
Python_Crawler_Scrapy05
Scrapy Architecture overview
Scrapy Tutorial: https://blog.michaelyin.info/scrapy-tutorial-series-web-scraping-using-python/
Scrapy Reference: https://doc.scrapy.org/en/latest/
Scrapy installation:
1 #To install scrapy on Ubuntu (or Ubuntu-based) systems, you need to install these dependencies: 2 sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev 3 4 #If you want to install scrapy on Python 3, you’ll also need Python 3 development headers: 5 sudo apt-get install python3 python3-dev python3-pip 6 7 #you can install Scrapy with pip or pip3 after that: 8 pip install scrapy # install in /usr/local/lib/python2.7/dist-packages/scrapy if use python3, don't need to use pip install scrapy 9 pip3 install scrapy # install in /usr/local/lib/python3.5/dist-packages/scrapy
1. scrapy URLs (A simple example: )
class xxspider(scrapy.Spider):
name = 'xxspider'
start_urls = []
def parser(self,response)
for item in iresponse.xpath(//*[@id/class = 'xx']/div/) / response.css(div>ol>li):
yield { 'xx_name' : item.css('a tag').xpath(@href).extract_first(), or 'xx_name' : item.css('a tag::text).extract_first(),
'xx_desc' : item.xpath('span/text()')..extract_first(),
OR 'xx_desc' : item.css('span::text').extract_first(),
}
next_page = response.css('li.next a::attr(href)').extract_first()
OR next_page = response.xpath('//span[@class="next"]/a/@href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
OR next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
# A Scrapy spider typically generates many dictionaries containing the data extracted from the page. To do that, we use the yield Python keyword in the callback, as you can see above. The simplest way to store the scraped data is by using Feed exports, with the following command:
1 scrapy crawl quotes -o quotes.json
- Scrapy one page
start_urls = ['https://www.cnblogs.com']
- Scrapy multiple pages
start_urls = ['https://www.cnblogs.com/pick/#p%s' %p for p in range(1,5)]
OR
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
OR next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
- Scrapy multiple pages recursively
next_page = response.css('li.next a::attr(href)').extract_first()
OR response.xpath('//span[@class="next"]/a/@href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
OR next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
2. extract data
无论用CSS或Xpath提取数据,都要使用“就近原则,”。
- CSS
response.css('span.next:::text').extract_first() 要比长路径好:
response.css('#content > div > div.article > div.paginator > span.next::text').extract_first()
- Xpath
response.xpath('//span[@class="next"]/text()).extract_first() 要比长路径好:
response.xpath('//*[@id="content"]/div/div/div/span/text()).extract_first()
Example:
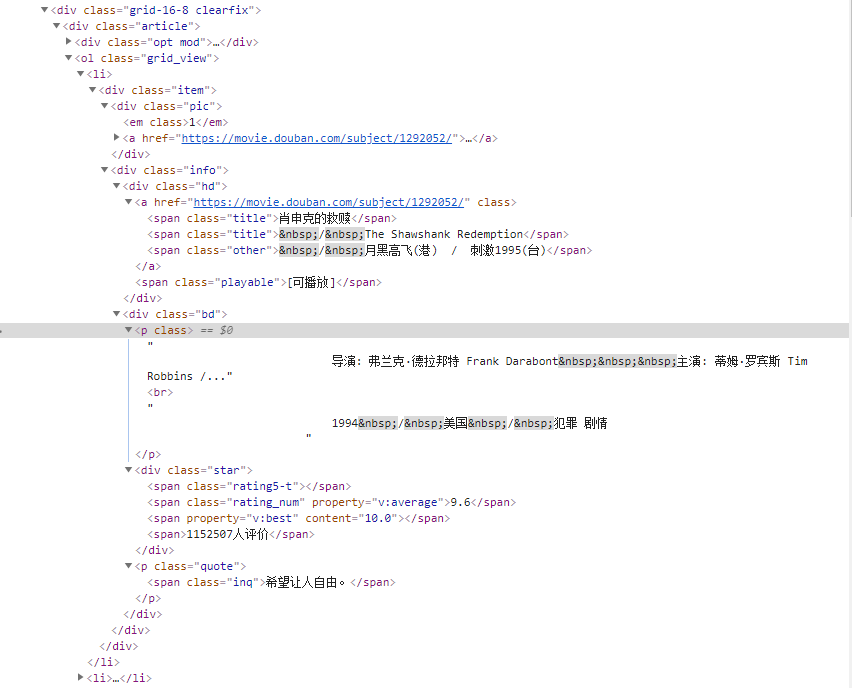
1 for item in response.xpath('//div[@class="info"]'): 2 print(item.xpath('div[@class="hd"]/a/span[1]/text()').extract_first()) 3 print(item.xpath('div[@class="hd"]/a/@href').extract_first()) 4 print(item.xpath('div[@class="bd"]/p/text()').extract_first()) 5 print(item.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract_first())
To extract data by using shell
1 scrapy shell 'http://quotes.toscrape.com/page/1/'
- CSS: The result of running
response.css('title')is a list-like object CalledSelectorList)
