
Java编程的逻辑 (51) - 剖析EnumSet
本系列文章经补充和完善,已修订整理成书《Java编程的逻辑》,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http://item.jd.com/12299018.html

上节介绍了EnumMap,本节介绍同样针对枚举类型的Set接口的实现类EnumSet。与EnumMap类似,之所以会有一个专门的针对枚举类型的实现类,主要是因为它可以非常高效的实现Set接口。
之前介绍的Set接口的实现类HashSet/TreeSet,它们内部都是用对应的HashMap/TreeMap实现的,但EnumSet不是,它的实现与EnumMap没有任何关系,而是用极为精简和高效的位向量实现的,位向量是计算机程序中解决问题的一种常用方式,我们有必要理解和掌握。
除了实现机制,EnumSet的用法也有一些不同。次外,EnumSet可以说是处理枚举类型数据的一把利器,在一些应用领域,它非常方便和高效。
下面,我们先来看EnumSet的基本用法,然后通过一个场景来看EnumSet的应用,最后,我们分析EnumSet的实现机制。
基本用法
与TreeSet/HashSet不同,EnumSet是一个抽象类,不能直接通过new新建,也就是说,类似下面代码是错误的:
EnumSet<Size> set = new EnumSet<Size>();
不过,EnumSet提供了若干静态工厂方法,可以创建EnumSet类型的对象,比如:
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType)
noneOf方法会创建一个指定枚举类型的EnumSet,不含任何元素。创建的EnumSet对象的实际类型是EnumSet的子类,待会我们再分析其具体实现。
为方便举例,我们定义一个表示星期几的枚举类Day,值从周一到周日,如下所示:
enum Day { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY }
可以这么用noneOf方法:
Set<Day> weekend = EnumSet.noneOf(Day.class); weekend.add(Day.SATURDAY); weekend.add(Day.SUNDAY); System.out.println(weekend);
weekend表示休息日,noneOf返回的Set为空,添加了周六和周日,所以输出为:
[SATURDAY, SUNDAY]
EnumSet还有很多其他静态工厂方法,如下所示(省略了修饰public static):
// 初始集合包括指定枚举类型的所有枚举值 <E extends Enum<E>> EnumSet<E> allOf(Class<E> elementType) // 初始集合包括枚举值中指定范围的元素 <E extends Enum<E>> EnumSet<E> range(E from, E to) // 初始集合包括指定集合的补集 <E extends Enum<E>> EnumSet<E> complementOf(EnumSet<E> s) // 初始集合包括参数中的所有元素 <E extends Enum<E>> EnumSet<E> of(E e) <E extends Enum<E>> EnumSet<E> of(E e1, E e2) <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3) <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4) <E extends Enum<E>> EnumSet<E> of(E e1, E e2, E e3, E e4, E e5) <E extends Enum<E>> EnumSet<E> of(E first, E... rest) // 初始集合包括参数容器中的所有元素 <E extends Enum<E>> EnumSet<E> copyOf(EnumSet<E> s) <E extends Enum<E>> EnumSet<E> copyOf(Collection<E> c)
可以看到,EnumSet有很多重载形式的of方法,最后一个接受的的是可变参数,其他重载方法看上去是多余的,之所以有其他重载方法是因为可变参数的运行效率低一些。
应用场景
下面,我们通过一个场景来看EnumSet的应用。
想象一个场景,在一些工作中,比如医生、客服,不是每个工作人员每天都在的,每个人可工作的时间是不一样的,比如张三可能是周一和周三,李四可能是周四和周六,给定每个人可工作的时间,我们可能有一些问题需要回答,比如:
- 有没有哪天一个人都不会来?
- 有哪些天至少会有一个人来?
- 有哪些天至少会有两个人来?
- 有哪些天所有人都会来,以便开会?
- 哪些人周一和周二都会来?
