
第六次作业--结对编程第二次
第六次作业--结对编程第二次
结对情况:123 兴桔 and 124 晗
队友博客地址
设计说明
-
接口设计
生成输入数据: Distribution.exe -c a b // a,b > 0 // -c表示生成json数据,a表示学生个数,b表示部门个数,自动生成sa-db-in.json文件到工作目录下 匹配并输出数据: Distribution.exe -mdt a b // a,b > 0 // -mdt表示先按志愿优先,再匹配时间的匹配方式,a表示学生个数,b表示部门个数,输出到工作目录下的sa-db-out.json文件 Distribution.exe -mdl a b // a,b > 0 // -mlt表示先按志愿优先,再匹配标签的匹配方式,a表示学生个数,b表示部门个数,输出到工作目录下的sa-db-out.json文件
内部实现设计(类图)

匹配算法设计(思想/流程等)
-
因为学生刚入学大家都是从零开始,所以处理学生申请的顺序由提交的时间决定,先提交的先处理。
-
保证学生优先原则,尽量保证学生能够选到自己心仪的部门。同时也尽量保证每个部门都能招到学生
-
保证学生的部门意愿优先为第一原则,每个人的意愿分为第一档到第五档,部门优先选择第一档的学生。
-
第一种:先处理每个人的第一志愿,按空闲时间匹配,部门的工作时间有其中一次与学生的空闲时间相符,并且所需学生未招满,则优先选择此学生,并且该学生的此次空闲时间将不再空闲。处理完所有人的第一志愿,接着处理二三四五志愿。再从第一志愿带第五志愿循环一遍,这次只要部门还有名额就招入处理完所有志愿后,把所有服从调剂的学生选择出来,如果该学生没有入选任何一个部门,则把他放入其中一个未招满的部门中。优先放入未招到人的部门,其次优先放入招的人数相差过大的部门。
-
第二种:先根据志愿,再根据标签匹配,满足一种标签即可,其他与第一种相同。
测试数据如何生成?
通过随机函数进行生成,不过因为是自己做的数据,所以做了一定的简化。具体如何用代码生成在上文的接口设计中有写。
输入数据
学生:
学号 // 8位数
标签 // 不多于5个
空闲时间 // 输入格式为xx:xx xx:xx 时间范围在每天8:00 至 22:00
部门意愿 // 最多不超过5个,数据为部门编号
是否服从调剂 // 0/1 1表示服从
部门:
部门编号 // 4位数
部门需要的学生数 // [0,15]
标签 // 不多于10个
工作时间: // 输入格式为xx:xx xx:xx 时间范围在每天8:00 至 22:00
如何评价自己的匹配算法?
-
优点
该匹配算法在保证学生意愿的情况下,尽可能的使匹配到学生的部门更多,同时也让学生能选到自己更心仪的部门。从测试数据上看,我随机生成的数据都能够保证每个部门都能选到学生。只有些极端数据的情况下才可能出现部门选不到学生。 -
缺点
部门不一定能够选到标签及时间最符合的学生,因为还需考虑学生意愿
部门与学生时间上的匹配如果要写的很到位的话,需要处理的细节太多,因此我只用了较为简单的匹配机制
关键代码解释
该段代码为主要的匹配过程
/*
按志愿优先,其次匹配时间的方式进行学生部门匹配
*/
void Matching::matchbyFdesireStime()
{
for (int i = 0; i < 5; i++) {
for (int j = 0; j < stusum; j++) {
if (stu[j].getdeslen() < i + 1) continue; //如果学生的志愿数比当前的第i+1志愿小,则判断下个学生
