


机器学习之模型选择与改进
前言
以下内容是个人学习之后的感悟,转载请注明出处~
经过前几篇博客的学习,我们了解到了线性回归、逻辑回归、神经网络等的一些知识。然而,到底该怎么开发一个
机器学习系统或者选择并改进一个学习系统呢?这应该是很多初学者的困惑之处。那么本文会带领你更一步了解如何更
好地使用机器学习。
由于内容较多,做以下目录,方便浏览:
评价假设函数
在设计一个好的机器学习系统之前,我们首先要学会评价一个机器学习系统的好坏,即评价假设函数的好坏。
那么我们应该如何来评价呢?首先,我们先选择一个原始样本数据,70%作为训练集,30%作为测试集。用70%的
训练集求出权重参数θ,再用30%的测试集对求出的学习模型进行测试,如下图所示。

然后使用误分类率(0/1错分率)法,对学习模型进行误差评估,公式如下:


模型选择
不管是用线性回归、逻辑回归算法,还是用神经网络等算法,模型的选择对于达到的效果是至关重要的。相同的算
法,不同的模型,结果也可能是千差万别的。所以,接下来要介绍的便是如何选择模型。
以多项式回归算法为例,对于一个样本集,我们可以列很多阶的假设函数,然后在其中寻找最合适的。在这里,把样
本集分为3个子集,分别是60%训练集、20%验证集、20%测试集。下面只列出了1到10阶的单特征多项式,分别用训练
集对它们进行训练,然后用验证集计算代价函数,取其最小值得多项式作为模型。

模型优化
选好模型并不意味着能够顺利地得出我们想要的结果,因为特征数量、样本数量、正则化参数等等都会对模型最终得
到的结果产生影响。那么影响到底有多大?影响是从那些特征可以看出?用什么方法可以改善模型?这些都是接下来要说
明的内容,请继续往下看。
首先,我们要找出能够表明模型好坏的一些特征,这样有利于我们分析从哪里下手去改进、优化模型。很多人都知道
欠拟合和过拟合,它们分别代表着“高偏差”、“高方差”。如下图所示:
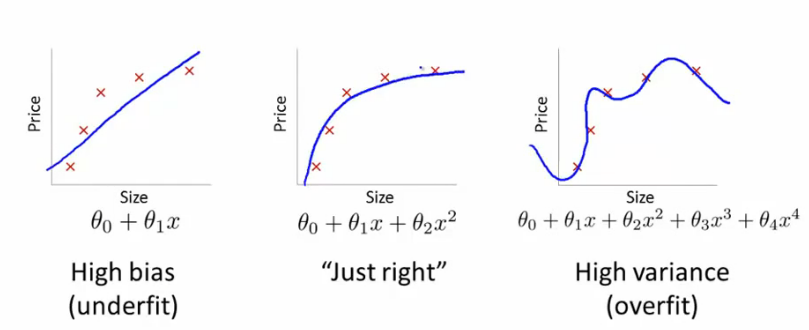
那么我们可以通过什么方法来判断高偏差和高方差呢?方法如下图所示,利用上文选择模型时计算的训练代价函数值
和验证代价函数值画出关于多项式阶数d的曲线图(是不是觉得,前面的计算没白费,接着利用很省力~)。从图中我们可
以很容易判断高偏差和高方差之处。

那么,哪些因素对模型的高偏差、高方差有些影响呢?其实有样本数、特征数、正则化参数等因素。
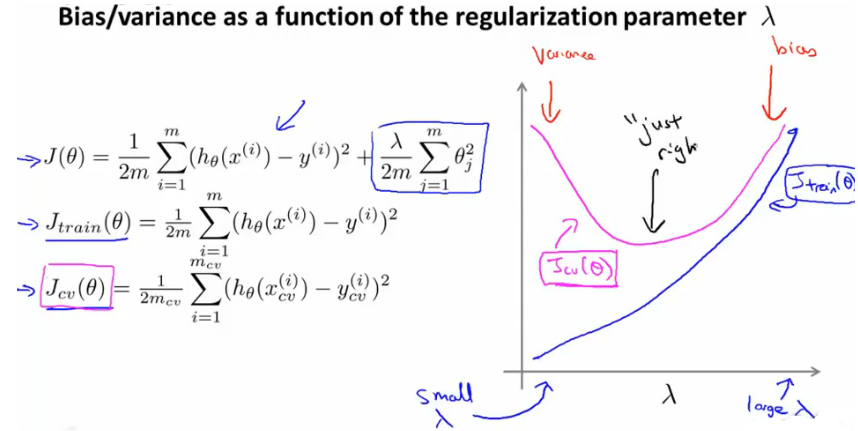
接下来我们看一下正则化参数λ是怎么影响高方差、高偏差的,如下图所示:

那么如何选择正则化参数呢?看下面左图,计算选择不同λ时的验证代价函数值Jcv(θ),取其最小值时的λ即可。下面的
右图则是Jcv(θ)和Jtrain(θ)随正则化参数λ的变化曲线,看起来十分直观。

