
dstat,vmstat,dd,iostat,mpstat,sar,free,iopp,iotop,iodump,ethtool,mii-tool;linux性能瓶颈排查;
dstat -cdlmnpsy --tcp 5 --------->每5秒取值( system:int,csw分别为系统的中断次数(interrupt)和上下文切换(context switch)hiq,siq分别为硬中断和软中断次数)
(netstat -anlp|grep LIST|grep -v unix|wc -l)
(mii-tool --verbose em2)
(ethtool em2)
(
lspci|grep -i ether
dmesg |grep -i eth
)
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
top -d 1-------------------->每1秒取值,最活跃的进程
vmstat 2 8----------------->每2秒取值,取8次,关注项有:r,us,id,io(bi,bo)
iostat -x 1 5 --------------->每1秒取值,取5次,关注项有:await,%util
sar 1 6 --------------------->每1秒取值,取6次,关注项有: %iowait
dd if=/dev/sdc of=test bs=64k count=4k oflag=dsync------------->
记录了4096+0 的读入
记录了4096+0 的写出
268435456字节(268 MB)已复制,3.77072 秒,71.2 MB/秒
=================
http://www.wenzizone.cn/?p=416
iostat和iowait[转]
%iowait并不能反应磁盘瓶颈
iowait实际测量的是cpu时间:
%iowait = (cpu idle time)/(all cpu time)
这个文章说明:高速cpu会造成很高的iowait值,但这并不代表磁盘是系统的瓶颈。唯一能说明磁盘是系统瓶颈的方法,就是很高的read/write时间,一般来说超过20ms,就代表了不太正常的磁盘性能。为什么是20ms呢?一般来说,一次读写就是一次寻到+一次旋转延迟+数据传输的时间。由于,现代硬盘数据传输就是几微秒或者几十微秒的事情,远远小于寻道时间2~20ms和旋转延迟4~8ms,所以只计算这两个时间就差不多了,也就是15~20ms。只要大于20ms,就必须考虑是否交给磁盘读写的次数太多,导致磁盘性能降低了。
作者的文章以AIX系统为例,使用其工具filemon来检测磁盘每次读写平均耗时。在Linux下,可以通过iostat命令还查看磁盘性能。其中的svctm一项,反应了磁盘的负载情况,如果该项大于15ms,并且util%接近100%,那就说明,磁盘现在是整个系统性能的瓶颈了。
来自:http://blog.morebits.org/?p=125
iostat来对linux硬盘IO性能进行了解
转载自:扶凯: http://www.php-oa.com/2009/02/03/iostat.html
以前一直不太会用这个参数。现在认真研究了一下iostat,因为刚好有台重要的服务器压力高,所以放上来分析一下.下面这台就是IO有压力过大的服务器
$iostat -x 1
Linux 2.6.33-fukai (fukai-laptop) _i686_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
5.47 0.50 8.96 48.26 0.00 36.82
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 6.00 273.00 99.00 7.00 2240.00 2240.00 42.26 1.12 10.57 7.96 84.40
sdb 0.00 4.00 0.00 350.00 0.00 2068.00 5.91 0.55 1.58 0.54 18.80
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait。
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外 await 的参数也要多和 svctm 来参考。差的过高就一定有 IO 的问题。
avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小.如果数据拿的大,才IO 的数据会高。也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s.也就是讲,读定速度是这个来决定的。
另外还可以参考
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
别人一个不错的例子(I/O 系统 vs. 超市排队)
举一个例子,我们在超市排队 checkout 时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧? 除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了。还有就是收银员的速度了,如果碰上了连 钱都点不清楚的新手,那就有的等了。另外,时机也很重要,可能 5 分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义 (不过我还没发现什么事情比排队还无聊的)。
I/O 系统也和超市排队有很多类似之处:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率 (%util)类似于收款台前有人排队的时间比例。
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间。
下面是别人写的这个参数输出的分析
# iostat -x 1
avg-cpu: %user %nice %sys %idle
16.24 0.00 4.31 79.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/cciss/c0d0 0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
上面的 iostat 输出表明秒有 28.57 次设备 I/O 操作: 总IO(io)/s = r/s(读) +w/s(写) = 1.02+27.55 = 28.57 (次/秒) 其中写操作占了主体 (w:r = 27:1)。
平均每次设备 I/O 操作只需要 5ms 就可以完成,但每个 I/O 请求却需要等上 78ms,为什么? 因为发出的 I/O 请求太多 (每秒钟约 29 个),假设这些请求是同时发出的,那么平均等待时间可以这样计算:
平均等待时间 = 单个 I/O 服务时间 * ( 1 + 2 + … + 请求总数-1) / 请求总数
应用到上面的例子: 平均等待时间 = 5ms * (1+2+…+28)/29 = 70ms,和 iostat 给出的78ms 的平均等待时间很接近。这反过来表明 I/O 是同时发起的。
每秒发出的 I/O 请求很多 (约 29 个),平均队列却不长 (只有 2 个 左右),这表明这 29 个请求的到来并不均匀,大部分时间 I/O 是空闲的。
一秒中有 14.29% 的时间 I/O 队列中是有请求的,也就是说,85.71% 的时间里 I/O 系统无事可做,所有 29 个 I/O 请求都在142毫秒之内处理掉了。
delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s =78.21 * delta(io)/s = 78.21*28.57 = 2232.8,表明每秒内的I/O请求总共需要等待2232.8ms。所以平均队列长度应为 2232.8ms/1000ms = 2.23,而 iostat 给出的平均队列长度 (avgqu-sz) 却为 22.35,为什么?! 因为 iostat 中有 bug,avgqu-sz 值应为 2.23,而不是 22.35。
什么是inode?
来自:http://www.dbconf.net/inode-related-issues.html
inode是Linux/Unix系文件系统[如ext]中的一个概念,当一个文件系统格式化了以后,他一定会有 inode table 与 data area 两个区块。Block 是记录文件内容数据的地区,而 inode 则是记录该文件的属性、及该文件放置在哪一个 Block 之内的信息。而且每个文件至少需要一个inode。
如何查询一个文件系统的inode使用情况:
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sda1 2366400 186064 2180336 8% /
none 63327 1 63326 1% /dev/shm
使用df -i可以看到文件系统的inode总数、使用数、剩余量和使用百分比。
如何查看每个文件系统的inode大小:
[root@gc_server ~]# dumpe2fs -h /dev/sda1|grep node
dumpe2fs 1.35 (28-Feb-2004)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery sparse_super large_file
Inode count: 2366400
Free inodes: 2177496
Inodes per group: 16320
Inode blocks per group: 510
First inode: 11
Inode size: 128
Journal inode: 8
First orphan inode: 150509
Journal backup: inode blocks
定义inode大小:
inode大小决定了一个文件系统中的inode总量,在创建文件系统的时候可以指定inode的大小,创建之后不可修改:
mkfs.ext3 -I 128 /dev/sdb5 //自定inode的大小为128byte
inode会引起什么问题:
可能出现磁盘空闲空间充足的情况下,新建文件时提示磁盘空间满。
inode数量过多由什么引起:
一般是小文件过多,如果一个文件大小比文件系统的块大小还小,如文件系统的block size为4k,而文件只有2k,则有2k的空间被浪费,也就是blocks per inode ratio过小,从而有可能会出现磁盘空间未满,而inode数消耗殆尽的情况。
如何规划:
因为inode大小一般而言略大于block大小为宜,所以:
1、 当 block 越小、inodes 越多,可利用空间越多,但是大文件写入效率较差:适合文件数量多但是文件容量小的系统,例如 BBS 或者新闻群组 news 这方面的服务之系统;
2、 当 block 越大 、 inodes 数越少,大文件写入效率较佳,但浪费的空间较多:适合文件容量大的系统。
IO调度器
IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调度器也被叫做电梯.(elevator)而相应的算法也就被叫做电梯算法.而Linux中IO调度的电梯算法有好几种,一个叫做as(Anticipatory),一个叫做cfq(Complete Fairness Queueing),一个叫做deadline,还有一个叫做noop(No Operation).具体使用哪种算法我们可以在启动的时候通过内核参数elevator来指定.
另一方面我们也可以单独的为某个设备指定它所采用的IO调度算法,这就通过修改在/sys/block/sda/queue/目录下面的scheduler文件.比如我们可以先看一下我的这块硬盘:
[root@localhost ~]# cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq]
可以看到我们这里采用的是cfq.
