
stm32之内部功能
本文将提到以下内容:
- 位带操作
- 中断
- printf重定向
- 随机数发生器RNG
- AD/DA
- DMA
- 高性能计算能力
- 加密
- ART加速
一、位带操作
在学习51单片机的时候就使用过位操作,通过关键字sbit对单片机IO口进行位定义。但是stm32没有这样的关键字,
而是通过访问位带别名区来实现,即将每个比特位膨胀成一个32位字,通过位带别名区指针指向位带区内容。
支持位带操作的两个内存区的范围是:
0x2000_0000‐0x200F_FFFF(SRAM 区中的最低 1MB)
0x4000_0000‐0x400F_FFFF(片上外设区中的最低 1MB)
位带别名区地址=(A&0xF0000000)+0x2000000+(A&0xFFFFF)<<5+(n≤2)
其中A为位带区地址,n为该字节的第几位。
这里再不嫌啰嗦地举一个例子:
1. 在地址 0x20000000 处写入 0x3355AACC
2. 读取地址0x22000008。本次读访问将读取 0x20000000,并提取比特 2,值为 1。
3. 往地址 0x22000008 处写 0。本次操作将被映射成对地址 0x20000000 的“读-改-写”操作(原子的),把比特2 清 0。
4. 现在再读取 0x20000000,将返回 0x3355AAC8(bit[2]已清零)。
注:如果用到位带操作,可以把各个引脚进行位带宏定义,封装在一个头文件里,方便使用引脚。
二、中断
中断其实就是当CPU执行程序时,由于发生了某种随机的事件(外部或内部),引起CPU暂时中断正在运行的程序,转
去执行一段特殊的服务程序(中段子程序)。下面是中断的示意图。
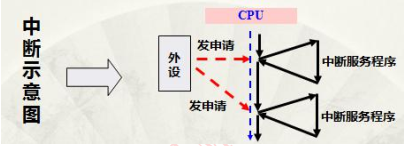
部分中断可屏蔽,部分中断不可屏蔽,每个中断通道都具备自己的中断优先级控制字,分别控制抢占优先级和响应优先
级。只有当抢占优先级相同时,响应优先级高低决定哪个中断被处理(响应式优先级的高低没法中断正在执行的中断程序)。
stm32中的NVIC(嵌套向量中断控制器)属于内核的一个外设,控制着芯片的中断相关功能。
注:中断和事件的区别:
可以这样简单的认为,事件机制提供了一个完全有硬件自动完成的触发到产生结果的通道,不要软件的参与,降低了CPU
的负荷,节省了中断资源,提高了响应速度(硬件总快于软件),是利用硬件来提升CPU芯片处理事件能力的一个有效方法。
三、printf重定向
