
ThreadLocal的实现和使用场景
《Java源码分析》:ThreadLocal /ThreadLocalMap
一、什么是ThreadLocal
ThreadLocal并不是用来并发控制访问一个共同对象,而是为了给每个线程分配一个只属于该线程的变量,顾名思义它是local variable(线程局部变量)。
它的功用非常简单,就是为每一个使用该变量的线程都提供一个变量值的副本,
是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突,实现线程间的数据隔离。从线程的角度看,就好像每一个线程都完全拥有该变量。
1、首先每个线程都有一个私有的ThreadLocalMap的引用map 2、当我们第一次调用threadLocal.set()/threadLocal.get()方法的时候会对这个map进行初始化。 3、这个ThreadLocalMap就是用来保存(threadLocal,value)这样的键值对的,
即每个使用threadLocal的线程都是将其作为键而指定的值作为value保存在这个map中,而map是每个线程私有的,因此是独立的,可以随意操作。 4,当我们调用threadLocal.get()方法时,他首先会拿到当前线程的ThreadLocalMap对象map,
由于这个ThreadLocalMap对象map中保存了(threadLocal,value)的键值对,
因此根据map.get(threadLocal)来拿到相应的value值,这样我们就可以随意来操作这个value,不会影响其他线程中的value。
接下来 我们来看下ThreadLocal的内部实现:
set和get方法是ThreadLocal类中最常用的两个方法。
1,set方法实现源码如下:
public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); }
ThreadLocalMap getMap(Thread t) { return t.threadLocals; }
//Thread类里默认threadLocals为null class Thread implements Runnable{ ThreadLocal.ThreadLocalMap threadLocals = null; }
static class ThreadLocalMap { static class Entry extends WeakReference<ThreadLocal<?>> { Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } } }
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
ThreadLocalMap.Entry类继承了WeakReference(弱引用),如果entry.get()==null,意味着key不在引用,因此在table中的键值对就会被去除。 关于ThreadLocalMap我们需要了解的一点是:它是用来保存(threadLocal,value)键值对。
当我们需要使用(threadLocal,value)键值对中的value时,只需要使用entry.get(threadLocal)即可获得
ThreadLocalMap是ThreadLocal的一个内部类,ThreadLocalMap的构造方法如下:
//table是ThreadLoaclMap类的实例变量


/** * 初始容量,必须为2的幂 */ private static final int INITIAL_CAPACITY = 16; /** * Entry表,大小必须为2的幂 */ private Entry[] table; /** * 表里entry的个数 */ private int size = 0; /** * 重新分配表大小的阈值,默认为0 */ private int threshold;
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { table = new Entry[INITIAL_CAPACITY]; int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); //求得此ThreadLocal在数组中保存的位置 table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); }
hash冲突解决:如何实现一个线程多个ThreadLocal对象,每一个ThreadLocal对象是如何区分的呢?