使用EnumSet,可以方便高效地回答这些问题,怎么做呢?我们先来定义一个表示工作人员的类Worker,如下所示:
class Worker { String name; Set<Day> availableDays; public Worker(String name, Set<Day> availableDays) { this.name = name; this.availableDays = availableDays; } public String getName() { return name; } public Set<Day> getAvailableDays() { return availableDays; } }
为演示方便,将所有工作人员的信息放到一个数组workers中,如下所示:
Worker[] workers = new Worker[]{ new Worker("张三", EnumSet.of( Day.MONDAY, Day.TUESDAY, Day.WEDNESDAY, Day.FRIDAY)), new Worker("李四", EnumSet.of( Day.TUESDAY, Day.THURSDAY, Day.SATURDAY)), new Worker("王五", EnumSet.of( Day.TUESDAY, Day.THURSDAY)), };
每个工作人员的可工作时间用一个EnumSet表示。有了这个信息,我们就可以回答以上的问题了。
哪些天一个人都不会来?代码可以为:
Set<Day> days = EnumSet.allOf(Day.class); for(Worker w : workers){ days.removeAll(w.getAvailableDays()); } System.out.println(days);
days初始化为所有值,然后遍历workers,从days中删除可工作的所有时间,最终剩下的就是一个人都不会来的时间,这实际是在求worker时间并集的补集,输出为:
[SUNDAY]
有哪些天至少会有一个人来?就是求worker时间的并集,代码可以为:
Set<Day> days = EnumSet.noneOf(Day.class); for(Worker w : workers){ days.addAll(w.getAvailableDays()); } System.out.println(days);
输出为:
[MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY]
有哪些天所有人都会来?就是求worker时间的交集,代码可以为:
Set<Day> days = EnumSet.allOf(Day.class); for(Worker w : workers){ days.retainAll(w.getAvailableDays()); } System.out.println(days);
输出为:
[TUESDAY]
哪些人周一和周二都会来?使用containsAll方法,代码可以为:
Set<Worker> availableWorkers = new HashSet<Worker>(); for(Worker w : workers){ if(w.getAvailableDays().containsAll( EnumSet.of(Day.MONDAY,Day.TUESDAY))){ availableWorkers.add(w); } } for(Worker w : availableWorkers){ System.out.println(w.getName()); }
输出为:
张三
哪些天至少会有两个人来?我们先使用EnumMap统计每天的人数,然后找出至少有两个人的天,代码可以为:
Map<Day, Integer> countMap = new EnumMap<>(Day.class); for(Worker w : workers){ for(Day d : w.getAvailableDays()){ Integer count = countMap.get(d); countMap.put(d, count==null?1:count+1); } } Set<Day> days = EnumSet.noneOf(Day.class); for(Map.Entry<Day, Integer> entry : countMap.entrySet()){ if(entry.getValue()>=2){ days.add(entry.getKey()); } } System.out.println(days);
输出为:
[TUESDAY, THURSDAY]
理解了EnumSet的使用,下面我们来看它是怎么实现的。
实现原理
位向量
EnumSet是使用位向量实现的,什么是位向量呢?就是用一个位表示一个元素的状态,用一组位表示一个集合的状态,每个位对应一个元素,而状态只可能有两种。
对于之前的枚举类Day,它有7个枚举值,一个Day的集合就可以用一个字节byte表示,最高位不用,设为0,最右边的位对应顺序最小的枚举值,从右到左,每位对应一个枚举值,1表示包含该元素,0表示不含该元素。
比如,表示包含Day.MONDAY,Day.TUESDAY,Day.WEDNESDAY,Day.FRIDAY的集合,位向量图示结构如下:

对应的整数是23。
位向量能表示的元素个数与向量长度有关,一个byte类型能表示8个元素,一个long类型能表示64个元素,那EnumSet用的长度是多少呢?
