20162330 2017-2018-1《程序设计与数据结构》第十一周学习总结
2017-2018-1 学习总结目录: 1 2 3 5 6 7 9 10 11 12
目录
- 0. 教材学习内容总结
- 0.1 哈希方法
- 0.2 哈希函数
- 0.3 解决问题
- 0.4 从哈希表中删除元素
- 0.5 Java Collections API 中的哈希表
- 1. 教材学习中的问题和解决过程
- 1.1 哈希表变满时,其性能会严重下降
- 1.2 最短路径算法中的Path列表值
- 1.3 陈留余数法中确定H(key)中的key与哪个数取余
- 1.4 互联网的搜索引擎对网页建立索引
教材学习内容总结
哈希方法
-
集合中元素的次序:
由元素添加到集合中或从集合中删除的次序决定。(栈、队列)
由保存在集合中的元素值的比较结果而定。(有序表、二叉查找树)
-
在哈希方法中,元素保存在哈希表中,元素在表中的位置由哈希函数决定。哈希表中的每个位置称为单元或桶。
-
使用哈希方法使得对某个元素的访问时间不依赖于表中的元素个数,不一定比较或定位,只需计算一个具体元素应该放在哪里。
对哈希表中一个元素的所有操作都将是 O(1).
-
冲突:两个元素或关键字都映射到表中的同一个位置。
-
理想哈希函数:将每个元素映射到表中唯一位置的哈希函数。
对表中元素都有常数的访问时间 O(1).
-
哈希表的扩容:使用装载因子动态调整。
在之前使用数组实现栈时,使用了动态调整的方法实现扩容:
private void expandCapacity() { T[] larger = (T[]) (new Object[stack.length * 2]); for (int index = 0; index < stack.length; index++) larger[index] = stack[index]; stack = larger; }即当数组满了时,创建一个原来两倍大小的数组,将原数组中的所有元素插入到新数组中,然后更新原数组的指向。但是对于哈希表来说,当表变满时其性能严重下降,所以更好的方法是使用装载因子。(哈希表扩展之前,表中允许的最大占有百分比,API 中默认为0.75)
哈希函数
-
哈希函数能够合理地将元素散列到表中以避免冲突。
合理的哈希函数仍能得到对数据集的常数阶 O(1)访问时间。
-
建立哈希函数的方法:
抽取:仅使用元素值或关键字中的一部分来计算保存元素的位置。(电话号码、车牌号)
除法:将使用关键字除以某个正整数后的余数作为下标。
Hashcode(key) = Math.abs(key) % p
将表的大小当做 p 可根据下标直接得到元素在表中的位置。使用 p 作为表长和除数,有助于更好地散列关键字。(处理未知关键字)折叠:分段,注意每个子段的长度和下标的长度一样,最后一段可能稍短。
分类:移位折叠(分段相加)、边界折叠(分段反转)。
【注】字符串可以用除法,也可以用折叠方法,使用异或函数将子串组合,转换为数值。平方取中:关键字自乘,抽取结果中部,每次选择的中部位必须相同。
基数转换:关键字转换为另一种数值基数。
数字分析:抽取关键字中的指定位进行处理。(多种方式)
长度依赖:关键字和关键字的长度组合,或者再进一步使用其他方法进行处理而得到下标。
【注】将字符串中各字符按二进制格式进行处理,长度依赖和平方取中方法也能适用于字符串。 -
java.lang.Object类定义了 hashcode 方法,根据对象在内存中的位置返回一个整数。所有的Java对象都能用于哈希方法,但对特定类最好还是定义一个具体的哈希函数。
解决冲突
-
链式方法:将哈希表看成是集合的表而不是各独立单元的表。
每个单元中保存一个指针,指向与表中该位置相关的元素集合。
-
链式方法的实现方式:
① 令保存表的数组大于表中的元素个数,利用额外的空间作为溢出区来保存与每个表相对应的链表;数组中的每个位置既保存元素(关键字),又保存链表中下一个元素在数组中的下标。
② 使用链,哈希表中的每个单元或桶都类似于之前构造链表时使用过的 LinearNode 类;
③ 让表中的每个位置当做指向集合的指针。 -
开放地址方法:在表中寻找不同于该元素原先哈希到的另一个开放的位置。(待学习)
从哈希表中删除元素
-
链式实现中删除:5种情形。(某一位置、表中(非溢出 → 溢出)、表尾、表的中间、不在表中)
-
开放地址实现中删除:标注,被覆盖,重新处理。
Java Collections API 中的哈希表
- 提供方案:
Hashtable、HashMap、HashSet、IdentityHashMap、LinkedHashSet、LinkedHashMap、WeakHashMap.
