


基于HDFS的SparkStreaming案例实战和内幕源码解密
一:Spark集群开发环境准备
- 启动HDFS,如下图所示:

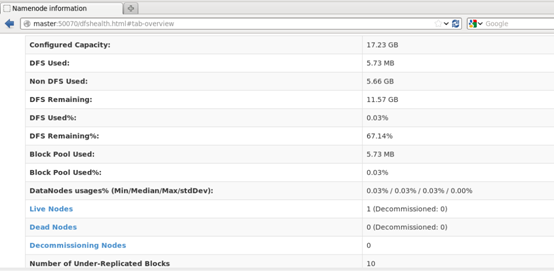
通过web端查看节点正常启动,如下图所示:
2.启动Spark集群,如下图所示:

通过web端查看集群启动正常,如下图所示:

3.启动start-history-server.sh,如下图所示:
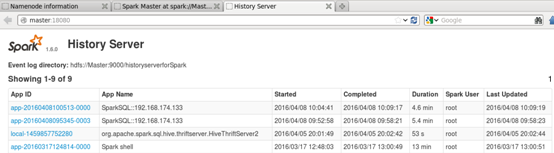
二:HDFS的SparkStreaming案例实战(代码部分)
package com.dt.spark.SparkApps.sparkstreaming;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by Jonson on 2016/4/17.
*/
public class SparkStreamingOnHDFS {
public static void main(String[] args){
/**
* 第一步:配置SparkConf
* 1. 至少两条线程:
* 因为Spark
Streaming应用程序在运行的时候,至少有一条线程用于不断的循环接收数据,
* 并且至少有一条线程用于处理接收的数据(否则的话无法有线程用于处理数据,随着时间的推移,内存和磁盘都不堪重负)
* 2. 对于集群而言,每个Executor一般而言肯定不止一个线程,对于处理Spark Streaming的应用程序而言,每个Executor一般
* 分配多少个Core合适呢?根据我们过去的经验,5个左右的core是最佳的(分配为奇数个Core为最佳)。
*/
final SparkConf conf = new SparkConf().setMaster("spark://Master:7077").setAppName("SparkOnStreamingOnHDFS");
/**
* 第二步:创建SparkStreamingContext,这个是Spark Streaming应用程序所有功能的起始点和程序调度的核心
* 1,SparkStreamingContext的构建可以基于SparkConf参数,也可以基于持久化SparkStreamingContext的内容
* 来恢复过来(典型的场景是Driver崩溃后重新启动,由于Spark Streaming具有连续7*24小时不间断运行的特征,
* 所有需要在Driver重新启动后继续上一次的状态,此时状态的恢复需要基于曾经的checkpoint)
* 2,在一个Spark
Streaming应用程序中可以创建若干个SparkStreamingContext对象,使用下一个SparkStreamingContext
* 之前需要把前面正在运行的SparkStreamingContext对象关闭掉,由此,我们获得一个重大启发:SparkStreamingContext
* 是Spark
core上的一个应用程序而已,只不过Spark Streaming框架箱运行的话需要Spark工程师写业务逻辑
*/
// JavaStreamingContext jsc = new
JavaStreamingContext(conf, Durations.seconds(5));//Durations.seconds(5)设置每隔5秒
final String checkpointDirectory = "hdfs://Master:9000/library/SparkStreaming/Checkpoint_Data";
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() {
@Override
public JavaStreamingContext create() {
return createContext(checkpointDirectory,conf);
}
};
/**
* 可以从失败中恢复Driver,不过还需要制定Driver这个进程运行在Cluster,并且提交应用程序的时候
* 指定
--supervise;
*/
JavaStreamingContext jsc =
JavaStreamingContext.getOrCreate(checkpointDirectory, factory);
/**
* 现在是监控一个文件系统的目录
* 此处没有Receiver,Spark Streaming应用程序只是按照时间间隔监控目录下每个Batch新增的内容(把新增的)
* 作为RDD的数据来源生成原始的RDD
*/
//指定从HDFS中监控的目录
JavaDStream lines = jsc.textFileStream("hdfs://Master:9000/library/SparkStreaming/Data");
/**
* 第四步:接下来就像对于RDD编程一样基于DStreaming进行编程!!!
* 原因是:
* DStreaming是RDD产生的模板(或者说类)。
* 在Spark Streaming具体发生计算前其实质是把每个batch的DStream的操作翻译成对RDD的操作!!
* 对初始的DStream进行Transformation级别的处理,例如Map,filter等高阶函数的编程,来进行具体的数据计算。
* 第4.1步:将每一行的字符串拆分成单个单词
*/
JavaDStream<String> words =
lines.flatMap(new FlatMapFunction<String,String>() {
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
/**
* 第4.2步:对初始的JavaRDD进行Transformation级别的处理,例如map,filter等高阶函数等的编程,来进行具体的数据计算
* 在4.1的基础上,在单词拆分的基础上对每个单词实例计数为1,也就是word => (word,1)
*/
JavaPairDStream<String,Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word,1);
}
});
/**
* 第4.3步:在每个单词实例计数的基础上统计每个单词在文件中出现的总次数
*/
JavaPairDStream<String,Integer> wordscount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws
Exception {
return v1 + v2;
}
});
/**
* 此处的print并不会直接触发Job的执行,因为现在的一切都是在Spark Streaming框架控制下的,对于Spark而言具体是否
* 触发真正的Job运行是基于设置的Duration时间间隔的
* 一定要注意的是:Spark Streaming应用程序要想执行具体的Job,对DStream就必须有output Stream操作,
* output Stream有很多类型的函数触发,例如:print,saveAsTextFile,saveAsHadoopFiles等,其实最为重要的一个方法是
* foraeachRDD,因为Spark Streaming处理的结果一般都会放在Redis,DB,DashBoard等上面,foreachRDD主要就是用来完成这些
* 功能的,而且可以随意的自定义具体数据到底存放在哪里!!!
*/
wordscount.print();
/**
* Spark Streaming执行引擎也就是Driver开始运行,Driver启动的时候是位于一条新的线程中的。
* 当然其内部有消息循环体用于接收应用程序本身或者Executor的消息;
*/
jsc.start();
jsc.awaitTermination();
jsc.close();
}
/**
* 工厂化模式构建JavaStreamingContext
*/
private static JavaStreamingContext createContext(String checkpointDirectory,SparkConf conf){
System.out.println("Creating new context");
SparkConf = conf;
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf,Durations.seconds(5));
ssc.checkpoint(checkpointDirectory);
return ssc;
}
}
代码打包在集群中运行
- 创建目录



