


快速排序(QuickSort)
一、思路
快速排序是一种分治排序算法。快速排序先把数组重新整理分割两个子数组,然后对两个子数组进行排序。
快速排序和归并排序是互补的:
归并排序中,算法先将数组分为两个子数组进行排序,再将两个子数组进行归并成一个有序的数组。
快速排序中,算法先对数组进行重新整理分割成两个子数组,再对两个子数组进行排序,当两个子数组是有序时,整个数组即为有序的。
归并排序中,递归调用发生在处理整个数组之前。快速排序中,递归调用发生在处理整个数组之后。
归并排序数组是对半平分的,快速排序数组切分位置取决于数组的内容。
归并排序代码:
private static void sort(Comparable[] input, int lo, int hi) { if(lo >= hi)//just one entry in array return; int mid = lo + (hi-lo)/2; sort(input, lo, mid); sort(input, mid+1, hi); merge(input, lo, mid, hi); }
快速排序代码:
private static void sort(Comparable[] a, int lo, int hi) { if(hi <= lo) return; int j = partition(a, lo, hi); sort(a, lo, j-1); sort(a, j+1, hi); }
快速排序的关键在于partition方法,执行完partition方法之后应该达到,a[j]就是最终位置,a[lo~(j-1)]都要小于或等于a[j],a[j+1~hi]都要大于或等于a[j]。
策略:
1、选a[lo]作为切分元素
2、从数组左端开始查找大于或等于a[lo]的元素(下标i<=hi)
3、从数组右端开始查找小于或等于a[lo]的元素(下标j>=lo)
4、交换这两个元素。
5、重复2-4步骤,直到i和j交叉,退出。
6、最后交换a[lo]和a[j],最后一个步骤的时候a[j]<=a[lo],a[i]>=a[lo]。
partition方法最后要达到的状态是,切分元素左边不大于切分元素,切分元素右边不小于切分元素,所以a[lo]应该和a[j]交换。
最终切分元素在位置j上,a[j]在位置lo上,这是符合的。
partition代码:
private static int partition(Comparable[] a, int lo, int hi) { int i = lo; int j = hi + 1; Comparable v = a[lo]; while(true) { while(less(a[++i], v))//find item larger or equal to v if(i == hi) break; while(less(v, a[--j]));//not need to worry about j will be out of bound if(i >= j)//cross break; exch(a, i, j); } exch(a, lo, j); return j; }
测试用例:
package com.qiusongde; import edu.princeton.cs.algs4.In; import edu.princeton.cs.algs4.StdOut; import edu.princeton.cs.algs4.StdRandom; public class Quick { public static void sort(Comparable[] a) { // StdRandom.shuffle(a);//eliminate dependence on input // show(a);//for test sort(a, 0, a.length-1); } private static void sort(Comparable[] a, int lo, int hi) { if(hi <= lo) return; int j = partition(a, lo, hi); sort(a, lo, j-1); sort(a, j+1, hi); } private static int partition(Comparable[] a, int lo, int hi) { int i = lo; int j = hi + 1; Comparable v = a[lo]; while(true) { while(less(a[++i], v))//find item larger or equal to v if(i == hi) break; while(less(v, a[--j]));//not need to worry about j will be out of bound if(i >= j)//cross break; exch(a, i, j); } exch(a, lo, j); StdOut.printf("partition(input, %4d, %4d), j is %4d\n", lo, hi, j);//for test show(a);//for test return j; } private