

福大软工1816 · 第二次作业 - 个人项目
福大软工1816 · 第二次作业
1. Github地址
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 240 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 50 | 240 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 200 |
| Reporting | 报告 | 100 | 300 |
| · Test Repor | · 测试报告 | 10 | 70 |
| · Size Measurement | · 计算工作量 | 10 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 80 | 210 |
| 合计 | 370 | 1060 |
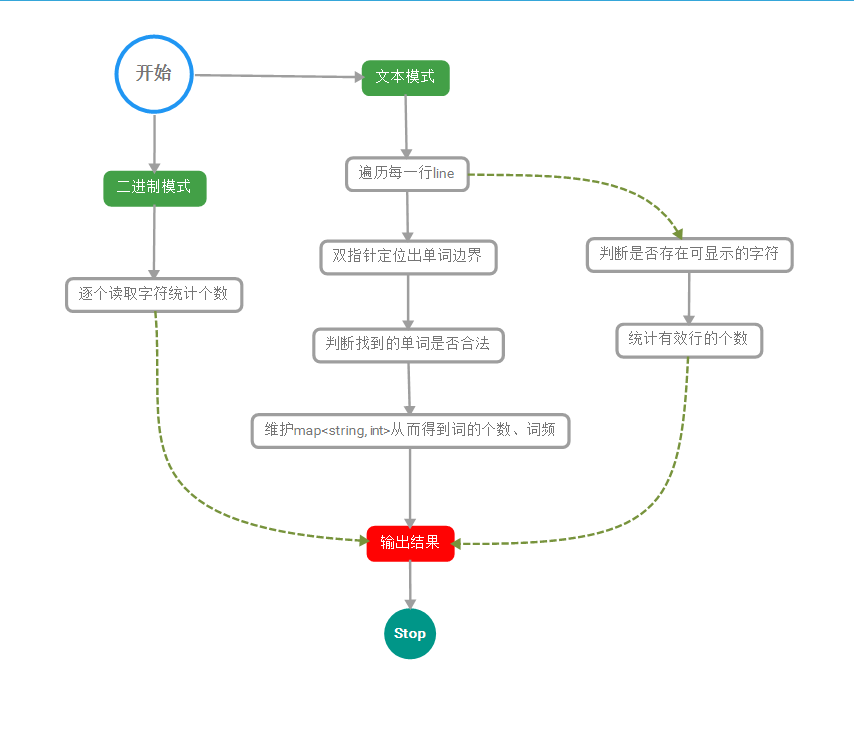
3. 解题思路描述