private final int threadLocalHashCode = nextHashCode(); private static AtomicInteger nextHashCode = new AtomicInteger(); private static final int HASH_INCREMENT = 0x61c88647; private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT);//这个方法应该让nextHashCode本身也进行了相加。 }
对于每一个ThreadLocal对象,都有一个final修饰的int型的threadLocalHashCode不可变属性,
对于基本数据类型,可以认为它在初始化后就不可以进行修改,所以可以唯一确定一个ThreadLocal对象。
但是如何保证两个同时实例化的ThreadLocal对象有不同的threadLocalHashCode属性:
在ThreadLocal类中,还包含了一个static修饰的AtomicInteger(提供原子操作的Integer类)成员变量(即类变量)
和一个static final修饰的常量(作为两个相邻nextHashCode的差值)。
由于nextHashCode是类变量,所以每一次调用ThreadLocal类都可以保证nextHashCode被更新到新的值,
并且下一次调用ThreadLocal类这个被更新的值仍然可用,同时AtomicInteger保证了nextHashCode自增的原子性。
ThreadLocalMap类的set方法
/** * Set the value associated with key. * * @param key the thread local object * @param value the value to be set */ private void set(ThreadLocal<?> key, Object value) { // We don't use a fast path as with get() because it is at // least as common to use set() to create new entries as // it is to replace existing ones, in which case, a fast // path would fail more often than not. Entry[] tab = table; int len = tab.length; //首先也是根据key的hash值得到其在数组中的存储位置 int i = key.threadLocalHashCode & (len-1); /* 对于第hashcode对应的槽有存储元素,则说明发生了hash碰撞。 发生hash碰撞的解决方法是:以加一的形式逐渐遍历整个数组,直到找到key或者是找到一个空位。 */ for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get(); if (k == key) { //此key本来存在,则更新其值即可。 e.value = value; return; } if (k == null) { //找到一个空位 replaceStaleEntry(key, value, i); return; } } //对于此key的hashcode对应的槽没有存储元素,则会直接新建一个对象并存储在这个位置上。 tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }
Thread.currentThread得到当前线程,如果当前线程存在threadLocals这个变量不为空,
那么根据当前的ThreadLocal实例作为key寻找在map中位置,然后用新的value值来替换旧值。
在ThreadLocal这个类中比较引人注目的应该是ThreadLocal->ThreadLocalMap->Entry这个类。这个类继承自WeakReference。
2,get方法实现源码如下:
public T get() { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) { ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue(); } private T setInitialValue() { T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); return value; }
/* 函数功能:返回当前线程在这个ThreadLocal中的初始值。该方法initialValue()将在第一次用户调用get方法访问这个变量时被调用, 除非线程之前调用了set方法这样就会导致该方法不被被调用。 一般情况下,这个方法至多被每个线程调用一次。但是,在调用remove方法之后紧跟着调用了get方法则会又一次的调用此方法。 这里的实现简单的返回null;如果程序员期望这个ThreadLocal变量有一个初始值(不是null),则我们需要在子类(内部类)中重写这个方法。 */ protected T initialValue() { return null; }
ThreadLocalMap类中getEntry(threadLocal)方法
private Entry getEntry(ThreadLocal<?> key) { int i = key.threadLocalHashCode & (table.length - 1); //根据ThreadLocal的hashcode求出其在数组中存储的下标 Entry e = table[i]; if (e != null && e.get() == key) //进一步比较确认,e==null或e.get()!=key可能是此键值对已被垃圾回收 return e; else return getEntryAfterMiss(key, i, e); } //在getEntry方法中在key对应的hash槽中没有直接找到与此key关联的键值对,则会调用此方法 private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { Entry[] tab = table; int len = tab.length; while (e != null) { ThreadLocal<?> k = e.get(); if (k == key) return e; if (k == null)//已被垃圾回收 expungeStaleEntry(i); else i = nextIndex(i, len); e = tab[i]; } return null; }
