MySQL练习-employees数据库(一)
安装一个数据库示例——employees
使用工具为Navicat——(ctrl + q: 打开新查询窗口
ctrl + r: 运行当前窗口内的所有语句)
参考http://www.cnblogs.com/chenyucong/p/5734800.html
该数据库中有6张关联,记录的数据为某一公司9个部门所有员工的薪资(包括离职员工),以下为关系图。
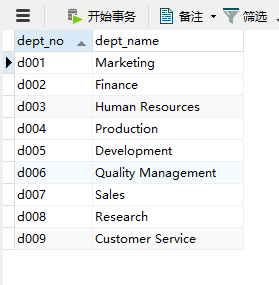
第一张表:departments
记录的是9个部门的部门编号和部门名称
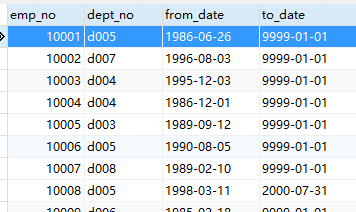
第二张表:dept_emp
部门员工数据,员工id和部门id,其实时间和结束时间(注:9999的意思就是仍在职)
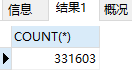
统计一下这张表的数据量,331603条记录
SELECT COUNT(*)
FROM dept_emp
再统计一下员工id(emp_no)的去重数量,300024条记录
SELECT COUNT(DISTINCT emp_no) FROM dept_emp
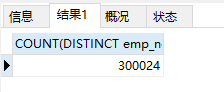
差异3W条,为什么?有重复出现的员工id,我们尝试把重复出现员工id筛选出来
SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>1

好了,现在有了那近3W个有重复值的员工id,但我们仍然不清楚重复的原因,现在需要跟着重复员工id把完整的信息筛选出来
SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>1 )
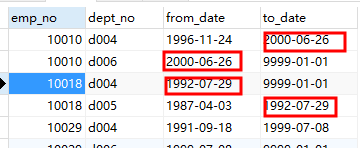
现在结果很明确,他们是调部门了!所以该表记录是数据真实含义是每个员工在每个部门所待的时间跨度。
但同时,也存在一个有趣的现象,就是没有一个员工是调过两次部门的,证明如下
SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>2 )
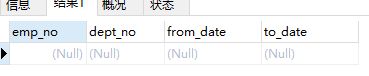
这个现象我们看看能不能在接下的表中又所发现
第三张表:dept_manger
同第二张表结构差不多,每个部门的每个经理的任职时期,总共就24个人,每个部门至少有过两个经理。
SELECT COUNT(DISTINCT emp_no) AS manger_sum from dept_manager GROUP BY dept_no

第四张表:employees
员工信息表,emp_no是唯一键值,

统计结果与表二得出的数据一致。
SELECT COUNT(*) FROM employees;

第五张表:salaries
记录每个员工每段时期的薪资!
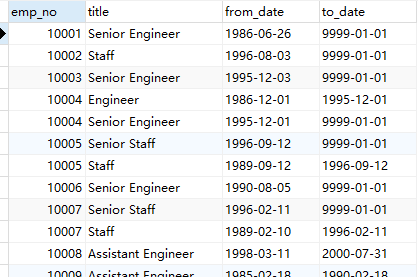
第六张表:title
记录每个员工每段时期的职位名称!但请注意,周期与第五张表是不同的,因为在同一职位上你也是会涨工资的嘛