

js方法encodeURI后,关于get请求url长度的限制测试与总结
(本文仅作个人记录只用比较啰嗦,重点只看红字部分即可)
Test.jsp
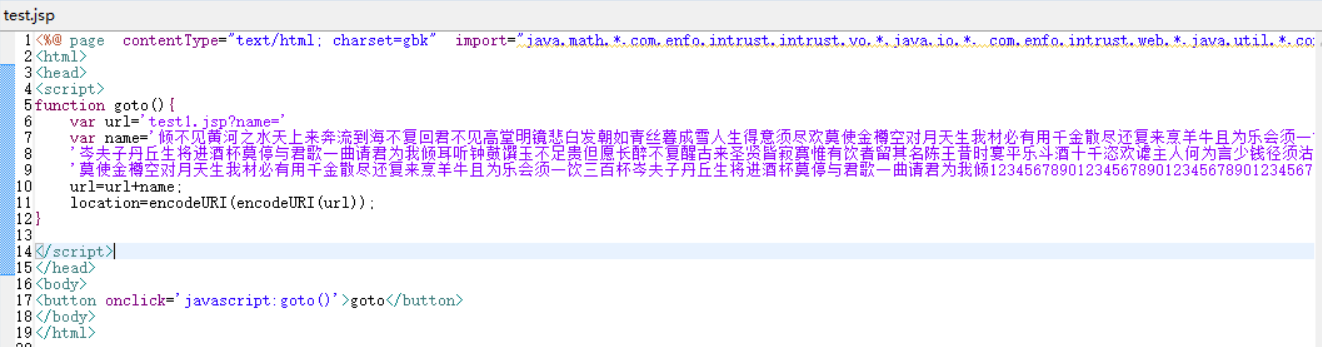
请求test1.jsp
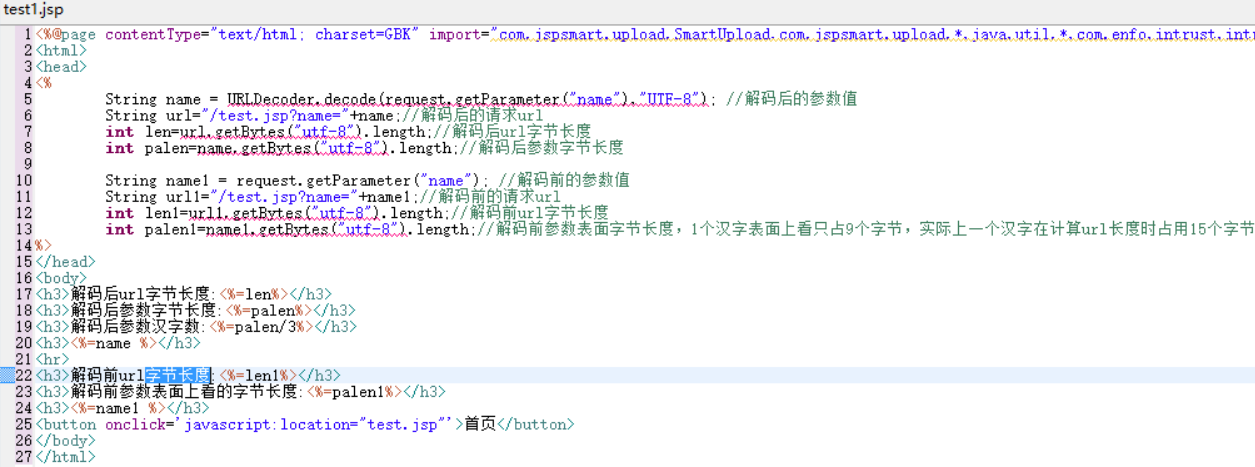
IE11环境下,get请求url最多4096个字节;
请求的是http://localhost:9080/test1.jsp?name=倾不见黄河之水天上来奔流到海不复回君不见高堂明镜悲白发朝如青丝暮成雪……(太长省略)
(君不见黄河之水天上来。。。不要在意这些细节)
经测试:
url计算长度时,对应的字符串是:
/test1.jsp?name=倾不见黄河之水天上来奔流……(太长省略)
关于汉字部分的编码:
通过js中encodeURI后,每一个汉字都进行转换成字符串,如:
“倾“的UTF-8编码是E580BE
encodeURI('倾')后变成:%E5%80%BE
encodeURI(encodeURI('倾'))后变成:%25E5%2580%25BE
即:url中的每一个汉字在encodeURI编码一次后占用成9个字节,在encodeURI编码两次后占用成15个字节!