1 # To display a list by using extract() or an element by using extract_first() / [0].extract() 2 3 response.css('body > div > div > div > div> span').extract() 4 5 response.css('body > div > div > div > div> span').extract_first() 6 7 response.css('body > div > div > div > div> span')[0].extract() 8 9 # To display the text from the label you want by using '::text' 10 11 response.css('body > div > div > div > div> span::text').extract() 12 13 response.css('body > div > div > div > div> span::text').extract_first() 14 15 response.css('body > div > div > div > div> span::text')[0].extract()
- Besides the
extract()andextract_first()methods, you can also use there()method to extract using regular expressions:
1 >>> response.css('title::text').re(r'Quotes.*') 2 ['Quotes to Scrape'] 3 >>> response.css('title::text').re(r'Q\w+') 4 ['Quotes'] 5 >>> response.css('title::text').re(r'(\w+) to (\w+)') 6 ['Quotes', 'Scrape']
1 # To get the root element 2 >>> root = response.xpath('/html/body/div/div/div') 3 >>> root.xpath('./div/span[@class="text"]').extract() 4 >>> root.xpath('./div/span[@class="text"]').extract_first() 5 >>> root.xpath('./div/span[@class="text"]')[0].extract() 6 7 # To use '/text()' to extract the text 8 >>> root.xpath('./div/span[@class="text"]/text()')[0].extract() 9 >>> root.xpath('./div/span[@class="text"]/text()')[1].extract() 10 >>> root.xpath('./div/span[@class="text"]/text()')[2].extract() 11 12 # using extract_fist() 13 >>> root.xpath('./div/span[@class="text"]/text()').extract_first()
From the code above, you should know how to use / and // to select the node. If you want to filter all div elements which have class=quote
1 response.xpath("//div[@class='quote']").extract() 2 3 # you can use this syntax to filter nodes 4 response.xpath("//div[@class='quote']/span[@class='text']").extract() 5 response.xpath("//div[@class='quote']/span[@class='text']")[0].extract() 6 7 # use text() to extract all text inside nodes 8 response.xpath("//div[@class='quote']/span[@class='text']/text()").extract() # a list text 9 response.xpath("//div[@class='quote']/span[@class='text']/text()")[0].extract() # the text of the first node 10 response.xpath("//div[@class='quote']/span[@class='text']/text()").extract_first()# the text of the first node
To get attribute values:
- CSS
1 >>> response.css('a.tag::attr(href)').extract() 2 3 >>> response.css('div.tags a.tag::attr(href)').extract()
- Xpath
1 # To get the root element 2 root = response.xpath('/html/body/div/div/div/div/div[@class="tags"]') 3 4 # To get the attribute values: 5 root.css('a.tag').xpath('@href').extract() 6 >>> root.css('a.tag').xpath('@href').extract() 7 8 >>> root.css('a').xpath('@class').extract()
Scrapy Frame: https://blog.csdn.net/qq_33689414/article/details/78669490
Scrapy installation
To install scrapy on Ubuntu (or Ubuntu-based) systems, you need to install these dependencies:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
python-dev,zlib1g-dev,libxml2-devandlibxslt1-devare required forlxmllibssl-devandlibffi-devare required forcryptography
If you want to install scrapy on Python 3, you’ll also need Python 3 development headers:
sudo apt-get install python3 python3-dev python3-pip
you can install Scrapy with pip or pip3 after that:
pip install scrapy # install in /usr/local/lib/python2.7/dist-packages/scrapy
pip3 install scrapy # install in /usr/local/lib/python3.5/dist-packages/scrapy
Warnings after installation: you do not have a working installation of the service_identity module: "cannot import name 'opentype'"
solution:
1 pip3 install service_identity --force --upgrade
Data flow

The data flow in Scrapy is controlled by the execution engine, and goes like this:
- The Engine gets the initial Requests to crawl from the Spider.