Linux IO调度器相关算法介绍
IO调度器(IO Scheduler)是操作系统用来决定块设备上IO操作提交顺序的方法。存在的目的有两个,一是提高IO吞吐量,二是降低IO响应时间。然而IO吞吐量和IO响应时间往往是矛盾的,为了尽量平衡这两者,IO调度器提供了多种调度算法来适应不同的IO请求场景。其中,对数据库这种随机读写的场景最有利的算法是DEANLINE。接着我们按照从简单到复杂的顺序,迅速扫一下Linux 2.6内核提供的几种IO调度算法。
1、NOOP
NOOP算法的全写为No Operation。该算法实现了最最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。之所以说“大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,并不是完完全全按照先进先出的规则满足IO请求。
假设有如下的io请求序列:
100,500,101,10,56,1000
NOOP将会按照如下顺序满足:
100(101),500,10,56,1000
2、CFQ
CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
假设有如下的io请求序列:
100,500,101,10,56,1000
CFQ将会按照如下顺序满足:
100,101,500,1000,10,56
在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能被满足,可能会出现饿死的情况。
3、DEADLINE
DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队列内的IO请求优先级要比CFQ队列中的高,,而读FIFO队列的优先级又比写FIFO队列的优先级高。优先级可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
4、ANTICIPATORY
CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足。
IO调度器算法的选择,既取决于硬件特征,也取决于应用场景。
在传统的SAS盘上,CFQ、DEADLINE、ANTICIPATORY都是不错的选择;对于专属的数据库服务器,DEADLINE的吞吐量和响应时间都表现良好。然而在新兴的固态硬盘比如SSD、Fusion IO上,最简单的NOOP反而可能是最好的算法,因为其他三个算法的优化是基于缩短寻道时间的,而固态硬盘没有所谓的寻道时间且IO响应时间非常短。
查看和修改IO调度器的算法非常简单。假设我们要对sda进行操作,如下所示:
cat /sys/block/sda/queue/scheduler
echo “cfq” > /sys/block/sda/queue/scheduler
来自:http://www.sar4.com/2011/02/25/iostat%E5%92%8Ciowait.html
=============
http://www.centoscn.com/CentOS/2014/0827/3586.html
http://lhflinux.blog.51cto.com/1961662/518868
执行 dstat 命令的时候,默认他会 收集-cpu-、-disk-、-net-、-paging-、-system-的数据,一秒钟收集一次。默认输入 dstat 等于输入了dstat -cdngy 1或dstat -a 1;
在1024×768的屏幕上正好全部显示出来
别名 alias dstat='dstat -cdlmnpsy'
http://opsmysql.blog.51cto.com/2238445/1202135
使用说明
1.使用语法
dstat [-afv][options..] [delay [count]]
简单执行 dstat 命令:

在不带任务参数的情况它只会collectlcpu、disk、net、paging、system这些数据, 默认是 1s 收集一次. 默认输入dstat等于输入了dstat -cdngy 1或dstat-a 1.
2.dstat 使用参数
-c, -cpu 显示CPU情况
-C 0,3,totalinclude cpu0, cpu3 and total
-d, -disk 显示磁盘情况
-D total,hdainclude hda and total
-g, -page enable pagestats
-i, -int enableinterrupt stats
-I 5,eth2 includeint5 and interrupt used by eth2
-l, -load enable loadstats
-m, -mem 显示内存情况
-n, -net 显示网络情况
-N eth1,total 可以指定网络接口
-p, -proc enableprocess stats
-s, -swap 显示swap情况
-S swap1,total 可以指定多个swap
-t, -time enable timecounter
-y, -sys enablesystem stats
-ipc 报告IPC消息队列和信号量的使用情况
-lock enable lockstats
-raw enable raw stats
-tcp enable tcp stats
-udp enable udp stats
-unix enable unixstats
-M stat1,stat2 enableexternal stats
-mods stat1,stat2
-a, -all 使用-cdngy 缺省的就是这样显示
-f, -full 使用 -C, -D, -I, -N and -S 显示
-v, -vmstat 使用-pmgdsc -D 显示
-integer show integervalues
-nocolor disablecolors (implies -noupdate)
-noheaders 只显示一次表头以后就不显示了,使用重定向写入文件时很有用
-noupdate disableintermediate updates
-output file 写入到CVS文件中
上面这些参数大多都容易理解,会点英文的同志都能看懂...........................
3. 实例
实例1: dstat sda -D3 5 #在默认显示内容的基础上只显示sda磁盘的信息
这里的 3 5 意思跟vmstat3 5 一样,意思就是每隔3秒更新一次,总共更新5次,但是这里有个小区别就是初使时要显示一次,不包括在内!

实例2:dstat-cdlmnpsy #统计显示CPU,IO,load,memory,network,process,swap,system

实例3 :date&& dstat -tclmdny 10 #10秒监视一次


实例4:dstat -cdlmnyp-N total -D total 3 5

相关各模块显示内容跟top、vmstat、iostat等这些工具的意思相同,如cpu相关的usr代表应用空间也就是应用程序所占用的百分比,注意这里也是百分比,sys表示系统内核空间占用的百分比,idl表示CPU空闲情况,wai表示IO等待数,hiq和sig则显示服务中断有关信息。
其它就不再一一说明,都相对简单!
OK,只简单介绍到这里,这工具应用起来还算比较简单,显示也很直观。工具的使用还需靠平时多去练习、观察才能熟能生巧!
参考站点:http://wiki.51osos.com/index.php?title=Dstat&printable=yes
http://dag.wieers.com/home-made/dstat
=====================================
http://10lover10.blog.51cto.com/6266102/1087731
很多服务端开发的同事和新手运维都来和我讨论过如何诊断linux系统的性能瓶颈,今天统一说明。
查找瓶颈有一个基本的流程,不外乎借助系统工具来给系统做一个全面的检查,最后根据结果来确定问题出在哪方面。
基本流程:
1、使用top查看系统的总体运行情况;
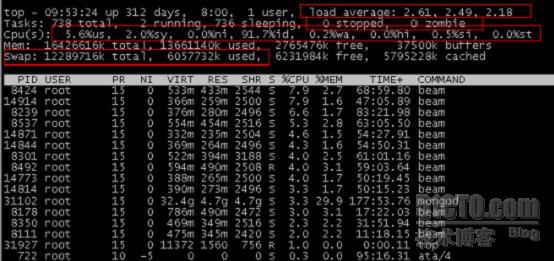
Top的输出结果那些是很有用的信息呢?我已经全部用红线框起来了,具体如下:
:load average 这行表示系统最近1分钟,5分钟,15分钟的平均负载。那么怎样的负载才是可以接受的呢?有个简单的办法,在top命令中,再按‘1’键,会列出系统使用的cpu的数量,以负载的值不要超过cpu数量最合适。
:Tasks 这行反应的是当前系统的任务状态,主要看running和zombie进程的数量,一个健康的系统zombie(僵死进程)的数量一定是为0的,否则肯定系统已经出不小的问题了。
:Cpu(s)这行反应当前cpu的工作状态,us表示用户进程占整个cpu运行时间的百分比,sy表示系统进程的占用时间百分比;id表示cpu当前的空闲时间百分比,wa表示等待时间百分比,这几个概念是最重要的。下面有个实际的列子会再详细分析。
:Mem这行反应当前系统内存使用状况
:Swap 这行就是系统交换分区使用状态,一个性能优越的系统,交换分区使用量一定是为0的,交换分区只是一种应对在系统内存不足时的一种紧急机制,用到交换分区,说明可以考虑增加内存或者裁减现有内存数据大小了。毕竟交换分区就是硬盘,速度和内存差了太多。
2、看硬盘容量,硬盘容量如果爆满的话,那么什么诡异的情况都可能出现,这个已经非常危急了,具体的命令:df;

3、看带宽;这里如果细分的话就复杂了,比如是否有网络攻击,封包数量和特征是否异常等,zabbix是其中的佼佼者,这里我们只要看目前的带宽有没有接近网卡的上限,命令: dstat -n;
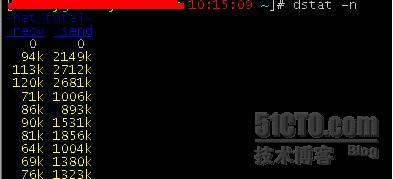