-
统计文件的字符数:
以二进制模式打开文件,逐个统计字符
-
统计文件的单词总数:
单独处理每一行,设置两个下标标识出一个词的界限,再判断是否合法
-
统计文件的有效行数:
单独处理每一行,判断是否有可显示的字符
-
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词:
- 对于合法的单词转小写后→维护一个
map<string,int> - 有关排序,偶然看到了陈伯涛同学的博客的博客,值得思考!本来我的做法是重载<号直接sort,但这样的复杂度是
O(N*Log(N)),我们只需要提取出前十个,如果直接去找这前十个的话,复杂度是O(N*10)。如果使用堆排序,在初始化堆的过程中,也需要O(N*Log(N))的时间。所以最后我使用的是直接去找这前十个。另外还有陈同学没有像我一样蠢蠢的把map<string, int>的东西再转到一个vector中进行排序,而是直接使用迭代器进行排序,这样能避免拷贝的时间,后来我也照着这一点更改了我的代码。
- 对于合法的单词转小写后→维护一个
-
按照字典序输出到文件result.txt:
C/C++的IO操作
在实际过程中发现windows下文本编辑时一次回车=两个字符(\r + \n),使用文本的形式打开文件是看不到那个\r的,如需统计字符个数,需要在二进制形式下打开
查找的资料:
- C++的argc、argv
- C++的IO流
- 回车和换行的区别
- Google C++命名规范
- 《构建之法》个人项目部分
C++: std::ifstream::open
4. 设计实现过程
应作业要求,代码组织如下
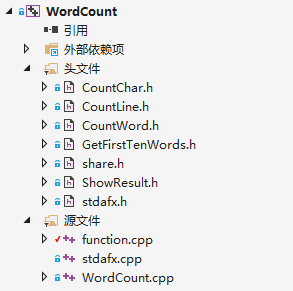
结构说明:
- 在
*.h中声明相关函数,如CountChar.h中有一个int CountChar()的函数声明 - 在
*.h中声明的函数统一定义在function.cpp中 - 主程序WordCount.cpp引用
*.h,直接使用其中的函数即可
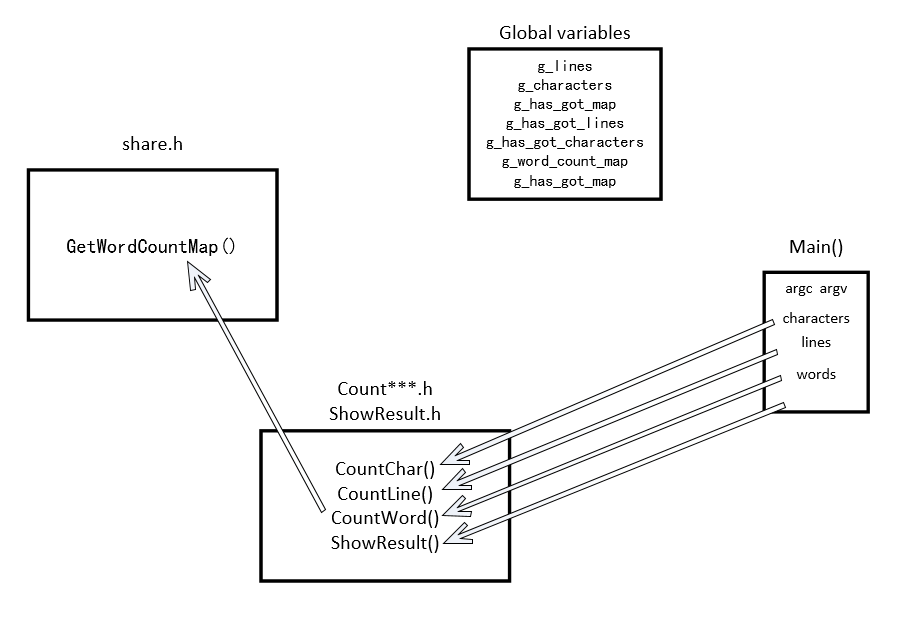
测试模块设计
