python---基础知识回顾(十)进程和线程(进程)
前戏:进程和线程的概念
若是学过linux下的进程,线程,信号...会有更加深刻的了解。所以推荐去学习下,包括网络编程都可以去了解,尤其是对select,poll,epoll都会有更多的认识。
进程就是资源管理的最小单位,而线程是程序执行的最小单位。一个程序可以有多个进程,一个进程可以有多个同时执行的线程
1.进程:
操作系统隔离各个进程可以访问的地址空间。如果进程间需要传递信息。那么可以使用进程间通信或者其他方式,像信号,像文件,数据库,剪切板....等。在进程的调度中,进程进行切换所需要的事件是比较多的。为了更好的支持信息共享和减少切换开销。从而从进程中演变出来了线程。
2.线程:
线程是进程的执行单元。对于大多数程序来说可能只有一个主线程,就是该程序进程。在系统中看起来所有的线程都是同时执行的,实际上是去共同抢占资源,当一个线程使用完后,下一个马上使用,减少了时间的空隙。和进程抢占时间片大致相同。但是依旧提高了很多的效率。
实例:下载文件时,可以将文件分成多个部分,然后使用多个线程同时去下载,从而加快下载速度。
3.进程线程的对比:
明确进程和线程的区别十分重要。
一般地,进程是重量级的。在进程中需要处理的问题包括进程间通信,临界区管理,和进程调度等。这些特性使得新生成一个进程的开销比较大。
线程是轻量级的。线程之间共享许多资源,容易进行通信,生成一个线程的开销比较小。但是在使用线程会遇到锁问题,死锁和自锁,还有数据同步,实现复杂等问题。需要谨慎使用。
GIL(全局解释器锁)和队列的使用减少了线程实现的复杂性,但是由于GIL的存在,所以python解释器不是线程安全的。因为使用当前线程必须持有这个全局解释器锁,从而可以安全的访问python数据。
例:需要计算操作时,要用到CPU进行处理数据,当我们调用多线程时,由于GIL的存在,一次只允许一个线程被CPU调度(哪怕我们有多核CPU)<为了保证数据同步>,所以由于GIL限制,无论我们开了多少线程,只能使用一个CPU,而CPU是专门用于计算的,所以对于计算型,使用多线程的效果反而下降了。所以计算密集型使用多进程,IO密集型使用多线程
(1)与进程和线程相关的模块 os/sys 包含基本进程管理函数 subprocess 多进程相关模块 signal 信号相关模块 threading 线程相关模块
(2)os/sys模块中与进程相关的函数 popen 生成新的进程 system 直接生成字符串所代表的进程 abort/exit 终止进程 exec足 在现有进程环境下生成新进程
进程编程
创建进程:
一:简单使用:
1.system函数
可以使用os模块中system函数创建进程,是最快捷方式,可以去执行命令或者调用其他程序



>>> import os >>> os.system("dir") 2018/04/21 周六 下午 07:09 <DIR> . 2018/04/21 周六 下午 07:09 <DIR> .. 2017/11/18 周六 下午 10:08 <DIR> .android 0 #执行命令dir,返回0,代表执行成功。否则失败 >>> os.system("calc") 0 #调用其他程序,计算器。 上面调用system产生的子进程的父进程都是该程序,只有子进程执行完毕,父进程才会获取控制器
实际上是调用了系统内置的命令行程序来执行系统命令,所以在命令借宿之后才会将控制权返回给Python进程。
2.exec族函数
使用exec族函数调用进程后,会终结自己Python进程,新生成的进程会替换他。不产生返回值
import os note = "c:\\windows\\notepad.exe"
os.execl(note,"任意,但是必须写") #是调用程序时传入的参数
http://blog.51cto.com/wangyongbin/1672725
3.进程终止
(1)主函数中return直接退出程序,终止进程
(2)sys.exit函数。会返回值给调用进程(一般是操作系统),使用此返回值,可以判断程序是否正常突出或者出错。同时 使用该函数,在退出之前,会做一些清理操作。
(3)使用os.abort函数发送信号终止SIGABORT,可以进行终止进程,但是退出时不会进行清理操作。可以使用signal。signal()来为SIGABORT信号注册不同的学号处理函数,从而修改默认行为。一般尽量避免使用该函数
二:使用subprocess模块管理进程
subprocess模块中高级进程管理类Popen的使用:
>>> import subprocess >>> pingP = subprocess.Popen(args="ping -n 4 www.sina.com.cn",shell=True) >>> 正在 Ping spool.grid.sinaedge.com [124.95.163.249] 具有 32 字节的数据: 来自 124.95.163.249 的回复: 字节=32 时间=7ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=7ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=7ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=7ms TTL=53 124.95.163.249 的 Ping 统计信息: 数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失), 往返行程的估计时间(以毫秒为单位): 最短 = 7ms,最长 = 7ms,平均 = 7ms >>> print(pingP.pid) 6204 >>> print(pingP.returncode) None
pingP = subprocess.Popen(args="ping -n 4 www.sina.com.cn",shell=True)
linux下,当shell为True时会直接使用系统shell来执行指令,否则使用os.execvp来执行对应的程序。window下无差别对于True和False。
>>> print(pingP.pid) 6204 >>> print(pingP.returncode) None
上面的输出值,分别是子进程id和返回值。返回值输出None表示此子进程还没有被终止。
D:\MyPython\day24\jc>python pro.py 8200 None D:\MyPython\day24\jc> 正在 Ping spool.grid.sinaedge.com [124.95.163.249] 具有 32 字节的数据: 来自 124.95.163.249 的回复: 字节=32 时间=8ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=7ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=7ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=8ms TTL=53 124.95.163.249 的 Ping 统计信息: 数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失), 往返行程的估计时间(以毫秒为单位): 最短 = 7ms,最长 = 8ms,平均 = 7ms
从上面数据中可以看出,由于网络延时,在主进程结束后,才去打印数据(子进程并没有结束,有打印的返回值可知None)。这样并不是太好,不加一限制,会将结果混淆。所以我们需要主进程去等待子进程的结束。
使用wait()方法。
pingP = subprocess.Popen(args="ping -n 4 www.sina.com.cn",shell=True) pingP.wait() print(pingP.pid) print(pingP.returncode)