- The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
- The Scheduler returns the next Requests to the Engine.
- The Engine sends the Requests to the Downloader, passing through theDownloader Middlewares (see
process_request()). - Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (see
process_response()). - The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (see
process_spider_input()). - The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (see
process_spider_output()). - The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.
- The process repeats (from step 1) until there are no more requests from the Scheduler.

Event-driven networking
Scrapy is written with Twisted, a popular event-driven networking framework for Python. Thus, it’s implemented using a non-blocking (aka asynchronous) code for concurrency.
For more information about asynchronous programming and Twisted see these links:
- Introduction to Deferreds in Twisted
- Twisted - hello, asynchronous programming
- Twisted Introduction - Krondo
Example 01: just crawl one page
1 import scrapy 2 3 class JulyeduSpider(scrapy.Spider): 4 name = 'julyedu' #give the spider a name 5 start_urls = ['https://www.julyedu.com/category/index'] #give it a URL to crawl 6 7 def parse(self, response): #how to parse the HTML webpage 8 #print (response.xpath('//div[@class="course_info_box"]')) 9 for julyedu_class in response.xpath('//div[@class="course_info_box"]'): #定位到具有course_info_box属性的div标签。 10 print(julyedu_class) 11 print(julyedu_class.xpath('a/h4/text()')) #在原有标签的基础上找a/h4标签。text()提取文本内容。 12 print(julyedu_class.xpath('a/h4/text()').extract_first()) #extract_first(),extract出来是一个list 13 print(i, julyedu_class.xpath('a/p[1]/text()').extract_first()) 14 #print(i, julyedu_class.xpath('a/p[@class="course-info-tip"][1]/text()').extract_first()) #同上。 15 print(i, julyedu_class.xpath('a/p[2]/text()').extract_first()) 16 yield {'title':julyedu_class.xpath('a/h4/text()').extract_first(),'description':julyedu_class.xpath('a/p[1]/text()').extract_first()} #yield返回一个字典
#Outcome:
<Selector xpath='//div[@class="course_info_box"]' data='<div class="course_info_box">\n\t\t\t\t\t\t\t<a '> #print(julyedu_class)
[<Selector xpath='a/h4/text()' data='机器学习中的数学第二期 [远胜第1期,另转发送海量数学干货]'>] #print(julyedu_class.xpath('a/h4/text()'))
0 机器学习中的数学第二期 [远胜第1期,另转发送海量数学干货] #print(i, julyedu_class.xpath('a/h4/text()').extract_first())
1 涵盖微积分,概率论,线性代数以及优化 #print(i, julyedu_class.xpath('a/p[1]/text()').extract_first())
1 开班时间:已上前两次课,年后3.3日起每周六、周日晚8点-10点继续直播 #print(i, julyedu_class.xpath('a/p[2]/text()').extract_first())
2018-02-14 09:20:17 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.julyedu.com/category/index>
{'title': '机器学习中的数学第二期 [远胜第1期,另转发送海量数学干货]'} #yield {'title':julyedu_class.xpath('a/h4/text()').extract_first()}
<Selector xpath='//div[@class="course_info_box"]' data='<div class="course_info_box">\n\t\t\t\t\t\t\t<a '>
[<Selector xpath='a/h4/text()' data='深度学习项目班 [一站式掌握场景、数据、建模与优化]'>]
1 深度学习项目班 [一站式掌握场景、数据、建模与优化]
2 从场景理解、到数据分析、到建模与优化,一站式全掌握。
2 开班时间:3月24日,每周六周日晚上8~10点
2018-02-14 09:20:17 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.julyedu.com/category/index>
Example 02: crawl multiple pages
1 import scrapy 2 3 class CnBlog(scrapy.Spider): 4 name = 'CnBlog' 5 start_urls = ['https://www.cnblogs.com/pick/#p%s' %p for p in range(1,5)] #crawl multiple pages by using for clause. 6 7 def parse(self, response): 8 for cn_blog_root_xpath in response.xpath('//div[@class="post_item"]'): 9 print(cn_blog_root_xpath.xpath('div/div/span/text()').extract_first()) 10 print(cn_blog_root_xpath.xpath('div[@class="post_item_body"]/h3/a/text()').extract_first()) 11 yield {'num':cn_blog_root_xpath.xpath('div[@class="digg"]/div/span/text()').extract_first(),'title':cn_blog_root_xpath.xpath('div[@class="post_item_body"]/h3/a/text()').extract_first()}
#outcome
{"num": "124", "title": "\u5982\u4f55\u5199\u4ee3\u7801 \u2014\u2014 \u7f16\u7a0
b\u5185\u529f\u5fc3\u6cd5"},
{"num": "259", "title": "\u3010javascript\u3011\u51fd\u6570\u4e2d\u7684this\u768
4\u56db\u79cd\u7ed1\u5b9a\u5f62\u5f0f \u2014 \u5927\u5bb6\u51c6\u5907\u597d\u74d
c\u5b50\uff0c\u6211\u8981\u8bb2\u6545\u4e8b\u5566~~"}
]
Example 03: crawl multiple pages_depth_first_traversal (by finding the next button, instead of the pages)
