
使用 Beautiful Soup 测试修复不规范HTML文件
测试环境:win10、Python 3.7
摘要:由于Tidy目前只支持Python 2.5及以下版本,所以使用Beautiful Soup来解析和检查不规范的HTML文件。
1、安装 Beautiful Soup
下载地址:https://www.crummy.com/software/BeautifulSoup/bs4/download/
将安装文件解压缩并拷贝到 D:\Python\Python37\Lib\site-packages 目录中
在 cmd 中输入pip install bs4进行安装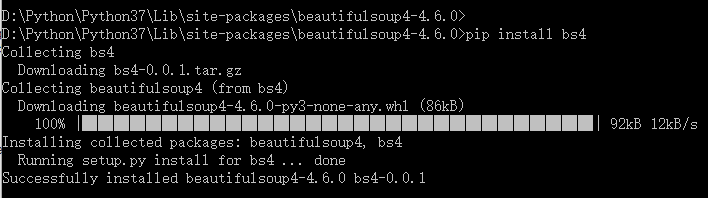
2、测试 Beautiful Soup
1)在 python 安装目录中创建一个名为“messy.html”的HTML文件。
D:\Python\Python37\messy.html
在IDLE中输入代码
from bs4 import BeautifulSoup text = open('messy.html','r',encoding='UTF-8').read() soup = BeautifulSoup(text,'html.parser')

注意:
1)如果HTML文件被保存为ANSI格式,则open无法解析该文件的编码,会出现
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa1 in position xxx: invalid start byte
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa1 in position xxx: invalid start byte
等编码错误。使用记事本另存为utf-8编码格式即可。
2)根据《python基础教程(第2版)》第260页的例子,如果直接写
soup = BeautifulSoup(text)
则会出现如下错误信息
Warning (from warnings module):
File "D:\Python\Python37\lib\site-packages\bs4\__init__.py", line 181
markup_type=markup_type))
UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("html.parser"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 1 of the file <string>. To get rid of this warning, change code that looks like this:
BeautifulSoup(YOUR_MARKUP})
to this:
BeautifulSoup(YOUR_MARKUP, "html.parser")
加上第二个参数即可
soup = BeautifulSoup(text,'html.parser')
在HTML文件中添加一段不规范文本 <p>Sogetsu Kazama</b>,进行修复后发现它居然直接在</b>后面添加了</body></html>,Beautiful Soup居然犯这种低级错误,我真是晕死了。
如果添加 <p>Sogetsu Kazama 则会修复为 <p>Sogetsu Kazama</p>,修复正确。
关于修复错误的问题继续寻找解决办法。