D:\MyPython\day24\jc>python pro.py 正在 Ping spool.grid.sinaedge.com [124.95.163.249] 具有 32 字节的数据: 来自 124.95.163.249 的回复: 字节=32 时间=8ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=8ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=8ms TTL=53 来自 124.95.163.249 的回复: 字节=32 时间=7ms TTL=53 124.95.163.249 的 Ping 统计信息: 数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失), 往返行程的估计时间(以毫秒为单位): 最短 = 7ms,最长 = 8ms,平均 = 7ms 8276 0
使用wait等待子进程结束后再去获取返回值为0,代表子进程已终止。
默认获取的数据会直接显示在屏幕上,我们可以改变其输出方式。stdin.stdout,stderr分别用于指定程序标准输入,输出,错误处理器。可以使用PIPE管道去接收,或者文件描述符。默认为None直接显示。
import subprocess pingP = subprocess.Popen(args="ping -n 4 www.sina.com.cn",shell=True,stdout = subprocess.PIPE) #将数据直接存放在管道中,等待区读取,而不是直接显示出来
pingP.wait() print(pingP.pid) print(pingP.returncode) data = pingP.stdout.read() print(data.decode("gbk")) #从网络中获取的数据默认是字节码,我们需要对其进行编码。而window系统默认是gbk编码,所以我们获取的字节码是由gbk数据解码而来的,要想使用,必须编码为gbk
使用communicate()方法
pingP = subprocess.Popen(args="ping www.baidu.com",shell=True,stdout = subprocess.PIPE) pingPout,pingPerr = pingP.communicate() data = pingPout print(data.decode("gbk"))
def communicate(self, input=None, timeout=None)第一个参数允许设置输入参数(前提是该进程依旧存在,而且在我们输入参数后可以返回,而不是一直阻塞),第二个是设置超时时间
但是他还有一个用途:可以和wait一样获取构造函数执行命令下的结果。两者的区别大概就是:
当我们设置stdout等参数为PIPE时,管道是有数据大小的限制,当我们传入的数据大于这个值时,而我们有没有及时将数据从管道中取出,则数据一直堵塞管道,下面的数据无法读入,原来的数据无法处理,而此时我们使用wait方法去等待子进程返回时,子进程已经处于懵逼状态(数据一直读取不了),会导致死锁。卡在wait()调用上面。(有大小限制)
而使用communicate方法,先去将数据读取到管道中,然后将数据获取放在内存中去,去获取所有数据,然后调用wait方法等待子进程结束。这个方法不会产生上面的死锁问题,但是读取大文件,全部放在内存中,并不是太妥当。
推文:https://blog.csdn.net/carolzhang8406/article/details/22286913
调用外部系统命令call()和check_all()
这两种方法和Popen的构造函数类似,是对其的简化。其参数列表和构造参数是一致的。call会直接调用命令产生子进程,并等待其结束,然后返回子进程的返回值。
retcode = subprocess.call(["ls","-l"]) #数据在子进程中执行,打印在屏幕上 print(retcode) #成功返回0
check_call只是在其基础上,对他进行了返回码的判断,然后抛出异常。
def check_call(*popenargs, **kwargs): retcode = call(*popenargs, **kwargs) if retcode: cmd = kwargs.get("args") if cmd is None: cmd = popenargs[0] raise CalledProcessError(retcode, cmd) return 0
call内部也是实现了一个Popen对象,其参数是使用call传递进去,两者参数一致。
在call中只返回了子进程的返回码。直接将数据展示到了屏幕上,但是我们想将数据存放在管道上进行获取,那么如何获取数据,这个在py2.5中似乎没有办法,我们只能使用自己再创建一个Popen实例来完成这些复杂操作。但是这个函数可以用来替换如os.system()等函数
在py3.5中我们可以使用run方法,获取一个已经完成的子进程,从中获取数据。
def run(*popenargs, input=None, timeout=None, check=False, **kwargs): with Popen(*popenargs, **kwargs) as process: stdout, stderr = process.communicate(input, timeout=timeout) return CompletedProcess(process.args, retcode, stdout, stderr)
class CompletedProcess(object): def __init__(self, args, returncode, stdout=None, stderr=None): self.args = args self.returncode = returncode self.stdout = stdout self.stderr = stderr def check_returncode(self): """Raise CalledProcessError if the exit code is non-zero.""" if self.returncode: raise CalledProcessError(self.returncode, self.args, self.stdout, self.stderr)
retObj = subprocess.run(["ls","-l"],stdout=subprocess.PIPE) data = retObj.stdout print(data.decode("gbk"))
或者我们不使用管道,使用文件描述符,也可以在2.5中使用call获取数据。
fp = open("sp","w+",encoding="gbk") try: retcode = subprocess.check_call(["ping", "www.baidu.com"], stdout=fp) print(retcode) # 成功返回0 except Exception as e: print(e) finally: fp.close()
推文:详细参数:https://www.cnblogs.com/yyds/p/7288916.html
三:进程间的信号机制引入
try: retcode = subprocess.call("cmd", shell=True) #若是返回小于0的数,则是信号的负值 if retcode < 0 : print("子进程被信号中断") else: print("正常返回") except Exception as e: print("错误"+e)
当子进程被信号中断的时候,将返回信号的负值。
介绍:
信号处理也是进程间通信的一种方式。信号是操作系统的一种软件中断。采用异步方式传递给应用程序。信号模块只包含系统中定义的信号,对于其他信号是忽略的。
信号的处理:
在signal模块汇总提供相关方法。核心函数是signal.siganl()函数。作用是为中断信号注册指定的信号处理函数。当程序收到了其中我们进行注册后的信号,回去调用我们定义的处理函数,
def signal(signalnum, handler):
第一个参数是信号量,第二个是我们设置的处理函数的句柄(也可以是系统中已定义的某个信号处理函数)
The action can be SIG_DFL(系统默认处理), SIG_IGN(忽略此信号), or a callable Python object.
补充(1):
ctrl-c 是发送 SIGINT 信号,终止一个进程;进程无法再重续。
ctrl-z 是发送 SIGSTOP信号,挂起一个进程;进程从前台转入后台并暂停,可以用bg使其后台继续运行,fg使其转入前台运行。
