
百度电影推荐系统比赛 小结 ——记我的初步推荐算法实践
前一阵子参加了百度的电影推荐系统创新比赛。http://openresearch.baidu.com/activitycontent.jhtml?channelId=284 。 之前没有实现过推荐算法,想趁这次机会锻炼一下。虽然成绩并不好,RMSE只有0.6214,没有挤进前30。
任务描述:从用户的历史评分数据:userid,movieid,rating, 即用户对某个电影的评分,预测用户将会对一个未评分的电影打多少分。主办方还提供了用户的朋友关系,电影的类别等信息,但是这些我都没用上(原因最后分析),所以就只关心用户的历史行为数据。
这是一个评分预测问题。主要有两种途径:1 协同过滤 和 2 基于内容的过滤。 其中协同过滤用的最多,我也只实现了它。下面都是协同过滤的算法。
1 User-based collaborative filtering 基于用户的协同过滤
用户u和用户v有各自的评分记录 rating_list, 基于这个历史评分记录,我们可以计算u和v的相似度。相似度的计算公式有很多种,比如余弦相似度、皮尔森相似度等。(具体的公式可以网上搜)。我使用的是自己改进的公式(因为自己觉得比较靠谱):

其中N(u)指u评过分的电影集合。dis就是指两个评分的绝对值差。因为电影评分都是1~5之间的,比如u评分5,v评分4,那么dis就是1, 2-1=1, 对w_uv有1的正分贡献。除以Log(1+N(i))的原因:如果电影很流行,比如泰坦尼克号,大家都看,那么对u和v的相似度影响应该小;相反,如果看过电影i的人很少,比如电梯里的恶魔,那么i对u和v用户的影响就应该更大。
现在有了用户之间的相似度关系。要预测用户u对电影i的评分。取出所有对i评过分的用户。从中取出相似度最高的K个用户,以他们的打分做加权平均,得到的分数就是对用户u的预测。所以有些人也把这种算法称为“基于邻居”的预测。(knn)
技巧: 做加权平均的时候,权值一般设为相似度w。但是有学者认为权值要经过训练估计,得到的结果比较好。“Modeling relationships at multiple scales to improve accuracy of large recommender systems”
结果: RMSE = 0.6638
2 Item-based collaborative filtering 基于物品的协同过滤
和user-based思路基本一样,只不过,刚才是计算用户之间的相似度,现在换成计算电影间的相似度。有点类似对偶问题。
效果:RMSE=0.6483
点评:据经验总结,Item-based 的效果比user-based好,而且占内存小。因为电影的数量要比用户的数量少很多。
把 user-based 和item-based的结果加权: RMSE= 0.6343
3 SVD和pmf
下面就谈谈最流行的矩阵分解途径吧。 参考的是两篇论文"matrix factorization techniques for recommender systems" 和 "Probabilistic matrix factorization"
把用户-电影 评分看成一个矩阵,rui 表示u对电影i的评分。这个矩阵是很稀疏的,很多元素都缺失。一般来说填充率不到1%。然后假定每个用户u都有一个D维的向量,表示他对不同风格的电影的偏好,每个电影i也有一个D维的向量表示不同风格的用户对它的偏好。 于是电影的评分矩阵可以这样来估计:
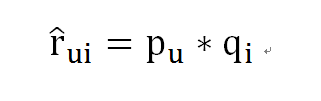
p 和q就是D维的向量。用梯度下降法训练p和q,迭代几十次就收敛了。但是这样的SVD很容易就过拟合,所以需要加一些约束。具体的约束请看那两篇论文,这里只将一种:要优化的目标函数变为:
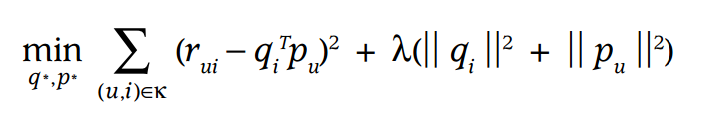
对它求导,可以发现每次迭代的时候,p和q的更新公式变成:
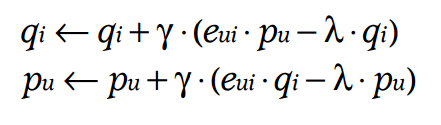
加入了一些约束之后,就可以避免过拟合。或许有些人不知道什么是过拟合的后果,这里顺便也把图贴上来:

虚线的线,前期RMSE下降的很快,后来又上升了,成V型,就是过拟合的表现了。
还有一种 bayesian probabilistic matrix factorization(http://www.utstat.toronto.edu/~rsalakhu/BPMF.html), 效果很赞,有源码,可以直接使用。
效果: RMSE= 0.6302
4 后处理
主要针对特殊用户。 1 是评分很少的用户,比如评分数只有7个以下的。经统计这些用户的评分,猜测这些人是精心挑选好电影看的,所以给他们的打分直接设成平均分多一分。
2 是评分一直很稳定的用户。有两种情况,一种是电影托,第二是用户比较随意,随意给分的。所以对他们的结果,直接预测为他们历史的平均值。
5 各种算法的加权平均
最后把几种算法的结果加权平均起来,RMSE=0.6214。 前netflix冠军队是整合了他们的108个模型的结果,对此我只能呵呵了。"the BellKor solution to the Netflix Prize"
最后,因为是我第一次参加推荐系统的实践,很多经验都不足,希望能多和大家交流切磋。时间比较玩了,担心楼管会锁门,文章可能写的比较肤浅。持续更新。
posted on 2013-05-07 01:00 leavingseason 阅读(6085) 评论(19) 编辑 收藏 举报


