
深层网络识别猫(吴恩达1课4周编程实例)
第四周编程
目标:建立一个深层的神经网络识别猫
核心思想:
- 正向传播
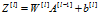
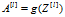
- 反向传播
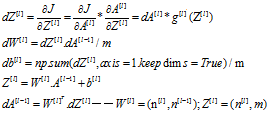
需要注意的事正反向传播的初始值, ,
,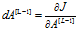 ,
,
数据集:与第一个编程作业的数据集一样
代码流程:
- 根据神经网络结构初始化参数(W,b)
- 将单元函数写出来(linear,sigmoid,relu,sigmoid_backward,relu_backward)
- 正反向传播,输出梯度
- 单步梯度下降更新参数
- 预测函数
- 建立整合函数
代码,穿插详解与思路
第16行:随机初始化,将W1=(n1,n0)的矩阵存入字典parameters['W1']中
注意:随机初始化时时* np.sqrt(2/layers_dims[l-1]),并不是吴恩达所说的*0.01
这是因为,这是一个多隐藏层的网络,当*0.01时,反向传播几次之后会使得后面的深层网络参数值变成0
详细原因可看这四篇文章:
https://blog.csdn.net/shwan_ma/article/details/76257967
https://www.cnblogs.com/makefile/p/init-weight.html?utm_source=itdadao&utm_medium=referral
https://blog.csdn.net/marsggbo/article/details/77771497
https://blog.csdn.net/u013082989/article/details/53770851
(被吴恩达给坑了,一开始*0.01,cost一直不变。搞了好长时间)
21-38行:将单元函数列在这里,是因为我想将这个model标准化,你可以在这里添加你想添加的单元函数, 比如tanh函数,记得添加了一个tanh函数时,还要添加一个对应的tanh_backward函数。有正向传播,就要有反向传播
41-71行:propagate传播函数。这里代码看起来复杂,实际上很容易理解。正向传播就是一条路走到成本函数。第l层,正向传播先计算出Z[l],再根据选择的激活函数计算A[l]
反向传播,先看一下核心思想中反向传播。先根据激活函数,将dAl,和dZl传入反向传播计算的单元函数中。然后再一步一步计算出dW,db。假设L=5,那么左后一层的A的激活函数是dA4,从dA[L-l]开始反向传播计算
propagate函数传出Y_p,是因为不想在预测函数中再写一次正向传播,所以添加了一个Y_p
122,123行:两个超参数输入。122行输入的是layers_dims 即你想建立的神经网络结构。
如:你想建立几个隐藏层,每一层的隐藏层有几个神经节点。通过一个列表组装
123行输入的是每一层的激活函数。由于我的单元函数只有relu和sigmoid函数,所以只有这两个关键字可选进去
ps:通过列表组装数据很不稳,一不小心就会传错参数。最好的方法是传一个字典进去如
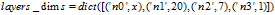
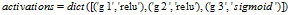
当然,中间调用layers_dims,activations的代码也要发生点变化,人懒,不想改了
最后的分析步骤也就是,将识别错误的图片打印出来而已
- import numpy as np
- import h5py
- import matplotlib.pyplot as plt
- import lr_utils
- import testCases_v2
- plt.rcParams['figure.figsize']=(5.0,4.0)
- plt.rcParams['image.interpolation']='nearest'
- plt.rcParams['image.cmap']='gray'
- #上面三句是设置图形的默认格式
- np.random.seed(1)
- 产生可预测#随机值
- def initialize_parameters(layers_dims):
- np.random.seed(3)
- parameters={}
- for l in range(1,len(layers_dims)):
- parameters['W'+str(l)]=np.random.randn(layers_dims[l],layers_dims[l-1])*np.sqrt(2/layers_dims[l-1])
- parameters['b'+str(l)]=np.zeros(shape=(layers_dims[l],1))
- return parameters
- # 单元函数
- def linear(A,W,b):
- Z=np.dot(W,A)+b
- return Z
- def sigmoid(Z):
- A=1/(1+np.exp(-Z))
- return A
- def relu(Z):
- A=np.maximum(0,Z)
- return A
- def sigmoid_backword(dA,Z):
- s=1/(1+np.exp(-Z))
- dZ=dA*s*(1-s)
- return dZ
- def relu_backword(dA,Z):
- dZ=dA.copy()
- dZ[Z<=0]=0
- return dZ
- #正反向传播
- def propagate(X,Y,parameters,layers_dims,activations):
- m=X.shape[1]
- L=len(layers_dims)
- #正向传播
- caches,grads={'A0':X},{}
- for l in range(1,L):
- caches['Z'+str(l)]=linear(caches['A'+str(l-1)],parameters['W'+str(l)],parameters['b'+str(l)])
- if activations[l-1]=='sigmoid':
- caches['A'+str(l)]=sigmoid(caches['Z'+str(l)])
- if activations[l-1]=='relu':
- caches['A'+str(l)]=relu(caches['Z'+str(l)])
- Y_p=caches['A'+str(L-1)]
- #成本函数
- cost=-np.sum(Y*np.log(Y_p)+(1-Y)*np.log(1-Y_p))/m
