flume1.8 开发指南学习感悟
概述:
Apache Flume是一个分布式、可用的系统,用于从许多不同的sources有效的收集并移动大量日志数据用于集中存储数据。
架构及数据流动模型:
flume实际上就是一个Agent。Agent里面包含三大组件:Source、Channel、Sink。
Flume agent流动的数据单位为一个Event。一个Flume agent 是一个JVM进程,维持允许Events从一个外部source流动到一个外部目的地的组件。
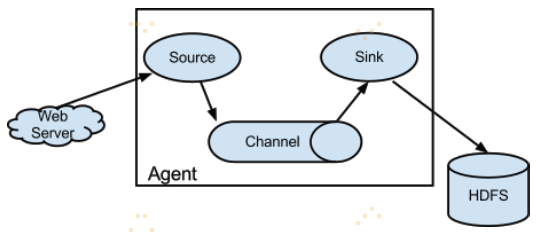
Events被外部source(例如web server)发送到Source,被发送的Events要有特定的格式。例如,AvroSource可以用来接受来自客户端的Avro Events或者其他Flume agent。当Source接受Event时,Source存储Event进一个或多个Channels。该Channel是一个活的存储,保存Event直到它被Sink消费。Sink把Event从Channel中移除并把Event放进外部存储库,如HDFS。Source和Sink在Agent里面是异步运行的。
Client--开发自定义组件:
Client在events的来源地操作,并把获取到的events发送到Flume agent。Client通常在它们消耗数据的应用过程操作。Flume一般支持Avro,log4j,syslog,和Http POST(带有JSON body)作为途径方式去从转换来自外部Source的数据。在上图中的web server就相当于一个Client。
在条件无法满足的情况下,可以创建一个自定义机制发送数据给Flume。有两种实现方式:第一种是创建自定义client与Flume已存在的sources,如AvroSource或者SyslogTcpSource,联系交流。这里client需要把数据转换成Flume Sources能够识别的信息。另外一种是去编写自定义Flume Source,它能直接与你已存在的使用IPC或者RPC协议的client应用交流,然后转换client数据为Flume Events用于发送。
RPC client 接口
Flume的RpcClient接口的实现封装了flume支持的RPC机制。用户的应用可以简单的调用Flume Client SDK的append(Event)或者appendBatch(List<Event>)去发送数据,而不用担心底层消息交换的细节。用户提供要求的Event的方式有两种,一种是可以通过直接实现Event接口,如SimpleEvent类,二是通过使用EventBuilder的withBody()方法。
RPC clients - Avro和Thrift
Avro是默认的RPC协议,NettyAvroRpcClient和ThriftRpcClient实现RpcClient接口。client需要创建带有host和port的目标Flume agent,然后可以使用RpcClient发送数据到agent。
Flume Client (Avro Client)配置解析


① 分别给Channels、Sources、Sinks命名为c1、r1、k1;
②标明channels c1的类型,为memory内存存储;
③注明sources r1需要连接的channels为c1,然后标明sources r1的类型为avro,即client为avroClient类型,发送到source的数据格式为avro;其次把client的host和port写明;
④注明sinks k1需要连接的channels为c1,然后表明sinks类型为loggger存储方式。
事务接口:
事务接口是Flume可靠性的基础。全部的主要组件(如Sources,Sinks和Channels)必须使用Flume事务;
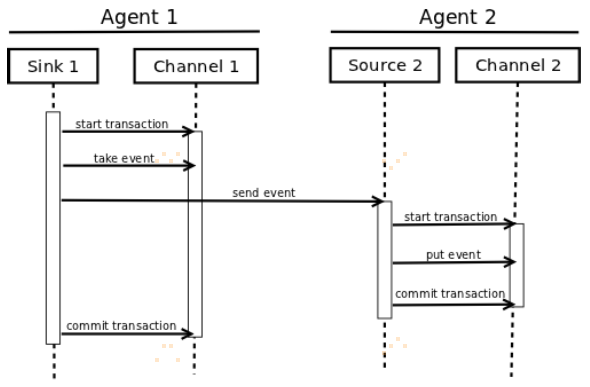
事务是在Channle实现过程中实现的。每一个Source和Sink连接到的Channel,其必须包含Transaction对象。Sources使用ChannelProcessor去管理Transactions,Sinks通过其配置的Channel管理Transactions。把event放进Channel或者从Channel移除event的操作是在一个活的Transaction中完成的。
Sink:
Sink的目的是把Events从Channel移除并把它们发送到下一个Flume Agent或者在外部存储库存储它们。一个Sink恰好连接一个Channels,在Flume配置文件中配置。有个SinkRunner实例连接每一个配置的Sink,当Flume框架调用SinkRunner.start(),一个新线程被创建去驱动Sink(使用SinkRunner.PollingRunner作为线程的Runnable)。这个线程管理Sink的生命周期。该Sink需要实现start()和stop()方法,这些方法是LifecycleAware的接口。Sink.start()方法应该初始化Sink和带它到一个能使Event前进到下一个目的地的状态。Sink.process()方法应该执行把Event从Channel移除并使它前进的核心进程。Sink.stop()方法应该执行必要的清除(如释放资源)
Source:
Source的目的是接收来自外部Client的数据和把它存储在配置好的Channels。Source可以通过它本身的ChannelProcessor得到一个实例,用来处理一个Event,并在Channel本地transaction提交。类似于SinkRunner.PollingRunner Runnable,有PollingRunner Runnable在一个新线程中执行,当Flume框架调用PollableSourceRunner.start(),该线程会被创建。每一个配置的PollableSource与它本来的运行一个PollingRunnable的线程关联。该线程管理PollableSource的生命周期,例如starting和stopping。一个PollableSource实现必须实现strat()和stop()方法,它们在LifecycleAware接口中声明。PollableSource运行调用Source的process()方法。process()方法应该检查新的数据并把它以Flume Events的形式存储在Channel中。注意这里有两种Sources。PollableSource已经被提及啦。另一种是EventDrivenSource。EventDrivenSource,不同于PollableSource,必须有它自己的调用机制去识别新数据并把新数据存在Channel。EventDrivenSources不是由它们本身的线程驱动的。
Channel:
暂无