static void exch(Comparable[] a, int i, int j) { Comparable t = a[i]; a[i] = a[j]; a[j] = t; } private static boolean less(Comparable v, Comparable w) { return v.compareTo(w) < 0; } private static void show(Comparable[] a) { //print the array, on a single line. for(int i = 0; i < a.length; i++) { StdOut.print(a[i] + " "); } StdOut.println(); } public static boolean isSorted(Comparable[] a) { for(int i = 1; i < a.length; i++) { if(less(a[i], a[i-1])) return false; } return true; } public static void main(String[] args) { //Read strings from standard input, sort them, and print. String[] a = In.readStrings(); show(a); sort(a); assert isSorted(a); show(a); } }
输出结果:
K R A T E L E P U I M Q C X O S partition(input, 0, 15), j is 5 E C A I E K L P U T M Q R X O S partition(input, 0, 4), j is 3 E C A E I K L P U T M Q R X O S partition(input, 0, 2), j is 2 A C E E I K L P U T M Q R X O S partition(input, 0, 1), j is 0 A C E E I K L P U T M Q R X O S partition(input, 6, 15), j is 6 A C E E I K L P U T M Q R X O S partition(input, 7, 15), j is 9 A C E E I K L M O P T Q R X U S partition(input, 7, 8), j is 7 A C E E I K L M O P T Q R X U S partition(input, 10, 15), j is 13 A C E E I K L M O P S Q R T U X partition(input, 10, 12), j is 12 A C E E I K L M O P R Q S T U X partition(input, 10, 11), j is 11 A C E E I K L M O P Q R S T U X partition(input, 14, 15), j is 14 A C E E I K L M O P Q R S T U X A C E E I K L M O P Q R S T U X
二、注意细节
1、原地切分
如果像归并排序算法那样使用一个辅助数组可以很容易实现切分,但是将切分后的元素复制回原来的数组的开销也非常大。
2、别越界
如果切分元素是最大元素或最小元素,要特别注意数组越界的情况。
partition方法可通过显示的判断来预防这种情况,也可以通过将数组的最大值放置在数组最右端。
从而将下边红色代码去掉
while(less(a[++i], v))//find item larger or equal to v if(i == hi) break;
3、保持随机性
在排序之前要打乱数组的顺序,使之随机排序。这对预测算法的运行时间特别重要,同时也是为了避免最后情况的出现(第一次切分元素是最小值,第二次切分元素是第二小值,……)。
4、终止循环
保证循环结束需要非常小心。正确检测指针是否交叉(cross)需要一点技巧,并不像看上去那么简单。一个常见的错误就是没有考虑到和切分元素值相同的情况。
5、处理切分元素有重复的情况
左侧扫描最好是在遇到大于或等于切分元素的时候停下,右侧扫描最好是在遇到小于或等于切分元素的时候停下。
尽管这样会导致一些不必要的值交换,但在处理只有几个不同元素值得数组时,会导致运行时间变为平方级别。
6、终止递归
确保递归总能结束。
三、性能分析
1、最好性能
快速排序最好的情况是每次都正好把数组对半分。
比较次数:CN = 2CN/2 + N,即CN~NlgN。
2、平均性能(distinct keys)
平均比较次数:CN=N+1+(C0 + C1 + …… + CN-2 + CN-1)/N + (CN-1 + CN-2 + …… + C0)/N
第一项是partition函数的比较次数,第二项是左子数组的平均比较次数,第三项是右子数组的平均比较次数。
算出CN=2(N+1)(1/3+1/4+……+1/(N+1))~2(N+1)(ln(N+1)-ln3)~2NlnN约等于1.39NlgN