ctrl-d 不是发送信号,而是表示一个特殊的二进制值,表示 EOF,通常是表示输入终止,通常进程接收到终止符可以完成运行并退出。
补充(2):
SIGKILL 和 SIGSTOP是不能被捕获的,由内核决定
信号机制的使用:
import signal """ A signal handler function is called with two arguments: the first is the signal number, the second is the interrupted stack frame.可中断堆栈帧 """ def signal_handler(signum,frame): #SIGINT信号处理函数 print("sigint func execute") print(signum,frame) print(type(frame)) #<class 'frame'> signal.signal(signal.SIGINT,signal_handler) pingP = subprocess.Popen("ping www.baidu.com",shell=True) pingP.wait() print(pingP.pid) print(pingP.returncode) func = signal.getsignal(signal.SIGINT) #原来查询特定信号值所关联的信号处理函数,返回值是一个可调用的Python对象,或者是SIG_DFL,SIG_ING,None print(func) # func(signal.SIGINT,0)
加上几个UNIX中使用的方法
1.pause() 进程暂停,等待信号。
import signal def sigHandle(signum,frame): print(signum) signal.signal(signal.SIGINT,sigHandle) signal.pause() print("signal pause fin")
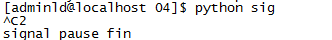
2.alarm定时器发送信号,用于在一定时间后,向进程发送SIGALRM信号:
import signal import time def sigHandle(signum,frame): print("Timer is exec") signal.signal(signal.SIGALRM,sigHandle) signal.alarm(5) for i in range(10): time.sleep(1) print(i) #time.sleep(15) print("time fin")
补充:注意,在使用信号的时候,对于sleep这个函数,是可中断睡眠,由于信号是异步,所以到时间后会去执行处理函数,处理完后,不会再次回来继续执行sleep方法,而是执行下一条语句,所以我们不要使用sleep(多秒),而是每次循环延时一秒
0 1 2 3 Timer is exec 4 5 6 7 8 9 time fin
3.发送信号。
使用kill可以向进程发送信号 kill -9 进程号pid 可以杀死进程 kill默认发送的是TREM信号,可以被捕获,所以对于一些进程是无法杀死,这时就需要用到-9 发送SIGKILL信号(是无法被捕获的)
在python中kill在os模块中
import signal import os def signal_handler(signum,frame): #SIGINT信号处理函数 print("sigint func execute") signal.signal(signal.SIGINT,signal_handler) pingP = subprocess.Popen("ping www.baidu.com",shell=True) os.kill(pingP.pid,signal.SIGINT) #直接将子进程杀死了,不会进行输出 pingP.wait() print(pingP.pid) print(pingP.returncode)
信号使用的规则:
(1)尽管信号是一种异步的信息传递机制,但是实际上在进行长时间计算的时候使用信号,可能会产生一定的延时
(2)当程序在执行I/O操作的时候收到信号中断,有可能使得在信号处理函数执行完毕后触发异常,或者直接触发异常
import signal """ A signal handler function is called with two arguments: the first is the signal number, the second is the interrupted stack frame.可中断堆栈帧 """ def signal_handler(signum,frame): #SIGINT信号处理函数 print("sigint func execute") print(signum,frame) print(type(frame)) #<class 'frame'> signal.signal(signal.SIGINT,signal_handler) while True: ret = input("Prompt>>") print(ret) ---------------------------------------------------------- Prompt>>Traceback (most recent call last): File "<stdin>", line 2, in <module> KeyboardInterrupt
(3)Python已经为部分的信号注册了处理函数,如在前面的SIGINT信号,默认情况下,就会转化为KeyboardInterrupt
(4)当信号和线程同时使用的时候,必须要小心。如果使用不当,可能会出现意想不到的问题
在同时使用信号和线程的时候,特别要记住的是:总是在主线程中执行signal()函数,所以不能使用线程作为线程间的通信方式
四:多进程multiprocessing模块
推文:https://www.zhihu.com/question/23474039
如果你的代码是CPU密集型,多个线程的代码很有可能是线性执行的。所以这种情况下多线程是鸡肋,效率可能还不如单线程因为有context switch
如果你的代码是IO密集型,多线程可以明显提高效率。例如制作爬虫(我就不明白为什么Python总和爬虫联系在一起…不过也只想起来这个例子…),绝大多数时间爬虫是在等待socket返回数据。这个时候C代码里是有release GIL的,最终结果是某个线程等待IO的时候其他线程可以继续执行。
由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。
Python中提供了非常好用的多进程包multiprocessing。只需要定义一个函数,python就会完成其他所有事情。
借助这个包,可以轻松完成从单 进程到并发执行的转换,能更好的利用多CPU。multiprocessing支持子进程,通信和共享数据,执行不同形式的同步,提供了Process,Queue,Pipe,Lock等组件。
利用multiprocessing.Process对象来创建一个进程,该进程可以运行在python程序内部编写的函数。有start(),run(),join()等方法。此外,该包中有Lock/Event/Semaphore/Condition类(可以通过参数将数据同步传输到各个进程,来进行同步)
在使用这些方法时,需要注意:
- 在UNIX平台上,当某个进程终结之后,该进程需要被其父进程调用wait,否则进程成为僵尸进程(Zombie)。所以,有必要对每个Process对象调用join()方法 (实际上等同于wait)。对于多线程来说,由于只有一个进程,所以不存在此必要性。
- multiprocessing提供了threading包中没有的IPC(比如Pipe和Queue),效率上更高。应优先考虑Pipe和Queue,避免使用Lock/Event/Semaphore/Condition等同步方式 (因为它们占据的不是用户进程的资源)。
- 多进程应该避免共享资源。在多线程中,我们可以比较容易地共享资源,比如使用全局变量或者传递参数。在多进程情况下,由于每个进程有自己独立的内存空间,以上方法并不合适。此时我们可以通过共享内存和Manager的方法来共享资源。但这样做提高了程序的复杂度,并因为同步的需要而降低了程序的效率。