1 import scrapy 2 3 class depth_first_spider(scrapy.Spider): #注:参数名不能变。name&start_urls 4 name = 'depth_first_transval' 5 start_urls = ['http://quotes.toscrape.com/tag/humor/'] 6 7 def parse(self, response): 8 for root_path in response.xpath('//div[@class="quote"]'): 9 print(root_path.xpath('span[@class="text"]/text()').extract_first()) 10 11 next_page = response.xpath('//li[@class="next"]/a/@href').extract_first() 12 if next_page is not None:
13 print(next_page) 14 next_page = response.urljoin(next_page) #把链接加入原链接中,形成新链接 15 print(next_page) 16 yield scrapy.Request(next_page,callback = self.parse) #call back parse.
#Outcome:
/tag/humor/page/2/ #before urljoin http://quotes.toscrape.com/tag/humor/page/2/ #after utljoin 2018-02-15 08:49:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/tag/humor/page/2/> (referer: http://quotes.toscrape.com/tag/humor/) “I am free of all prejudice. I hate everyone equally. ” “A lady's imagination is very rapid; it jumps from admiration to love, from love to matrimony in a moment.”
Example: scrap douban movices:
- CSS:


1 import scrapy 2 3 class JulyeduSpider(scrapy.Spider): 4 name="movies" 5 start_urls = ['https://movie.douban.com/top250'] 6 7 def parse(self,response): 8 for item in response.css('div.info'): 9 print(item.css('div.hd span.title::text').extract_first()) 10 print(item.css('div.hd a::attr(href)').extract_first()) 11 print(item.css('div.bd p::text').extract_first()) 12 print(item.css('div.bd p.quote span::text').extract_first()) 13 14 yield {'movie_name': item.css('div.hd span.title::text').extract_first(), 15 'link':item.css('div.hd a::attr(href)').extract_first(), 16 'description':item.css('div.bd p::text').extract_first(), 17 'quote':item.css('div.bd p.quote span::text').extract_first(), 18 } 19 20 next_page = response.css('span.next a::attr(href)').extract_first() 21 if next_page is not None: 22 next_page = response.urljoin(next_page) 23 yield scrapy.Request(next_page,callback=self.parse) 24 else: 25 print('scrapping is over')
- XPath:
1 import scrapy 2 3 class JulyeduSpider(scrapy.Spider): 4 name="movies" 5 start_urls = ['https://movie.douban.com/top250'] 6 7 def parse(self,response): 8 for item in response.xpath('//div[@class="info"]'): 9 print(item.xpath('div[@class="hd"]/a/span[1]/text()').extract_first()) 10 print(item.xpath('div[@class="hd"]/a/@href').extract_first()) 11 print(item.xpath('div[@class="bd"]/p/text()').extract_first()) 12 print(item.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract_first()) 13 14 yield {'movie_name': item.xpath('div[@class="hd"]/a/span[1]/text()').extract_first(), 15 'link':item.xpath('div[@class="hd"]/a/@href').extract_first(), 16 'description':item.xpath('div[@class="bd"]/p/text()').extract_first(), 17 'quote':item.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract_first(), 18 } 19 20 next_page = response.xpath('//span[@class="next"]/a/@href').extract_first() 21 if next_page is not None: 22 next_page = response.urljoin(next_page) 23 yield scrapy.Request(next_page,callback=self.parse) 24 else: 25 print('scrapping is over')
Scrapy Tutorial
This tutorial will walk you through these tasks:
- Creating a new Scrapy project
- Writing a spider to crawl a site and extract data
- Exporting the scraped data using the command line
- Changing spider to recursively follow links
- Using spider arguments
Creating a project
Before you start scraping, you will have to set up a new Scrapy project. Enter a directory where you’d like to store your code and run:
1 scrapy startproject tutorial
This will create a tutorial directory with the following contents:
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
The first Spider:
1 import scrapy 3 4 class QuotesSpider(scrapy.Spider): 5 name = "quotes" #identifies the Spider. 6 7 def start_requests(self): # return a iterable of Requests which the spider will begin to crawl from. 8 urls = [ 9 'http://quotes.toscrape.com/page/1/', 10 'http://quotes.toscrape.com/page/2/', 11 ] 12 for url in urls: 13 yield scrapy.Request(url=url, callback=self.parse) 14 15 def parse(self, response): #a method that will be called to handle the response downloaded for each of the requests made. 16 page = response.url.split("/")[-2] 17 filename = 'quotes-%s.html' % page 18 with open(filename, 'wb') as f: 19 f.write(response.body) 20 self.log('Saved file %s' % filename)
As you can see, our Spider subclasses scrapy.Spider and defines some attributes and methods:
-