我们知道C语言中printf函数默认输出设备是显示器,如果要实现在串口或者LCD上显示,必须重定义标准库函数里调用与输
出设备相关的函数。一般是在fputc函数里把输出对象改为指向串口或者LCD,这一过程叫做重定向。
四、随机数发生器RNG
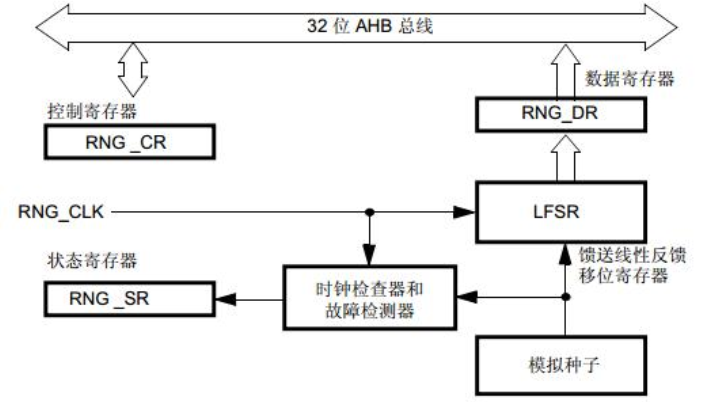
STM32F4芯片内部含有一个硬件随机数发生器(RNG),RNG处理器是一个以连续模拟噪声为基础的随机数发生器,提供了
一个32位的随机数。使能后,需要检查标志位,判断其是否稳定,稳定后才能使用。RNG结构图如下图所示:
五、AD/DA
STM32的ADC模块,请允许我用如此通俗的语言:普通话 来介绍STM32ADC模块的特色
1、1MHz转换速率、12位转换结果(12位、记住这个12位哈、因为2^12=4096 ,也请记住4096哈)
STM32F103系列:在56MHz时转换时间为:1μs
在72MHz时转换时间为:1.17μs
2、转换范围:0~3.3V (3.3v---->当你需要将采集的数据用电压来显示的话:设你采集的数据为:x[0~4095],此时的计
算公式就为:(x / 4096) * 3.3))
3、ADC供电要求:2.4V~3.6 V(可千万别接到 5V 的石榴裙子底下呀)
4、ADC输入范围:VREF-≤ VIN ≤VREF+ (VREF+和VREF-只有LQFP100封装才有)
5、双重模式(带2个ADC的设备): 8种转换模式
6、最多有18个通道:16个外部通道,2个内部通道:连接到温度传感器和内部参考电压(VREFINT = 1.2V)。通道可以分为
规则通道和注入通道,其中规则通道组最多有16路,是一种规规矩矩的通道,具有DMA功能,而注入通道组最多有4路,转换
过程中可以中断,还可以在规则通道转换过程中插队。
其转换步骤如下:
- 使能端口时钟和ADC时钟
- 设置ADC通道控制器CCR(ADC模式(独立、双重、三重)、输入时钟分频等)
- 初始化ADC(分辨率、转换模式(单次、连续)、数据对齐方式等)
- 开启ADC
- 读取ADC转换值
测交流电信号要把交流电分压到5V 以内,再把负半周提升到零点以上,用运放做一个加法器(有专用交流电检测用的高精
度运放,好像是MCP的),把零点抬高到2.5V,这样最低点也大于零,最高点不超过5V ,再用单片机在交流电一周期内采40个
点,存入内存,计算出各离散值的均方根就是交流电的有效值。