Process.PID中保存有PID,如果进程还没有start(),则PID为None。
简单使用:
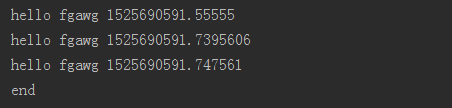
from multiprocessing import Process import time def f(name): time.sleep(1) print("hello",name,time.time()) if __name__ == "__main__": p_list = [] for i in range(3): p = Process(target=f,args=('fgawg',)) p_list.append(p) p.start() for p in p_list: p.join() print("end")
可以实现并发:
最后执行我们的函数是通过run()方法去调用的。
class BaseProcess(object): def __init__(self, group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None): self._target = target def run(self): ''' Method to be run in sub-process; can be overridden in sub-class ''' if self._target: self._target(*self._args, **self._kwargs)
所以我们可以直接使用类式调用,对进程进行调用,将需要执行的函数写在run()方法中。
from multiprocessing import Process import time,os class MyProcess(Process): def __init__(self): super(MyProcess, self).__init__() def run(self): time.sleep(5) print("hello",time.time()) print(self.pid,os.getpid()) #获取自己的进程号 print(os.getppid()) #获取父进程号 if __name__ == "__main__": p_list = [] for i in range(3): p = MyProcess() p_list.append(p) p.start() for p in p_list: p.join() print("end")
Process类
参数:
def __init__(self, group=None, target=None, name=None, args=(), kwargs={}):
group: 线程组,目前还没有实现,库引用中提示必须是None;
assert group is None, 'group argument must be None for now'
target: 要执行的方法;
name: 进程名;
args/kwargs: 要传入方法的参数。
方法:
is_alive():返回进程是否在运行。
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。
terminate():不管任务是否完成,立即停止工作进程
属性:
authkey
daemon:和线程的setDeamon功能一样
exitcode(进程在运行时为None、如果为–N,表示被信号N结束) -N 是一个负数 N是信号值
name:进程名字。
pid:进程号
进程间通讯
注意:由于进程之间的数据需要各自持有一份,所以创建进程需要的非常大的开销。
不同进程间内存是不共享的,要想实现两个进程间的数据交换,可以用以下方法
Pipe管道实现数据共享:
from multiprocessing import Process,Pipe class MyProcess(Process): def __init__(self,pipe_child): super(MyProcess, self).__init__() self.pipe_child = pipe_child def run(self): self.pipe_child.send(['fawfw',57]) self.pipe_child.close() if __name__ == "__main__": parent_conn,child_conn = Pipe() p = MyProcess(pipe_child=child_conn) p.start() print(parent_conn.recv()) p.join() print("end")
from multiprocessing import Process,Pipe def func(child_pipe): child_pipe.send(["fwafaw",444,]) child_pipe.close() if __name__ == "__main__": parent_conn,child_conn = Pipe() p = Process(target=func,args=(child_conn,)) p.start() print(parent_conn.recv()) p.join() print("end") ---------------------------------------------------------- ['fwafaw', 444] end
注意其中:
def Pipe(duplex=True): 默认是全双工模式,即两边都可以进行数据传输和接收
def Pipe(duplex=False): 传输方式为单工模式,前面的接收,后面的为传输
Queue实现数据传输:
from multiprocessing import Process,Queue import os def func(que,n): que.put([n,os.getpid()]) if __name__ == "__main__": q = Queue() p_list = [] for i in range(3): p = Process(target=func,args=(q,i)) p_list.append(p) p.start() for i in p_list: p.join() print(q.get()) print(q.get()) print(q.get()) print("end") ---------------------------------------------------------- [2, 11132] [1, 11124] [0, 11116] end
Manager实现数据共享
#使用Manager中列表 from multiprocessing import Process,Manager def func(lst,i): lst.append(i) if __name__ == "__main__": p_list = [] manage = Manager() lst = manage.list() for i in range(3): p = Process(target=func,args=(lst,i,)) p_list.append(p) p.start() for i in p_list: p.join() print(lst) print("end") ---------------------------------------------------------- [1, 0, 2] end
其中还包括其他数据类型的使用:
A manager returned by Manager() will support types
list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array.
Semaphore信号量:原来控制对共享资源的访问数量,例如池的最大连接数