name: identifies the Spider. It must be unique within a project, that is, you can’t set the same name for different Spiders. -
start_requests(): must return an iterable of Requests (you can return a list of requests or write a generator function) which the Spider will begin to crawl from. Subsequent requests will be generated successively from these initial requests. -
parse(): a method that will be called to handle the response downloaded for each of the requests made. The response parameter is an instance ofTextResponsethat holds the page content and has further helpful methods to handle it.The
parse()method usually parses the response, extracting the scraped data as dicts and also finding new URLs to follow and creating new requests (Request) from them.
How to run our spider
To put our spider to work, go to the project’s top level directory and run:
scrapy crawl quotes
or
scrapy runspider quotes_spider.py
Now, check the files in the current directory. You should notice that two new files have been created: quotes-1.html and quotes-2.html, with the content for the respective URLs, as our parse method instructs.
What just happened under the hood?
Scrapy schedules the scrapy.Request objects returned by the start_requests method of the Spider. Upon receiving a response for each one, it instantiates Response objects and calls the callback method associated with the request (in this case, the parse method) passing the response as argument.
A shortcut to the start_requests method
Instead of implementing a start_requests() method that generates scrapy.Request objects from URLs, you can just define a start_urls class attribute with a list of URLs. This list will then be used by the default implementation of start_requests() to create the initial requests for your spider:
1 import scrapy 2 3 class QuotesSpider(scrapy.Spider): 4 name = "quotes" 5 start_urls = [ 6 'http://quotes.toscrape.com/page/1/', 7 'http://quotes.toscrape.com/page/2/', 8 ] 9 10 def parse(self, response): 11 page = response.url.split("/")[-2] 12 filename = 'quotes-%s.html' % page 13 with open(filename, 'wb') as f: 14 f.write(response.body)
The parse() method will be called to handle each of the requests for those URLs, even though we haven’t explicitly told Scrapy to do so. This happens because parse() is Scrapy’s default callback method, which is called for requests without an explicitly assigned callback.
Extracting data
The best way to learn how to extract data with Scrapy is trying selectors using the shell Scrapy shell. Run:
scrapy shell 'http://quotes.toscrape.com/page/1/'
https://doc.scrapy.org/en/master/intro/tutorial.html#extracting-data
Selecting elements using CSS with the response object:
1 # The result of running response.css('title') is a list-like object called SelectorList, which represents a list of Selector objects that wrap around XML/HTML elements and allow you to run further queries to fine-grain the selection or extract the data. 2 3 >>> response.css('title') 4 [<Selector xpath='descendant-or-self::title' data='<title>Quotes to Scrape</title>'>] 5 6 # we’d get the full title element, including its tags: 7 8 >>> response.css('title')[0] 9 <Selector xpath='descendant-or-self::title' data='<title>Quotes to Scrape</title>'> 10 11 #the result of calling .extract() is a list, because we’re dealing with an instance of SelectorList. 12 13 >>> response.css('title').extract() 14 ['<title>Quotes to Scrape</title>'] 15 16 >>> response.css('title').extract_first() 17 '<title>Quotes to Scrape</title>' 18 19 >>> response.css('title')[0].extract() 20 '<title>Quotes to Scrape</title>' 21 22 # adding ::text to the CSS query, to mean we want to select only the text elements directly inside <title> element. 23 24 >>> response.css('title::text') 25 [<Selector xpath='descendant-or-self::title/text()' data='Quotes to Scrape'>] 26 28 >>> response.css('title::text').extract() 29 ['Quotes to Scrape'] 30 31 >>> response.css('title::text').extract_first() 32 'Quotes to Scrape' 33 34 However, using .extract_first() avoids an IndexError and returns None when it doesn’t find any element matching the selection. 35 36 >>> response.css('title::text')[0].extract() # equals .extract_first 37 'Quotes to Scrape'
Extracting text by using [0..n].extract() and extract_first():
1 # original copy selector: body > div > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text # the result of extract() is a list.