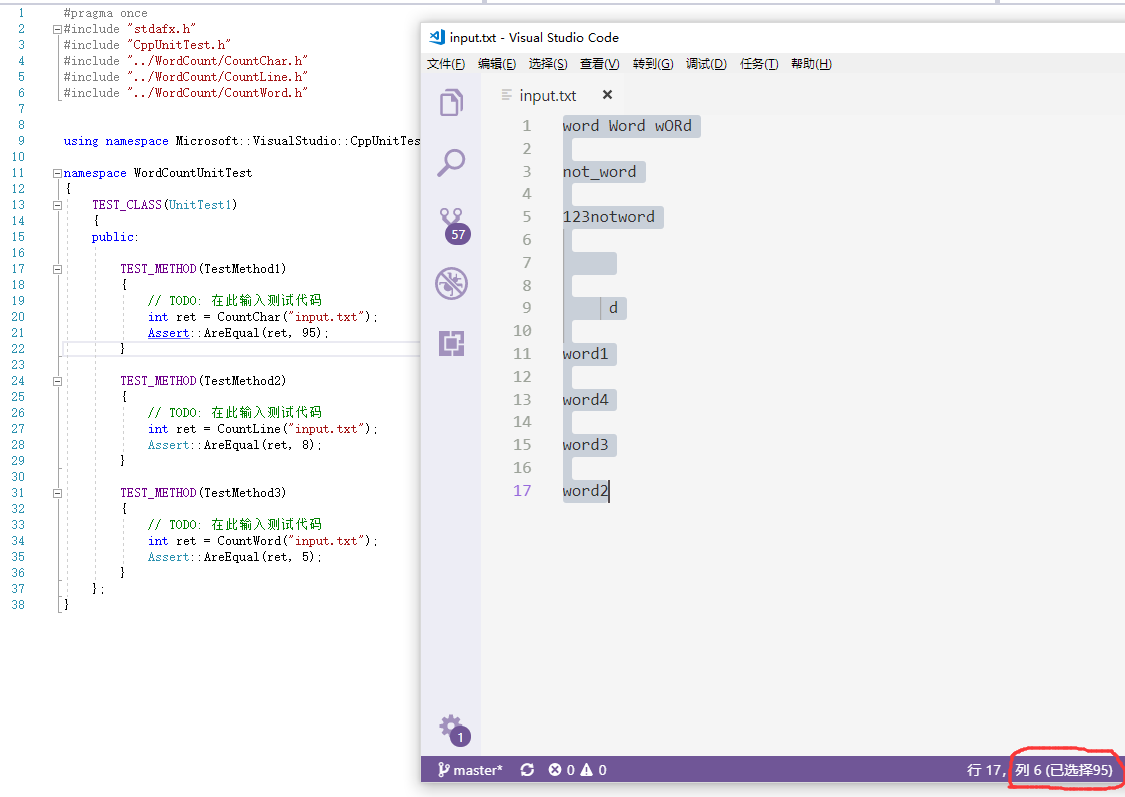
测试文件以Windows下文本编辑器VS Code进行编辑,测试文件如图
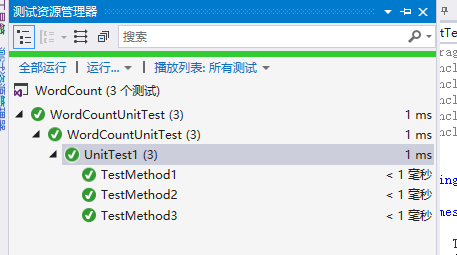
主要对CountChar()、CountLine()、CountWord()三个函数进行了测试
5.性能分析以及改进
版本1的程序过程:
更改main函数,让程序多次循环读取文件

进行效能分析

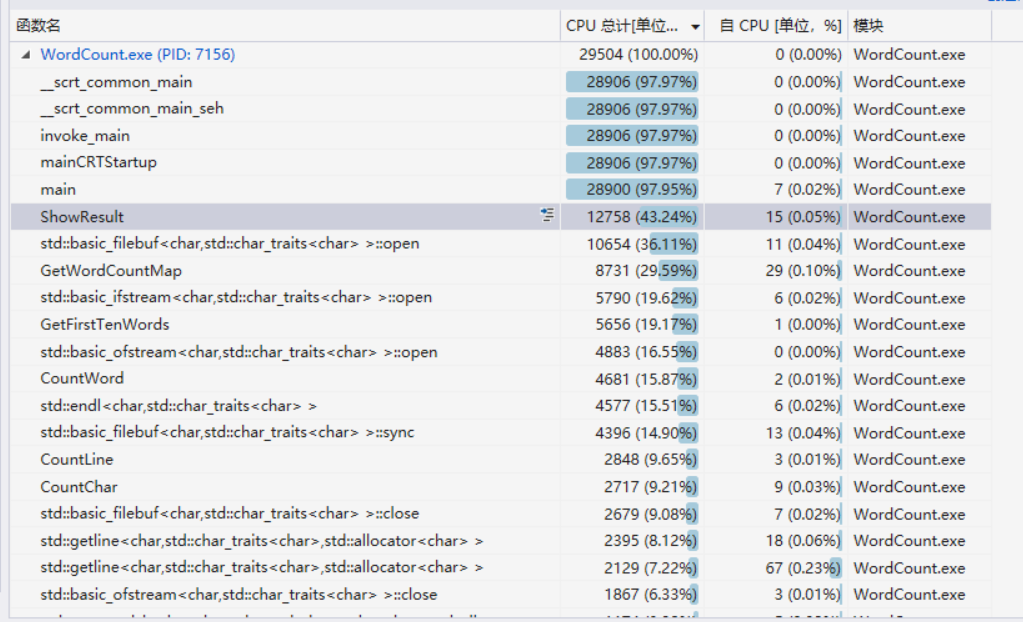
我们可以看到,比较花费时间的是ShowResult函数、文件操作的Open函数、GetWordCountMap函数。首先我打开了两次文件(一次是文本模式,一次是二进制模式),还有输出结果的时候需要以写的形式打开文件,Open操作比较多可以理解。ShowResult函数以及GetWordCountMap函数中涉及对Map的操作,需要多加一个Log复杂度进去,且GetWordCountMap会在两个函数中被调用,这个结果也可以理解。
更详细的性能报告