首先我们通过Thread.currentThread得到当前线程,然后获取当前线程的threadLocals变量,
这个变量就是ThreadLocalMap类型的,如果这个变量map不为空,再获取ThreadLocalMap.Entry e,
如果e不为空,则获取value值返回,否则在Map中初始化Entry,并返回初始值null。
如果map为空,则创建并初始化map,并返回初始值null。
注意:Entry继承若引用类,但是Entry类生成的对象并不是被弱引用,而是泛型类ThreadLocal(也就是Entry构造器的key)。
static class ThreadLocalMap { static class Entry extends WeakReference<ThreadLocal<?>> { Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }
3,ThreadLocal.remove()方法介绍
public void remove() { ThreadLocalMap m = getMap(Thread.currentThread()); if (m != null) m.remove(this); //把ThreadLocal对应的键值对在Map中删除 }
在ThreadLocalMap中的remove方法如下
/** * Remove the entry for key. */ private void remove(ThreadLocal<?> key) { Entry[] tab = table; int len = tab.length; int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { if (e.get() == key) { e.clear(); expungeStaleEntry(i); return; } } }
思想为:遍历整个数组链表,如果匹配了key,则就删除。
PS:总结threadlocal
1,每个ThreadLocal对象,只能为当前线程存放一个对象。 每个线程有个map,map有个Entry键值对对象,用来存放数据。
通过同一个ThradLocal对象设置的值,那么所有线程的Entry对象的健都是一样的都是该ThreadLocal对象。 2,每个ThreadLocal只能存一个对象,为什么当前线程还要通过map来存对象? 因为通过多个ThreadLocal对象存值,都是存在当前线程的map中,那么当前线程就会存在多个值. 3,如何使用ThreadLocal 在主线程中创建ThreadLocal对象,并且提供存/取值的方法(最好提供remove方法防止内存泄漏)。业务线程通过该方法调用添加和获取值。
二,ThreadLocal的内存泄露问题
根据上面Entry方法的源码,我们知道ThreadLocalMap是使用ThreadLocal的弱引用作为Key的
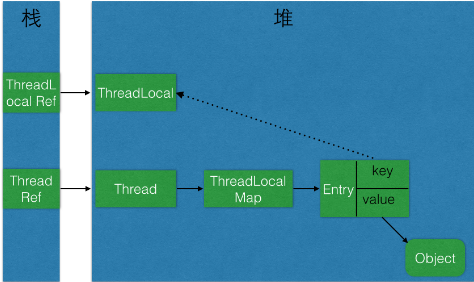
(实线表示强引用,虚线表示弱引用)
ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用引用他,那么系统gc的时候,这个ThreadLocal势必会被回收, 这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value, 如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链: Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value 永远无法回收,造成内存泄露。
ThreadLocalMap设计时的对上面问题的对策:
1,首先从ThreadLocal的直接索引位置(通过ThreadLocal.threadLocalHashCode & (table.length-1)运算得到)获取Entry e,如果e不为null并且key相同则返回e;
2,如果e为null或者key不一致则向下一个位置查询,如果下一个位置的key和当前需要查询的key相等,则返回对应的Entry。
否则,如果key值为null,则擦除该位置的Entry,并继续向下一个位置查询。
在这个过程中遇到的key为null的Entry都会被擦除,那么Entry内的value也就没有强引用链,自然会被回收。
仔细研究代码可以发现,set操作也有类似的思想,将key为null的这些Entry都删除,防止内存泄露。
但是光这样还是不够的,上面的设计思路依赖一个前提条件:
要调用ThreadLocalMap的getEntry函数或者set函数。
这当然是不可能任何情况都成立的,所以很多情况下需要使用者手动调用ThreadLocal的remove函数,手动删除不再需要的ThreadLocal,防止内存泄露。
所以JDK建议将ThreadLocal变量定义成private static的,这样的话ThreadLocal的生命周期就更长,
由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会被回收,
也就能保证任何时候都能根据ThreadLocal的弱引用访问到Entry的value值,然后remove它,防止内存泄露。
在上面提到过,每个thread中都存在一个map, map的类型是ThreadLocal.ThreadLocalMap. Map中的key为一个threadlocal实例. 这个Map的确使用了弱引用,不过弱引用只是针对key. 每个key都弱引用指向threadlocal. 当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用. 只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收。
所以得出一个结论就是只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间不会被回收的,就发生了我们认为的内存泄露。其实这是一个对概念理解的不一致,也没什么好争论的。最要命的是线程对象不被回收的情况,这就发生了真正意义上的内存泄露。比如使用线程池的时候,线程结束是不会销毁的,会再次使用的。就可能出现内存泄露。
三、ThreadLocal应用场景
1、数据库连接池实现
jdbc连接数据库,如下所示:
Class.forName("com.mysql.jdbc.Driver"); java.sql.Connection conn = DriverManager.getConnection(jdbcUrl);