教材学习中的问题和解决过程
-
【问题1】:书中的第一部分内容介绍哈希方法时,为什么哈希表变满时,其性能会严重下降?
-
解决方案 :我继续读了课本,结合哈希函数的定义,并且查找了一些资料,大致弄懂了。
当关键字集合很大时,关键字值不同的元素可能会映射到哈希表的同一地址上,即 k1≠k2 ,但 H(k1)=H(k2),这种现象称为 冲突,此时称k1和k2为同义词。实际中,冲突是不可避免的,只能通过改进哈希函数的性能来减少冲突。
哈希函数不仅要容易计算,而且要对键值的分布要均匀。如果有太多的冲突,哈希表的性能将显著下降,例如下面的哈希函数:public static int hash(String key , int tableSize){ int hashVal = 0; for(int i=0;i<key.length;i++){ hashVal+=key.charAt(i); } return hashVal%tableSize; }这个哈希函数很简单,很容易实现,计算哈希值也非常快,但这是个糟糕的哈希函数。
假设tableSize很大,为10000,再假设所有的关键字值的长度都是8个或少于8个字符。因为一个ASCII char是一个0到127之间的整数,那么哈希函数的值介于0到1016(127*8)之间,这个限制肯定不会产生一个均匀的分布。
所以后来才有了解决冲突、保证均匀分布的链式方法和开放地址方法。
-
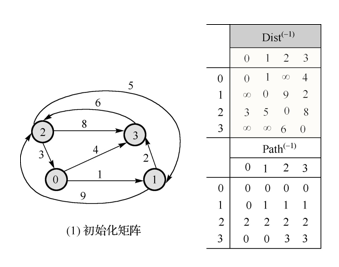
【问题2】:在解答“门票”上莫礼钟的问题时引发的思考:最短路径算法中的Path列表值表示什么?(如图所示)
-
解决方案 :(查找资料)
课堂上只讲了数值的规律,并没有解释原因。查找资料之后,我发现图中对应Disk(-1)的路径Path(-1)是说:矩阵Path记录 u,v 两点之间最短路径所必须经过的点的数量,所以这里的规律可以表示为:对应Disk表中无穷的值在Path中都为0,其他非无穷的值对应每行点 u (起始点)的值。
-
【问题3】:陈留余数法中如何确定H(key)中的key与哪个数取余?
-
解决方案 :(查找资料)
对于散列表长为 m 的散列函数公式为:f( key ) = key mod p ( p ≤ m ),若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。这么做是因为如果 p 的约数越多,那么冲突的几率就越大,这样余数相同的数就会增加,从而使得散列表第一次处理数据时的利用率降低,从而增加了算法复杂度,以上是个人理解。下面举一个查到的例子说明一下:某散列表的长度为100,散列函数 H(k) = k%P ,则P通常情况下最好选择哪个呢?
