基于统计的无词典的高频词抽取(三)——子串归并
由于最近换了工作,需要熟悉新的工作环境,工作内容也比较多,所以一直没有更新文章,趁着今晚有空,就继续写写这系列的文章。
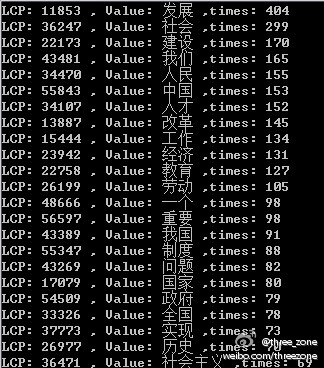
前面两篇,我们已经实现了后缀数组的排序,高频字串的抽取,也初有成效,如下图:
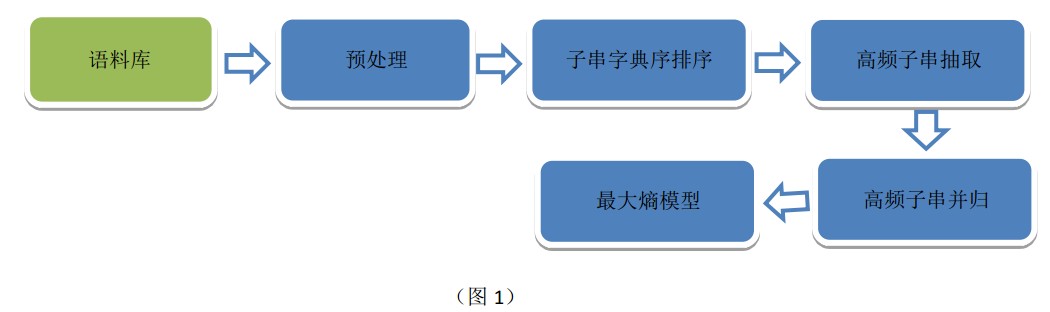
接下来,我们就继续对结果进行进一步的精确化,使用子串归并来实现:
首先,我先举一个可能不大适合的例子来大概解释一下什么叫做子串归并。假设,某个语料库中,统计到“你”出现了100次,而“你好”也刚好出现了100次,那么,我们舍弃“你”这个结果,保留“你好”;我们为什么这样做呢?从这个简单的例子可以看出,出现“你”子的时候,一定会出现“你好”,那么根据成词的规则,我们保存长的子串(一般来说,子串选取长度在[2,4]这个区间内)。
好了,现在,我们再从上面的规则中进行加深:
① 我们先限定抽取串的长度在[2,4]中,以避免抽取过长的字符串;
② 当字符串S被抽取(其中S的长度为L,L≥2,S出现的次数为 t),且S的后缀sfx(i)(其中i∈(0,L))在文本中出现的次数也等于t时(S的后缀出现的次数可能大于t,但不会小于t,这是很好理解的,例如,“中国人”出现次数为10,则其一个后缀“国人”仅在这个字符串中出现的次数就为10,而假设还有一个字符串“美国人”出现5次,那么“国人”这个字符串就出现了15次,大于10),S的后缀sfx(i)将不再被抽取;
③ 当然仅仅当母串的次数等于子串次数作为归并的条件,这限定太过苛刻,我们将可以调整归并的策略,引入阀值t,t根据语料库的大小进行调整(t取[0.1,0.3]较为合理;语料库越大时,应适当调低;文本越小时,应适当调高);假设字符串S1是S2的前缀,S1出现的次数t1,S2出现的次数为t2。当(t1 - t2 )/t2 <t 时,舍弃,S1不作高频串抽取;
我们将过程进行细化和限定,处理过程看起来稍微合理,下面,我使用C#将此过程转换为程序语言(注,由于时间关系,该代码未做任何优化,性能欠佳,大家可以对代码进行优化或自己实现)
1 public static void RemoveSubString(List<StringFrequency> stringFrequency, string str, int[] pat, int[] lcp) 2 { 3 var _STACK = new Stack<StringFrequency>(); 4 var _PSTACK = new Stack<int>(); 5 var isContinu = true; 6 var p = 0; 7 var count = stringFrequency.Count(); 8 for (var i = 0; i < count; i++) 9 { 10 isContinu = _PSTACK.Contains(i) ? false : true; 11 if (isContinu) 12 { 13 p = i; 14 var tmp = str.Substring(pat[stringFrequency[i].Position], lcp[stringFrequency[i].Position]); 15 for (var j = i + 1; j < count; j++) 16 { 17 if (!_PSTACK.Contains(j)) 18 { 19 var cur = str.Substring(pat[stringFrequency[j].Position], lcp[stringFrequency[j].Position]); 20 if (Convert.ToSingle((stringFrequency[i].Times - stringFrequency[j].Times) / stringFrequency[j].Times)>0.3f) 21 break; 22 if (tmp.Contains(cur)) 23 { 24 _STACK.Push(stringFrequency[j]); 25 _PSTACK.Push(j); 26 } 27 else if (cur.Contains(tmp)) 28 { 29 tmp = cur; 30 _STACK.Push(stringFrequency[i]); 31 _PSTACK.Push(i); 32 } 33 } 34 } 35 } 36 } 37 while (_STACK.Count() > 0) 38 { 39 stringFrequency.Remove(_STACK.Pop()); 40 } 41 }
上面代码指向前,我们需要使用一个根据出现次数排序的 List<StringFrequency> stringFrequency 集合:
1 var sortList = stringFquency.OrderByDescending(x => x.Times).ToList(); 2 //str为语料库,a为字符串的后缀数组,lcpList为LCP扫描结果,详见上一篇 3 RemoveSubString(sortList, str, a, lcpList);
如果不出所料,上面的代码执行效率是不尽人意的,即使上面做了一定程度上的减少扫描次数,但是大体上的时间复杂度要达O(n2),效率奇低;而如果使用基于散列表的算法(将所有重复串及其频次存放于散列表中,然后依次去判断表中的每一项的所有可能子串是否存在,存在且频次相同,则归并,理论上可达O(n),但是次算法空间开销太大,容易造成内存泄露,大家可以参考《基于散列的子串归并算法》这篇论文)。。。我们可以结合上一篇文章中扫描LCP的过程,并在此过程中完成子串归并的动作;这篇文章仅仅描述子串归并的原理,此处就不再详述解决的过程;
好了,第三部分就先讲到这里,如果觉得文章对您有用或者对其他人有帮助,请帮忙点文章下面的“推荐”;如果文章有任何纰漏,欢迎指正,谢谢!
多聚旅游 聚游宝 学友网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号