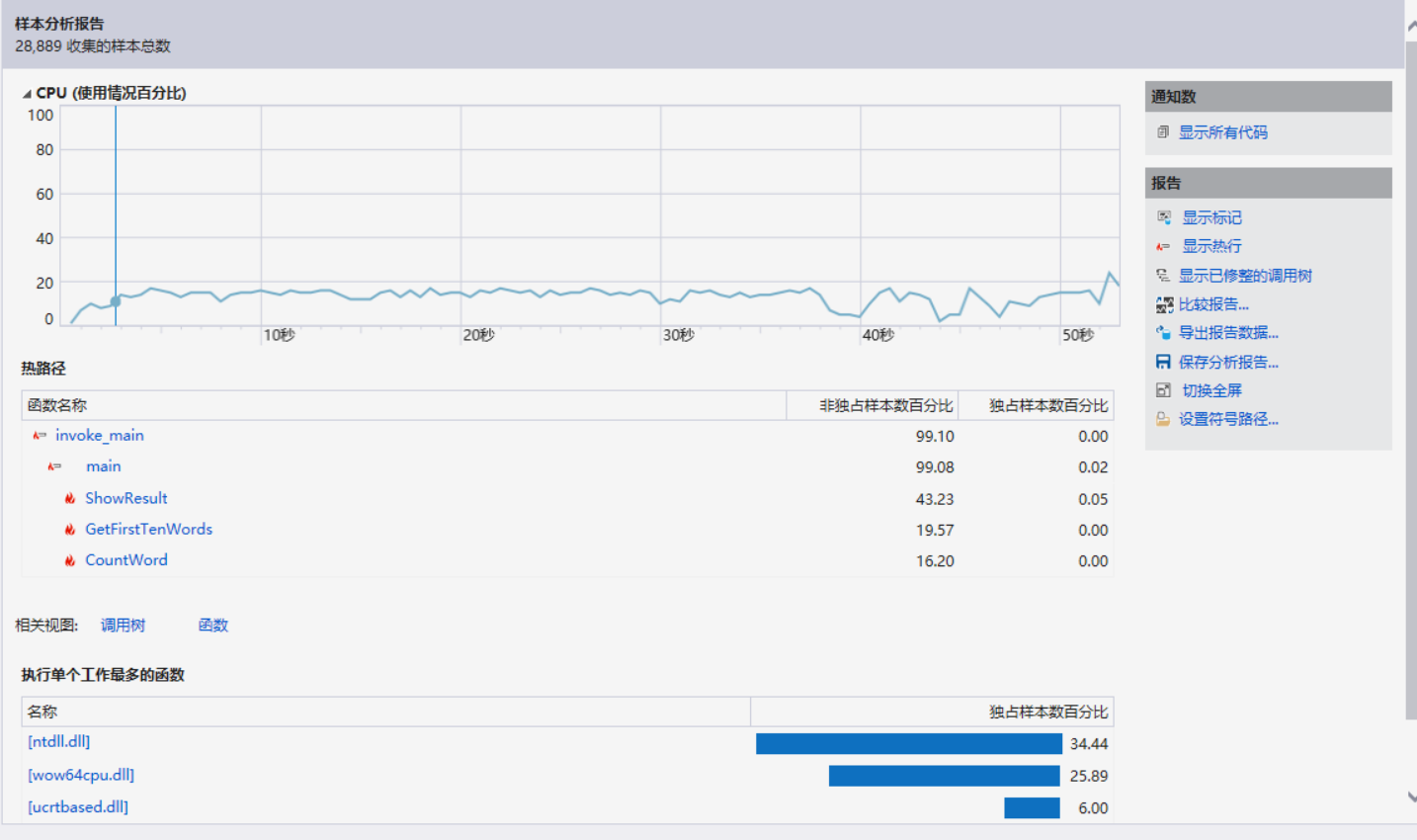
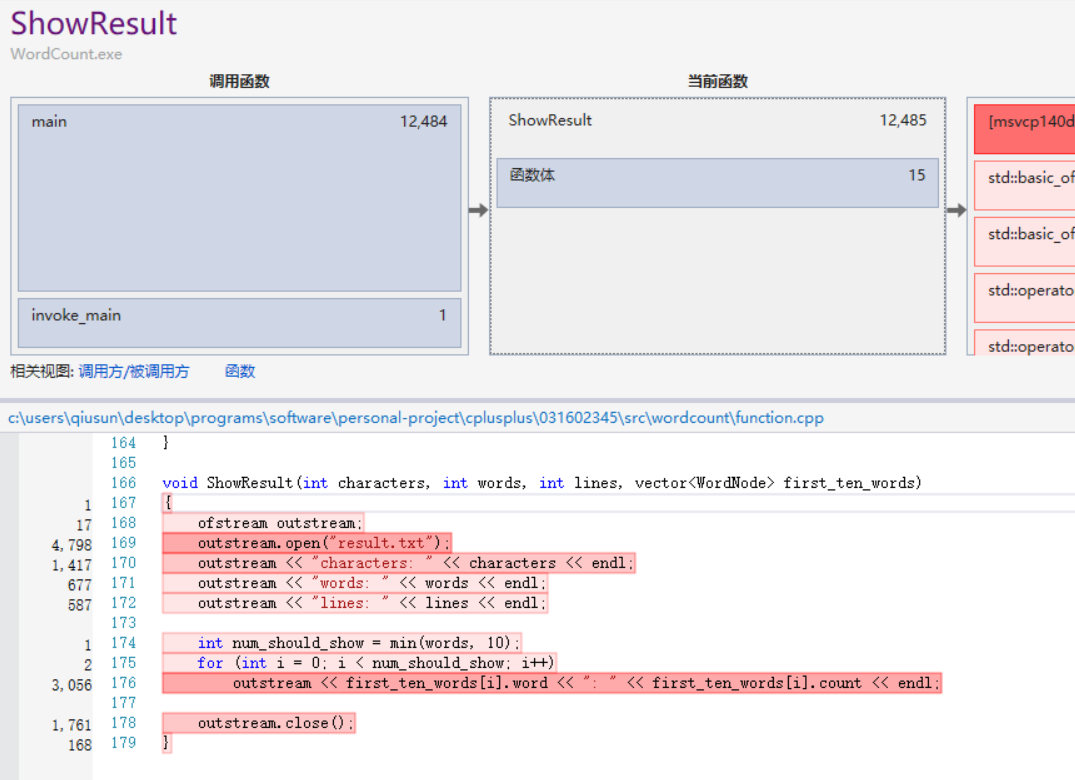
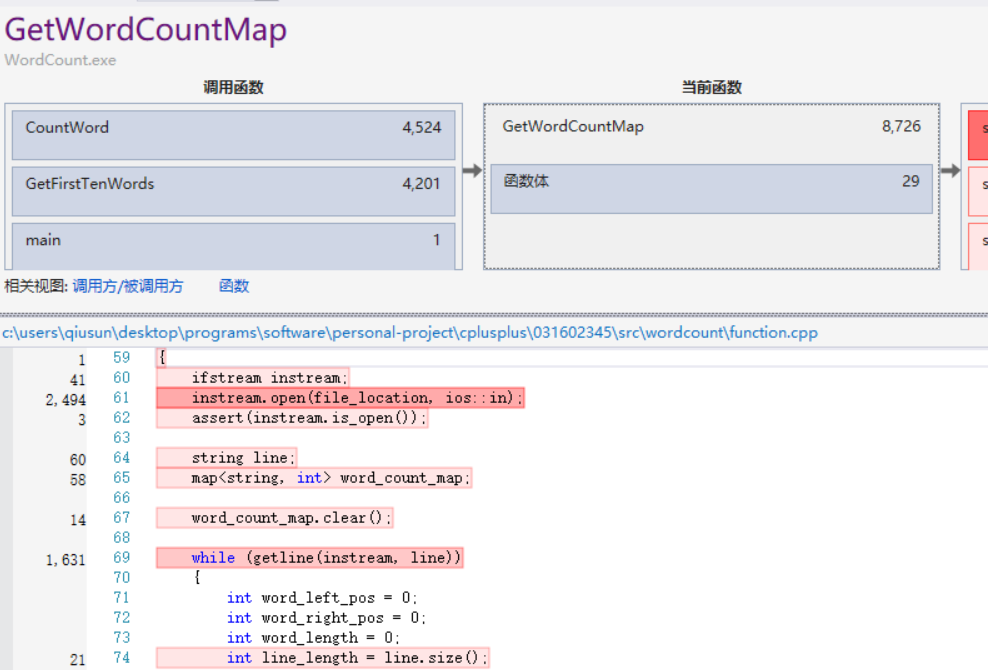
可以看到文件IO的耗时比较大,因此我考虑只在二进制模式下打开文件一次,得到所有信息的方法。
于是就有了版本2
版本2的程序过程:
版本2主要改进内容:
- 只读取一次文件(在获取词频字典的过程中顺路获得其他信息,并修改标志位)
- 取消排序算法,改用直接选取前10大
在版本2中,我自己封装了一个GetLine方法,既可以统计字符,也可以返回该行的其他字符(非\r \n),同时在舍弃了排序,采取了直接选取前10大的方法,这样在数据量较大的时候会取得不错的性能
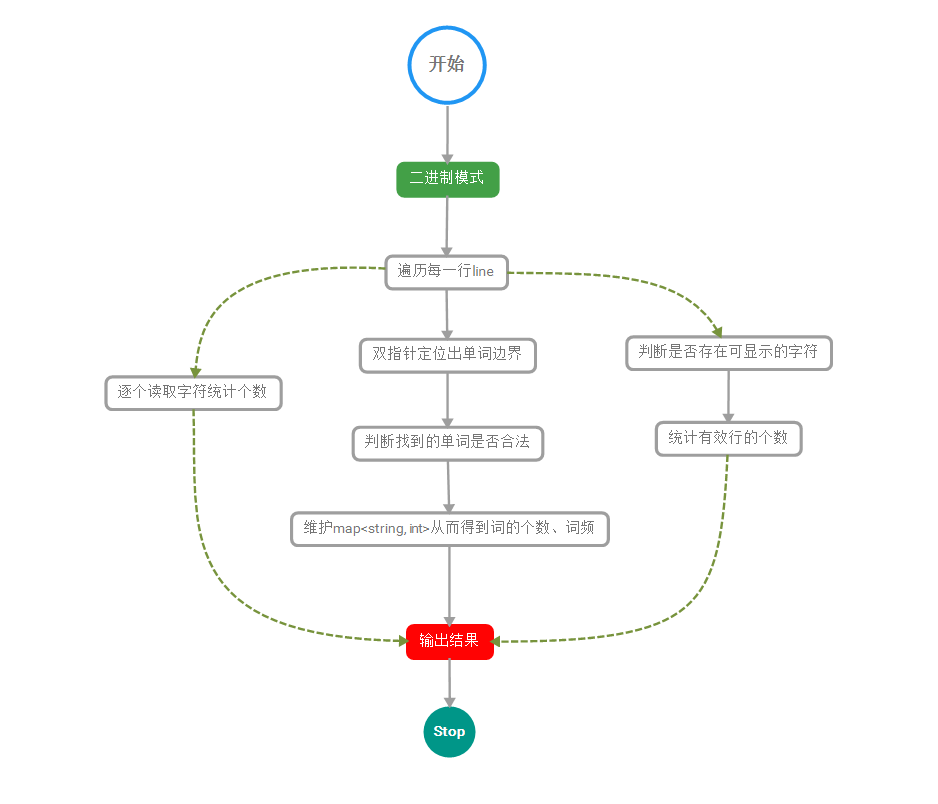
版本2的性能分析
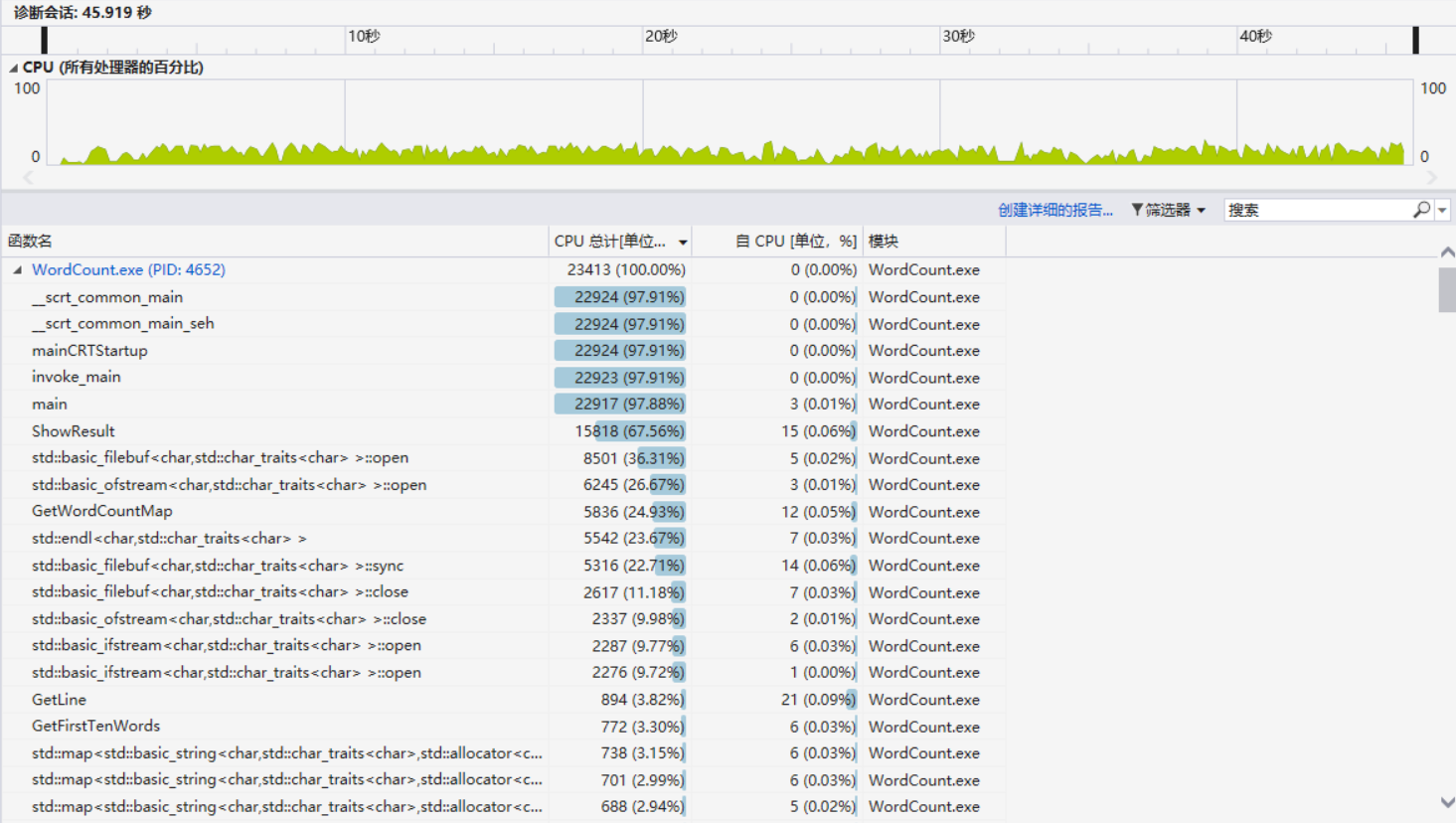
