

验证--另一个划分
在每次迭代时,我们都会对训练数据进行训练并评估测试数据,并以基于测试数据的评估结果为指导来选择和更改各种模型超参数,例如学习速率和特征。多次重复执行流程可能导致我们不知不觉地拟合我们的特征测试集的特性。
上一个单元介绍了如何将数据集划分为训练集和测试集。这种划分,您可以对一个样本集进行训练,然后使用不同的样本测试模型。采用两种分类后,工作流程可能如下所示:
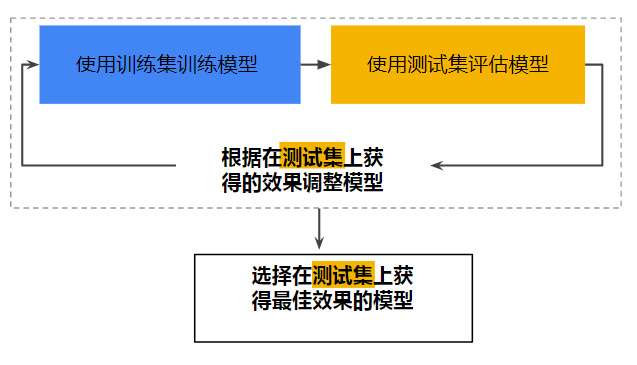
图1 可能的工作流程
在图中,“调整模型”指的是调整您可以想到的关于模型的任何方面,从更改学习速率、添加或移除特征,到从到开始设计新的模型。该工作流程结束时,您可以选择在测试集上获得最佳效果的模型。
将数据集划分为连个子集是个不错的想法,但是并不是万能良方。通过将数据集划分为三个子集(如下图所示),您可以大幅度降低过拟合发生的概率。

图2 将单个数据集划分为三个子集
使用验证集评估训练集的效果。然后,在模型“通过”验证集之后,使用测试集再次检查评估结果。下图展示了这一新的工作流程:
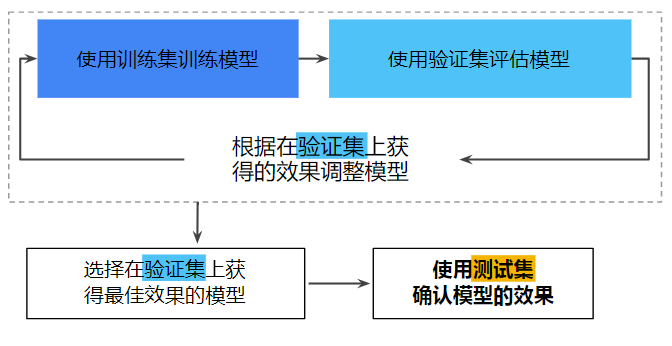
图3 更好的工作流程
在这一经过改进的工作流程中:
- 选择在验证集上获得最佳效果的模型;
- 使用测试集再次检查该模型。
该工作流程之所以更好,原因在于它暴露给测试集的信息更少。
提示
不断使用测试集和验证集会使其逐渐失去效果。也就是说,您使用相同数据来决定超参数设置或其它模型改进的次数越多,您对于这些结果能够真正泛化到未见过的新数据的信心就越低。请注意:验证集的实效速度通常比测试集缓慢。
如果可以的话,建议您收集更多的数据来“刷新”测试集和验证集。重新开始是一种很好的重置方法。