这样,url前面的/test1.jsp?name=占用16个字节,还剩4096-16=4080个字节可用,换算成汉字就是:4080÷15=272个汉字。
与test1.jsp中取得的name这个参数的值的字节数816,汉字数816÷3=272一致;
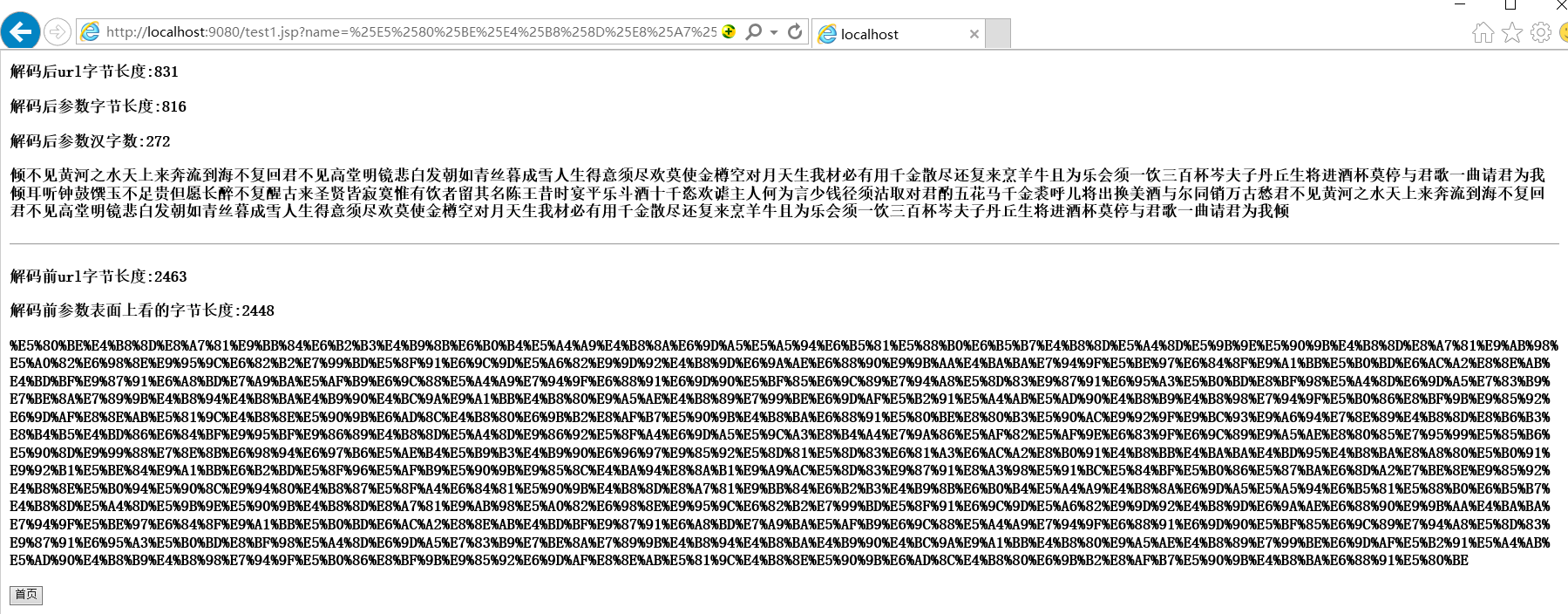
另外:如果通过encodeURI转码导致url超过长度时,有可能最后一个汉字,比如“倾”转码成“%E5%80%BE”时,若url对应长度的4096个字节处于“%E5%80%BE”中间位置时,会发生截断处理,这将会导致“倾”这个汉字在test1.jsp中通过URLDecoder.decode时发生解码异常,所以在ie11下get传参时,url长度尽量不要太接近到4096,要保证最后一个汉字decode后不因为长度截断。