3、最差性能
在每次切分后,两个子数组总有一个是空的情况,性能最差。
CN=N+(N-1)+(N-2)+……+ 2 + 1 = (N+1)N/2
这不仅说明了算法所需的时间是平方级别的,也显示了算法所需的空间是线性的。
但是,对于大数组,这个事件发生的概率几乎可以忽略不计。而且我们在进行排序之前还对数组进行随机处理(shuffle),可以让这种糟糕情况的可能性降到最低。
比较次数的标准差为0.65N,随着N的增大,运行时间会趋于平均数,且不可能离平均数太大。
总结:对于大小为N的数组,快速排序运行时间在1.39NlgN的某个常数因子的范围之内。归并排序也能做到这点,但没有快速排序快,因为归并排序需要更多的数据移动次数。
这些数算法性能保证来自数学概率,但可以依赖之。
四、算法改进
1、切换为插入排序
对于小数组来说,快速排序比插入排序慢。
小数组容量M的最佳值是和系统相关的,5-15之间的任意值在大多数情况下都能满足需要。
2、三取样区分
改进快速排序性能的第二个办法是使用子数组的一小部分元素的中位数来作为切分元素。
这样做的代价是需要计算中位数,好处是可以使用sample item放在数组末尾作为哨兵,这样就可以去掉判断i和j出界的代码。下边j出界的代码是多余的,已经去除。
while(less(a[++i], v))//find item larger or equal to v if(i == hi) break; while(less(v, a[--j]));//not need to worry about j will be out of bound
3、熵最优排序
实际应用中经常会出现大量重复元素的数组,在这些情况下,快速排序还有改进空间。
例如,一个元素全部重复的子数组就不需要排序了,但上述快速排序还会继续切分为更小的数组。在有大量重复元素的情况下,快速排序的递归性会使元素重复的子数组经常出现。
这很有改进潜力,可将线性对数级别提升为线性级别。
简单的想法是将数组分为三部分,分别小于、等于和大于切分元素的数组元素。
(1)Dijkstra的解法如下边代码所示:
int lt = lo, i= lo + 1, gt = hi; Comparable v = a[lo]; while (i <= gt) { int cmp = a[i].compareTo(v); if (cmp < 0) exch(a, lt++, i++); else if (cmp > 0) exch(a, i, gt--); else i++; }
sort(a, lo, lt - 1);
sort(a, gt + 1, hi);
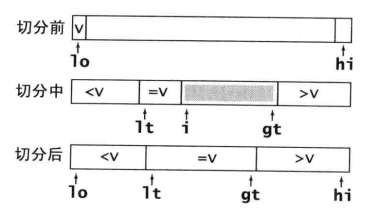
算法从左到右扫描子数组,维护指针lt,i,gt,使a[lo..lt-1]<v,a[gt+1,hi]>v,a[lt..i-1] = v,a[i..gt]是还未扫描的部分。
初始化lt=lo, gt = hi, i = lo + 1
当a[i]<v,交换a[i]和a[lt],然后lt和i都增1;
当a[i]>v,交换a[i]和a[gt],然后gt减1;
当a[i]=v,i加1。
但是,这个改进并没有流行起来,因为当数组元素重复不多时,三切分比标准二切分多使用了很多次交换。
(2)J. Bentley 和 D. Mcilroy找到了一个更好的方法克服了这个问题:
int i = lo, j = hi+1; int p = lo, q = hi+1; Comparable v = a[lo]; while (true) { while (less(a[++i], v)) if (i == hi) break; while (less(v, a[--j])) if (j == lo) break; // pointers cross if (i == j && eq(a[i], v)) exch(a, ++p, i); if (i >= j) break; exch(a, i, j); if (eq(a[i], v)) exch(a, ++p, i); if (eq(a[j], v)) exch(a, --q, j); } i = j + 1; for (int k = lo; k <= p; k++) exch(a, k, j--); for (int k = hi; k >= q; k--) exch(a, k, i++);
sort(a, lo, j);
sort(a, i, hi);
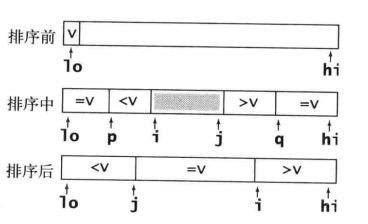
这个方法,维护指针lo,p,i,j使得a[lo..p-1] = v,a[q+1,hi] = v,a[p..i-1] < v,a[j+1..q] > v。
最后将数组两边等于v的元素,搬移到中间。
这个方法和上个方法是等价的,只是这个方法的额外交换用于和切分元素相等的元素,而上个方法将额外交换用于和切分元素不相等的元素。
(3)性能分析:

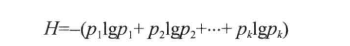
由命题N,可知当排序有大量重复元素数组时,三向切分快速排序将排序时间从线性对数级降为线性级别。
结合命题M和命题N,可知三向切分快速排序算法是熵最优(entropy-optimal)的。