from multiprocessing import Process, Semaphore import time,os def f(s, i): s.acquire() print("Semaphore acquired") time.sleep(i) print('hello world', i) print("Semaphore release") s.release() if __name__ == '__main__': print("start") bg = time.time() sp = Semaphore(2) p_list = [] for i in range(10): pro = Process(target=f, args=(sp,i,)) p_list.append(pro) pro.start() for i in range(10): p_list[i].join() print("end") end = time.time() print(end-bg) #27.68558359146118花了大概一半的事件,正好是我们允许一次访问是2个进程(两个停车位,走了就会有下一个去占)
start Semaphore acquired Semaphore acquired hello world 1 Semaphore release Semaphore acquired hello world 2 Semaphore release Semaphore acquired hello world 3 Semaphore release Semaphore acquired hello world 7 Semaphore release Semaphore acquired hello world 6 Semaphore release Semaphore acquired hello world 5 Semaphore release Semaphore acquired hello world 9 Semaphore release Semaphore acquired hello world 0 Semaphore release Semaphore acquired hello world 4 Semaphore release hello world 8 Semaphore release end 27.68558359146118
由输出可以知道,Semaphore的访问限制不是一次同时加入两个,同时退出两个,而是有空位就会去占据,始终保持这两个访问数量都在使用。
Event实现进程间同步通信
class Event(object): def __init__(self, *, ctx): self._cond = ctx.Condition(ctx.Lock()) #条件锁 self._flag = ctx.Semaphore(0) #信号量为0,堵塞状态 def is_set(self): with self._cond: #with获取锁 if self._flag.acquire(False): #获取一个信号量,前提是信号量不为0,否则返回False self._flag.release() return True return False def set(self): with self._cond: self._flag.acquire(False) self._flag.release() #这个释放信号量,是将信号量对象中的计数加1 self._cond.notify_all() def clear(self): with self._cond: self._flag.acquire(False) def wait(self, timeout=None): with self._cond: if self._flag.acquire(False): self._flag.release() else: self._cond.wait(timeout) if self._flag.acquire(False): self._flag.release() return True return False
def acquire(self, blocking=True, timeout=None): """ acquire(blocking=True, timeout=None) -> bool Acquire the semaphore. .. caution:: If this semaphore was initialized with a size of 0, this method will block forever (unless a timeout is given or blocking is set to false). :keyword bool blocking: If True (the default), this function will block until the semaphore is acquired. :keyword float timeout: If given, specifies the maximum amount of seconds this method will block. :return: A boolean indicating whether the semaphore was acquired. If ``blocking`` is True and ``timeout`` is None (the default), then (so long as this semaphore was initialized with a size greater than 0) this will always return True. If a timeout was given, and it expired before the semaphore was acquired, False will be returned. (Note that this can still raise a ``Timeout`` exception, if some other caller had already started a timer.) """ if self.counter > 0: self.counter -= 1 return True if not blocking: return False timeout = self._do_wait(timeout) if timeout is not None: # Our timer expired. return False # Neither our timer no another one expired, so we blocked until # awoke. Therefore, the counter is ours self.counter -= 1 assert self.counter >= 0 return True
def release(self): """ Release the semaphore, notifying any waiters if needed. """ self.counter += 1 self._start_notify() return self.counter
class Condition(object): def __init__(self, lock=None, *, ctx): self._lock = lock or ctx.RLock() self._sleeping_count = ctx.Semaphore(0) self._woken_count = ctx.Semaphore(0) self._wait_semaphore = ctx.Semaphore(0) self._make_methods() def wait(self, timeout=None): assert self._lock._semlock._is_mine(), \ 'must acquire() condition before using wait()' # indicate that this thread is going to sleep self._sleeping_count.release() # release lock count = self._lock._semlock._count() for i in range(count): self._lock.release() try: # wait for notification or timeout return self._wait_semaphore.acquire(True, timeout) finally: # indicate that this thread has woken self._woken_count.release() # reacquire lock for i in range(count): self._lock.acquire()
