[python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。就算可以弄下来,但是我们需要几千个页面当中的图片,如果一个一个下载,你的手将残。好吧~!其实你很厉害的,右键查看页面源代码。
我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一、获取整个页面数据

def get_content(url):
"""
获取网页源码
"""
html = urllib.urlopen(url)
content = html.read()
html.close()
return content
二、抓取图片文件名
抓取文件名时,由于特殊符号会影响显示,所以将“ * ”,“ / ”等符号删
def get_name(name,file):
"""
抓取图片文件名
"""
self.picName = name.decode('utf-8')
if "*" in self.picName:
self.picName = self.picName.replace("*","")
elif "/" in self.picName:
self.picName = self.picName.replace("/","")
print self.picName
def get_file(info):
"""
获取img文件
"""
soup = BeautifulSoup(info,"html.parser")
# 找到所有免费下载的模块
all_files = soup.find_all('a',title="免费下载")
# 找到所有的hi标题
titles = soup.find_all('h1')
# 截取需要的标题
for title in titles:
name = str(title)[4:-5]
# 获取文件名
for file in all_files:
get_name(name,file)
三、下载图片
下载后缀名是"gif"或者"jpg"的图片,并存放在E:\\googleDownLoad\\\cssmuban目录下
def pic_category(str_images):
"""
下载图片
"""
soup = BeautifulSoup(info,"html.parser")
all_image = soup.find_all('div',class_="large-Imgs")
images = str_images
pat = re.compile(images)
image_code = re.findall(pat,str(all_image))
for i in image_code:
if str(i)[-3:] == 'gif':
image = urllib.urlretrieve('http://www.cssmoban.com'+str(i), 'E:\\googleDownLoad\\\cssmuban\\'+str(self.picName).decode('utf-8')+'.gif')
else:
image = urllib.urlretrieve('http://www.cssmoban.com'+str(i), 'E:\\googleDownLoad\\\cssmuban\\'+str(self.picName).decode('utf-8')+'.jpg')
def pic_download(info):
"""
下载图片
"""
pic_category(r'src="(.+?\.gif)"')
pic_category(r'src="(.+?\.jpg)"')
四、遍历所有url,下载每个页面的所需要的图片和文件名
self.num = 1
# 下载文件
for i in range(6000):
url = 'http://www.cssmoban.com/cssthemes/'+ str(self.num) +'.shtml'
info = get_content(url)
get_file(info)
pic_download(info)
self.num = self.num + 1
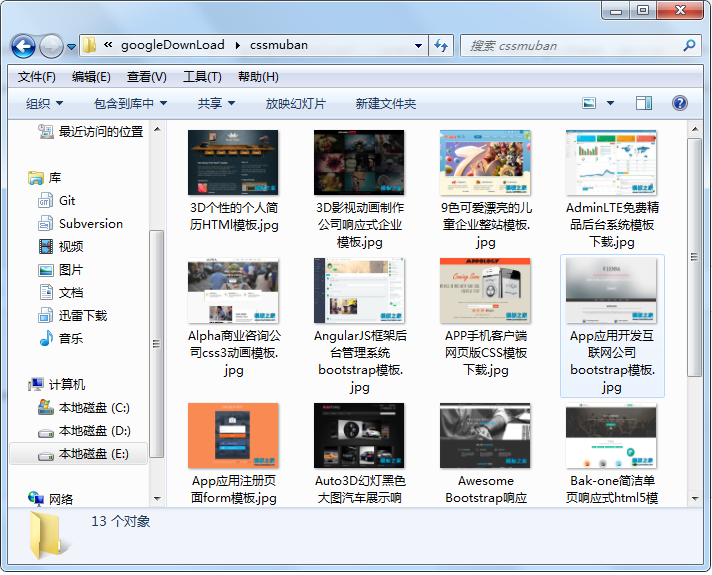
运行结果如下:

本站文章为 宝宝巴士 SD.Team 原创,转载务必在明显处注明:(作者官方网站: 宝宝巴士 )
转载自【宝宝巴士SuperDo团队】 原文链接: http://www.cnblogs.com/superdo/p/4927574.html
比大多数人的努力程度之低,根本轮不到拼天赋...
宝宝巴士 SD.Team

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步