
RNN、LSTM、Char-RNN 学习系列(一)
RNN、LSTM、Char-RNN 学习系列(一)
zoerywzhou@gmail.com
http://www.cnblogs.com/swje/
作者:Zhouw
2016-3-15
版权声明:本文为博主原创文章,未经博主允许不得转载。
转载请注明出处:http://www.cnblogs.com/swje/p/5279349.html
作者是深度学习的初学者,经由导师指导,稍微学习了解了一下RNN、LSTM的网络模型及求导,打算在这里分享一下,欢迎各种交流。
2016-03-15看到的博客、参考文档:
从NN到RNN再到LSTM(附模型描述及详细推导)——(一)NN、
从NN到RNN再到LSTM(附模型描述及详细推导)——(二)RNN、
从NN到RNN再到LSTM(附模型描述及详细推导)——(三)LSTM。
Softmax回归:http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
反向传播算法的解释:Principles of training multi-layer neural network using backpropagation:http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
近期的学习体会:
1、Softmax分类器:解决多分类问题。
当训练过程中,我们想要improve 某目标字符的置信度并降低其他字符的置信度时,通常的做法是使用一个交叉熵损失函数,这相当于在每个输出向量使用Softmax分类器,将下一个出现的字符的索引作为一个正确的分类。一旦损失进行了反向传播并且RNN权值得到更新,在输入相同的情况下,下一个正确的字符将会有更高的分数。
2、前向传播(Forward propagation):依次按照时间的顺序计算一次。
反向传播(Back propagation):从最后一个时间将累积的残差传递回来。
3、 符号 "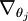 " 的含义:
" 的含义: 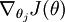 本身是一个向量,它的第
本身是一个向量,它的第  个元素
个元素 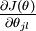 是
是  对
对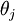 的第 个分量的偏导数。
的第 个分量的偏导数。
4、激活函数(activation function):是用来加入非线性因素的,因为线性模型的表达能力不够。激活函数不是指它去激活什么,而是指如何把“激活的神经元的特征”通过函数把特征保留并映射出来。
常见的激活函数有:
- sigmoid函数:S型函数。特征比较复杂或者相差不是很大,需要更细微的分类判断时,效果好。
- tanh:是设置一个值,大于0.5的通过为1,不然为0。特征相差明显是效果好,在循环过程中不断扩大特征效果显示出来。
- ReLU:简单粗暴,大于0的留下,否则一律为0。取max(0,x),不断试探如何用一个大多数为0的矩阵来尝试表达数据特征。
5、问答区域
- 问:训练好的网络怎么使用?
- 答: 用来给新数据分类。
- 问:神经网络通过什么方法训练?
- 答:可以用BP算法,前向传播:从第一层到最后一层(last layer)跑一遍。
6、Dropout参数(@char-rnn模型):指模型训练时随机让网络某些隐含层节点的权重不工作,不工作的节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已)。
训练神经网络模型时,如果训练样本比较少,为了防止模型过拟合,Dropout可以作为一种trick供选择。
7、Boosting 方法:为了提高弱分类算法的准确度:构造预测函数序列,then combine 之。
Adaboost 算法:将容易找到的识别率不高的弱分类算法提升为识别率很高的强分类算法。给定一个弱的学习算法和训练集,在训练集的不同子集上,多次调用弱学习算法,最终按加权方式联合多次弱学习算法的预测结果得到最终学习结果。


