
温习DL之一:梯度的概念
1.梯度的概念
梯度是一个矢量,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快。
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。比如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T,简称grad f(x,y)或者▽f(x,y)。
问 1)梯度的公式是什么?
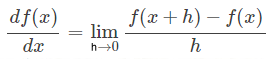
(要记得是极限的形式)
问 2)曲线有斜率吗?
没有,曲线上的点的切线才有斜率。曲线有梯度。
2.梯度下降的概念

问:为什么 反方向更新?
参数的更新公式为
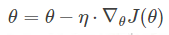
当梯度(导数)为负数的时候(下降),θ增加,即往曲线的下方移动
当梯度为正,θ减小后并以新的θ为基点重新求导,一直迭代
在不断迭代的过程中,梯度值会不断变小,所以θ的变化速度也会越来越慢,所以在这里其实并不需要使学习率的值随着时间越来越小
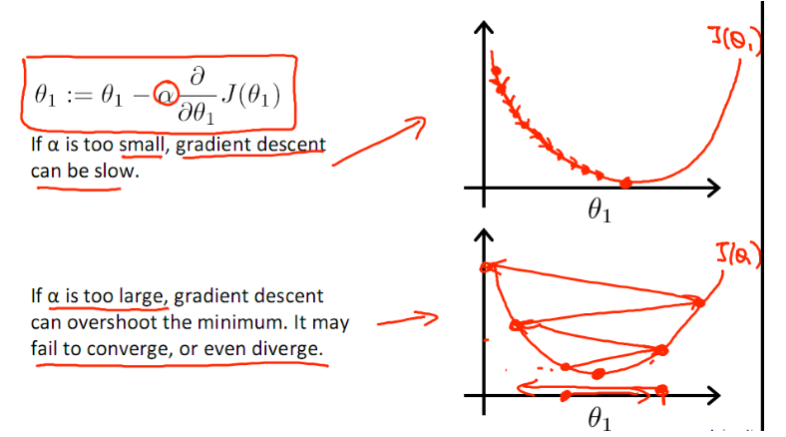
值得注意的是步长的大小,太小,则会迭代很多次才找到最优解,若太大,可能跳过最优,从而找不到最优解。这个时候,学习率衰减就起到至关重要的作用了
Python 示例:
@ Standford CS231n [Optimization Note](http://cs231n.github.io/optimization-1/)
/**
* 以下代码以基础梯度公式为例
*/
def eval_numerical_gradient(f, x):
"""
一个f在x处的数值梯度法的简单实现
- f是只有一个参数的函数
- x是计算梯度的点
"""
fx = f(x) # 在原点计算函数值
grad = np.zeros(x.shape)
h = 0.00001
# 对x中所有的索引进行迭代
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# 计算x+h处的函数值
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # 增加h
fxh = f(x) # 计算f(x + h)
x[ix] = old_value # 存到前一个值中 (非常重要)
# 计算偏导数
grad[ix] = (fxh - fx) / h # 坡度
it.iternext() # 到下个维度
return grad
该代码中h根据微分原理取值应该越小越好,建议值为1e−5左右。而且中心差值梯度效果也肯定比基础梯度效果好,但是相应的计算量也会增大。
3.梯度下降的数学描述
参考:
http://www.cnblogs.com/pinard/p/5970503.html
4.随机梯度下降
假如我们要优化一个函数 f(x),即找到它的最小值,常用的方法叫做 Gradient Descent (GD)。说起来很简单, 就是每次沿着当前位置的导数方向走一小步
GD 算法至少有两个明显的缺陷。
首先,在使用的时候, GD需要计算f(x)的精确导数,往往意味着我们要花几个小时把整个数据集都扫描一遍,然后还只能走一小步,一般 GD 要很长时间才能收敛。
其次,如果我们不小心陷入了鞍点,或者比较差的局部最优点,GD 算法就跑不出来了,因为这些点的导数是 0。什么是鞍点:鞍点是函数上的导数为零但不是轴上局部极值的点
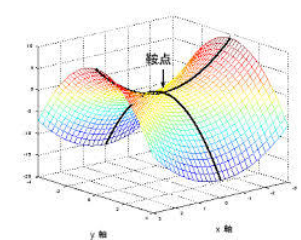
于是Stochastic Gradient Descent (SGD) 算法被提出,解决GD的缺陷。
虽然SGD的下降方向包含一定的随机性,但是从期望上来看,它是等于正确的导数的。
由于它对导数的要求非常低,可以包含大量的噪声,只要期望正确就行,所以导数算起来非常快
除了算得快,SGD 有非常多的优良性质。它能够自动逃离鞍点,自动逃离比较差的局部最优点,而且,最后找到的答案还具有很强的一般性(generalization),即能够在自己之前没有见过但是服从同样分布的数据集上表现非常好
问:什么是鞍点?
