
C#获取HTML文件指定DIV内容
最近自己找了一个开源的博客网站,放到阿里云上,方便自己发布博客。
我一般把文章发布到博客园和QQ空间,家了这个网站后又要多发布一次,为了省事就做了一个从博客园读取文章的功能;
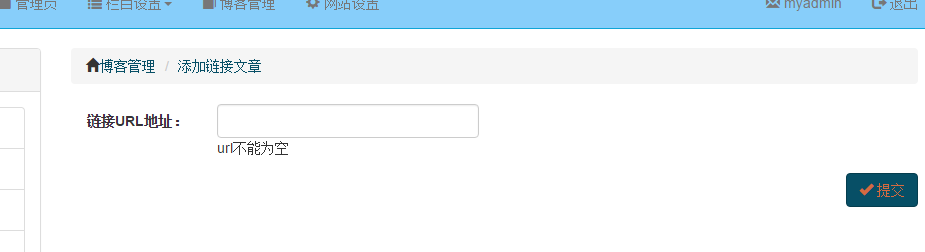
输入链接URL地址点击提交;
从GetHub安装HtmlAgilityPack
后台C#代码
public ActionResult LinkBlog(string urlStr) { Response response = new Response() { Code =1 }; if (string.IsNullOrWhiteSpace(urlStr)) { response.Code = 0; response.Message = "链接URL必填"; return Json(response); } WebClient c = new WebClient(); c.Encoding = Encoding.GetEncoding("UTF-8"); string html = c.DownloadString(urlStr); HtmlDocument doc = new HtmlDocument(); doc.LoadHtml(html); HtmlNode nodeinfo = doc.GetElementbyId("post_detail"); //post_detail // HtmlNode nodetitle = doc.GetElementbyId("cb_post_title_url"); //cnblogs_post_body HtmlNode nodecontent = doc.GetElementbyId("cnblogs_post_body"); string htmlstr = nodeinfo.OuterHtml; Blog blog = new Blog(); blog.Publish = true; blog.Title =string.Format("链接文章:{0}", nodetitle.InnerText); blog.Volume = 0; blog.Content = htmlstr; blog.CreateTime = DateTime.Now; string htmlsumm = nodecontent.InnerText.Replace(" ", ""); int sublen = htmlsumm.Length; if (sublen > 80) { sublen = 80; } blog.Summary = htmlsumm.Substring(0, sublen); blog.Category= categoryManager.FindRoot()[0]; response = blogManager.AddBlog(blog); return Json(response); }
应用的技术
WebClient c = new WebClient();
c.Encoding = Encoding.GetEncoding("UTF-8");
string html = c.DownloadString(urlStr);
通过WebClient读取网页,注意这里的编码问题,有的网页用的是UTF-8有的是GB2312
自己尝试一下就知道了,编码设置错误会出现汉子乱码。
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(html);
HtmlNode nodeinfo = doc.GetElementbyId("post_detail");
读取HTML字符串中指定id的标签的内容;
参考博客:http://www.cnblogs.com/ITmuse/archive/2010/05/29/1747199.html
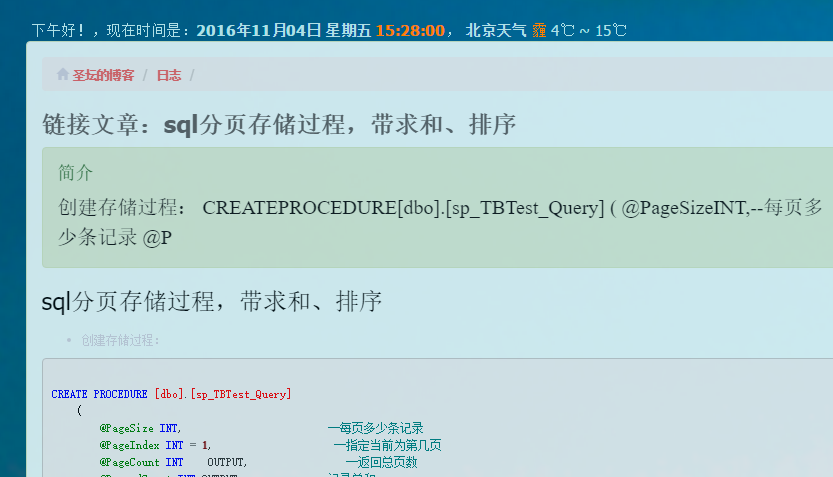
最终我不用再重复添加博客了,不过还多亏博客园没有做图片防盗链,否则图片还要单独处理。