2.脚本运行
脚本内容如下:


此时Spark Streaming会每隔5秒执行一次,不断的扫描监控目录下是否有新的文件。
3.上传文件到HDFS中的Data目录下

4.输出结果

三:Spark Streaming on HDFS源码解密
- JavaStreamingContextFactory的create方法可以创建JavaStreamingContext
- 而我们在具体实现的时候覆写了该方法,内部就是调用createContext方法来具体实现。上述实战案例中我们实现了createContext方法。
/*** Factory interface for creating a new JavaStreamingContext
*/
trait JavaStreamingContextFactory {
def create(): JavaStreamingContext
}
3.checkpoint:
一方面:保持容错
一方面保持状态
在开始和结束的时候每个batch都会进行checkpoint
** Sets the context to periodically checkpoint the DStream operations for master
* fault-tolerance. The graph will be checkpointed every batch interval.
* @param directory HDFS-compatible directory where the checkpoint data will be reliably stored
*/
def checkpoint(directory: String) {
ssc.checkpoint(directory)
}
4.remember:
流式处理中过一段时间数据就会被清理掉,但是可以通过remember可以延长数据在程序中的生命周期,另外延长RDD更长的时间。
应用场景:
假设数据流进来,进行ML或者Graphx的时候有时需要很长时间,但是bacth定时定条件的清除RDD,所以就可以通过remember使得数据可以延长更长时间。/**
* Sets each DStreams in this context to remember RDDs it generated in the last given duration.
* DStreams remember RDDs only for a limited duration of duration and releases them for garbage
* collection. This method allows the developer to specify how long to remember the RDDs (
* if the developer wishes to query old data outside the DStream computation).
* @param duration Minimum duration that each DStream should remember its RDDs
*/
def remember(duration: Duration) {
ssc.remember(duration)
}
5.在JavaStreamingContext中,getOrCreate方法源码如下:
如果设置了checkpoint ,重启程序的时候,getOrCreate()会重新从checkpoint目录中初始化出StreamingContext。
/* * Either recreate a StreamingContext from checkpoint data or create a new StreamingContext.
* If checkpoint data exists in the provided `checkpointPath`, then StreamingContext will be
* recreated from the checkpoint data. If the data does not exist, then the provided factory
* will be used to create a JavaStreamingContext.
*
* @param checkpointPath Checkpoint directory used in an earlier JavaStreamingContext program
* @param factory JavaStreamingContextFactory object to create a new JavaStreamingContext
* @deprecated As of 1.4.0, replaced by `getOrCreate` without JavaStreamingContextFactor.
*/
@deprecated("use getOrCreate without JavaStreamingContextFactor", "1.4.0")
def getOrCreate(
checkpointPath: String,
factory: JavaStreamingContextFactory
): JavaStreamingContext = {
val ssc = StreamingContext.getOrCreate(checkpointPath, () => {
factory.create.ssc
})
new JavaStreamingContext(ssc)
}
异常问题思考:

为啥会报错?
- Streaming会定期的进行checkpoint。
- 重新启动程序的时候,他会从曾经checkpoint的目录中,如果没有做额外配置的时候,所有的信息都会放在checkpoint的目录中(包括曾经应用程序信息),因此下次再次启动的时候就会报错,无法初始化ShuffleDStream。
总结:
备注:85课
更多私密内容,请关注微信公众号:DT_Spark