可以看到相同的数据,版本2的CPU开销从29504下降到了23413(效率提升20.6%),Open函数的开销也从10654下降到了8501(效率提升20.2%)
6.代码说明
- 总体思想是使用二进制模式打开文件,首先获取词频统计字典,在获取这个字典的过程中一次性得到所有信息(字符数、行数、词频),并修改g_has_got_map、g_has_got_lines、g_has_got_char三个标志位为True,这样在调用CountChar()、CountLines()函数时就可以直接返回值。
- 维护字符数、有效行数的工作在自定义的
GetLine()中实现 - 考虑到其他程序在调用过程中未必有统计词频的功能,我在程序中设置全局变量
g_has_got_map、g_has_got_lines、g_has_got_charaters三个全局变量,如果程序在调用过程中已经求得了词频、有效行、字符数的时候就直接将结果返回,没有得到的时候再重新计算。这样可以减少计算量。
GetWordCountMap()函数的实现

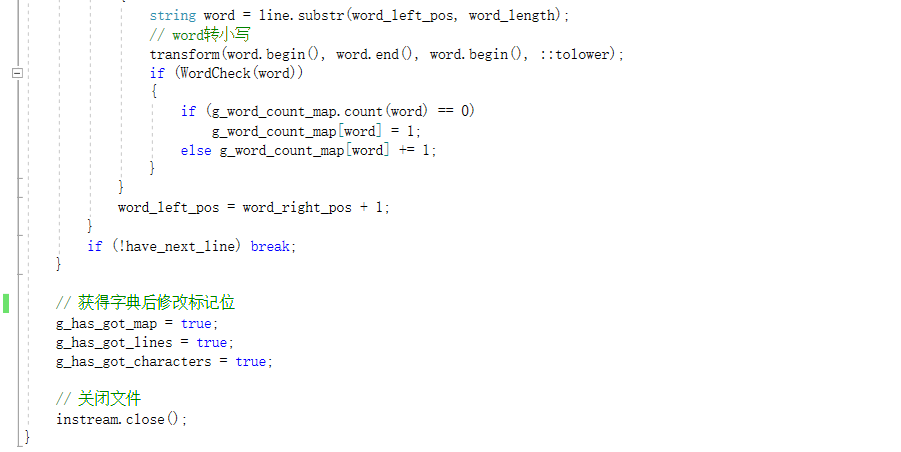