EnumSet是一个抽象类,它没有定义使用的向量长度,它有两个子类,RegularEnumSet和JumboEnumSet。RegularEnumSet使用一个long类型的变量作为位向量,long类型的位长度是64,而JumboEnumSet使用一个long类型的数组。如果枚举值个数小于等于64,则静态工厂方法中创建的就是RegularEnumSet,大于64的话就是JumboEnumSet。
内部组成
理解了位向量的基本概念,我们来看EnumSet的实现,同EnumMap一样,它也有表示类型信息和所有枚举值的实例变量,如下所示:
final Class<E> elementType; final Enum[] universe;
elementType表示类型信息,universe表示枚举类的所有枚举值。
EnumSet自身没有记录元素个数的变量,也没有位向量,它们是子类维护的。
对于RegularEnumSet,它用一个long类型表示位向量,代码为:
private long elements = 0L;
它没有定义表示元素个数的变量,是实时计算出来的,计算的代码是:
public int size() { return Long.bitCount(elements); }
对于JumboEnumSet,它用一个long数组表示,有单独的size变量,代码为:
private long elements[]; private int size = 0;
静态工厂方法
我们来看EnumSet的静态工厂方法noneOf,代码为:
public static <E extends Enum<E>> EnumSet<E> noneOf(Class<E> elementType) { Enum[] universe = getUniverse(elementType); if (universe == null) throw new ClassCastException(elementType + " not an enum"); if (universe.length <= 64) return new RegularEnumSet<>(elementType, universe); else return new JumboEnumSet<>(elementType, universe); }
getUniverse的代码与上节介绍的EnumMap是一样的,就不赘述了。如果元素个数不超过64,就创建RegularEnumSet,否则创建JumboEnumSet。
RegularEnumSet和JumboEnumSet的构造方法为:
RegularEnumSet(Class<E>elementType, Enum[] universe) { super(elementType, universe); } JumboEnumSet(Class<E>elementType, Enum[] universe) { super(elementType, universe); elements = new long[(universe.length + 63) >>> 6]; }
它们都调用了父类EnumSet的构造方法,其代码为:
EnumSet(Class<E>elementType, Enum[] universe) { this.elementType = elementType; this.universe = universe; }
就是给实例变量赋值,JumboEnumSet根据元素个数分配足够长度的long数组。
其他工厂方法基本都是先调用noneOf构造一个空的集合,然后再调用添加方法,我们来看添加方法。
添加元素
RegularEnumSet的add方法的代码为:
public boolean add(E e) { typeCheck(e); long oldElements = elements; elements |= (1L << ((Enum)e).ordinal()); return elements != oldElements; }
主要代码是按位或操作:
elements |= (1L << ((Enum)e).ordinal());
(1L << ((Enum)e).ordinal())将元素e对应的位设为1,与现有的位向量elements相或,就表示添加e了。从集合论的观点来看,这就是求集合的并集。