def notify_all(self): assert self._lock._semlock._is_mine(), 'lock is not owned' assert not self._wait_semaphore.acquire(False) # to take account of timeouts since last notify*() we subtract # woken_count from sleeping_count and rezero woken_count while self._woken_count.acquire(False): res = self._sleeping_count.acquire(False) assert res sleepers = 0 while self._sleeping_count.acquire(False): self._wait_semaphore.release() # wake up one sleeper sleepers += 1 if sleepers: for i in range(sleepers): self._woken_count.acquire() # wait for a sleeper to wake # rezero wait_semaphore in case some timeouts just happened while self._wait_semaphore.acquire(False): pass
from multiprocessing import Process, Event import time,os def wait_for_event(e): print("wait_for_event:starting") e.wait() print("wait_for_event:e.is_set()->"+str(e.is_set())) def wait_for_event_timeout(e,t): print("wait_for_event_timeout:starting") e.wait(t) print("wait_for_event_timeout:e.is_set->"+str(e.is_set())) if __name__ == '__main__': print("start") bg = time.time() e = Event() w1 = Process(name="block",target=wait_for_event,args=(e,)) w2 = Process(name="unblock",target=wait_for_event_timeout,args=(e,2)) w1.start() w2.start() time.sleep(3) e.set() print("end") end = time.time() print(end-bg) #3.2621865272521973
输出:
start wait_for_event:starting wait_for_event_timeout:starting wait_for_event_timeout:e.is_set->False #非阻塞状态,到达我们设置的2秒后,依旧没有接受到信号,所以是False end wait_for_event:e.is_set()->True #阻塞状态,一致到达,直到接收到信号 3.2621865272521973
事件通信:当我们的事件发生改变,所有有关的进程都会改变
from multiprocessing import Process, Event import time,os def wait_for_event(e): print("wait_for_event:starting") e.wait() print("wait_for_event:e.is_set()->"+str(e.is_set())) def wait_for_event_timeout(e,t): print("wait_for_event_timeout:starting") e.wait(t) print("wait_for_event_timeout:e.is_set->"+str(e.is_set())) if __name__ == '__main__': print("start") bg = time.time() e = Event() p_list = [] for i in range(5): pro = Process(target=wait_for_event, args=(e,)) p_list.append(pro) for i in range(5): pro = Process(target=wait_for_event_timeout, args=(e, i)) p_list.append(pro) for i in range(10): p_list[i].start() time.sleep(3) e.set() for i in range(10): p_list[i].join() print("end") end = time.time() print(end-bg) #4.196239948272705 ---------------------------------------------------------- start wait_for_event_timeout:starting wait_for_event:starting wait_for_event:starting wait_for_event_timeout:starting wait_for_event_timeout:e.is_set->False wait_for_event_timeout:starting wait_for_event:starting wait_for_event:starting wait_for_event_timeout:starting wait_for_event:starting wait_for_event_timeout:starting wait_for_event_timeout:e.is_set->False wait_for_event:e.is_set()->True wait_for_event:e.is_set()->True wait_for_event_timeout:e.is_set->True wait_for_event:e.is_set()->True wait_for_event_timeout:e.is_set->True wait_for_event:e.is_set()->True wait_for_event:e.is_set()->True wait_for_event_timeout:e.is_set->True end 4.196239948272705
使用Lock锁,保证数据进程同步
未加锁,并行执行:
from multiprocessing import Process, Lock import time def f(i): time.sleep(5) print('hello world', i) if __name__ == '__main__': print("start") bg = time.time() p_list = [] for num in range(10): pro = Process(target=f, args=(num,)) p_list.append(pro) pro.start() for num in range(10): p_list[num].join() print("end") end = time.time() print(end-bg) #7.856449365615845
加锁后的执行时间(谁先抢到这把锁,谁就去先执行,直到将锁释放后再去抢锁):