GetFirstTenWords()函数的实现
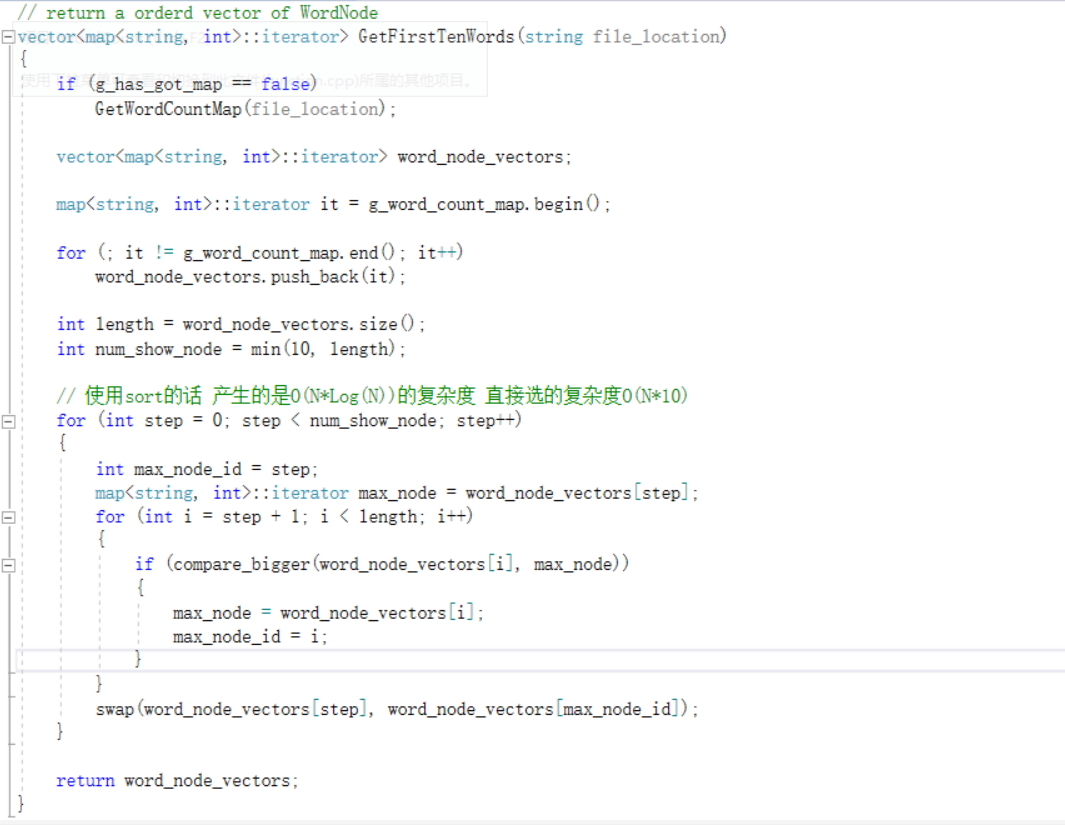
CountChar()函数的实现
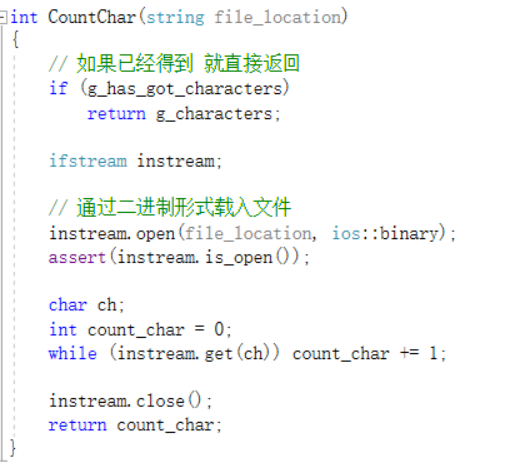
CountLine()函数的实现
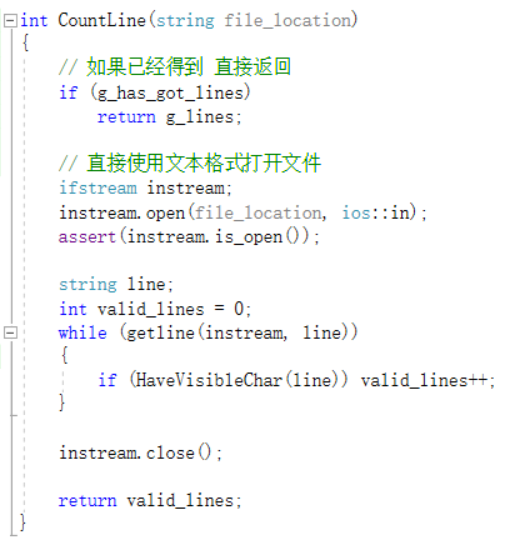
自定义GetLine()函数的实现
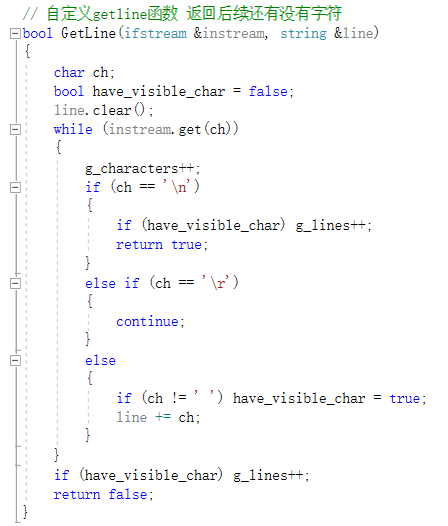
main()函数的调用

7.个人收获
- 通过
link2005这个错误,才明白C++工程中不能在头文件中定义函数,函数的定义要放在CPP文件中;还有如果要定义全局变量的话,在一个CPP中定义好全局变量,在其他需要使用全局变量的CPP使用extern进行引用 - 看了邹欣老师的《构建之法》的前面一部分,才意识一个复杂软件的诞生需要复杂的过程。之前没有使用过完整的构建方法,不知道写一个软件还需要进行单元测试、回归测试等步骤,也没有使用过VS强大的性能分析工具。通过这个简单的个人项目学到了通过VS测试软件的基本方法。
- 初步掌握了Git,我不是实验班的,而且之前并没有使用Git的需要,虽然学过但由于不经常使用慢慢又忘了。
- 课上听到柯老师的建议,要有科研精神,比如算法改进后,不要只给出绝对值,而要给出一个相对提升的百分比。
- 在我按照助教老师的要求测试GB级文件时,建立词频统计字典花了4分钟,相比之下VS Code打开这个文件并做好显示大概只需要10So(╥﹏╥)o,他们开挂了吗?好吧,一定是我的算法可改进的空间还有很大。
- 通过这道题目,让我意识到我的工程化思维不够。之前参加算法竞赛,因为时间有限,一般考虑的是怎么快速的A了这道题目,不会使用工程化的思想来解决这个问题,反正怎么快怎么来,还封装成模块?不可能有这样的时间的好嘛。但,平心静气来讲,我相信一个庞大的软件,一定需要完整工程化体系的支持。反思为什么国外的企业基本没有什么加班的现象但国内的加班现象这么严重?我并不觉得是国内程序员笨,而是想比国内,国外多家公司有成熟的工程化体系(Apple、Facebook、Amazon、Microsoft等)。