JumboEnumSet的add方法的代码为:
public boolean add(E e) { typeCheck(e); int eOrdinal = e.ordinal(); int eWordNum = eOrdinal >>> 6; long oldElements = elements[eWordNum]; elements[eWordNum] |= (1L << eOrdinal); boolean result = (elements[eWordNum] != oldElements); if (result) size++; return result; }
与RegularEnumSet的add方法的区别是,它先找对应的数组位置,eOrdinal >>> 6就是eOrdinal除以64,eWordNum就表示数组索引,有了索引之后,其他操作与RegularEnumSet就类似了。
对于其他操作,JumboEnumSet的思路是类似的,主要算法与RegularEnumSet一样,主要是增加了寻找对应long位向量的操作,或者有一些循环处理,逻辑也都比较简单,后文就只介绍RegularEnumSet的实现了。
RegularEnumSet的addAll方法的代码为:
public boolean addAll(Collection<? extends E> c) { if (!(c instanceof RegularEnumSet)) return super.addAll(c); RegularEnumSet es = (RegularEnumSet)c; if (es.elementType != elementType) { if (es.isEmpty()) return false; else throw new ClassCastException( es.elementType + " != " + elementType); } long oldElements = elements; elements |= es.elements; return elements != oldElements; }
类型正确的话,就是按位或操作。
删除元素
remove方法的代码为:
public boolean remove(Object e) { if (e == null) return false; Class eClass = e.getClass(); if (eClass != elementType && eClass.getSuperclass() != elementType) return false; long oldElements = elements; elements &= ~(1L << ((Enum)e).ordinal()); return elements != oldElements; }
主要代码是:
elements &= ~(1L << ((Enum)e).ordinal());
~是取反,该代码将元素e对应的位设为了0,这样就完成了删除。
从集合论的观点来看,remove就是求集合的差,A-B等价于A∩B',B'表示B的补集。代码中,elements相当于A,(1L << ((Enum)e).ordinal())相当于B,~(1L << ((Enum)e).ordinal())相当于B',elements &= ~(1L << ((Enum)e).ordinal())就相当于A∩B',即A-B。
查看是否包含某元素
contains方法的代码为:
public boolean contains(Object e) { if (e == null) return false; Class eClass = e.getClass(); if (eClass != elementType && eClass.getSuperclass() != elementType) return false; return (elements & (1L << ((Enum)e).ordinal())) != 0; }
代码也很简单,按位与操作,不为0,则表示包含。
查看是否包含集合中的所有元素
containsAll方法的代码为:
public boolean containsAll(Collection<?> c) { if (!(c instanceof RegularEnumSet)) return super.containsAll(c); RegularEnumSet es = (RegularEnumSet)c; if (es.elementType != elementType) return es.isEmpty(); return (es.elements & ~elements) == 0; }
最后的位操作有点晦涩。我们从集合论的角度解释下,containsAll就是在检查参数c表示的集合是不是当前集合的子集。一般而言,集合B是集合A的子集,即B⊆A,等价于A'∩B是空集∅,A'表示A的补集,如下图所示:
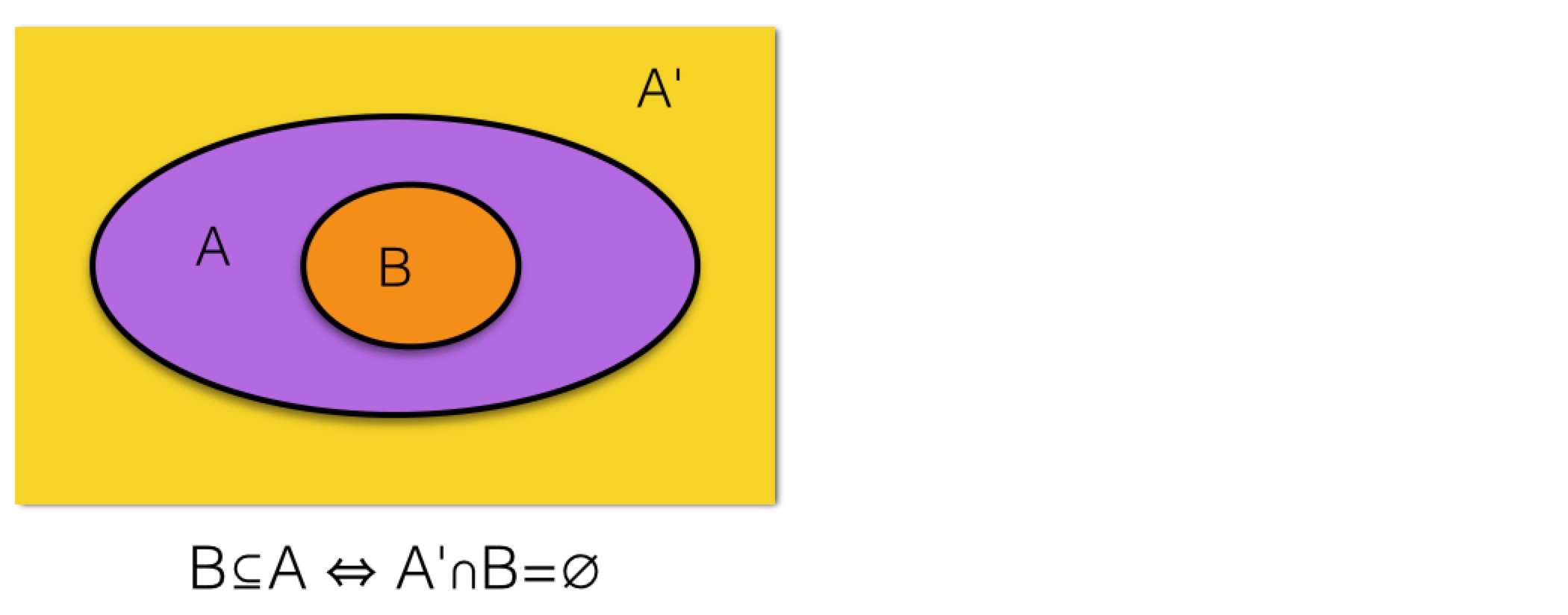
上面代码中,elements相当于A,es.elements相当于B,~elements相当于求A的补集,(es.elements & ~elements) == 0;就是在验证A'∩B是不是空集,即B是不是A的子集。
只保留参数集合中有的元素
retainAll方法的代码为:
public boolean retainAll(Collection<?> c) { if (!(c instanceof RegularEnumSet)) return super.retainAll(c); RegularEnumSet<?> es = (RegularEnumSet<?>)c; if (es.elementType != elementType) { boolean changed = (elements != 0); elements = 0; return changed; } long oldElements = elements; elements &= es.elements; return elements != oldElements; }
从集合论的观点来看,这就是求集合的交集,所以主要代码就是按位与操作,容易理解。
求补集
EnumSet的静态工厂方法complementOf是求补集,它调用的代码是:
void complement() { if (universe.length != 0) { elements = ~elements; elements &= -1L >>> -universe.length; // Mask unused bits } }
这段代码也有点晦涩,elements=~elements比较容易理解,就是按位取反,相当于就是取补集,但我们知道elements是64位的,当前枚举类可能没有用那么多位,取反后高位部分都变为了1,需要将超出universe.length的部分设为0。下面代码就是在做这件事:
elements &= -1L >>> -universe.length;
-1L是64位全1的二进制,我们在剖析Integer一节介绍过移动位数是负数的情况,上面代码相当于:
elements &= -1L >>> (64-universe.length);
如果universe.length为7,则-1L>>>(64-7)就是二进制的1111111,与elements相与,就会将超出universe.length部分的右边的57位都变为0。
实现原理小结
以上就是EnumSet的基本实现原理,内部使用位向量,表示很简洁,节省空间,大部分操作都是按位运算,效率极高。
小结
本节介绍了EnumSet的用法和实现原理,用法上,它是处理枚举类型数据的一把利器,简洁方便,实现原理上,它使用位向量,精简高效。
对于只有两种状态,且需要进行集合运算的数据,使用位向量进行表示、位运算进行处理,是计算机程序中一种常用的思维方式。
至此,关于具体的容器类,我们就介绍完了。Java容器类中还有一些过时的容器类,以及一些不常用的类,我们就不介绍了。
在介绍具体容器类的过程中,我们忽略了一个实现细节,那就是,所有容器类其实都不是从头构建的,它们都继承了一些抽象容器类。这些抽象类提供了容器接口的部分实现,方便了Java具体容器类的实现。如果我们需要实现自定义的容器类,也应该考虑从这些抽象类继承。
那,具体都有什么抽象类?它们都提供了哪些基础功能?如何进行扩展呢?让我们下节来探讨。
----------------
未完待续,查看最新文章,敬请关注微信公众号“老马说编程”(扫描下方二维码),从入门到高级,深入浅出,老马和你一起探索Java编程及计算机技术的本质。用心原创,保留所有版权。