这台机器是千兆网卡,现在最大才跑到2.7mbyte/s *8 ~ 20mbit/s,远远没到,带宽这个很少有机会用到网卡峰值的80%左右,但是在业务繁忙的时候,这个也是非常重要的监控对象。
4、一个具体的实例。昨天一个新同学说应用很卡,延迟较大。内存还有很多不使用,就如上面top图显示那样,还有接近3G可以使用的内存。我等录上去看了看,使用vmstat:
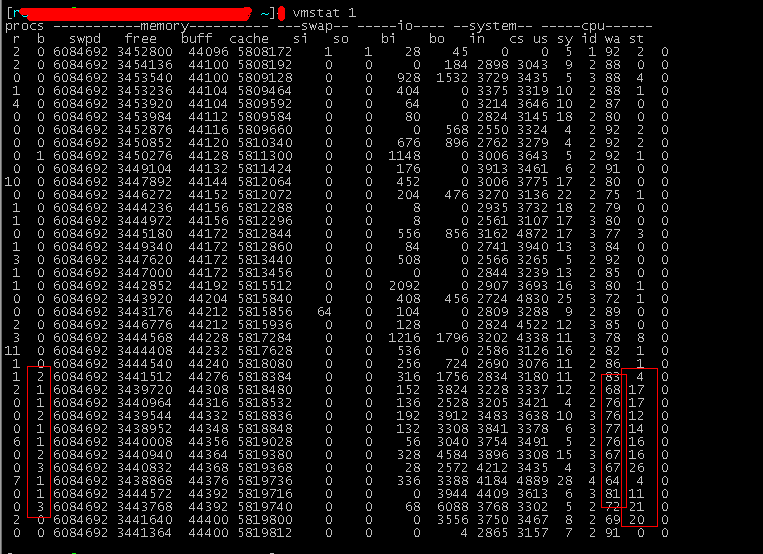
可以看到过段时间就会发现有些进程处于阻塞状态,原因内是因为cpu处于等待的时间变长了,cpu是空闲的很,等着进程进来运算,而进程迟迟没有到达,这个肯定就是数据在交换分区了,存取太慢导致的卡和延迟,后来关闭了交换分区,并且整理内存之后,一切就正常了。
一个初步的系统性能诊断按照基本流程就几步,只是开始接触linux的同学不知道按照一个流程来操作。所以需要多看多动手。当然现在监控软件很多,可以监控的性能指标也很多。
本文出自 “时乘六龙” 博客,请务必保留此出处http://10lover10.blog.51cto.com/6266102/1087731
===========================
http://www.ha97.com/4512.html
一、前言
很显然从名字中我们就可以知道vmstat是一个查看虚拟内存(Virtual Memory)使用状况的工具,但是怎样通过vmstat来发现系统中的瓶颈呢?在回答这个问题前,还是让我们回顾一下Linux中关于虚拟内存相关内容。
二、虚拟内存原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
三、vmstat详解
1.用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
2.使用说明
例子1:每3秒输出一条结果

字段说明:
Procs(进程):
r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1)
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
注意:如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
free: 空闲物理内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
注意:如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap:
si: 每秒从交换区写到内存的大小,由磁盘调入内存
so: 每秒写入交换区的内存大小,由内存调入磁盘
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
IO:(现在的Linux版本块的大小为1kb)
bi: 每秒读取的块数
bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示):
us: 用户进程执行时间百分比(user time)
注意: us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 内核系统进程执行时间百分比(system time)
注意:sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa: IO等待时间百分比
注意:wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
id: 空闲时间百分比
例子2:显示活跃和非活跃内存

使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
字段说明:
Memory(内存):
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
总结:
目前说来,对于服务器监控有用处的度量主要有:
r(运行队列)
pi(页导入)
us(用户CPU)
sy(系统CPU)
id(空闲)
注意:如果r经常大于4 ,且id经常少于40,表示cpu的负荷很重。如果bi,bo 长期不等于0,表示内存不足。
通过VMSTAT识别CPU瓶颈:
r(运行队列)展示了正在执行和等待CPU资源的任务个数。当这个值超过了CPU数目,就会出现CPU瓶颈了。
Linux下查看CPU核心数的命令:cat /proc/cpuinfo|grep processor|wc -l
当r值超过了CPU个数,就会出现CPU瓶颈,解决办法大体几种:
1. 最简单的就是增加CPU个数和核数
2. 通过调整任务执行时间,如大任务放到系统不繁忙的情况下进行执行,进尔平衡系统任务
3. 调整已有任务的优先级
通过vmstat识别CPU满负荷:
首先需要声明一点的是,vmstat中CPU的度量是百分比的。当us+sy的值接近100的时候,表示CPU正在接近满负荷工作。但要注意的是,CPU 满负荷工作并不能说明什么,Linux总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化。唯一能够确定CPU瓶颈的还是r(运行队列)的值。
通过vmstat识别RAM瓶颈:
数据库服务器都只有有限的RAM,出现内存争用现象是Oracle的常见问题。
首先用free查看RAM的数量:
[oracle@oracle-db02 ~]$ free
total used free shared buffers cached
Mem: 2074924 2071112 3812 0 40616 1598656
-/+ buffers/cache: 431840 1643084
Swap: 3068404 195804 2872600
当内存的需求大于RAM的数量,服务器启动了虚拟内存机制,通过虚拟内存,可以将RAM段移到SWAP DISK的特殊磁盘段上,这样会 出现虚拟内存的页导出和页导入现象,页导出并不能说明RAM瓶颈,虚拟内存系统经常会对内存段进行页导出,但页导入操作就表明了服务器需要更多的内存了, 页导入需要从SWAP DISK上将内存段复制回RAM,导致服务器速度变慢。
解决的办法有几种:
1. 最简单的,加大RAM;
2. 改小SGA,使得对RAM需求减少;
3. 减少RAM的需求。(如:减少PGA)
参考文档,本人做了相关修改和说明:
http://hi.baidu.com/imlidapeng/blog/item/51872329329ab8335243c1c9.html
http://qa.taobao.com/?p=2269
==================================
http://www.ctohome.com/FuWuQi/cf/659.html
vmstat下表io下面的bi表示读取和bo表示写入,单位是block(硬盘读写的最小单位是扇区,一个扇区是512 bytes。一次硬盘读写的数据量不会超过512 bytes,这一次读写的数据量就称为1个block。在大文件的读写操作中,基本可以按乘512来根据block计算出读写的实际数据量,误差很小。)cpu下面的wa,这个wa就是wait的缩写,代表的意思是CPU在等待硬盘读写操作的时间,用百分比表示。wait越大则机器io性能就越差。 -------------------------------------------------- 关于bo和bi,到底是读还是写,也许你会看到完全相反的2种解释。这是某些理解错误导致的。正确做法,是你自己测试下。首先vmstat 1 1000运行起来,观察下bo和bi, 然后再开一个ssh窗口,运行 du -sh / 这个命令来读取输出各个目录的大小。这里几乎没有写入操作,然后你看看你的bi或bo是否有变化,对CTOHOME的服务器测试结果,明显,bi变大,说明bi是读文件
首先可以通过看硬盘型号,大致判断硬盘是什么级别的。比如你不能拿企业级的硬盘和 家用PC的普通硬盘比,这样比是没有价值的。VPS也是没有测试的必要,因为VPS的性能取决于整个服务器性能,比如一个低配服务器开5个vps,和一个高配服务器开30个vps,这是没有对比性的。 独立服务器检测硬盘性能如下,通过dd命令和vmstat命令,仅供技术员墨迹:
DD大致检测: dd if=/dev/zero of=test bs=64k count=4k oflag=dsync
几个独立服务器的硬盘dd结果参考(注意,dd只有在服务器完全空闲的情况下对比才有意义。如果一个服务器跑了很多应用,一个服务器空闲,那么对比结果是没有任何意义的):
Vendor: ATA Model: WDC WD5000AAKX-0 Rev: 15.0
[root@host640.ctohome.com]# dd if=/dev/zero of=test bs=64k count=4k oflag=dsync
4096+0 records in
4096+0 records out
268435456 bytes (268 MB) copied, 7.05519 seconds, 38.0 MB/s
Vendor: ATA Model: WDC WD2002FYPS-0 Rev: 04.0
[root@host30.ctohome.com]# dd if=/dev/zero of=test bs=64k count=4k oflag=dsync
4096+0 records in
4096+0 records out
268435456 bytes (268 MB) copied, 4.96645 seconds, 54.0 MB/s
Vendor: WDC Model: WD1002FAEX-0 Rev: 05.0 RAID10
[root@host650.ctohome.com]# dd if=/dev/zero of=test bs=64k count=4k oflag=dsync
