
Hive是一个基于Hadoop的数据仓库,最初由Facebook提供,使用HQL作为查询接口、HDFS作为存储底层、mapReduce作为执行层,设计目的是让SQL技能良好,但Java技能较弱的分析师可以查询海量数据,2008年facebook把Hive项目贡献给Apache。Hive提供了比较完整的SQL功能(本质是将SQL转换为MapReduce),自身最大的缺点就是执行速度慢。Hive有自身的元数据结构描述,可以使用MySql\ProstgreSql\oracle 等关系型数据库来进行存储,但请注意Hive中的所有数据都存储在HDFS中。虽然 hive 可能存在这样那样的问题,但它作为后续研究 sparkSql 的基础,值得重点研究。
解释一下经常遇到的 hiveServer1、hiveServer2 ? 早期版本的 hiveServer(即 hiveServer1)因使用Thrift接口的限制,不能处理多于一个客户端的并发请求,在hive-0.11.0版本中重写了hiveServer代码(即 hiveServer2),支持了多客户端的并发和认证,并且为开放API客户端如JDBC、ODBC提供了更好的支持。
目录:
- hive 架构
- 知识体系
- 数据类型
- Beeline
hive架构:
![]()
- 用户接口主要有三个:CLI(command line interface)命令行,Client 和 Web UI, CLI是开发过程中常用的接口,在 hive Server2提供新的命令beeline,使用sqlline语法,会有单独的章节来介绍
- metaStore: hive 的元数据结构描述信息库,可选用不同的关系型数据库来存储,通过配置文件修改、查看数据库配置信息,如下图(/etc/hive/2.4.2.0-258/0/hive-siet.xml)
![]()
- Driver: 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行
- Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成


知识体系:
- 包含shell命令语法、HiveQl语法、访问方式等,如下图:
![]()

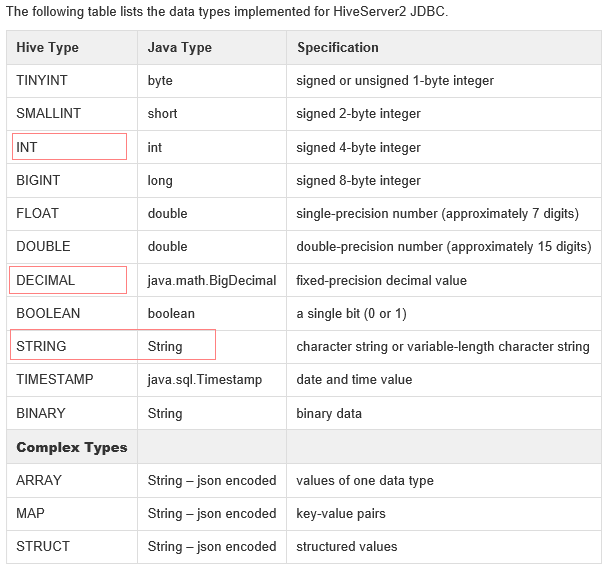
数据类型:
- hiveServer2支持以下数据类型,图片来至 (https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients)
![]()
Beeline:
- HiveServer2提供了一个新的命令行工具Beeline,它是基于SQLLine CLI的JDBC客户端。
- 命令: cd /usr/hdp/2.4.2.0-258/hive/bin (切换至hive安装bin目录), 通过 beeline 命令进入beeline shell
- beeline 启动常用参数说明:
- -u<database URL>: 通过 JDBC 访问数据库的 Url 地址
- -n <username>: 访问数据库的用户名
- -p <password> : 访问数据库密码
- -e <query>:Sql 语句执行参数 beeline -e "query_string"
- -f <file>: sql文件执行参数, beeline -f filepath
- --color=[true/false]:Control whether color is used for display. Default is false
- --help:帮助
- 命令: beeline
- 进入 beeline 命令行后,连接数据库 : !connect jdbc:hive2://localhost:10000/default
- 输入用户名和密码,进入 beeline shell
- sqlline 语法: !quit 退出beeline (不要带分号)
- 多行命令用 ";" 分隔, 注释: “ -- ” (在里面执行的sql语句要带分号)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号