
.net之工作流工程展示及代码分享(三)数据存储引擎
数据存储引擎是本项目里比较有特色的模块。
特色一,使用接口来对应不同的数据库。数据库可以是Oracle、Sqlserver、MogoDB、甚至是XML文件。采用接口进行对应:



1 public interface IWorkflowDB 2 { 3 List<Flow> GetFlows(); 4 bool SaveFlow(Flow flow); 5 bool DeleteFlow(Guid flowId); 6 7 FlowInstance GetFlowInstanceByInstanceId(Guid flowInstanceId); 8 List<FlowInstance> GetFlowInstanceByFlowId(Guid flowId); 9 bool SaveFlowInstance(FlowInstance flowInstance); 10 List<FlowInstance> GetFlowInstancesListByUser(Person person = null); 11 bool DeleteFlowInstanceByInstanceId(Guid flowInstanceId); 12 13 bool SaveForm(Form form); 14 bool DeleteForm(Guid formId); 15 List<Form> GetFormList(); 16 17 bool AddStep(WorkflowStep workflowStep); 18 bool DeleteStep(Guid stepId); 19 List<WorkflowStep> GetStepList(); 20 21 bool AddBaseTable(WorkflowConstant.BaseTable baseTable, Dictionary<int, string> values); 22 Dictionary<int, string> GetBaseTableData(WorkflowConstant.BaseTable baseTable); 23 bool DeleteBaseTableValue(WorkflowConstant.BaseTable baseTable, int key); 24 }
特色二,使用Oracle的SYS.XMLTYPE来存储数据,查询时使用辅助方法,或者XML查询表达式
这样系统里一共只用了四个表,包括一个临时表,每个表不超过三个字段。
WORKFLOW_SETTINGS表:(存储系统设置参数、流程等)

WORKFLOW_FORM表:(存储系统表单)

WORKFLOW_FLOW表:(存储流程实例)
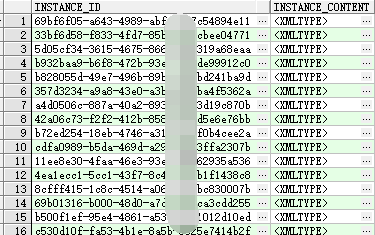
还有一个temp表,一行一列,字段为CLOB类型。
XMLType里面存储的是什么呢?不错,正是各个类的实例,序列化后的字符:

实际存储的方式:
保存时:类的实例-->XML序列化-->直接用Oracle的XMLtype存储;
读取时:读出数据-->反序列化-->类的实例直接可用。
这样就能方便的解决实体模型或领域模型与数据库存储之间“阻抗不匹配的”的问题。而且XMLType可以被SQLServer等主流数据库支持,所以迁移到其他数据库也很方便;如果你要使用常规的建表规则进行存储,只要实现IWorkflowDB接口即可。
序列化反序列化的方法,使用了扩展方法,可以放在项目里任何一个静态类里:
1 public static string ToSerializableXML<T>(this T t) 2 { 3 XmlSerializer mySerializer = new XmlSerializer(typeof (T)); 4 StringWriter sw = new StringWriter(); 5 mySerializer.Serialize(sw, t); 6 return sw.ToString(); 7 } 8 9 public static T ToEntity<T>(this string xmlString) 10 { 11 var xs = new XmlSerializer(typeof (T)); 12 var srReader = new StringReader(xmlString); 13 var steplist = (T) xs.Deserialize(srReader); 14 return steplist; 15 }
注意:有些类不能被序列化,比如Dictionary<TKey,TValue>,需要自己写可序列化的类。
好啦,接下来是实现IWorkflowDB接口的OracleWorkFlowDBUtility类,以存储工作流表单为例:
存储:
1 public bool SaveForm(Form form) 2 { 3 var formContent = form.FormContent; 4 var formId = form.FormId; 5 form.FormContent = string.Empty; 6 7 var sql = string.Empty; 8 9 DbHelperOra.ExecuteSql("truncate table WORKFLOW_TEMP"); 10 var para = new OracleParameter("formInfo", OracleType.Clob); 11 para.Value = form.ToSerializableXML(); 12 DbHelperOra.ExecuteSql("insert into WORKFLOW_TEMP(content) values (:formInfo)", para); 13 14 var paras = new[] 15 { 16 new OracleParameter("formId", formId.ToString()), 17 new OracleParameter("formContent", formContent) 18 }; 19 if (DbHelperOra.GetSingle("select count(*) from WORKFLOW_FORM where form_id = :formId", 20 new OracleParameter("formId", formId.ToString())).ToString() == "1") 21 { 22 sql = 23 "update WORKFLOW_FORM set FORM_INFO = (select sys.xmlType.createXML(WORKFLOW_TEMP.content) from WORKFLOW_TEMP), FORM_CONTENT = :formContent where FORM_ID = :formId"; 24 } 25 else 26 { 27 sql = 28 "insert into WORKFLOW_FORM(FORM_ID,FORM_INFO,FORM_CONTENT) values (:formId,(select sys.xmlType.createXML(WORKFLOW_TEMP.content) from WORKFLOW_TEMP),:formContent)"; 29 } 30 31 return DbHelperOra.ExecuteSql(sql, paras).ToString() == "1"; 32 }
读取:
1 public List<Form> GetFormList() 2 { 3 var ds = 4 DbHelperOra.Query( 5 "select t.form_info.getclobval() form_info, form_content from WORKFLOW_FORM t"); 6 if (ds != null) 7 { 8 var forms = new List<Form>(ds.Tables[0].Rows.Count); 9 foreach (DataRow dr in ds.Tables[0].Rows) 10 { 11 var str = dr["form_info"].ToString(); 12 var form = str.ToEntity<Form>(); 13 form.FormContent = dr["form_content"].ToString(); 14 forms.Add(form); 15 } 16 return forms; 17 } 18 return null; 19 }
删除:
1 public bool DeleteForm(Guid formId) 2 { 3 try 4 { 5 if(DbHelperOra.ExecuteSql("delete from WORKFLOW_FORM where form_id = :formid", 6 new OracleParameter("formid", formId.ToString())).ToString(CultureInfo.InvariantCulture)=="1") 7 return true; 8 return false; 9 } 10 catch (Exception ex) 11 { 12 return false; 13 } 14 }
一切都很简单,没有恼人的一列列字段名,也不用ORM、代码生成器等,开发、维护效率大幅度提高。
数据访问类实例化在WorkflowService类里面
先定义私有变量:
private readonly IWorkflowDB _iWorkflowDb;
然后在类的构造函数里这么写:
1 public WorkflowService(IWorkflowDB workflowDb, IWorkflowMethods workflowMethods) 2 { 3 _iWorkflowDb = workflowDb; 4 _iWorkflowMethods = workflowMethods; 5 6 }
使用简单工厂返回类的实例:
1 /// <summary> 2 /// 程序主调用方法 3 /// </summary> 4 /// <returns></returns> 5 public static WorkflowService GetWorkflowService() 6 { 7 IWorkflowDB iWorkflowDb; 8 try 9 { 10 string dbSavingProvider = WorkFlowUtility.GetConfiguration("DataBaseProvider").ToLower(); 11 switch (dbSavingProvider) 12 { 13 case "oracle": 14 iWorkflowDb = new OracleWorkFlowDBUtility(); 15 break; 16 case "sqlserver": 17 //iWorkflowDb = new SqlServerWorkFlowDBUtility(); 18 //break; 19 default: 20 iWorkflowDb = (IWorkflowDB) Assembly.Load(dbSavingProvider).CreateInstance(dbSavingProvider); 21 break; 22 } 23 24 } 25 catch (Exception) 26 { 27 throw new WorkFlowConfigurationNotImplementException("数据库配置失败!"); 28 }
这样能在不同的项目中自由配置数据存储方式了。
如果要提高查询效率,比如报表,就可以这么写查询:
1 select rownum "序号", t.dw "单位",vt.groupname || vs.groupname "团支部",t.xh "学号",t.xm "姓名",t.xb "性别",t.csrq "出生年月", t.zzmm "政治面貌", t.zc "职称", t.gzsj "工作时间", t.lxdh "联系电话" from 2 (select f.instance_id, 3 f.instance_content.extract('//FlowInstance/Creator/@PersonId').getstringval() xh, 4 max(decode(x.key,'c57e4eb1-834c-491f-a1b5-b8b67f1ed160',x.value,null)) dw, 5 max(decode(x.key,'6008c07f-617b-4607-8fe2-6a384c75ea8a',x.value,null)) xm, 6 max(decode(x.key,'1153c641-7567-44ce-85c8-fcb0230d5cf7',x.value,null)) xb, 7 max(decode(x.key,'76936043-17e0-40b7-9adc-22e88d461082',x.value,null)) csrq, 8 max(decode(x.key,'22c6f1c5-d07b-45ba-9752-1118fdafee4c',x.value,null)) zzmm, 9 max(decode(x.key,'47b32ce0-828e-4179-bf11-2ace0028fda5',x.value,null)) zc, 10 max(decode(x.key,'a5cd9229-c8f9-4fb4-ba4f-e8157eeefa04',x.value,null)) gzsj, 11 max(decode(x.key,'9d2984f9-a5c5-474d-807a-cd756b961615',x.value,null)) lxdh 12 from WORKFLOW_FLOW f, 13 XMLTable( '/FlowInstance/FlowStepInstances/FlowInstanceStep/WriteValues/SerializableDictionary' 14 passing f.instance_content 15 COLUMNS key VARCHAR2(40) PATH 'key', 16 value VARCHAR2(100) PATH 'value') x 17 where f.instance_content.extract('//FlowInstance/Flow/@FlowId').getstringval() = 'e2f35ac0-d5aa-4413-af54-2cf4fe3759ef' 18 and to_date(substr(f.instance_content.extract('//FlowInstance/@CreateDate').getstringval(), 0, 10), 'YYYY-MM-DD') 19 between to_date('2015-01-01','yyyy-mm-dd') and to_date('2015-06-01','yyyy-mm-dd') 20 group by f.instance_id, f.instance_content.extract('//FlowInstance/Creator/@PersonId').getstringval()) t 21 left outer join vm_tuanwei_teachergr vt on t.xh = vt.gh 22 left outer join vm_tuanwei_studentgr vs on t.xh = vs.xh
查出来的结果如下图:

好啦,大家对我数据存储方式有什么意见,可以就此进行讨论。
本系列导航:
- .net之工作流工程展示及代码分享(预告)
- .net之工作流工程展示及代码分享(一)工作流表单
- .net之工作流工程展示及代码分享(二)工作流引擎
- .net之工作流工程展示及代码分享(三)数据存储引擎
- .net之工作流工程展示及代码分享(四)主控制类
- .net之工作流工程展示及代码分享(五)前端交互

 浙公网安备 33010602011771号
浙公网安备 33010602011771号