注意:
一次Drivermanager.getConnection(jdbcurl)获得只是一个connection,并不能满足高并发情况。
因为connection不是线程安全的,一个connection对应的是一个事物。
每次获得connection都需要浪费cpu资源和内存资源,是很浪费资源的。所以诞生了数据库连接池。
数据库连接池实现原理如下:
pool.getConnection(),都是先从threadlocal里面拿的,如果threadlocal里面有,则用,保证线程里的多个dao操作,用的是同一个connection,以保证事务。
如果新线程,则将新的connection放在threadlocal里,再get给到线程。
将connection放进threadlocal里的,以保证每个线程从连接池中获得的都是线程自己的connection。
Hibernate的数据库连接池源码实现:
public class ConnectionPool implements IConnectionPool { // 连接池配置属性 private DBbean dbBean; private boolean isActive = false; // 连接池活动状态 private int contActive = 0;// 记录创建的总的连接数 // 空闲连接 private List<Connection> freeConnection = new Vector<Connection>(); // 活动连接 private List<Connection> activeConnection = new Vector<Connection>(); // 将线程和连接绑定,保证事务能统一执行 private static ThreadLocal<Connection> threadLocal = new ThreadLocal<Connection>(); public ConnectionPool(DBbean dbBean) { super(); this.dbBean = dbBean; init(); cheackPool(); } // 初始化 public void init() { try { Class.forName(dbBean.getDriverName()); for (int i = 0; i < dbBean.getInitConnections(); i++) { Connection conn; conn = newConnection(); // 初始化最小连接数 if (conn != null) { freeConnection.add(conn); contActive++; } } isActive = true; } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } // 获得当前连接 public Connection getCurrentConnecton(){ // 默认线程里面取 Connection conn = threadLocal.get(); if(!isValid(conn)){ conn = getConnection(); } return conn; } // 获得连接 public synchronized Connection getConnection() { Connection conn = null; try { // 判断是否超过最大连接数限制 if(contActive < this.dbBean.getMaxActiveConnections()){ if (freeConnection.size() > 0) { conn = freeConnection.get(0); if (conn != null) { threadLocal.set(conn); } freeConnection.remove(0); } else { conn = newConnection(); } }else{ // 继续获得连接,直到从新获得连接 wait(this.dbBean.getConnTimeOut()); conn = getConnection(); } if (isValid(conn)) { activeConnection.add(conn); contActive ++; } } catch (SQLException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } return conn; } // 获得新连接 private synchronized Connection newConnection() throws ClassNotFoundException, SQLException { Connection conn = null; if (dbBean != null) { Class.forName(dbBean.getDriverName()); conn = DriverManager.getConnection(dbBean.getUrl(), dbBean.getUserName(), dbBean.getPassword()); } return conn; } // 释放连接 public synchronized void releaseConn(Connection conn) throws SQLException { if (isValid(conn)&& !(freeConnection.size() > dbBean.getMaxConnections())) { freeConnection.add(conn); activeConnection.remove(conn); contActive --; threadLocal.remove(); // 唤醒所有正待等待的线程,去抢连接 notifyAll(); } } // 判断连接是否可用 private boolean isValid(Connection conn) { try { if (conn == null || conn.isClosed()) { return false; } } catch (SQLException e) { e.printStackTrace(); } return true; } // 销毁连接池 public synchronized void destroy() { for (Connection conn : freeConnection) { try { if (isValid(conn)) { conn.close(); } } catch (SQLException e) { e.printStackTrace(); } } for (Connection conn : activeConnection) { try { if (isValid(conn)) { conn.close(); } } catch (SQLException e) { e.printStackTrace(); } } isActive = false; contActive = 0; } // 连接池状态 @Override public boolean isActive() { return isActive; } // 定时检查连接池情况 @Override public void cheackPool() { if(dbBean.isCheakPool()){ new Timer().schedule(new TimerTask() { @Override public void run() { // 1.