4096+0 records in
4096+0 records out
268435456 bytes (268 MB) copied, 2.05799 seconds, 130 MB/s
IO wait 参考:
vmstat下表io下面的bi表示读取和bo表示写入,单位是block(硬盘读写的最小单位是扇区,一个扇区是512 bytes。一次硬盘读写的数据量不会超过512 bytes,这一次读写的数据量就称为1个block。在大文件的读写操作中,基本可以按乘512来根据block计算出读写的实际数据量,误差很小。)cpu下面的wa,这个wa就是wait的缩写,代表的意思是CPU在等待硬盘读写操作的时间,用百分比表示。wait越大则机器io性能就越差。
[root@host30.ctohome.com]# man vmstat | grep 'block device'
bi: Blocks received from a block device (blocks/s). 读
bo: Blocks sent to a block device (blocks/s). 写
CTOHOME提醒:关于bo和bi,到底是读还是写,也许你会看到完全相反的2种解释。这是某些理解错误导致的。正确做法,是你自己测试下。首先vmstat 1 1000运行起来,观察下bo和bi, 然后再开一个ssh窗口,运行 du -sh / 这个命令来读取输出各个目录的大小。这里几乎没有写入操作,然后你看看你的bi或bo是否有变化,对CTOHOME的服务器测试结果,明显,bi变大,说明bi是读文件。
vmstat 1 1000
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
5 1 9504 230360 593980 12154304 0 0 24 1316 3170 7063 15 2 83 1 0
3 2 9504 226840 594016 12156884 0 0 180 0 3403 5827 18 3 76 3 0
2 0 9504 238936 594076 12157364 0 0 108 16 3634 2834 17 3 76 4 0
2 0 9504 246568 594084 12157356 0 0 172 0 3315 7355 12 2 84 1 0
3 0 9504 246072 594092 12157400 0 0 12 0 3489 5299 18 2 80 1 0
5 1 9504 246128 594100 12157828 0 0 60 3800 3430 2577 18 3 78 1 0
3 0 9504 243936 594164 12158428 0 0 984 2220 3624 12936 23 3 71 3 0
1 0 9504 249004 594168 12158424 0 0 4 0 3222 2282 12 2 86 0 0
0 0 9504 249192 594208 12158468 0 0 76 2060 3762 5611 9 2 88 1 0
0 0 9504 248256 594216 12158460 0 0 92 0 3471 7062 7 1 90 1 0
3 1 9504 233860 594232 12158880 0 0 144 0 3371 8783 15 2 81 2 0
1 0 9504 232720 594236 12158876 0 0 180 24 3648 19296 33 4 61 3 0
5 0 9504 228440 594260 12159408 0 0 36 0 3589 5185 18 2 79 2 0
4 0 9504 245836 594280 12159824 0 0 264 2820 3743 17055 25 5 67 2 0
2 0 9504 232392 594292 12159816 0 0 92 0 3799 4387 17 3 79 1 0
0 0 9504 248092 594324 12159784 0 0 116 1448 3395 2450 4 2 92 2 0
0 3 9504 241272 594336 12159896 0 0 4 3364 3828 3339 6 1 68 26 0
1 5 9504 245452 594360 12159872 0 0 608 1804 3851 7458 5 2 59 34 0
1 2 9504 246452 594396 12159872 0 0 20 848 3176 3440 1 1 62 36 0
4 2 9504 245352 594488 12160652 0 0 992 1012 3725 9925 16 2 54 28 0
1 0 9504 239124 594504 12161668 0 0 96 4 3283 10042 19 2 77 2 0
0 0 9504 246200 594508 12161664 0 0 0 1716 3707 2144 1 1 98 0 0
1 0 9504 229088 594508 12161664 0 0 16 0 3438 2846 12 3 84 1 0
vmstat 1 1000
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 217284 116704 397428 0 0 1244 327 80 272 0 0 99 1 0
0 0 0 216424 116716 397416 0 0 8 272 366 1717 0 0 99 0 0
0 0 0 216424 116716 397436 0 0 0 0 310 1590 0 0 100 0 0
0 0 0 216424 116736 397416 0 0 12 420 340 1841 0 0 100 0 0
0 0 0 216424 116744 397436 0 0 4 120 318 1684 0 0 100 0 0
0 0 0 216424 116744 397436 0 0 0 0 302 1612 0 0 100 0 0
0 0 0 216424 116756 397424 0 0 8 96 315 1667 0 0 100 0 0
0 0 0 216424 116756 397424 0 0 0 0 305 1603 0 0 100 0 0
0 0 0 216424 116760 397432 0 0 4 184 323 1738 0 0 100 0 0
0 0 0 216424 116760 397432 0 0 0 168 314 1702 0 0 100 0 0
0 0 0 216432 116764 397432 0 0 4 0 306 1636 0 0 100 0 0
0 0 0 216432 116776 397420 0 0 8 96 314 1634 0 0 100 0 0
.....
http://lihuipeng.blog.51cto.com/3064864/1183732
vmstat参数:
-bo 磁盘写的数据量大
-us 持续大于50,服务器高峰可以接受
-wa IO等待,持续大于30,说明IO等待严重
-id 持续小于50,服务器高峰可以接受
▶ CPU使用率【CPU Utilization】
这可能是最直接的指标了,它表示每个处理器的整体使用率。在IBM System x架构中,如果在持续一段时间里CPU使用率超过80%,就可能预示着CPU出现了瓶颈。
▶ 用户时间【User Time】
表示用户进程所花费的CPU百分比,包括Nice时间。在用户时间值很高的情况下,表明系统正在执行实际的工作。
▶ 系统时间【System Time】
表示内核操作所花费的CPU百分比,包括硬中断【IRQ】和软中断[SoftIRQ]。系统时间值持续很高表明网络或驱动器堆栈可能存在瓶颈。通常系统只花费很少时间在内核时间上。
▶ 等待【Waiting】
花费在等待I/O操作所需的CPU时间总和,与阻塞【Blocked】值相似,系统不应该花费过多的时间等待I/O操作;否则你应该检查一下I/O子系统各方面性能。
▶ 空闲时间【Idle time】
表示CPU空闲的百分比。
▶ Nice时间【Nice time】
表示花费在执行re-nicing(改变进程的执行顺序和优先级)进程的CPU百分比。
▶ 平均负载【Load average】
平均负载不是百分比,它是下面数值之和的平均值:
– 队列中等待执行的进程数
– 等待不可中断任务执行完成的进程数。
也就是TASK_RUNNING和TASK_UNINTERRUPTIBLE之和的平均值。如果请求CPU时间的进程发生阻塞(),平均负载将会上升。相反如果每个进程都可以立即执行不会错过CPU周期,平均负载就会降低。
▶ 可运行进程【Runable processes】
这个值表示准备执行的进程。这个值在持续一段时间按内应该不会超过物理处理器数量的10倍,否则CPU可能存在瓶颈。
▶ 堵塞【Blocked】
在等待I/O操作完成前,进程是不能继续执行。进程堵塞可能意味着I/O存在瓶颈。
▶ 上下文交换【Context switch】
系统中进程之间进行交换的数量。上下文交换次数过多与大量的中断有关,这可能暗示着驱动器或应用程序存在问题。通常是不需要上下文交换的,因为每次只需要刷新CPU缓存,但有些上下文交换是必要的。
▶ 中断【Interrupts】
中断数量中包括硬中断和软中断。硬中断会对系统性能产生非常不利的影响。高中断值表明软件存在瓶颈,可能是内核或者驱动。请记住中断值中也包括CPU始终所导致的中断。内存的性能指标。
▶ 空闲内存【Free memory】
与其它操作系统相比,不必过分在意空闲内存值。正如1.2.2“虚拟内存管理”所述,Linux内核将大量未使用的内存分配作为文件系统缓存使用,所以在已用内存扣除用于缓冲和缓存的数量得到实际空闲内存。