首先,我们考虑的情况是导数为0的点。这些点被称为 Stationary points,即稳定点。稳定点的话,可以是(局部)最小值,(局部)最大值,也可以是鞍点。如何判断呢?我们可以计算它的 Hessian 矩阵 H。
- 如果 H 是负定的,说明所有的特征值都是负的。这时,无论往什么方向走,导数都会变负,也就是说函数值会下降。所以,这是(局部)最大值。
- 如果 H 是正定的,说明所有的特征值都是正的。这时,你无论往什么方向走,导数都会变正,也就是说函数值会上升。所以,这是(局部)最小值。
- 如果H既包含正的特征值,又包含负的特征值,那么这个稳定点就是一个鞍点。具体参照之前的图片。也就是说有些方向函数值会上升,有些方向函数值会下降。
- 虽然看起来上面已经包含了所有的情况,但是其实不是的!还有一个非常重要的情况就是 H 可能包含特征值为0的情况。这种情况下面,我们无法判断稳定点到底属于哪一类,往往需要参照更高维的导数才行。想想看,如果特征值是0,就说明有些方向一马平川一望无际,函数值一直不变,那我们当然不知道是怎么回事了:)
上面第四种,是被称为退化了的情况,这里只关注前几种非退化情况。
在这种非退化的情况下面,我们考虑一个重要的类别,即 strict saddle 函数。这种函数有这样的特点:对于每个点 x
- 要么 x 的导数比较大
- 要么 x 的 Hessian 矩阵包含一个负的特征值
- 要么 x 已经离某一个(局部)最小值很近了
为什么我们要 x 满足这三个情况的至少一个呢?因为
- 如果 x 的导数大,那么沿着这个导数一定可以大大降低函数值(我们对函数有光滑性假设)
- 如果 x 的 Hessian 矩阵有一个负的特征值,那么我们通过加噪声随机扰动,跑跑就能够跑到这个方向上,沿着这个方向就能够像滑滑梯一样一路滑下去,大大降低函数值
- 如果 x 已经离某一个(局部)最小值很近了,那么我们就完成任务了,毕竟这个世界上没有十全十美的事情,离得近和精确跑到这个点也没什么区别。
所以说,如果我们考虑的函数满足这个 strict saddle 性质,那么 SGD 算法其实是不会被困在鞍点的.那么 strict saddle 性质是不是一个合理的性质呢?
实际上,有大量的机器学习的问题使用的函数都满足这样的性质。比如 Orthogonal tensor decomposition,dictionary learning, matrix completion 等等。而且,其实并不用担心最后得到的点只是一个局部最优,而不是全局最优。因为实际上人们发现大量的机器学习问题,几乎所有的局部最优是几乎一样好的,也就是说,只要找到一个局部最优点,其实就已经找到了全局最优,比如 Orthogonal tensor decomposition 就满足这样的性质,还有小马哥 NIPS16 的 best student paper 证明了 matrix completion 也满足这样的性质。我觉得神经网络从某些角度来看,也是(几乎)满足的,只是不知道怎么证。
下面讨论一下证明,主要讨论一下第二篇。第一篇论文其实就是用数学的语言在说"在鞍点加扰动,能够顺着负的特征值方向滑下去"。第二篇非常有意思,我觉得值得介绍一下想法。
首先,算法上有了一些改动。算法不再是 SGD,而是跑若干步 GD,然后跑一步 SGD。当然实际上大家是不会这么用的,但是理论分析么,这么考虑没问题。什么时候跑 SGD 呢?只有当导数比较小,而且已经很长时间没有跑过 SGD 的时候,才会跑一次。也就是说,只有确实陷在鞍点上了,才会随机扰动一下下。
因为鞍点有负的特征值,所以只要扰动之后在这个方向上有那么一点点分量,就能够一马平川地滑下去。除非分量非常非常小的情况下才可能会继续陷在鞍点附近。换句话说,如果加了一个随机扰动,其实大概率情况下是能够逃离鞍点的!
虽然这个想法也很直观,但是要严格地证明很不容易,因为具体函数可能是很复杂的,Hessian 矩阵也在不断地变化,所以要说明"扰动之后会陷在鞍点附近的概率是小概率"这件事情并不容易。
作者们采取了一个很巧妙的方法:对于负特征值的那个方向,任何两个点在这两个方向上的投影的距离只要大于 u/2,那么它们中间至少有一个点能够通过多跑几步 GD 逃离鞍点。也就是说,会持续陷在鞍点附近的点所在的区间至多只有 u 那么宽!通过计算宽度,我们也就可以计算出概率的上届,说明大概率下这个 SGD+GD 算法能够逃离鞍点了。
5.随机梯度下降的数学描述
参考:https://www.cnblogs.com/ooon/p/5485231.html
这里贴上著名的几个动图,以示几种梯度下降法的性能差异。


(搬运自水印)
参考:
https://blog.csdn.net/u010248552/article/details/79764340
https://www.cnblogs.com/ooon/p/4947688.html
https://blog.csdn.net/u013709270/article/details/78667531