对线程里面的连接状态 // 2.连接池最小 最大连接数 // 3.其他状态进行检查,因为这里还需要写几个线程管理的类,暂时就不添加了 System.out.println("空线池连接数:"+freeConnection.size()); System.out.println("活动连接数::"+activeConnection.size()); System.out.println("总的连接数:"+contActive); } },dbBean.getLazyCheck(),dbBean.getPeriodCheck()); } } }
2、有时候ThreadLocal也可以用来避免一些参数传递,通过ThreadLocal来访问对象。
比如一个方法调用另一个方法时传入了8个参数,通过逐层调用到第N个方法,传入了其中一个参数,
此时最后一个方法需要增加一个参数,第一个方法变成9个参数是自然的,但是这个时候,相关的方法都会受到牵连,使得代码变得臃肿不堪。
这时候就可以将要添加的参数设置成线程本地变量,来避免参数传递。
上面提到的是ThreadLocal一种亡羊补牢的用途,不过也不是特别推荐使用的方式,
它还有一些类似的方式用来使用,就是在框架级别有很多动态调用,调用过程中需要满足一些协议,
虽然协议我们会尽量的通用,而很多扩展的参数在定义协议时是不容易考虑完全的以及版本也是随时在升级的,
但是在框架扩展时也需要满足接口的通用性和向下兼容,而一些扩展的内容我们就需要ThreadLocal来做方便简单的支持。
简单来说,ThreadLocal是将一些复杂的系统扩展变成了简单定义,使得相关参数牵连的部分变得非常容易。
3、在某些情况下提升性能和安全。
(PS:共享对象的方法换成局部的)
用SimpleDateFormat这个对象,进行日期格式化。
因为创建这个对象本身很费时的,而且我们也知道SimpleDateFormat本身不是线程安全的,也不能缓存一个共享的SimpleDateFormat实例,
为此我们想到使用ThreadLocal来给每个线程缓存一个SimpleDateFormat实例,提高性能。
同时因为每个Servlet会用到不同pattern的时间格式化类,所以我们对应每一种pattern生成了一个ThreadLocal实例。
public interface DateTimeFormat { String DATE_PATTERN = "yyyy-MM-dd"; ThreadLocal<DateFormat> DATE_FORMAT = ThreadLocal.withInitial(() -> { return new SimpleDateFormat("yyyy-MM-dd"); }); String TIME_PATTERN = "HH:mm:ss"; ThreadLocal<DateFormat> TIME_FORMAT = ThreadLocal.withInitial(() -> { return new SimpleDateFormat("HH:mm:ss"); }); String DATETIME_PATTERN = "yyyy-MM-dd HH:mm:ss"; ThreadLocal<DateFormat> DATE_TIME_FORMAT = ThreadLocal.withInitial(() -> { return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); }); }
为什么SimpleDateFormat不安全,可以参考此篇博文:
假如我们把SimpleDateFormat定义成static成员变量,那么多个thread之间会共享这个sdf对象, 所以Calendar对象也会共享。
假定线程A和线程B都进入了parse(text, pos) 方法, 线程B执行到calendar.clear()后,线程A执行到calendar.getTime(), 那么就会有问题。
如果不用static修饰,将SimpleDateFormat定义成局部变量:
每调用一次方法就会创建一个SimpleDateFormat对象,方法结束又要作为垃圾回收。
加锁性能较差,每次都要等待锁释放后其他线程才能进入。
那么最好的办法就是:使用ThreadLocal: 每个线程都将拥有自己的SimpleDateFormat对象副本。
附-SimpleDateFormat关键源码:
public class SimpleDateFormat extends DateFormat { public Date parse(String text, ParsePosition pos){ calendar.clear(); // Clears all the time fields // other logic ... Date parsedDate = calendar.getTime(); } } abstract class DateFormat{ // other logic ... protected Calendar calendar; public Date parse(String source) throws ParseException{ ParsePosition pos = new ParsePosition(0); Date result = parse(source, pos); if (pos.index == 0) throw new ParseException("Unparseable date: \"" + source + "\"" , pos.errorIndex); return result; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号