


游戏汉化教程1-汉化流程
游戏汉化流程
游戏汉化是非常具有挑战和成就感的,挑战在于和游戏开发商斗智斗勇,想尽一切办法层层拨开文件,得到最后需要汉化的资源,其过程不亚于一段推理。成就感就不用说了,和开发程序一样的,谁不愿意看到自己的作品被很多人使用呢?
实际上,游戏的汉化流程非常简单,如下图所示:
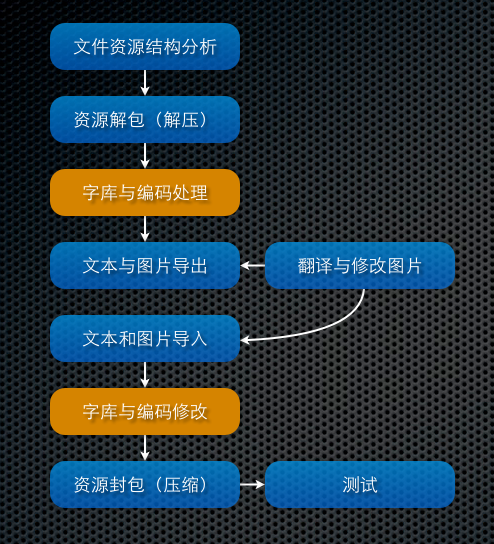
其中,黄色的表示要根据实际情况进行处理,大部分游戏是需要处理字库和编码(字库和编码的处理属于汉化中难度比较大的一个技术环节,后面的教程会详细说明)的,不过如果运气好遇到一些比较厚道的厂商(比如我们汉化的托托莉的工作室,采用Unicode编码,TrueType字库,那就可以直接利用ttf字库,而不需要重新生成字库了),那么这个环节就简单多了。
OK,我们还是按照流程来说,上图整个左边就是汉化组中,程序需要做的工作。看起来几个简单的步骤,实际上每一步都还可以拆分的更细,每一步要做的工作也不会很少。
首先是要多整个游戏的文件资源进行分析,一般来说,游戏的资源都不是我们平时在Windows或者Linux下常见的文件类型,而是一些游戏厂商利用第三方工具处理或者自己开发的文件格式。例如PS3的psarc格式(playstation archive),CRIWare的cpk等等。这些文件都是对游戏资源的一个压缩打包,作用是减小游戏的体积并且减少零碎文件的存在,以提升游戏的运行效率。这些文件有些可以直接利用现成的工具解包,有些则需要分析封包数据来自己编写解包程序。
游戏资源解包以后,就要开始寻找文本了,寻找文本以前,首先要搞清楚游戏文本所用的编码方式,一般来说,PS3上的日文游戏采用的是UTF8、ShiftJIS等编码,也有游戏使用的自定义编码(自定义编码处理起来稍微麻烦一些,不过到目前为止,还没有在PS3上遇到过自定义编码的,PSP上倒是有)。找编码的方式有几种,一是先找到字库(大部分游戏是自制字库,整个字库就是一张图片,整图或者Tile图片),通过字库可以观察出游戏的文本编码。二是对文件进行16进制搜索,先在游戏中找到一段对话,然后利用工具在资源中选择不同的编码方式进行搜索,对于非自定义编码,第二种方式比较简单,对于自定义编码,可以采用相对搜索方式(或者叫差值搜索),这种方式就需要结合字库来进行。寻找字库和编码常用的工具有CrystalTile2(天使汉化组的一款功能比较强大的工具),还有一个是我近期才编写的16进制搜索工具(源代码在这里),我在网上找的16进制搜索工具都不太好用,不太适合汉化。
文本搞定以后,就需要处理游戏图片了,一般游戏图片上也包含了需要汉化的内容(比如封面之类的),游戏的图片常见格式为PNG或者DDS(当然还有其他格式)。但是这些图片一般都不是直接就乖乖的躺在资源文件里面,而是用一种厂商自定义的格式来封装了一下(也就是加了些文件头信息和控制数据,但是图片内容数据本身就是位图),所以只需要去掉这些自定义的文件头信息,换成BMP或者DDS的文件头即可用常用图片阅览器打开。
文本和图片搞定以后,要做的就是编写一个程序来导出文本和图片(最好是批量工具,能整体处理某一个文件夹下的所有文件)。图片还好,一般包装的文件格式都比较简单,文本就不一样了,千差万别。所以,为了导出文本,还需要读懂文本包装文件的数据。比如一个文本包装文件,包含头信息,里面告诉了你这个文件包含多少句文本,同时,每一句文本前还有控制数据,告诉你这句文本总共包含了多少字节的数据(但一般都直接利用一个特殊字节来做为每一句的结束,例如0x00)。所以,我们需要读懂这些数据来编写导入导出程序。
上面的工作完成后,汉化就基本完成一半了,这个时候,还不要急着把文本和图片丢给翻译,一个拥有良好习惯的程序员总是要自测一下自己的程序的。我们需要将解包的资源封包,放回游戏,看看有没有问题,如果没有问题,则将导出的文本随便修改一些,再导入放回游戏,看看在游戏里面是否有效果等等。完成一系列的测试后,再交给翻译人员,不要等翻译完了,才发现,不能封包什么的,那就亏大了。
翻译完成后,程序要做的事情实际上就是翻译前的一个逆向过程了,就像上山总要下山一样。不过一般的汉化组的程序会在编写导出程序的同时,就完成了导入程序的开发,并且,按照我的习惯,会利用我的程序来将导出的资源导入回去,与原始文件做一次MD5校验,必须保证完全一致,才能确保在游戏中不出问题。
以上就是整个汉化的大致流程,比较粗,实际上整个汉化过程会非常繁琐,而且有时候一个很小的细节,就会导致游戏出现各种问题。我会在后面的文章中,把每一个步骤都细分,然后结合实例来编写这部汉化教程。教程中所有涉及到的源代码,我会在Github上共享。