string dno = stu[j].getdesire()[i];
int no = mdno[dno];//通过部门编号获取代码中实际的部门数组下标
//获取学生及部门的时间数据
int *stubtime = stu[j].getbeginTime();
int *stuetime = stu[j].getendTime();
int *depbtime = dep[no].getbeginTime();
int *depetime = dep[no].getendTime();
int stutlen = stu[j].gettlen();
//匹配时间段
for (int ii = 0; ii < stutlen; ii++) {
if (!stu[j].getisworktime(ii)) { //如果该学生的当前时间段未被占用
bool flag = false;
int deptlen = dep[no].gettlen();
for (int jj = 0; jj < deptlen; jj++) {
//判断部门的人数是否已满,以及判断是否时间段符合
if (dep[no].getstulen() < dep[no].getmlimit()
&& stubtime[ii] <= depbtime[jj] && stuetime[ii] >= depetime[jj]) {
stu[j].setisworktime(ii,true); //把学生的当前时间段标记未工作时间
stu[j].setdep(dno); //把部门信息传入学生数据中
dep[no].setstu(stu[j].getsno()); //把学生信息传入部门数据中
flag = true;
break;
}
}
if (flag) break;
}
}
}
}
matchOnlyBydesire(); //按志愿匹配,不管时间
matchOnlyByadjust(); //按调剂原则匹配
}
运行及测试结果展示
- 运行情况正常
具体的测试结果不好描述,大概就是每个部门基本都能收到学生,但是随着输入数据学生数目的增多,选不到部门的学生数量也会增多
下面给出的是先符合学生意愿再匹配时间得出的匹配结果
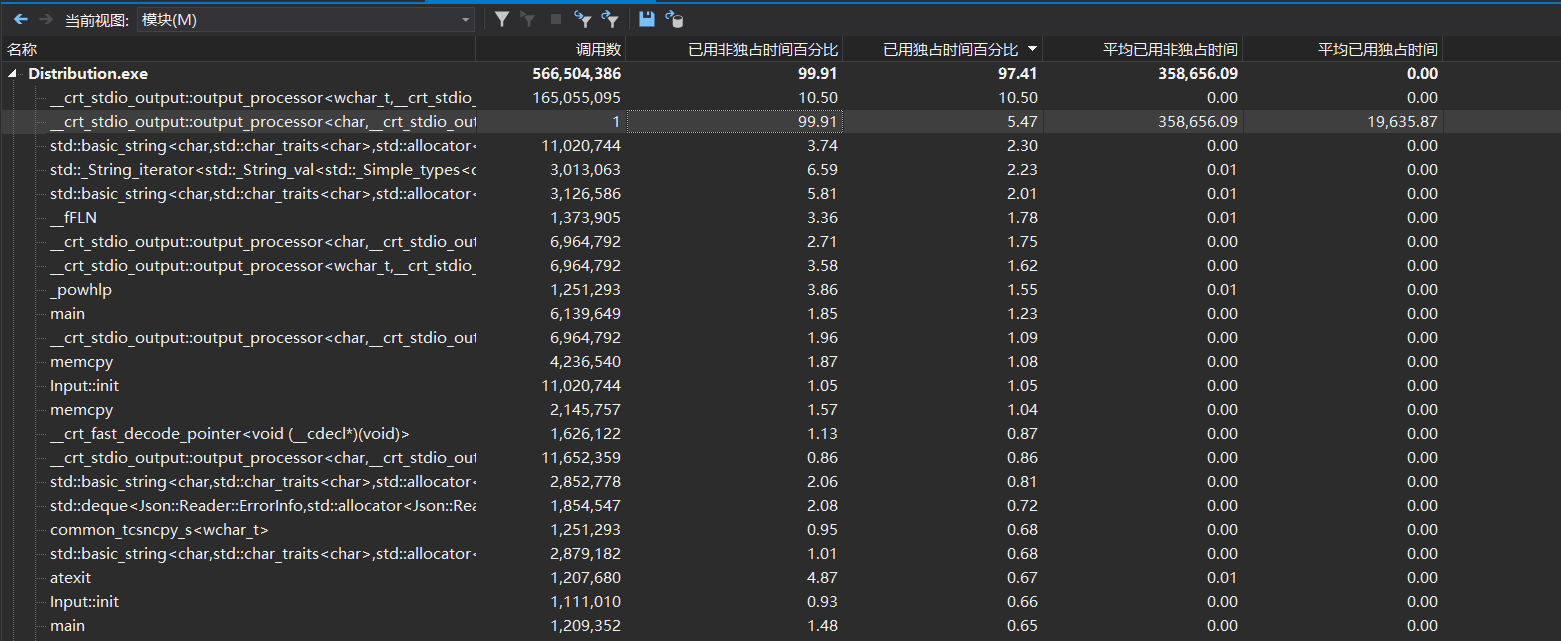
从该图我们可以大致看到每个模块消耗时间的信息。
jsoncpp自带库中的解析json文件花费了大量的时间。因为是外部的代码,所以我暂时没办法优化。
我的输入输出以及匹配所花的时间很少,因此也没有进一步优化。
遇到的困难及解决方法
这次主要的困难都在json上面,在此之前都只是只闻其名,并没有真正去了解。因此花费了大量的时间在生成json输入,以及读取json文件上面。
主要的解决办法就是上网查资料,看别人的博客,别人写的代码,慢慢的自己也摸索出来了。
对队友的评价
-
有哪些好的地方值得学习
对语言的掌握和理解能力很强,能迅速通过代码实现算法。 -
有哪些不好或者需要改进的地方
没找到。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 120 | 60 |
| · Coding | · 具体编码 | 300 | 500 |
| · Code Review | · 代码复审 | 60 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 960 | 1190 |