接下来再来看看训练样本数量对高偏差、高方差的影响,看下图:
| 高偏差 | 
|
| 正常 | 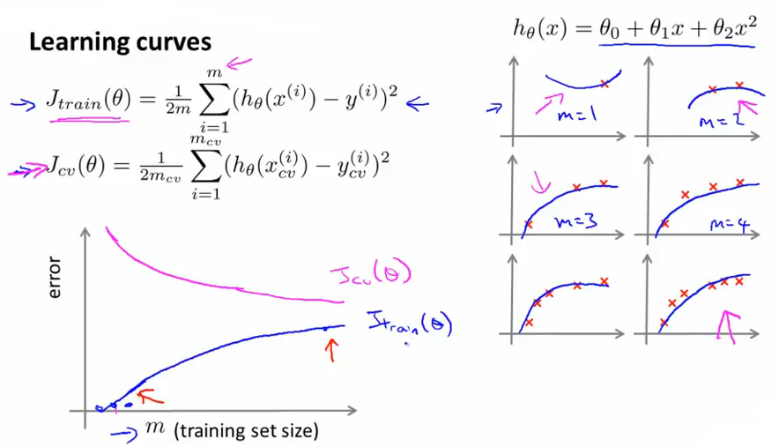
|
| 高方差 | 
|
很多人会觉得我之前提到了3个主要的影响因素,已经讲了正则化参数λ、训练样本数m对高偏差、高方差的影响,是不
是应该讲特征数了呀。童鞋们很聪明,推测的很准,不过有没有人注意到,上文在选择模型时,计算过关于特征值阶数的验证
代价函数值Jcv(θ),然后选择较小值的阶数作为模型,其实这就是对特征值影响的分析(也许有人会提到特征数,其实道理都是
一样的,就不展开),当验证代价函数值最小的时候,完美地避过了高偏差和高方差区。
说了这么多,在这里总结一下模型优化的方法:

说了这么多,都没提到神经网络的模型选取和模型优化,其实吧,神经网络和多项式回归以及其他一些算法一样,其选择模
型和优化模型的方法一般采取的也是交叉验证法,即通过交叉验证集误差Jcv(θ)来实现。神经网络一般特征数、隐含层的层数是需
要重点关注的方面,因为这些处理不当,往往会造成过拟合。
不平衡数据学习模型的评估
在生活中,存在这样一个样本数据集,它有一个类别占的比重特别大,其他类占的比重特别小。比如有一个病人集,里面得了
癌症的人占0.5%,不得癌症的人占99.5%,假设得癌症输出1,不得癌症输出0。然后有人开发了一个算法,不管是输入什么病人,
一律输出0,那么正确率可以达到99.5%,然后得出评估,这个算法很成功。呵呵~,很多人都会觉得这个评估很荒谬,显然这种评
估方法不适合这种不平衡数据学习模型。
为了解决这个问题,我们先建立一个表格,如下图所示,上边的1、0代表真实的值,左边的1、0代表算法预测的值。这是什么
意思呢?以第一格为例,它代表真实上得了癌症以及算法预测上也得了癌症的人数,其它的以此类推。接下来我们把真实及预测都得
了癌症的人数除以预测得了癌症的总人数,即查准率;把真实及预测都得了癌症的人数除以真实得了癌症的总人数,即召回率。

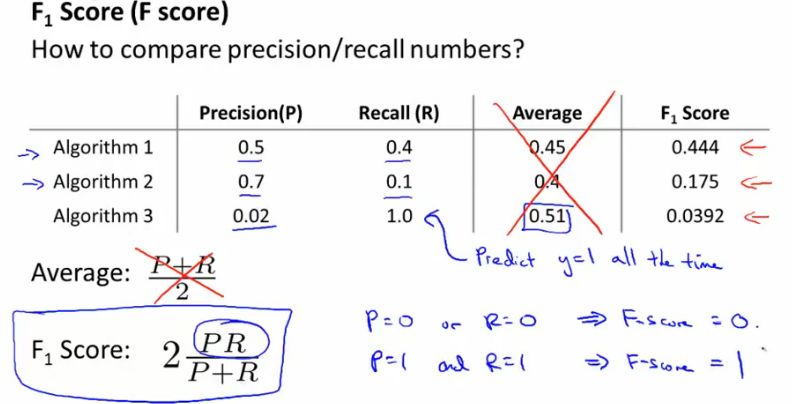
看到这里,很多人都已经想到本文是准备用查准率和召回率来评估算法的好坏,没错,如果查准率和召回率都很高,算法肯定
很好。然而,查准率和召回率并不能同时很大,一个很大,另一个必然很小。所以我们需要寻找一种合适的方法去综合评估算法。
我们采用的是F值方法,能够很好的评估这类不平衡数据学习算法模型,如下图所示。
以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~