▶ 交换空间使用【Swap usage】
这个值表示已使用的交换空间数量。正如1.2.2“虚拟内存管理”所述,交换空间的使用只能告诉你Linux在管理内存上是多么有效。要想确定内存是否存在瓶颈,Swap In/Out的数量才以为着用来。如果Swap In/Out长时间保持在每秒钟超过200到300页以上可能表示内存存在瓶颈。
▶ 缓冲与缓存【Buffer and cache】
被用来作为文件系统和块设备的缓存
▶ Slabs
表示内核所使用的内存。注意内核的页是不能被交换到硬盘上的。
▶ 活动与非活动内存【Active versus inactive memory】
提供关于活动内存的相关信息。非活动内存会作为候选被kswapd交换到硬盘。参见“页帧回收”网络的性能指标。
▶ 已收到和已传送的封包【Packets received and sent】
这个指标能告诉你特定网卡已收到和已发送的封包数量
▶ 已收到和已传送的字节【Bytes received and sent】
这个值表示特定网卡已收到和已发送的字节数量。
▶ 每秒钟冲突数【Collisions per second】
这个值提供发生在指定网卡的网络冲突的数量。持续出现冲突值表示在网络架构中存在瓶颈而不是服务器。在大多数正确配置网络中,冲突时非常罕见的,除非网络架构是由hub组成的。
▶ 丢弃的封包【Packets dropped】
被内核丢弃的封包数,原因可能是防火墙配置问题或缺乏网络缓冲
▶ Overruns
Overruns表示超出网络接口缓冲的次数。这个指标可以与丢弃的封包数量配合来确定瓶颈是出自网络缓冲还是网络队列长度。
▶ 错误【Errors】
被标示为失败的帧的数量。这经常是由于网络不匹配或部分网线损坏引起的。对于铜缆千兆网部分网线损坏会产生严重的性能问题。块设备的性能指标。
▶ IO等待【Iowait】
CPU在等待I/O操作发生所花费的时间。如果这个值持续很高,很可能表示I/O存在瓶颈。
▶ 队列平均长度【Average queue length】
I/O请求的数量。通常硬盘队列值在2到3为最佳;过高可能表示硬盘I/O存在瓶颈。
▶ 平均等待时间【Average wait】
I/O请求服务所花费的平均时间。等待时间包括实际I/O操作的时间和在I/O队列中等待的时间。单位为毫秒ms。
▶ 每秒钟传输的数量【Transfers per second】
表示每秒钟执行了多少次I/O操作(包括读取和写入)。与每秒钟传输字节数【kBytes per second】结合可以帮助确定系统平均传输大小。平均传输大小通常要与硬盘子系统的条带大小一致。
▶ 每秒钟读写块的数量【Blocks read/write per second】
这个指标表示每秒钟读写块的数量,在2.6内核中块的大小为1024字节,早期的内核可以有不同的块大小,从512字节到4KB。
▶ 每秒钟读写字节的数量【Kilobytes per second read/write】
表示块设备读写的实际数据的数量,单位为KB。
=========================
http://blog.163.com/xychenbaihu@yeah/blog/static/13222965520123724410678
linux性能分析及调优__cpu 性能瓶颈调优可调性能参数 、内存性能瓶颈可调性能参数(操作系统设置swap的目的、在写程序时、如何使自己的内存不被换出swap,常驻物理内存)、磁盘I/O可调性能参数(如何判断磁盘IO瓶颈,使用iostat -x 1)、网络可调性能参数
2012-04-07 02:44:10| 分类: Linux高性能开发|举报|字号 订阅
计算机中,cpu是最重要的一个子系统,负责所有计算任务;
基于摩尔定律的发展,cpu是发展最快的一个硬件,所以瓶颈很少出现在cpu上;
我们线上环境的cpu都是多核的,并且基于SMP(symmetric multiprocessing)结构的。
通过观察线上机器cpu使用率会发现,使用率很低很低,不到5%; 说明我们的资源浪费情况多么严重啊;(但为什么不能一台机器多部署几个应用呢,后边我会解释); 我们线上的cpu一个核支持超级线程,也就是一个核上可以并行运行几个线程)
机器CPU使用情况监控:
1、良好状态指标
CPU利用率:User Time <= 70%,System Time <= 35%,User Time + System Time <= 70%。
上下文切换: 与CPU利用率相关联,如果CPU利用率状态良好,大量的上下文切换也是可以接受的。
可运行队列: 每个处理器的可运行队列<=3个线程。
2、监控工具 vmstat
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
14 0 140 2904316 341912 3952308 0 0 0 460 1106 9593 36 64 1 0 0
17 0 140 2903492 341912 3951780 0 0 0 0 1037 9614 35 65 1 0 0
20 0 140 2902016 341912 3952000 0 0 0 0 1046 9739 35 64 1 0 0
17 0 140 2903904 341912 3951888 0 0 0 76 1044 9879 37 63 0 0 0
16 0 140 2904580 341912 3952108 0 0 0 0 1055 9808 34 65 1 0 0
重要参数:
r, run queue, 可运行队列的线程数,这些线程都是可运行状态,只不过CPU暂时不可用;
一般要求小于CPU*3的数量。
cat /proc/stat 可以看到有几个CPU。
b,被blocked的进程数,正在等待IO请求;
in,interrupts,被处理过的中断数
cs,context switch,系统上正在做上下文切换的数目
us,用户占用CPU的百分比
sys,内核和中断占用CPU的百分比
id,CPU完全空闲的百分比
上例可得:
sy高us低,以及高频度的上下文切换(cs),说明应用程序进行了大量的系统调用;
这台4核机器的r应该在12个以内,现在r在14个线程以上,此时CPU负荷很重。
一般我们认为,如果是4核机器,r高于8是,应该就是负载很高了。
可调优性能参数:
1、 通过调整进程优先级调整: nice 命令来调整进程优先级别;可调范围(-20到 19) 如: renice 5 pid
2、 通过调整cpu的亲和度来集中处理某一个中断类型:(比如网卡中断)
将系统发出的中断都绑定在一个cpu上,这样其他cpu继续执行自己正在执行的线程,不被中断打扰,从而较少了线程上下文切换时间,增强性能;
注: cpu亲和度的概念: 在多核cpu中,linux操作系统抢占式调度系统,按照cpu时间片/中断/等不断调度进程给cpu去执行的;
如果在一个时间片调度线程1在cpu1上运行,另外一个时间片调度线程1在cpu2上去运行,这样会造成线程执行速度慢,性能降低。
为什么呢?
我们知道SMP上多核都是共享L1 ,L2 CPU Cache的。并且各个核的内存空间都是不可共享的,一个线程如果多次时间片上在不同的cpu上运行,会造成cache的不断失效和写入,性能会降低;
而linux的进程调度有个亲和度算法可以将尽量将进程每次都调度到同一个cpu上处理;
linux调度时当然也有Loadbalance算法保证进程调度的均匀负载的;
例如: echo 03 > /proc/irq/19/smp-affinity (将中断类型为19的中断绑定到第三个cpu上处理)
第二节:内存性能瓶颈
首先,linux的内存管理是聪明和智能的;
linux通过(virtual memory manage)来管理内存的; 对于大多数应用,linux是不直接写到硬盘上去的,而是先写到 virtual memory manage 管理的文件系统缓存(也在内存中的)里 ,方便应用的后续的读请求;因为和磁盘的I/O操作是昂贵的;linux会根据一些算法策略适当的时候同步到硬盘的;这就是为什么我们运行linux一段时间后,发现可用内存那么少的原因,多数被cache+buffer占用咧;
所以我们提高性能的办法就是减少写到磁盘的次数,提高每次写磁盘时的效率质量;
机器内存使用情况监控:
1、良好状态指标
swap in (si) == 0,swap out (so) == 0
应用程序可用内存/系统物理内存 <= 70%
2、监控工具 vmstat
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 3 252696 2432 268 7148 3604 2368 3608 2372 288 288 0 0 21 78 1
0 2 253484 2216 228 7104 5368 2976 5372 3036 930 519 0 0 0 100 0
0 1 259252 2616 128 6148 19784 18712 19784 18712 3821 1853 0 1 3 95 1
1 2 260008 2188 144 6824 11824 2584 12664 2584 1347 1174 14 0 0 86 0
2 1 262140 2964 128 5852 24912 17304 24952 17304 4737 2341 86 10 0 0 4
重要参数:
swpd, 已使用的 SWAP 空间大小,KB 为单位;
free, 可用的物理内存大小,KB 为单位;
buff, 物理内存用来缓存读写操作的buffer大小,KB 为单位;
cache, 物理内存用来缓存进程地址空间的 cache 大小,KB 为单位;
si, 数据从 SWAP 读取到 RAM(swap in)的大小,KB 为单位;
so, 数据从 RAM 写到 SWAP(swap out)的大小,KB 为单位。