from multiprocessing import Process, Lock import time def f(l, i): l.acquire() try: time.sleep(5) print('hello world', i) finally: l.release() if __name__ == '__main__': print("start") bg = time.time() lock = Lock() p_list = [] for num in range(10): pro = Process(target=f, args=(lock, num)) p_list.append(pro) pro.start() for num in range(10): p_list[num].join() print("end") end = time.time() print(end-bg) #51.65195417404175
注意:在多进程中不支持共享全局变量。
from multiprocessing import Process print(66666) def func(num,i): pass if __name__ == "__main__": p_list = [] num = 10 for i in range(3): p = Process(target=func,args=(num,i)) p_list.append(p) p.start() for i in p_list: p.join()
""" 66666 正常顺序下来的第一条 66666 子进程开始后有跑回这个文件重新执行 66666 66666 """
推测:追踪代码:
class Popen(object): ''' Start a subprocess to run the code of a process object ''' method = 'spawn' def __init__(self, process_obj): prep_data = spawn.get_preparation_data(process_obj._name) ......... with open(wfd, 'wb', closefd=True) as to_child:try: reduction.dump(prep_data, to_child) #prep_data其中包含有环境信息,文件路径... reduction.dump(process_obj, to_child) #process_obj含有父进程对象的信息 finally: context.set_spawning_popen(None)
所以应该是子进程生成时会将父进程的资源再次进行拷贝,并执行下去。导致我们在生成子进程时出现,会重复执行print("66666")语句。
所以我们不要将锁放在全局变量中,而是应该放在__main__中进行生成,不然,在每一个子进程生成时,都会去生成一个属于自己的锁,那就没有了数据同步的意义了。
from multiprocessing import Process, Lock import time lock = Lock() def f(i): lock.acquire() try: time.sleep(5) print('hello world', i) finally: lock.release() if __name__ == '__main__': print("start") bg = time.time() p_list = [] for num in range(10): pro = Process(target=f, args=(num,)) p_list.append(pro) pro.start() for num in range(10): p_list[num].join() print("end") end = time.time() print(end-bg) #7.288417100906372
补充:在锁设置正确的情况下,可能你会在自定义函数中去id(锁),查看内存地址是否一致。结果可能不尽人意。因为你查看的是一个对象,不能代表那把锁,这把锁可能是一个类成员属性,或者是静态成员等,不会随着对象的id不同而改变自己再内存中的位置,所以这把锁还是正确的.......(这里也是导致我思考好久的原因...当我发现这个“锁对象”的id不一致时)
Pool进程池
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
简单使用:(非阻塞apply_async)
from multiprocessing import Process, Pool import time,os def func(num): print(num,os.getpid(),"start") time.sleep(3) print(num,"end") if __name__ == '__main__': print("start") bg = time.time() pool = Pool(processes=3) for i in range(10): pool.apply_async(func,args=(i,)) #非阻塞方法
#注意:在使用join之前需要先调用close方法,不然会产生AssertionError错误 pool.close() #关闭进程池,不再接受新的任务 pool.join() #主进程阻塞,等待子进程的退出,需要在close或terminate后面使用 print("end") end = time.time() print(end-bg) #12.909738540649414
输出:
start 0 3136 start 1 7172 start 2 8388 start 0 end 3 3136 start 1 end 4 7172 start 2 end 5 8388 start 3 end 6 3136 start 4 end 7 7172 start 5 end 8 8388 start 6 end 9 3136 start 7 end 8 end 9 end end 12.990743160247803
补充:
pool = Pool(processes=3)
这里的Pool(processes=3)不一定是一次性产生3个进程。只有当我们的代码中有堵塞状态(上面就是有阻塞状态,产生3个进程<允许的最多个数>)或者代码执行需要较长时间,才会去产生新的子进程去进行执行。
from multiprocessing import Process, Pool import time,os def func(num): print(num,os.getpid(),"start") # time.sleep(3) for i in range(4): #模拟任务 num += i print(num,"end") if __name__ == '__main__': print("start") bg = time.time() pool = Pool(processes=3) for i in range(10): pool.apply_async(func,args=(i,)) pool.close() pool.join() print("end") end = time.time() print(end-bg) #1.0350592136383057 ---------------------------------------------------------- start 0 6384 start 6 end 1 6384 start 7 end 2 6384 start 8 end 3 6384 start 9 end 4 6384 start 10 end 5 6384 start 11 end 6 6384 start 12 end 7 6384 start 13 end 8 6188 start 9 6384 start 14 end 15 end end 1.0350592136383057