A、91 B、93 C、97 D、99【解析】实践证明,当P取小于哈希表长的最大质数时,产生的哈希函数较好。我选97,因为它是离长度值最近的最大质数。
-
至于为什么P应该这么选取,以下简单的证明过程:(gcd表示最大公约数)
假设 p 是一个有较多约数的数,同时在数据中存在 key 满足最大公约数 gcd(p,key) = d > 1 ,即有 p = a·d , key = b·d ,则有以下等式:key % p = key – p·[key/p] = key – p·[b/a] 。其中,[b / a]的取值范围是不会超过[0,a-1]的正整数。也就是说,[b / a]的值只有a 种可能,而p 是一个预先确定的数。因此上式的值就只有a 种可能了(这显然缩小了余数分布的范围)。这样,取 mod 运算之后的余数仍然在[0,p-1]内,但是它的取值仅限于等式可能取到的那些值,也就是说余数的分布变得不均匀了。容易看出,p 的约数越多,发生这种余数分布不均匀的情况就越频繁,冲突的几率越高。而素数的约数是最少的,因此我们选用大素数。所以 p应该最优选择素数。
-
【问题4】:关于索引在生活中的应用,互联网的搜索引擎是如何对网页建立索引从而实现筛选和排序的呢?
-
解决方案 :(阅读吴军老师的《数学之美》)

在第 8 章的内容中,书中谈到搜索引擎,对于我需要的答案,可以整合如下:
计算机做布尔运算是非常非常快的。现在最便宜的微机都可以一次进行三十二位布尔运算,一秒钟进行十亿次以上。当然,由于这些二进制数中绝大部分位数都是零,我们只需要记录那些等于1的位数即可。于是,搜索引擎的索引就变成了一张大表:表的每一行对应一个关键词,而每一个关键词后面跟着一组数字,是包含该关键词的文献序号。
对于互联网的搜索引擎来讲,每一个网页就是一个文献。互联网的网页数量是巨大的,网络中所用的词也非常多。因此,这个索引是巨大的。早期的搜索引擎,由于计算机速度和容量的限制,只能对重要、关键的主题词建立索引。至今很多学术杂志还要求作者提供 3-5 个关键词。这样,所有不常见的词和太常见的虚词就找不到了。现在,为了保证对任何搜索都能提供相关的网页,常见的搜索引擎都会对所有的词进行索引。但是,这在工程上却极具挑战性。
假如互联网上有 100 亿个有意义的网页,而词汇表的大小至少是30万,那么这个索引的大小至少是 100 亿 x 30万 = 3000 万亿。考虑到大多数词只出现在一部分文本中,压缩比为100:1,也是30万亿的量级。为了网页 排名方便,索引中还需存有大量附加信息,诸如每个词出现的位置、次数等等。因此,整个索引就变得非常之大,显然,这不是一台服务器的内存能够存下的。所以,这些索引需要通过分布式的方式存储到不同的服务器上。普遍的做法就是根据网页的序号将索引分成很多份,分别存储在不同的服务器中。每当接受一个查询时,这个查询就被分发到许许多多的服务器中,这些服务器同时并行处理用户请求,并把结果送到主服务器进行合并处理,最后将结果返回给用户。
随着互联网上内容的增加,尤其是互联网 2.0 时代,用户产生的内容越来越多,即使是Google这样的服务器数量近乎无限的公司,也感到了数据增加带来的压力。因此,需要根据网页的重要性、质量和访问的频率建立常用和非常用等不同级别的索引。常用索引需要访问的速度快,附加信息多,更新也要快;而非常用的要求就低多了。但是不论搜索引擎的索引在工程上如何复杂,原理上依然非常简单,即等价于布尔运算。
代码调试中的问题和解决过程
- 暂无。
代码托管
- 本周代码上传至 test 文件夹中:
(statistics.sh脚本的运行结果截图)
上周考试错题总结
- 【错题1】Consider a digraph with the following vertices and edges:
vertices: 1, 2, 3, 4
edges: (1,2), (2,1), (3,4)
Which of the following statements are true?
A.The graph has a cycle
B.The graph is connected
C.The graph is acyclic
D.all of the above are true
E.neither a, b, nor c are true.
-
错误原因:对环的概念理解有误,在两个元素之间也可能形成环,错选C。
解析:这个图有一个循环,即边(1,2)和(2,1)。因为在1和4之间没有路径,所以没有连接。 -
【错题2】A graph is a special kind of tree.
A.true
B .false -
错误原因:没有认真思考树和图的关系,错选A。
加深理解:树是一种特殊的图,教材的第420页提到树总是图,所以所有的树都是图,而所有的图不一定是树,所以树是一种特殊的图。 -
A cycle is a path that starts and ends on the same vertex.