上例可得:
物理可用内存 free 基本没什么显著变化,swapd逐步增加,说明最小可用的内存始终保持在 256MB(物理内存大小) * 10% = 2.56MB 左右,当脏页达到10%的时候就开始大量使用swap。
这个10%来自" /proc/sys/vm/dirty_background_ratio "。
可调优性能参数:
1.、通过调节缓存的脏数据同步到硬盘的策略:(脏数据表示没有被当前的线程使用的数据)
例如: echo 10 > /proc/sys/vm/dirty_background_ratio (当脏数据占据物理内存10%时,触发pdflush同步到硬盘):
小心调节,会大幅度的影响性能;
echo 2000 > /proc/sys/vm/dirty_expire_centisecs (当脏数据在物理内存的逗留时间超过2000ms时被同步到硬盘);
2、通过调节swap参数,来优化linux虚拟内存管理:基于程序的局部性原理,linux通过虚拟内存机制来实现并发运行进程,linux发现物理内存不够用时,会根据LRU算法将一部分内存swap out到硬盘;当运行被换出的那个线程时,在swap in 到内存里;
例如: echo 10 > /proc/sys/vm/swappiness (值为0表示尽量都用物理内存,值为100表示积极的使用swap分区;)这个参数很重要;小心调节; 一般为60; ##在紧急处理线上问题时,可以紧急使用一下。
更多的参数:

一、操作系统设置swap的目的
程序运行的一个必要条件就是足够的内存,而内存往往是系统里面比较紧张的一种资源。为了满足更多程序的要求,操作系统虚拟了一部分内存地址,并将之映射到swap上。对于程序来说,它只知道操作系统给自己分配了内存地址,但并不清楚这些内存地址到底映射到物理内存还是swap。物理内存和swap在功能上是一样的,只是因为物理存储元件的不同(内存和磁盘),性能上有很大的差别。操作系统会根据程序使用内存的特点进行换入和换出,尽可能地把物理内存留给最需要它的程序。但是这种调度是按照预先设定的某种规则的,并不能完全符合程序的需要。
一些特殊的程序(比如MySQL)希望自己的数据永远寄存在物理内存里,以便提供更高的性能。于是操作系统就设置了几个api,以便为调用者提供“特殊服务”。
二、Linux提供的几个api
1、mlockall()和munlockall()
这一对函数,可以让调用者的地址空间常驻物理内存,也可以在需要的时候将此特权取消。mlockall()的flag位可以是MCL_CURRENT和MCL_FUTURE的任意组合,分别代表了“保持已分配的地址空间常驻物理内存”和“保持未来分配的地址空间常驻物理内存”。对于Linux来说,这对函数是非常霸道的,只有root用户才有权限调用。
2、shmget()和shmat()
这一对函数,可以向操作系统申请使用大页内存(Large Page)。大页内存的特点是预分配和永驻物理内存,因为使用了共享内存段的方式,page table有可能会比传统的小页分配方式更小。
对于多进程共享内存的程序(比如ORACLE),大页内存能够节省很多page table开销;
而对于MySQL来说,性能和资源开销都没有显著变化,好处就在于减少了内存地址被映射到swap上的可能。至于为什么是减少,而不是完全避免,之后再讲解。
3、O_DIRECT和posix_memalign()
以上两个方法都不会减少内存的使用量,调用者的本意是获取更高的系统特权,而不是节约系统资源。
O_DIRECT是一种更加理想化的方式,通过避免double buffer,节省了文件系统cache的开销,最终减少swap的使用率。O_DIRECT是Linux IO调度相关的标志,在open函数里面调用。通过O_DIRECT标志打开的文件,读写都不会用到文件系统的cache。
传统的数据库(ORACLE、MySQL)基本都有O_DIRECT相关的开关,在提高性能的同时,也减少了内存的使用。至于posix_memalign(),是用来申请对齐的内存地址的。只有用posix_memalign()申请的内存地址,才能用来读写O_DIRECT模式下的文件描述符。
4、madvise()和fadvise()
这对函数也是比较温和的,可以将调用者对数据访问模式的预期传递给Linux,以期得到更好的性能。
我们比较感兴趣的是MADV_DONTNEED和FADV_NOREUSE这两个flag。前者会建议Linux释放指定的内存区域,而后者会建议文件系统释放指定文件所占用的cache。
当mysql出现内存导致的性能瓶颈时,可以:
1、/proc/sys/vm/swappiness的内容改成0(临时),/etc/sysctl.conf上添加vm.swappiness=0(永久)
这个参数决定了Linux是倾向于使用swap,还是倾向于释放文件系统cache。在内存紧张的情况下,数值越低越倾向于释放文件系统cache。当然,这个参数只能减少使用swap的概率,并不能避免Linux使用swap。
2、修改MySQL的配置参数innodb_flush_method,开启O_DIRECT模式。
这种情况下,InnoDB的buffer pool会直接绕过文件系统cache来访问磁盘,但是redo log依旧会使用文件系统cache。值得注意的是,Redo log是覆写模式的,即使使用了文件系统的cache,也不会占用太多。
3、添加MySQL的配置参数memlock
这个参数会强迫mysqld进程的地址空间一直被锁定在物理内存上,对于os来说是非常霸道的一个要求。必须要用root帐号来启动MySQL才能生效。
4、还有一个比较复杂的方法,指定MySQL使用大页内存(Large Page)。Linux上的大页内存是不会被换出物理内存的,和memlock有异曲同工之妙。具体的配置方法可以参考:http://harrison-fisk.blogspot.com/2009/01/enabling-innodb-large-pages-on-linux.html
第三节: 磁盘I/O可调性能参数
linux的子系统VFS(virtural file system)虚拟文件系统;从高层将各种文件系统,以及底层磁盘特性隐藏,对程序员提供:read,write,delete等文件操作;这就是之所以我们可以在linux上mount多种不同格式的文件系统的,而window确不行;
当然基于:虚拟文件系统,文件系统,文件系统驱动程序,硬件特性方面,都能找到性能瓶颈;
1、选择适合应用的文件系统;
2.、调整进程I/O请求的优先级,分三种级别:1代表 real time ; 2代表best-effort; 3代表idle ;
如:ionice -c1 -p 1113(给进程1113的I/O优先级设置为最高优先级)
3、根据应用类型,适当调整page size 和block size;
4、升级驱动程序;
第四节 :网络可调性能参数
对于我们web应用来说,网络性能调整如此重要,linux的网络支持是无与伦比的;是作为网络服务器的首先;对于web服务来说:除了应用的响应速度外,linux网络管理子系统,网卡,带宽都可能成为性能瓶颈;
网络参数可以在/proc/sys/net/ipv4/ 下面的文件中进行配置。
可以查看和设置的参数:
1、查看网卡设置是否全双工传输的: echtool eth0
2.、设置MTU(最大传输单元),在带宽G以上的时候,要考虑将MTU增大,提高传输性能;
如: ifconfig eth0 mtu 9000 up
如果数据包的长度大于mtu的长度时,很容易出现丢包情况。
3.、增加网络数据缓存;传输数据时linux是将包先放入缓存,填满缓存后即发送出去;读操作类似;
sysctl -w net.ipv4.tcp_rmem="4096 87380 8388608" :设置tcp读缓存:最小缓存,初始化时,最大缓存
sysctl -w net.ipv4.tcp_wmem="4096 87380 8388608" :设置tcp写缓存:最小缓存,初始化时,最大缓存
由于是先将数据放入缓存再发送,或收取收据,那么当内存紧张或内存不够用时,网络丢包就可能出现。
4、禁用window_scaling,并且直接设置window_size;(就像我们经常设置jvm的参数:xms = xmx一样
sysctl -w net.ipv4.tcp_window_scaling=0
5、设置TCP连接可重用性: 对于TIME_OUT状态的TCP连接可用于下一个TCP重用,这样减少了三次握手和创建时间,非常提高性能,尤其对于web server;
如: 开启可重用tcp功能: sysctl -w net.ipv4.tcp_tw_reuse=1 sysctl -w net.ipv4.tcp_tw_recyle=1
6、禁用掉没必要的tcp/ip协议功能:比如icmp;broadcast包的接收;
7、linux对于keeplive的tcp连接有一个默认的过期时间;可以减小这个时间,让没用的连接释放掉,毕竟tcp连接数是有限的嘛;
如: sysctl -w net.ipv4.tcp_keepalive_time=1800 (设置过期时间,1800s)
8、设置最大tcp正在连接状态(还没ESTABLISHED)队列长度;避免由于太多的tcp连接过来,导致服务器挂掉;比如DoS攻击
如:sysctl -w net.ipv4.tcp_max_syn_backlog=4096
9、 绑定tcp类型的中断到一个cpu上;(让cpu去亲和这个类型中断,避免频繁的中断,影响线程调度性能)
总结: 我们在性能优化一个应用时,首要的是设定优化要达到的目标,然后寻找瓶颈,调整参数,达到优化目的;但是寻找瓶颈时可能是最累的,要从大范围,通过很多用例,很多测试报告,不断的缩小范围,最终确定瓶颈点;以上这些参数只是个认识,系统性能优化中可能用到,但并不是放之四海而皆准的; 有的参数要边测试,边调整的;
................