from multiprocessing import Process, Pool import time,os def func(num): print(num,os.getpid(),"start") # time.sleep(3) # for i in range(4): #模拟任务 # num += i print(num,"end") if __name__ == '__main__': print("start") bg = time.time() pool = Pool(processes=3) for i in range(10): pool.apply_async(func,args=(i,)) pool.close() pool.join() print("end") end = time.time() print(end-bg) #1.060060739517212 ---------------------------------------------------------- start 0 7768 start 0 end 1 7768 start 1 end 2 7768 start 2 end 3 7768 start 3 end 4 7768 start 4 end 5 7768 start 5 end 6 7768 start 6 end 7 7768 start 7 end 8 7768 start 8 end 9 7768 start 9 end end 1.060060739517212
进程池(阻塞apply的使用)
from multiprocessing import Process, Pool import time,os def func(num): print(num,os.getpid(),"start") time.sleep(3) print(num,"end") if __name__ == '__main__': print("start") bg = time.time() pool = Pool(processes=3) for i in range(10): pool.apply(func,args=(i,)) pool.close() pool.join() print("end") end = time.time() print(end-bg) #30.94777011871338
start 0 9976 start 0 end 1 9636 start 1 end 2 4740 start 2 end 3 9976 start 3 end 4 9636 start 4 end 5 4740 start 5 end 6 9976 start 6 end 7 9636 start 7 end 8 4740 start 8 end 9 9976 start 9 end end 30.94777011871338
比较前面非阻塞进程池的输出结果,可以知道:进程池是按照顺序,子进程一个一个的执行,而不是并行执行,是需要一个结束才去下一个。其他的还是相同的。若无阻塞或复杂业务,不一定会是产生3个子进程。
若是执行的自定义方法中含有返回值,获取返回值
from multiprocessing import Process, Pool import time,os def func(num): print(num,os.getpid(),"start") time.sleep(3) print(num,"end") return num,os.getpid() if __name__ == '__main__': print("start") bg = time.time() result = [] pool = Pool(processes=3) for i in range(10): ret = pool.apply_async(func,args=(i,)) result.append(ret) pool.close() pool.join() for item in result: print(item.get()) #在执行完后去获取所有的返回值 print("end") end = time.time() print(end-bg)
为进程池添加多个任务
from multiprocessing import Process, Pool import time,os def func(num): print(num,os.getpid(),"start") time.sleep(3) def func2(num): print(num,os.getpid(),"start2") time.sleep(3) if __name__ == '__main__': print("start") bg = time.time() result = [] pool = Pool(processes=3) for i in range(5): ret = pool.apply_async(func,args=(i,)) ret = pool.apply_async(func2,args=(i,)) pool.close() pool.join() print("end") end = time.time() print(end-bg) #12.818733215332031
相当于一次注册10个任务,分给3个子进程去执行。需要执行4次,大概12,秒
start 0 9520 start 0 9532 start2 1 10136 start 1 9520 start2 2 9532 start 2 10136 start2 3 9520 start 3 9532 start2 4 10136 start 4 9520 start2 end 12.818733215332031
使用fork创建子进程(守护进程)linux系统下可用
像httpd、mysqld、vsftpd最后个字母d其实就是表示daemon的意思。
import os,sys,time pid = os.fork() if pid > 0: #若是pid大于0则是父进程,否则是子进程 sys.exit() #要想生成守护进程,其父进程不能存在,不能让父进程被人杀除,守护进程跟着完蛋
#修改子进程工作目录,为避免挂载问题,设置在根目录 os.chdir("/")
#创建新的会话,子进程成为会话主进程。 os.setsid()
#修改工作目录的掩码。与chmod相反,umask(0)代表权限全给 os.umask(0)
print(os.getpid()) #获取进程号,方便关闭 kill -9 pid #重定向原有的标准IO流 sys.stdout.flush() sys.stderr.flush()
sys.stdin.flush() si = open("/dev/null","r") #/dev/null 代表丢弃的意思 so = open("/home/test3.txt","a+") se = open("/dev/null","a+",0) os.dup2(si.fileno(),sys.stdin.fileno()) os.dup2(so.fileno(),sys.stdout.fileno()) os.dup2(se.fileno(),sys.stderr.fileno()) for i in range(10): print(i) #在我们设置的test3.txt进行输出 while True: time.sleep(10) f = open("/home/test2.txt","a") f.write("hello\r\n") #守护进程对文件进行修改
也可以在守护进程中生成子进程进行操作。
推文:Python实例浅谈之五Python守护进程和脚本单例运行
需要在linux下一管理员身份进行操作。
- fork子进程,而后父进程退出,此时子进程会被init进程接管。
- 修改子进程的工作目录、创建新进程组和新会话、修改umask。
- 重定向孙子进程的标准输入流、标准输出流、标准错误流到/dev/null,或者其他路径,然后可以进行测试。
- 也可以在其中设置子进程
在window平台下,生成进程时,有守护进程这个参数。但是如何生成守护进程.....?还需要了解
作者:山上有风景
欢迎任何形式的转载,但请务必注明出处。
限于本人水平,如果文章和代码有表述不当之处,还请不吝赐教。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 开发中对象命名的一点思考
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· C# 深度学习:对抗生成网络(GAN)训练头像生成模型
· 手把手教你更优雅的享受 DeepSeek
· AI工具推荐:领先的开源 AI 代码助手——Continue
· 探秘Transformer系列之(2)---总体架构
· V-Control:一个基于 .NET MAUI 的开箱即用的UI组件库
· 乌龟冬眠箱湿度监控系统和AI辅助建议功能的实现