或者把交流信号经(电压跟随器 + 全波整流 ),将负半周期信号反转到正半轴,得到半波交流信号,再用ADC进行测量。
我们来看看STM32之DAC的Resume(简历简介):

● 2个DAC转换器:每个转换器对应1个输出通道
● 8位或者12位单调输出
● 12位模式下数据左对齐或者右对齐
● 同步更新功能
● 噪声波形生成
● 三角波形生成
● 双DAC通道同时或者分别转换
● 每个通道都有DMA功能
● 外部触发转换
● 输入参考电压VREF+
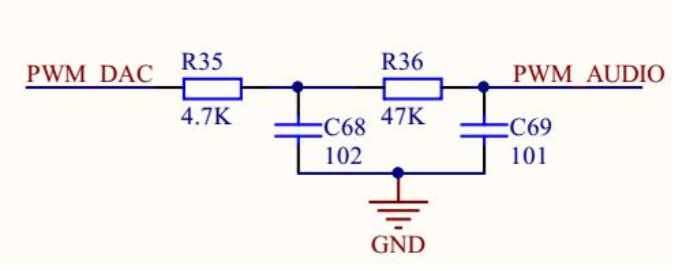
注:PWM+RC滤波可以模拟DAC的输出方式。
在对DAC的输出频率要求不是太高的情况下,我们一般可以采用PWM+二阶RC滤波来模拟DAC,进行输出。PWM的占
空比来模拟幅值,二阶RC低通滤波电路用来截止谐波(一般只考虑基波即可),通过直流,具体详情如下:
在8位分辨条件下,我们一般要求1次谐波对输出电压的影响不要超过1个位的精度,也就是3.3/256=0.01289V。假设VH
为3.3V,VL为0V,那么一次谐波的最大值是2*3.3/π=2.1V,这就要求我们的RC滤波电路提供至少-20lg(2.1/0.01289)=-44dB
的衰减。STM32的定时器最快的计数频率是168Mhz,部分定时器只有84MHz,以84M为例,8为分辨率的时候,PWM频率
为84M/256=328.125Khz。如果是1阶RC滤波,则要求截止频率为2.07Khz,如果为2阶RC滤波,则要求截止频率为26.14Khz。
1、PWM频率为328.125Khz,那么一次谐波频率就是328.125Khz;
2、1阶RC滤波,幅频特性为:-10lg[1+(f/fp)^2];fp为截止频率。
所以对一阶滤波来说,要达到-44dB的衰减,必须-10lg[1+(f/fp)^2]=-44; 得到f/fp=158.486,即fp=328.125/158.486=2.07Khz。
3、2阶RC滤波,幅频特性为:-20lg[1+(f/fp)^2];fp为截止频率。
所以对二阶滤波来说,要达到-44dB的衰减,必须-20lg[1+(f/fp)^2]=-44; 得到f/fp=12.549,即fp=328.125/12.549=26.14Khz。
得到截止频率以后,我们可以紧接着求出R、C的值。如下图所示,R35*C68=R36*C69,fp=1/2πRC。
六、DMA
DMA,全称为:Direct Memory Access,即直接存储器访问。DMA传输方式无需CPU 直接控制传输,也没有中断处理方
