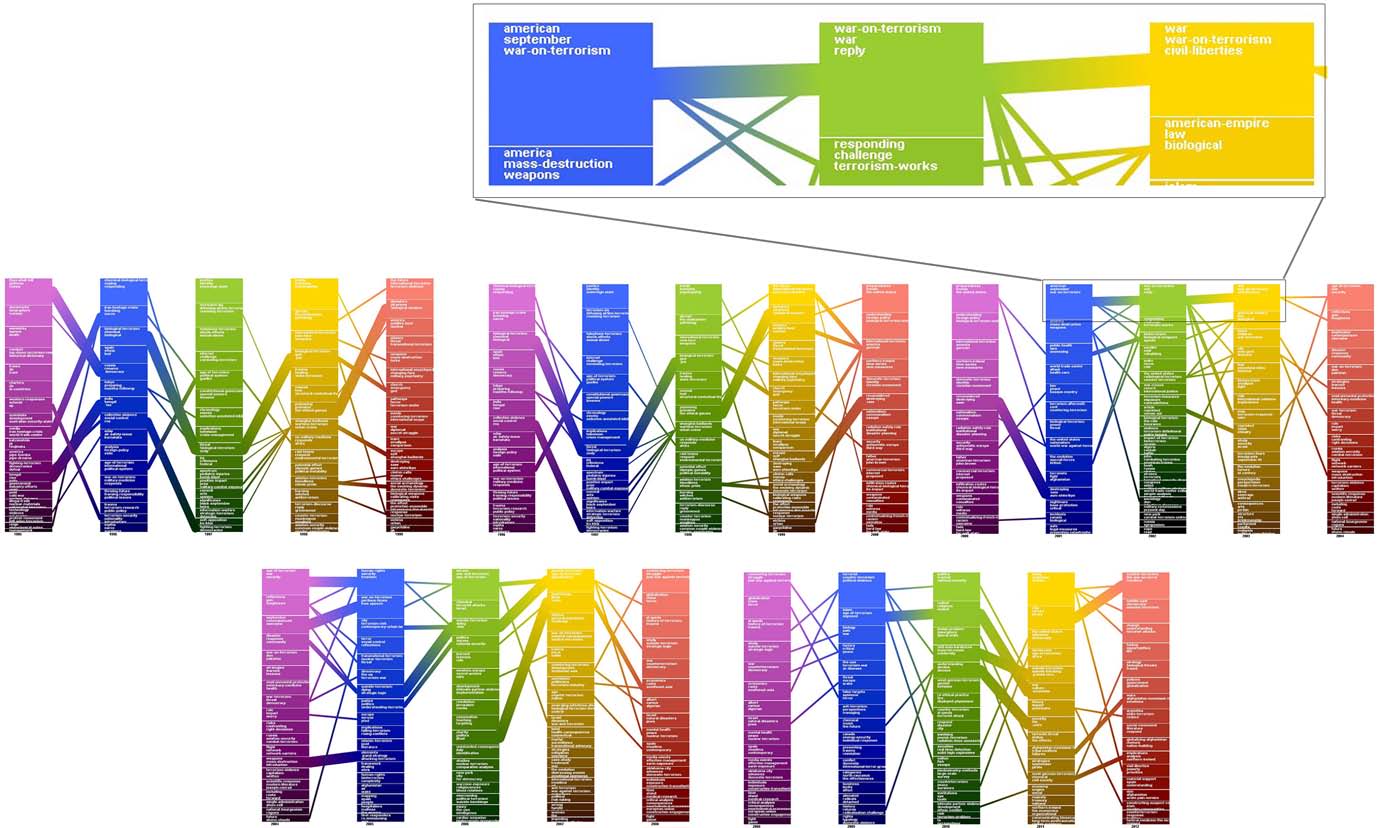
图13 主题演化
在图13中,重要的主题趋势出现在2002年(在图中顶部),并且一直保持到2007年。由于2001年的911恐怖袭击事件,2002年得到了很多的研究。从2002到2007年,研究主题从911事件向“自杀恐怖主义”转变,2007年之后,又分成其他小的领域。
Conclusion
该文比较了三种方法在监测和跟踪方面的效果,并在Terrorism研究数据中进行了测试,然后进行了可视化展示。最终发现HDP在敏感性和持久性方面都优于其他两种方法。
另外,在主题监测中,共引方法优于共词方法,但是在主题跟踪中,共词方法优于共引方法。
我们监测到了8个重要的主题,一个重要的关于恐怖主义研究的演化过程。
但是,目前的研究也存在一些局限性,需要在将来的研究中继续改进。
- 仅仅用文章的标题进行分析,没有充分利用关键词和摘要信息。只用标题可能会漏掉重要的语义信息,在今后的研究中将会将其他信息包含进来,从而扩展方法的范围。
- 使用的数据仅仅在一个领域(恐怖主义),没有测试该方法在其他领域的适用性。接下来的研究将解决扩展性问题,包括将该方法应用与更广泛的科学领域或其他类型的文本数据,例如社交媒体数据等。
- 在主题跟踪中,相似度高的主题被作为一个主题,但是它们可能是不同的主题。下一步,将研究能够追踪特定主题的方法,但是不依赖于由重叠词计算出的相似度。
研究数据来源于WoS,对这个研究感兴趣的都可以从这里下载相同的数据。
最后,我们的结果表明与传统的共词和共引分析方法相比,HDP在主题监测和跟踪方面更有前途。但是深入的研究还需要对更广泛的数据源和学科进行测试和实验。
(完)