2 >>> response.css('body > div > div > div > div> span').extract()
['<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>', '<span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>', '<span class="text" itemprop="text">“It is our choices, Harry, that show what we truly are, far more than our abilities.”</span>', '<span>by <small class="author" itemprop="author">J.K. Rowling</small>\n <a href="/author/J-K-Rowling">(about)</a>\n </span>', '<span class="text" itemprop="text">“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”</span>', '<span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>', '<span class="text" itemprop="text">“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”</span>', '<span>by <small class="author" itemprop="author">Jane Austen</small>\n <a href="/author/Jane-Austen">(about)</a>\n </span>', '<span class="text" itemprop="text">“Imperfection is beauty, madness is genius and it\'s better to be absolutely ridiculous than absolutely boring.”</span>', '<span>by <small class="author" itemprop="author">Marilyn Monroe</small>\n <a href="/author/Marilyn-Monroe">(about)</a>\n </span>', '<span class="text" itemprop="text">“Try not to become a man of success. Rather become a man of value.”</span>', '<span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>', '<span class="text" itemprop="text">“It is better to be hated for what you are than to be loved for what you are not.”</span>', '<span>by <small class="author" itemprop="author">André Gide</small>\n <a href="/author/Andre-Gide">(about)</a>\n </span>', '<span class="text" itemprop="text">“I have not failed. I\'ve just found 10,000 ways that won\'t work.”</span>', '<span>by <small class="author" itemprop="author">Thomas A. Edison</small>\n <a href="/author/Thomas-A-Edison">(about)</a>\n </span>', '<span class="text" itemprop="text">“A woman is like a tea bag; you never know how strong it is until it\'s in hot water.”</span>', '<span>by <small class="author" itemprop="author">Eleanor Roosevelt</small>\n <a href="/author/Eleanor-Roosevelt">(about)</a>\n </span>', '<span class="text" itemprop="text">“A day without sunshine is like, you know, night.”</span>', '<span>by <small class="author" itemprop="author">Steve Martin</small>\n <a href="/author/Steve-Martin">(about)</a>\n </span>']
# the extract the first element of the list
3 >>> response.css('body > div > div > div > div > span::text')[0].extract() 4 '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' 5 6 >>> response.css('body > div > div > div > div > span::text').extract_first() 7 '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
8
9 Using the list index to extract the text of subsequent element.
10 >>> response.css('body > div > div > div > div> span')[1].extract()
'<span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>'
11 >>> response.css('body > div > div > div > div> span')[2].extract()
12 '<span class="text" itemprop="text">“It is our choices, Harry, that show what we truly are, far more than our abilities.”</span>'
Besides the extract() and extract_first() methods, you can also use the re() method to extract using regular expressions:
1 >>> response.css('title::text').re(r'Quotes.*') 2 ['Quotes to Scrape'] 3 >>> response.css('title::text').re(r'Q\w+') 4 ['Quotes'] 5 >>> response.css('title::text').re(r'(\w+) to (\w+)') 6 ['Quotes', 'Scrape']
Besides CSS, Scrapy selectors also support using XPath expressions:
1 # To get the root element 2 >>> root = response.xpath('/html/body/div/div/div') 3 4 >>> root.xpath('./div/span[@class="text"]').extract() 5 ['<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>', '<span class="text" itemprop="text">“It is our choices, Harry, that show what we truly are, far more than our abilities.”</span>', '<span class="text" itemprop="text">“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”</span>', '<span class="text" itemprop="text">“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”</span>', '<span class="text" itemprop="text">“Imperfection is beauty, madness is genius and it\'s better to be absolutely ridiculous than absolutely boring.”</span>', '<span class="text" itemprop="text">“Try not to become a man of success. Rather become a man of value.”</span>', '<span class="text" itemprop="text">“It is better to be hated for what you are than to be loved for what you are not.”</span>', '<span class="text" itemprop="text">“I have not failed. I\'ve just found 10,000 ways that won\'t work.”</span>', '<span class="text" itemprop="text">“A woman is like a tea bag; you never know how strong it is until it\'s in hot water.”</span>', '<span class="text" itemprop="text">“A day without sunshine is like, you know, night.”</span>'] 6 7 >>> root.xpath('./div/span[@class="text"]').extract_first() 8 '<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>' 9 10 >>> root.xpath('./div/span[@class="text"]')[0].extract() 11 '<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>' 12 13 # To use '/text()' to extract the text 14 15 >>> root.xpath('./div/span[@class="text"]/text()')[0].extract() 16 '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' 17 >>> 18 >>> root.xpath('./div/span[@class="text"]/text()')[1].extract() 19 '“It is our choices, Harry, that show what we truly are, far more than our abilities.”' 20 >>> root.xpath('./div/span[@class="text"]/text()')[2].extract() 21 '“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”' 22 23 # using extract_fist() 24 25 >>> root.xpath('./div/span[@class="text"]/text()').extract_first() 26 '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'
As you can see, .xpath() and .css() methods return a SelectorList instance, which is a list of new selectors. This API can be used for quickly selecting nested data:
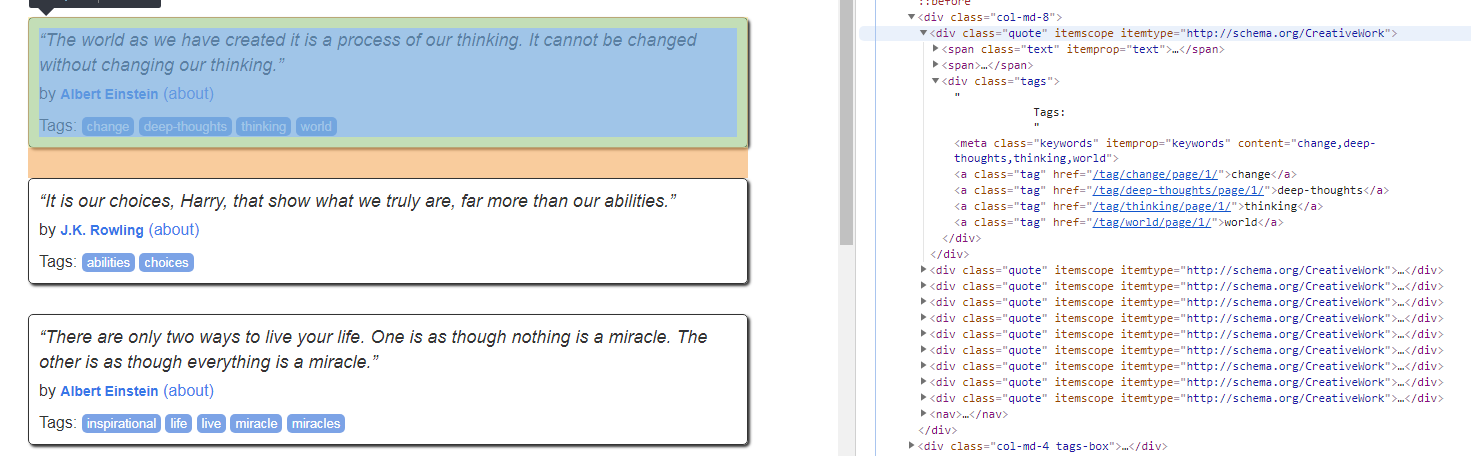
CSS
1 >>> response.css('a.tag::attr(href)').extract() 2 ['/tag/change/page/1/', '/tag/deep-thoughts/page/1/', '/tag/thinking/page/1/', '/tag/world/page/1/', '/tag/abilities/page/1/', '/tag/choices/page/1/', '/tag/inspirational/page/1/', '/tag/life/page/1/', '/tag/live/page/1/', '/tag/miracle/page/1/', '/tag/miracles/page/1/', '/tag/aliteracy/page/1/', '/tag/books/page/1/', '/tag/classic/page/1/', '/tag/humor/page/1/', '/tag/be-yourself/page/1/', '/tag/inspirational/page/1/', '/tag/adulthood/page/1/', '/tag/success/page/1/', '/tag/value/page/1/', '/tag/life/page/1/', '/tag/love/page/1/', '/tag/edison/page/1/', '/tag/failure/page/1/', '/tag/inspirational/page/1/', '/tag/paraphrased/page/1/', '/tag/misattributed-eleanor-roosevelt/page/1/', '/tag/humor/page/1/', '/tag/obvious/page/1/', '/tag/simile/page/1/', '/tag/love/', '/tag/inspirational/', '/tag/life/', '/tag/humor/', '/tag/books/', '/tag/reading/', '/tag/friendship/', '/tag/friends/', '/tag/truth/', '/tag/simile/'] 3 4 >>> response.css('div.tags a.tag::attr(href)').extract() 5 ['/tag/change/page/1/', '/tag/deep-thoughts/page/1/', '/tag/thinking/page/1/', '/tag/world/page/1/', '/tag/abilities/page/1/', '/tag/choices/page/1/', '/tag/inspirational/page/1/', '/tag/life/page/1/', '/tag/live/page/1/', '/tag/miracle/page/1/', '/tag/miracles/page/1/', '/tag/aliteracy/page/1/', '/tag/books/page/1/', '/tag/classic/page/1/', '/tag/humor/page/1/', '/tag/be-yourself/page/1/', '/tag/inspirational/page/1/', '/tag/adulthood/page/1/', '/tag/success/page/1/', '/tag/value/page/1/', '/tag/life/page/1/', '/tag/love/page/1/', '/tag/edison/page/1/', '/tag/failure/page/1/', '/tag/inspirational/page/1/', '/tag/paraphrased/page/1/', '/tag/misattributed-eleanor-roosevelt/page/1/', '/tag/humor/page/1/', '/tag/obvious/page/1/', '/tag/simile/page/1/']
XPath
1 # To get the root element 2 root = response.xpath('/html/body/div/div/div/div/div[@class="tags"]') 3 4 # To get the attribute values: 5 root.css('a.tag').xpath('@href').extract() 6 >>> root.css('a.tag').xpath('@href').extract() 7 ['/tag/change/page/1/', '/tag/deep-thoughts/page/1/', '/tag/thinking/page/1/', '/tag/world/page/1/', '/tag/abilities/page/1/', '/tag/choices/page/1/', '/tag/inspirational/page/1/', '/tag/life/page/1/', '/tag/live/page/1/', '/tag/miracle/page/1/', '/tag/miracles/page/1/', '/tag/aliteracy/page/1/', '/tag/books/page/1/', '/tag/classic/page/1/', '/tag/humor/page/1/', '/tag/be-yourself/page/1/', '/tag/inspirational/page/1/', '/tag/adulthood/page/1/', '/tag/success/page/1/', '/tag/value/page/1/', '/tag/life/page/1/', '/tag/love/page/1/', '/tag/edison/page/1/', '/tag/failure/page/1/', '/tag/inspirational/page/1/', '/tag/paraphrased/page/1/', '/tag/misattributed-eleanor-roosevelt/page/1/', '/tag/humor/page/1/', '/tag/obvious/page/1/', '/tag/simile/page/1/'] 8 9 >>> root.css('a').xpath('@class').extract() 10 ['tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag', 'tag'] 11 >>>
Storing the scraped data
The simplest way to store the scraped data is by using Feed exports, with the following command:
scrapy crawl quotes -o quotes.json
That will generate an quotes.json file containing all scraped items, serialized in JSON.
In small projects (like the one in this tutorial), that should be enough. However, if you want to perform more complex things with the scraped items, you can write an Item Pipeline. A placeholder file for Item Pipelines has been set up for you when the project is created, intutorial/pipelines.py. Though you don’t need to implement any item pipelines if you just want to store the scraped items.
Following links
1 def parse(self, response):
2 for root_path in response.xpath('//div[@class="quote"]'):
3 print(root_path.xpath('span[@class="text"]/text()').extract_first())
4
5 next_page = response.xpath('//li[@class="next"]/a/@href').extract_first()
6
7 if next_page is not None:
8 print(next_page)
9 next_page = response.urljoin(next_page) #builds a full absolute URL using the urljoin() method
10 print(next_page)
11 yield scrapy.Request(next_page,callback = self.parse) #when you yield a Request in a callback method, Scrapy will schedule that request to be sent and register a callback method to be executed when that request finishes.
A shortcut for creating Requests (same as response.follow):
1 def parse(self, response):
2 for root_path in response.xpath('//div[@class="quote"]'):
3 print(root_path.xpath('span[@class="text"]/text()').extract_first())
4
5 next_page = response.xpath('//li[@class="next"]/a/@href').extract_first()
6
7 if next_page is not None:
8 print(next_page)
9 yield response.follow(next_page,callback=self.parse) #Unlike scrapy.Request, response.follow supports relative URLs directly - no need to call urljoin.
