
互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑
上篇博文中,我们介绍了做互联网级监控系统的必备-Influxdb的关键特性、数据读写、应用场景:
本文中,我们介绍Influxdb数据库集群的搭建,同时分享一下我们使用集群遇到的坑!
一、环境准备
- 同一网段内,3个CentOS 节点,相互可以ping通
- 3个节点CentOS配置Hosts文件,相互可以解析主机名
- Azure 虚拟机启用root用户
- influxdb-0.10.3-1.x86_64.rpm
- 设置端口8083 8086 8088 8091例外
二、一步一步搭建Influxdb集群
1. 在各个节点的主机上配置Hosts文件,这样可以保证每个节点直接的互相通讯

2. 各个节点主机安装InfluxDB rpm,只是安装不启动Influxdb

3. 三个节点主机上依次 编辑Influxdb.conf文件(.etc/influxdb/influxdb.conf)
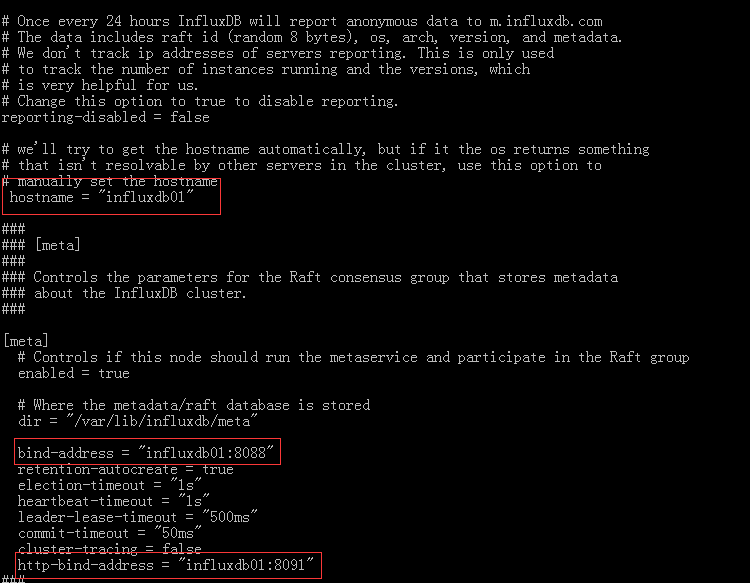
主要修改HostName、bind-address、http-bind-address三个选项
依次修改三个主机节点的配置文件
4. InfluxDB01机器上启动Influxdb
[root@influxdb01 influxdb]# sudo service influxdb start
5. InfluxDB02上配置/etc/default/influxdb文件
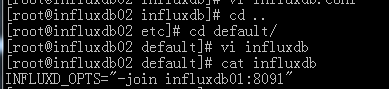
加入influxdb01节点
INFLUXD_OPTS="-join influxdb01:8091"
6. InfluxDB02机器启动InfluxDB
[root@influxdb02 default]# sudo service influxdb start
7. InfluxDB03上配置/etc/default/influxdb文件



加入influxdb01节点
INFLUXD_OPTS="-join influxdb01:8091"
8. InfluxDB03机器启动InfluxDB
[root@influxdb03 default]# sudo service influxdb start
9.InfluxDB01上启动InfluxDB
Influx -host influxdb01
10. 查看Influxdb集群
三、Influxdb集群,我们遇到的坑
Influxdb集群模式下,数据在各个节点之间是同步的,即,我们可以选择任何一个节点写入,数据都可以再其他节点查询到。
搭建集群后,我们遇到的第一个问题就是数据不同步问题。其实,数据写入压力并不大!
数据不同步后重启集群,依然数据不同步。
数据写入时,必须是UTC时间,并且是Unix下的UTC时间格式。
批量写入的数据,有时候会很慢,原因是数据必须按时间降序排序好,再批量插入。
单机模式比集群模式稳定,同时最新的集群不开源了,商业版本支持。
多条批量写入的性能好,但是并发数有限制,批量数据的个数在1000以内最佳。
周国庆
2017/7/12