A.true
B .false -
错误原因:对环的定义理解不清,之前有考虑过重复边,但还是错选A。
加深理解:一个环是一条在同一顶点开始和结束的路径,并且不会有任何重复边。
结对及互评
本周结对学习情况
-
莫礼钟本周状态一般,在团队上面,需要再积极主动一些。在个人学习方面,听课效率不错,下来我们又一起讨论了关于如何画出AOE网实现工程中的最短路径问题,本周结对学习内容较少,还有些问题在门票活动中已给出回答。
-
- 结对学习内容
- 使用AOE网实现工程中的最短路径
- 结对学习内容
其他(感悟、思考等,可选)
本周算是比较忙的一周,个人作业除了完成课堂上关于图的活动之外,还在课下大致学习了第二十章的内容。在课堂上娄老师加入了“出门门票”的活动,支持。
本周的团队作业有些散导致在分工时有些没头绪,这次团队任务按要求应该把 代码规范、后端架构、WBS图、优先级象限图、ER图、燃尽图、TODOList 都呈现出来才算完成吧?虽然我们组的代码规范仍需要补充,但是在所有团队当中算是最完整的一组了,为自己鼓掌!我们几个人分别使用对应软件先进行学习,再按要求完成,有的能使用Xmind代替就用Xmind了。当然在学习软件或者功能的过程中,有的任务完成得还不够熟练和规范,使用一个软件并不是一周就可以熟练运用的。例如我负责的燃尽图,按照给出参考资料的方法这个图在码云上是生成不了的(因为生成网站只针对github上的milestone),用命令行在虚拟机中装了一大堆插件还是运行错误,只好在 github 上重建一个项目,挺费劲才弄出来,但是我发现小组成员用的一些软件可以自动生成,下周我打算再试试。
每次看到我们团队的总投入时间都比其他团队多,而其他团队的成员可以把这部分时间用在个人学习或者其他事情上,总感觉有些憋屈,但是从长远的角度来看,多学会使用几种工具软件、提高一下搜商何尝不是一件乐事呢?这大概是一件重要但不紧急的事。从其他团队的情况看我们团队算是优秀的团队了,但是和其他大学(北航、福大等)的软件工程团队比起来还是差得太远。总之,我们团队会做好自己的分内之事,完成质量方面尽力即可。
-
【附1】教材及考试题中涉及到的英语:
Chinese English Chinese English 冲突 collision 动态调整 dynamic resizing 抽取 extraction 线性探测 linear probing -
【附2】本周小组博客
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 234/234 | 1/28 | 14/14 | 了解算法效率、大O符号等理论内容 |
| 第二周 | 255/489 | 1/29 | 12/26 | 了解敏捷的团队、泛型的使用 |
| 第三周 | 436/925 | 2/31 | 10/36 | 了解一些查找和排序的算法 |
| 第四周 | 977/1902 | 3/34 | 10/46 | 掌握实现线性结构 |
| 第五周 | 800/2702 | 2/36 | 12/58 | 掌握实现栈集合 |
| 第六周 | 260/2962 | 1/37 | 8/64 | 掌握实现队列集合 |
| 第七周 | 843/3805 | 4/41 | 12/76 | 掌握实现树的基本结构 |
| 第八周 | 738/4543 | 1/42 | 12/88 | 二叉树实验(查找树、平衡树) |
| 第九周 | 1488/6031 | 2/44 | 15/103 | 掌握堆的实现、哈夫曼树基本结构 |
| 第十周 | 1340/7371 | 2/46 | 12/115 | 查找与排序实验、图的基本概念及实现方法 |
| 第十一周 | 436/7807 | 3/49 | 17/132 | 图的遍历方法、最短路径等问题、大致了解哈希方法 |
-
计划学习时间:20小时
-
实际学习时间:17小时
-
有效学习时间:4小时
-
改进情况:本周学习时间有增加,对于团队项目中一些工具的用途还需多了解一些,以便更好地组织团队完成任务。