式那样保留现场和恢复现场的过程,通过硬件为RAM 与I/O设备开辟一条直接传送数据的通路,能使CPU 的效率大为提高。
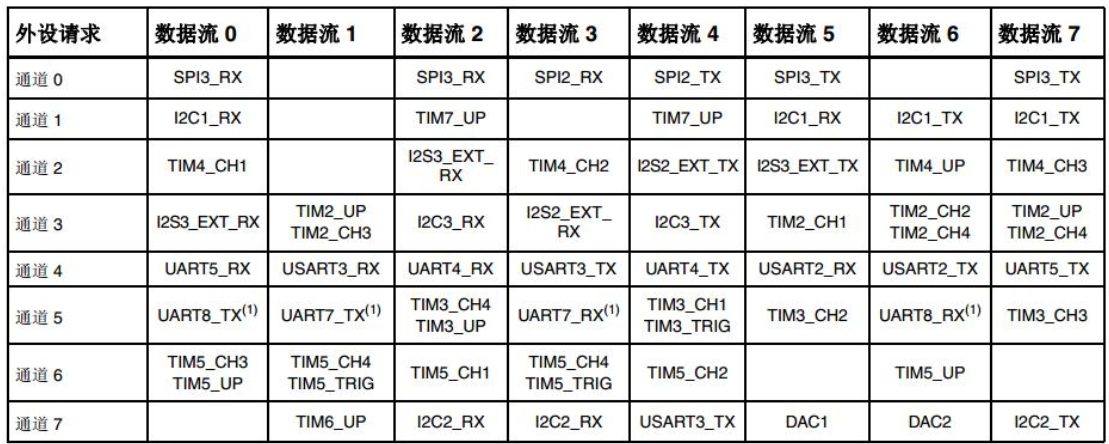
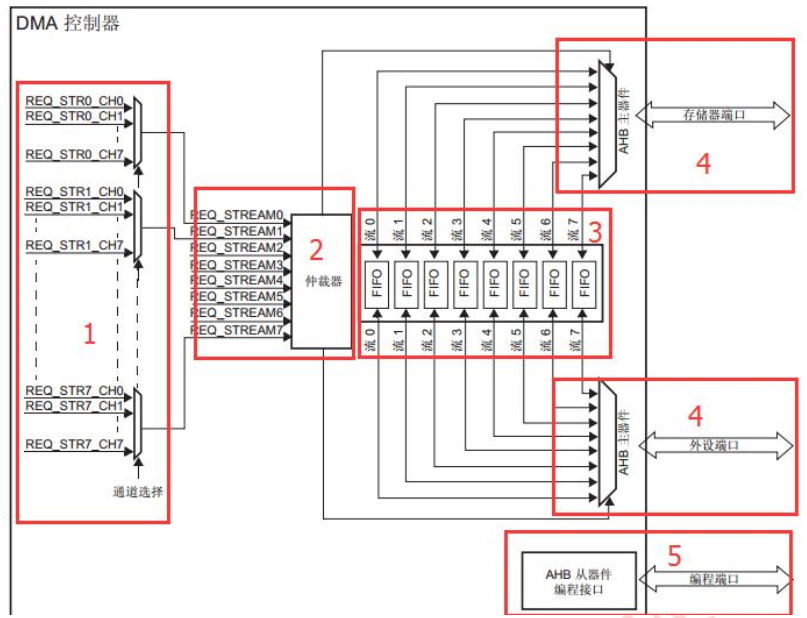
STM32F4中 有两个DMA,每个DMA控制器对应8个数据流,每个数据流又对应8个通道,其映射图如下图所示。DMA挂载
的时钟为AHB总线,其时钟为72Mhz,所以可以实现高速数据搬运。
DMA的结构框图如下图所示,可以看出DMA各数据流需要仲裁优先级,且拥有FIFO先进先出缓存区(解决目标地址和原地
址数据宽度不一致的情况)。
七、高性能计算能力
如下图所示,stm32F4自带DSP处理器,我们可以采用DSP库函数进行浮点运算等计算问题。

我们平常所使用的CPU为定点CPU,意思是进行整点数值运算的CPU。当遇到形如1.1+1.1的浮点数运算时,定点CPU就遇到大
难题了。对于32位单片机,利用Q化处理能发挥他本身的性能,但是精度和速度仍然不会提高很多。
现在设计出了一个新的CPU,叫做FPU,这个芯片专门处理浮点数的运算,这样处理器就将整点数和浮点数分开来处理,整点数
交由定点CPU处理而浮点数交由FPU处理。我们见到过TI的DSP,还有STM32F4系列的带有DSP功能的微控制器。前者笔者没有用
过,不作评论,而后者如果需要用到FPU的浮点运算功能,必须要进行一些必要的设置。
八、加密
采用加密处理器CRYP,下面是CRYP的结构框图。
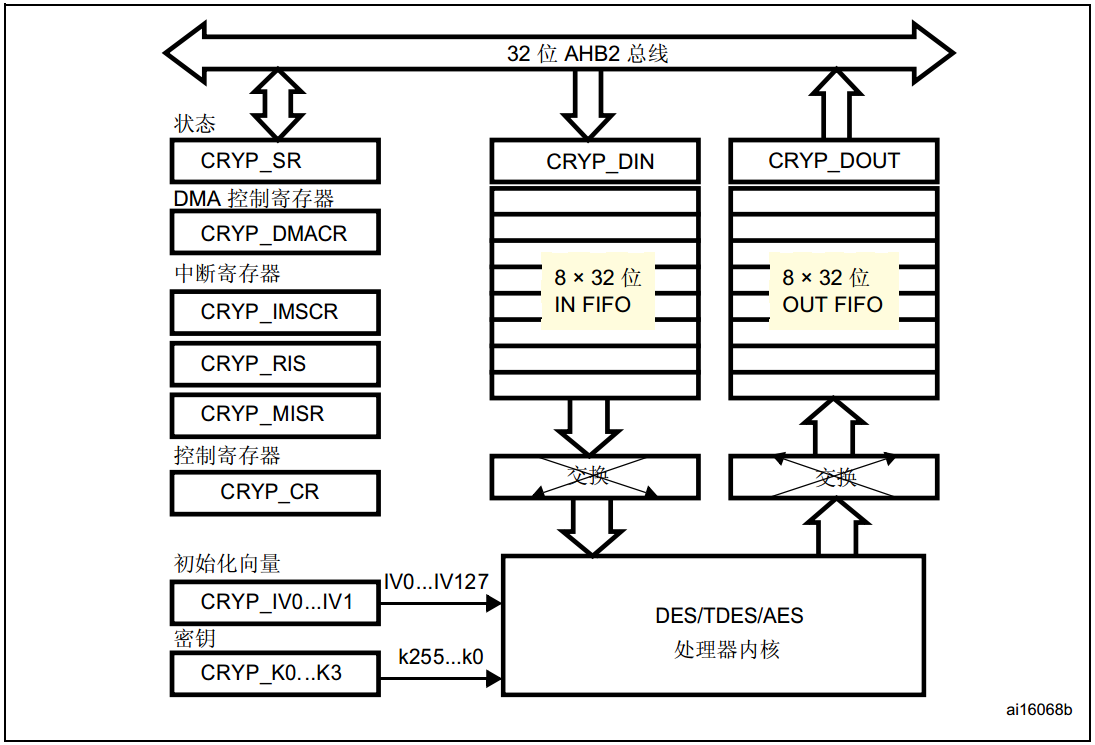
加密算法有AES加解密算法、DES/TDES加解密算法等
九、ART加速
由于生产工艺的限制,当CPU主频显著提高时,Flash的存取速度却只能处于一个较低的水平。
STM32F4有存储器加速器(ART),可以使 CPU 频率高达 168 MHz 时在闪存中以 0 个等待周期执行程序。其秘密在于,
STM32内部的Flash我记得是128bit的。这样每次读取时ART会把后面3条指令放到队列里。而Flash等待为5WS的话,每执行4条
指令则必须停一次,再继续执行后4条指令。反正是性能跟同频的X86差不多顶个70%的样子(指Dothan处理器,纯逻辑运算)。
超频我最高测过250MHz,还算比较稳定,结果没出错。再高结果就不对了。