http://4457553.blog.51cto.com/4447553/1297998
服务器宕机原因很多,资源不足、应用、硬件、系统内核bug等,以下一个小例子
服务器宕机了,首先得知道服务器宕机的时间点,然后分析日志查找原因
1.last reboot 此命令可以查看主机起来的时间,不是宕机的时间
reboot system boot 2.4.21-27.ELsmp Mon Sep 16 02:28 (07:02) //这个是主机起来的时间
2.sar -u -f /var/log/sa/sa16 |more 查看历史cpu情况
01:10:00 AM all 12.18 0.00 3.90 36.97 46.95
01:20:00 AM all 25.21 0.00 2.39 24.43 47.96
01:30:00 AM all 3.72 0.00 4.03 44.92 47.32
01:40:00 AM all 1.65 0.00 2.45 47.59 48.31
01:50:00 AM all 31.85 0.00 2.86 18.03 47.26
02:00:00 AM all 48.40 0.00 2.01 2.46 47.13 //这里才是主机宕机的时间,要看宕机原因看着个时间点的日志
Average: all 10.77 0.00 2.00 14.76 72.47
02:28:07 AM LINUX RESTART
02:30:00 AM CPU %user %nice %system %iowait %idle
02:40:00 AM all 0.44 0.00 1.11 0.90 97.55
02:50:00 AM all 0.94 0.00 1.03 0.36 97.67
Sep 16 02:00:02 ilearndb snmpd[1138]: [smux_accept] accepted fd 11 from 10.0.1.145:46748
Sep 16 02:01:53 ilearndb modprobe: modprobe: Can't locate module eth2
Sep 16 02:01:53 ilearndb last message repeated 3 times
Sep 16 02:05:04 ilearndb snmpd[1138]: [smux_accept] accepted fd 11 from 10.0.1.145:46824 //系统里面看到2:05分还有日志,说明2:00的时候主机hang住了,sar已经取不了数据
在看sar的数据,发现(用到了swap,并且使用率在上升),是内存不足导致的主机hang住了。
# sar -r -f sa16|more
12:00:00 AM kbmemfree kbmemused %memused kbbuffers kbcached kbswpfree kbswpused %swpused kbswpcad
12:10:00 AM 27784 2027668 98.65 14012 1668488 7436568 411176 5.24 70372
12:20:00 AM 22880 2032572 98.89 15292 1673892 7436576 411168 5.24 70536
12:30:01 AM 22068 2033384 98.93 16280 1672976 7436576 411168 5.24 70536
12:40:00 AM 22848 2032604 98.89 17760 1671660 7436576 411168 5.24 70540
12:50:00 AM 23048 2032404 98.88 18744 1670228 7436576 411168 5.24 70580
01:00:00 AM 27328 2028124 98.67 19616 1664684 7436648 411096 5.24 70572
01:10:00 AM 18760 2036692 99.09 8424 1714120 7418172 429572 5.47 28584
01:20:00 AM 18584 2036868 99.10 14596 1731984 7413060 434684 5.54 17520
01:30:00 AM 22208 2033244 98.92 2436 1739972 7421352 426392 5.43 17520
01:40:00 AM 18448 2037004 99.10 3940 1742296 7421444 426300 5.43 17600
01:50:00 AM 17880 2037572 99.13 6480 1727696 7410060 437684 5.58 18028
02:00:00 AM 18124 2037328 99.12 10916 1718740 7408268 439476 5.60 17644
Average: 21663 2033789 98.95 12375 1699728 7425990 421754 5.37 45003
02:28:07 AM LINUX RESTART
02:30:00 AM kbmemfree kbmemused %memused kbbuffers kbcached kbswpfree kbswpused %swpused kbswpcad
02:40:00 AM 1517792 537660 26.16 27452 393360 7847744 0 0.00 0
02:50:00 AM 1337060 718392 34.95 29020 562108 7847744 0 0.00 0
03:00:00 AM 1330228 725224 35.28 30468 563964 7847744 0 0.00 0
03:10:00 AM 1218940 836512 40.70 31964 668272 7847744 0 0.00 0
03:20:00 AM 1218008 837444 40.74 33016 670572 7847744 0 0.00 0
03:30:00 AM 1208612 846840 41.20 34072 673436 7847744 0 0.00 0
03:40:00 AM 1200904 854548 41.57 34212 678896 7847744 0 0.00 0
03:50:00 AM 1201228 854224 41.56 35204 679216 7847744 0 0.00 0
可以考虑给主机增加1G内存。
附:性能瓶颈分析
CPU资源的过度使用,会造成系统中出现大量的等待进程,导致应用程序响应缓慢,而进程的大量增加又会导致系统内存资源的增加,当物理内存耗尽时,系统会使用虚拟内存,而虚拟内存的使用又会造成磁盘IO的增加并加大CPU的开销。
1、查看cpu是否是瓶颈
可以使用很多工具:topas、vmstat、sar、top(命令的使用网上有很多资料介绍)
目前大部分CPU在同一时间只能运行一个线程,超线程的处理器可以在同一时间处理多个线程,因此可以利用超线程特性提高系统性能。
在linux系统下只有运行SMP内核才能支持超线程,但是安装的CPu数量越多,从超线程获得的性能提升越少。
另外linux内核会将多核的处理器当做多个单独的CPU来识别,例如,两个4核的CPU会被当成8个单个CPU,从性能角度讲,两个4核的CPU整体性能要比8个单核CPU低25%-30%。
可能出现CPU瓶颈的应用有邮件服务器、动态web服务器等。
CPU物理个数 》cat /proc/cpuinfo |grep "physicalid" |sort |uniq |wc -l
查看cpu几核 》cat /proc/cpuinfo |grep"cores"|uniq
逻辑cpu个数 》cat /proc/cpuinfo|grep processor|wc –l
CPU型号查看 》dmidecode |grep -B5 -A5 -i cpu
vmstat 虚拟内存统计
例: vmstat 2 3
输出项的解释如下:
procs
memory
swap
io
system
CPU
好: user%+sys%<70%
坏: user%+sys%=85%
糟糕: user%+sys%>=90%
2、查看内存是否瓶颈
内存不足时,可以使用工具观察到频繁使用虚拟内存,虚拟内存可以缓解物理内存的不足,但是虚拟内存的过多占用会导致应用程序的性能明显下降。
服务器内存查看 》dmidecode |grep -B5 -A5 -i memory |grep Size
free命令
free是监控linux内存使用的指令。-
free -m
-
total used free shared buffers cached
-
Mem: 48291 33630 14660 0 24 22437
-
-/+ buffers/cache: 11168 37122
-
Swap: 0 0 0
vmstat命令可以查看
好:SwapIn(si) = 0 SwapOut(so) = 0
坏:Per CPU with 10page/s
糟糕:more swap In & swap out
3. 磁盘IO性能
命令 iostat 可得到相应的数值
好:iowait%<20%
坏:iowait% = 35%
糟糕:iowait%>=50%
4.网络带宽
查询QLogic HBA卡 》lspci | grep -i Fibre
user%表示CPU处在用户模式下的时间百分比
sys%表示CPU处在系统模式下的时间百分比
iowait%表示CPU等待输入输出完成时间的百分比
swap in表示虚拟内存的页导入,从SWAP DISK交换到RAM
swap out表示虚拟内存的页导出,从RAM交换到SWAP DISK
个人总结:
|
总结论: |
|||||
|
序号 |
检查点 |
检查方法 |
判断依据 |
结果判断 |
|
|
1 |
系统的Uptime时间 |
uptime |
如果发现系统uptime时间很短,则需要检查系统是否重启过 |
||
|
2 |
检查文件系统的使用率 |
df -h |
对于OS的文件系统,如果发现使用率高于90%就应该再进一步检查是什么原因引起的文件系统使用率上涨。对于应用系统使用的文件系统,我们重点在于发现有没有文件系统使用率到达95%以上,若有,把情况报告给相关的人员。 |
||
|
3 |
检查网络状态 |
ping |
网络连通性检查 |
||
|
ifconfig |
检查当前处于up状态的网卡 |
||||
|
mii-tool |
link ok 显示各个网卡所接链路的状况 |
||||
|
ethtool eth[n] |
查看指定网卡所接链路的状况 |
||||
|
ls -al /etc/resolv.conf |
确保以上文件的权限是other可读 |
||||
|
cat /etc/hosts |
主机名在hosts文件中只应该与机器的物理IP映射,如果出现有机器的浮动IP与主机映射就需要做进一步检查 |
||||
|
netstat –rn |
正常情况下应该只设置了网关,而没有其它的静态路由,如果在列表中发现有其它的路由,则需要确认是否正确 |
||||
|
view /etc/sysconfig/network-scripts/ifcfg-eth* |
先检查子网掩码设置是否正确 |
||||
|
4 |
检查ntp时间服务器设置 |
ntpq -p |
正常情况下应该有如下输出信息: |