- cost=np.squeeze(cost)
- #反向传播
- grads['dA'+str(L-1)]=-(Y/Y_p)+(1-Y)/(1-Y_p)
- for l in range(1,L):
- if activations[-l]=='sigmoid':
- grads['dZ'+str(L-l)]=sigmoid_backword(grads['dA'+str(L-l)],caches['Z'+str(L-l)])
- if activations[-l]=='relu':
- grads['dZ'+str(L-l)]=relu_backword(grads['dA'+str(L-l)],caches['Z'+str(L-l)])
- grads['dW'+str(L-l)]=np.dot(grads['dZ'+str(L-l)],(caches['A'+str(L-l-1)]).T)/m
- grads['db'+str(L-l)]=np.sum(grads['dZ'+str(L-l)],axis=1,keepdims=True)/m
- grads['dA'+str(L-l-1)]=np.dot((parameters['W'+str(L-l)]).T,grads['dZ'+str(L-l)])
- return grads,Y_p,cost
- #更新参数
- def update_parameters(parameters,grads,learning_rate,layers_dims):
- L=len(layers_dims)
- for l in range(1,L):
- parameters['W'+str(l)]=parameters['W'+str(l)]-learning_rate*grads['dW'+str(l)]
- parameters['b'+str(l)]=parameters['b'+str(l)]-learning_rate*grads['db'+str(l)]
- return parameters
- #预测函数
- def predict(X,Y,parameters,layers_dims,activations):
- m=X.shape[1]
- grads,Y_p,cost=propagate(X,Y,parameters,layers_dims,activations)
- Y_p = np.round(Y_p)
- print('准确度:'+str(float(np.sum((Y_p == Y))/m)))
- return Y_p
- #模型组合
- def model3(X,Y,num_iterations,learning_rate,layers_dims,activations,print_cost=False,isplot=True):
- np.random.seed(1)
- parameters=initialize_parameters(layers_dims)
- L=len(layers_dims)
- costs=[]
- for i in range(num_iterations):
- grads,Y_p,cost=propagate(X,Y,parameters,layers_dims,activations)
- parameters=update_parameters(parameters,grads,learning_rate,layers_dims)
- if i%100 == 0:
- costs.append(cost)
- if print_cost:
- print('after iteration of %d cost:%f'%(i,cost))
- if isplot:
- plt.plot(np.squeeze(costs))
- plt.ylabel('cost')
- plt.title('Learning rate ='+str(learning_rate))
- plt.show()
- return parameters
- train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = lr_utils.load_dataset()
- train_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
- test_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
- train_x = train_x_flatten / 255
- train_y = train_set_y
- test_x = test_x_flatten / 255
- test_y = test_set_y
- layers_dims = [12288,20,7,5,1]
- activations=['relu','relu','relu','sigmoid']
- parameters=model3(train_x,train_y,num_iterations=2500,learning_rate=0.0075,layers_dims=layers_dims,activations=activations,print_cost=True,isplot=False)
- Y_p=predict(test_x,test_y,parameters,layers_dims,activations)
- #分析
- def print_mislabeled_images(classes,X,y,p):
- a=p+y
- mislabeled_indices=np.asarray(np.where(a==1))
- plt.rcParams['figure.figsize'] = (40.0, 40.0)
- num_images = len(mislabeled_indices[0])
- for i in range(num_images):
- index = mislabeled_indices[1][i]
- plt.subplot(2, num_images, i + 1)
- plt.imshow(X[:,index].reshape(64,64,3), interpolation='nearest')
- plt.axis('off')
- plt.title("Prediction: " + classes[int(p[0,index])].decode("utf-8") + " \n Class: " + classes[y[0,index]].decode("utf-8"))
- print_mislabeled_images(classes,test_x,test_y,Y_p)