||
|
5 |
进程状态 |
ps –ef | grep defunct;ps -ef | wc -l;ps -ef | grep -v root | wc -l |
如果系统中存在大量的僵尸进程则属于异常的状态需要检查处理。如果只是个别进程就不需要处理。 |
||
|
6 |
内存状态 |
free -m |
检查内存使用情况 |
||
|
7 |
swap状态 |
swapon -s |
查看swap使用百分比 |
||
|
8 |
检查机器性能 |
vmstat |
CPU:如果cpu的id字段长时间<10,该机器的CPU负载比较高 |
||
|
9 |
检查磁盘性能 |
iostat |
检查iowait 时长是否过大? |
||
|
10 |
检查系统日志 |
view /var/log/messages |
可以通过检索error,fail,warn等字眼加快检查的速度 |
||
|
11 |
收集系统日志 |
sosreport -a --batch |
收集系统日志 |
||
|
12 |
收集硬件日志 |
DSET |
Dell PC Server :用DSET 工具收集硬件日志 |
||
http://www.cnblogs.com/me115/p/3643778.html
寻找Linux单机负载瓶颈

服务器性能上不去,是哪里出了问题?IO还是CPU?只有找到瓶颈点,才能对症下药;
如何寻找Linux单机负载瓶颈,遵循的原则是不要推测,我们要通过测量的数据说话;
负载分两类:
1.CPU负载;
2.IO负载;
排查流程
1.查看平均负载(top/uptime命令)
2.确认CPU、IO有无瓶颈;(使用 sar vmstat)
3.CPU负载过高时寻找流程:
4.IO负载过高时寻找流程;
查看平均负载
先通过top命令查看服务器是否出现负载过重的状况,之后,再具体使用工具来分析出是CPU负载过高还是IO负载过高;
比如,使用sar工具查看CPU使用率和IO等待率(sar的具体使用教程参考大CC的这篇文章:
http://blog.me115.com/2013/12/468
top的结果:
load average:0.7, 0.66,0.59
平均负载分别表明从左到右1分钟、5分钟、15分钟内,单位时间内处于等待状态的任务数;
(等待 的意思 表明在等待cpu、或者等待IO)
CPU负载过高时的寻找流程
使用top、sar确认目标程序;
再通过ps查看进程状态和CPU使用时间等;
进一步寻找:通过strace 或 oprofile命令;
IO负载过高的寻找流程
IO负载过高,多半是程序发出的IO请求过多导致负载过高,或是发生页面交互导致频繁访问磁盘;
应通过sar或vmstat确认交换区状态,以找出原因;
如果是发生页面交互的情况,通过以下步骤调查:
1.使用ps工具确认是否有进程消耗了大量内存;
2.如果由于程序故障造成内存消息过大,应改进程序;
3.内存不足则增加内存;
如果没有交换发生,而且磁盘IO频繁,可能是用于缓存的内存不足;
1.考虑扩大缓存,增加内存;
2.考虑分散存储
Posted by: 大CC | 04APR,2014
博客:blog.me115.com
微博:新浪微博
作为一个 Linux 系统管理员,统计各类 IO 是一项必不可少的工作。其统计工具中 iostat 显然又是最重要的一个统计手段。但是这里 iostat 不是本文的重点,因为这个工具的使用在网络上已经有大量的教程,可以供大家参考。这里主要是想介绍一些其他统计工具以来满足不同的需求。
iostat
iostat 的功能异常强大,输出项也特别多,比如下面这个例子:
1
2
3
|
|
其各项的含义分别是:
- rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
- wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
- r/s: 每秒完成的读 I/O 设备次数.即 delta(rio)/s
- w/s: 每秒完成的写 I/O 设备次数.即 delta(wio)/s
- rsec/s: 每秒读扇区数.即 delta(rsect)/s
- wsec/s: 每秒写扇区数.即 delta(wsect)/s
- rkB/s: 每秒读 K 字节数.是 rsect/s 的一半,因为每扇区大小为 512 字节.(需要计算)
- wkB/s: 每秒写 K 字节数.是 wsect/s 的一半.(需要计算)
- avgrq-sz: 平均每次设备 I/O 操作的数据大小 (扇区).delta(rsect+wsect)/delta(rio+wio)
- avgqu-sz: 平均 I/O 队列长度.即 delta(aveq)/s/1000 (因为 aveq 的单位为毫秒).
- await: 平均每次设备 I/O 操作的等待时间 (毫秒).即 delta(ruse+wuse)/delta(rio+wio)
- svctm: 平均每次设备 I/O 操作的服务时间 (毫秒).即 delta(use)/delta(rio+wio)
- %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的.即 delta(use)/s/1000 (因为 use 的单位为毫秒)
如果 %util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈.
idle 小于 70% IO 压力就较大了,一般读取速度有较多的 wait.
同时可以结合vmstat查看查看 b 参数(等待资源的进程数)和 wa 参数(IO 等待所占用的 CPU 时间的百分比,高过 30%时 IO 压力高)
另外 await 的参数也要多和 svctm 来参考。差的过高就一定有 IO 的问题.
avgrq-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小.如果数据拿的大,才 IO 的数据会高.也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s.也就是讲,读定速度是这个来决定的.
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加.await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式.如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU.
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水.
有时间的话,我会单独写几个帖子来说说iostat。
iodump
iodump 是一个统计每一个进程(线程)所消耗的磁盘 I/O 工具。这个一个 perl 脚本,其原理时打开有关 I/O 的内核记录消息开关,而后读取消息然后分析输出。简单使用步骤如下:
首先下载这个工具
wget http://aspersa.googlecode.com/svn/trunk/iodump
然后打开有关 I/O 内核消息的开关
echo 1 >/proc/sys/vm/block_dump
上述开关打开后,内核会记录下每一个 I/O 操作的消息。我们只需要定时获取并分析就好了,比如下面这样
while true; do sleep 1; dmesg -c ; done |perl iodump
等待一段时间,然后通过ctrl+c来结束上述脚本,你将获得下面类似的信息:
1
2
3
4
5
6
7
|
|
上述输出的单位为块(block),每块的大小取决于创建文件系统时指定的块大小。比如我这个里的 sda7 的 block 大小是 1KB。
iotop
iotop 是一个 Python 编写的工具,有类似top工具的 UI,包括一些参数也和top类似。不过它对系统有一些要求,分别是:
- Python ≥ 2.5 or Python ≥ 2.4 with the ctypes module
- Kernel ≥ 2.6.20
- Kernel uses options:
- TASK_DELAY_ACCT
- CONFIG_TASKSTATS
- TASK_IO_ACCOUNTING
- CONFIG_VM_EVENT_COUNTERS
如果是基于 RPM 包的系统,可以直接下载编译好的二进制包(here)或者二进制源代码包(here)
如果是 Debian/Ubuntu 系统,直接使用
sudo apt-get install iotop
即可(不得不说,Debian 系统提供的软件真的是相当丰富呀),其他系统则可以通过下面的指令下载源代码,然后编译
git clone git://repo.or.cz/iotop.git
具体的使用方法可以参考 iotop(8)手册,下面是在我机器上的一个显示:
1
2
3
4
5
6
|
|
iopp
iopp 是另外一个统计每一个进程 I/O 的工具,使用 C 语言编写,理论上应该比上述两个重狙效率都要高。安装方法很简单,首先通过下面的指令下载源代码:
git://github.com/markwkm/iopp.git
然后分别通过下面的指令编译安装
1
2
3
|
|
下面是一个使用例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
|
上述输出的各项含义是:
- pid 进程 ID
- rchar 将要从磁盘读取的字节数
- wchar 已经写入或应该要写入磁盘的字节数
- syscr 读 I/O 数
- syscw 写 I/O 数
- rbytes 真正从磁盘读取的字节数
- wbytes 真正写入到磁盘的字节数
- cwbytes 因为清空页面缓存而导致没有发生操作的字节数
- command 执行的命令
其中rbytes,wbytes,cwbytes会因给出-k或者-m参数,而显示为rkb,wkb,cwkb或rmb,wmb,cwmb。command一列如果给出-c的参数则显示完整的命令名而不仅仅只是命令本身。这些参数的使用和top类似。
更具体的可以参考 iopp(8)手册。
dstat
dstat 号称各种资源统计工具,其目的是想替代vmstat,iostat,netstat,ifstat等各种单一统计工具,从而做到All in one。 dstat 用 Python 语言编写。
dstat 能够清晰显示每列的信息,特别是单位及大小很明确,不会在单位换算上犯迷糊和失误。最重要的是,因为它是基于模块化设计,因此我们可以很容易的写一个插件来收集我们需要的统计信息。
另外,dstat 的输出还可以导出为CSV格式文件,从而可以在电子表格工具里分方便的生成统计图形。
目前 dstat 的插件已经相当多了,这是我机器上目前的输出:
1
2
3
4
5
6
7
8
9
10
11
12
|
|
下面给出几个使用的列子(实际输出是带彩色的,很容易识别)
dstat 的缺省输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
|
指定需要显示的列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
|
指定需要显示的列,并同时将结果导出到文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
|
更详细的用法,可以参考 dstat(1)手册

