

网站日志统计案例分析与实现
1.概要
到这一步,若是按照前面到文章一步走来,不出意外,我想hadoop平台环境应该搭建OK了。下面我以自己工作中实际的案例来梳理一下整个流程。同时参考一些其他的文章来分析,由于很多网站的日志KPI都大同小异,故有些指标直接在文中赘述了。
2.流程
- 背景
- 前言
- 目录
- 日志分析概述
- 需求分析
- 源码
2.1 背景
从2011年开始,中国进入大数据时代如火如荼,以Hadoop为代表的套件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,纷纷向Hadoop靠拢。Hadoop也从小规模的试点和使用,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过大数据概念的不断创新,推进了Hadoop的发展速度。
如今,Hadoop2.x的出现,使很多企业纷纷主动去接受Hadoop这个平台,因此,作为IT界的开发人员,了解并掌握Hadoop的技能,成为开发人员必备的一项技能。也是今后主流的一种趋势。
注:Hadoop2.x的出现为何引起这么大大反响,这里不做赘述。
2.2 前言
Web日志包含着网站最重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值等。一般中型的网站(10w的PV以上),每天会产生1G以上的Web日志文件。大型或超大型的网站,可能每小时就产生10G的数据量。
对于日志的这种规模的数据,用Hadoop进行日志分析,是最合适不过了。
2.3 目录
- Web日志分析概述
- 需求分析:KPI指标设计
- 算法模型:Hadoop并行算法
- 架构设计:日志KPI系统架构
- 项目构建:Maven构建Hadoop项目
2.4 Web日志分析概述
Web日志由Web服务器产生,可能是Nginx,Apache,Tomcat等。从Web日志中,我们可以获取网站每类页面的PV值、独立IP数;稍微复杂一些的,可以计算得出用户所检索的关键词排行榜、用户停留时间最高的页面等;更复杂的,构建广告点击模型、分析用户行为特征等等。
Web日志中,每条日志通常代表着用户的一次访问行为,例如下面就是一条Nginx日志:
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
我们可以从中获取8个指标:
-
Remote_Addr:记录客户端的IP地址,222.68.172.190
-
Remote_User:记录客户端用户名称,-
-
Time_Local:记录访问时间与时区:[18/Sep/2013:06:49:57 +0000]
-
Request:记录请求的URL和HTTP协议,"GET /images/my.jpg HTTP/1.1"
-
Status:记录请求状态,成功是200,200
-
Body_Bytes_Sent:记录发送给客户端文件主体内容大小,19939
-
Http_Referer:用来记录从哪个页面链接访问过来的,http://www.angularjs.cn/A00n
-
Http_User_Agent:记录客户端浏览器的相关信息,"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
注:要更多的信息,则需要其它手段去获取,通过javascript代码单独发送请求,使用cookies记录用户访问信息。利用这些日志信息,我们可以深入挖掘网站的秘密了。
少量数据的情况:
少量数据的情况(10M,100M,1G),在单机处理尚能接受的时候,我们可以直接利用各种Unix/Linux工具,awk、grep、sort、join等都是日志分析的利器,再配合perl,python,正则表达式,基本就可以解决所有的问题。 例如,我们想从上面提到的Nginx日志中得到访问量最高前10个IP,实现很简单:
~ cat access.log.10 | awk '{a[$1]++} END {for(b in a) print b"\t"a[b]}' | sort -k2 -r | head -n 10
结果如果下:
163.177.71.12 972 101.226.68.137 972 183.195.232.138 971 50.116.27.194 97 14.17.29.86 96 61.135.216.104 94 61.135.216.105 91 61.186.190.41 9 59.39.192.108 9 220.181.51.212 9
数据海量的情况:
当数据量每天以10G、100G增长的时候,单机处理能力已经不能满足需求。我们就需要增加系统的复杂性,用计算机集群,存储阵列来解决。在Hadoop出现之前,海量数据存储和海量日志分析都是很困难的,只有少数公司,掌握着高效的并行计算,分布式计算,分布式存储的核心技术。 Hadoop的出现,大幅度的降低了海量数据处理的门槛,让小公司甚至是个人都能够处理海量数据。并且,Hadoop非常适用于日志分析系统。
2.5 KPI指标设计
下面我们将从一个公司案例出发来全面的诠释,如何进行海量Web日志分析,提前KPI数据。
2.5.1 案例介绍
某电商网站,在线团购业务。每日PV数100w,独立IP数5w;用户通常在工作日上午10:00-12:00和下午15:00-18:00访问量最大;日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问最多。网站搜索流量占整个网站的80%,PC用户不足1%的用户会消费,移动用户有5%会消费。
通过简短的描述,我们可以粗略的看出这家电商网站的经营状况,并认识到愿意消费的用户是从哪里来,有哪些潜在的用户可以挖掘,网站是否存在倒闭风险等。
2.5.2 KPI指标设计
- PV:页面访问量统计
- IP:页面独立IP访问量统计
- Time:用户每小时PV统计
- Source:用户来源域名的统计
- Browser:用户的访问设备统计
注:很遗憾,由于商业原因,无法提供电商网站的日志。这里我取的是某论坛的日志分析,原理都是一样的,指标也类似。
2.6 项目构建
这里Hadoop的项目,我们采用Maven结构来构建项目,这样能够保证整个项目的清爽,对依赖包能够统一的进行管理,在项目的打包和发布上也是大有裨益。
注:如何创建Maven项目这里不做赘述,可以自行查找相应的资料。
3.实现
指标我们已经分析的很明确了,下面我们来考虑如何实现这些指标,以及实现这些指标需要用到那些技术,下面我画了一个实现的流程图:
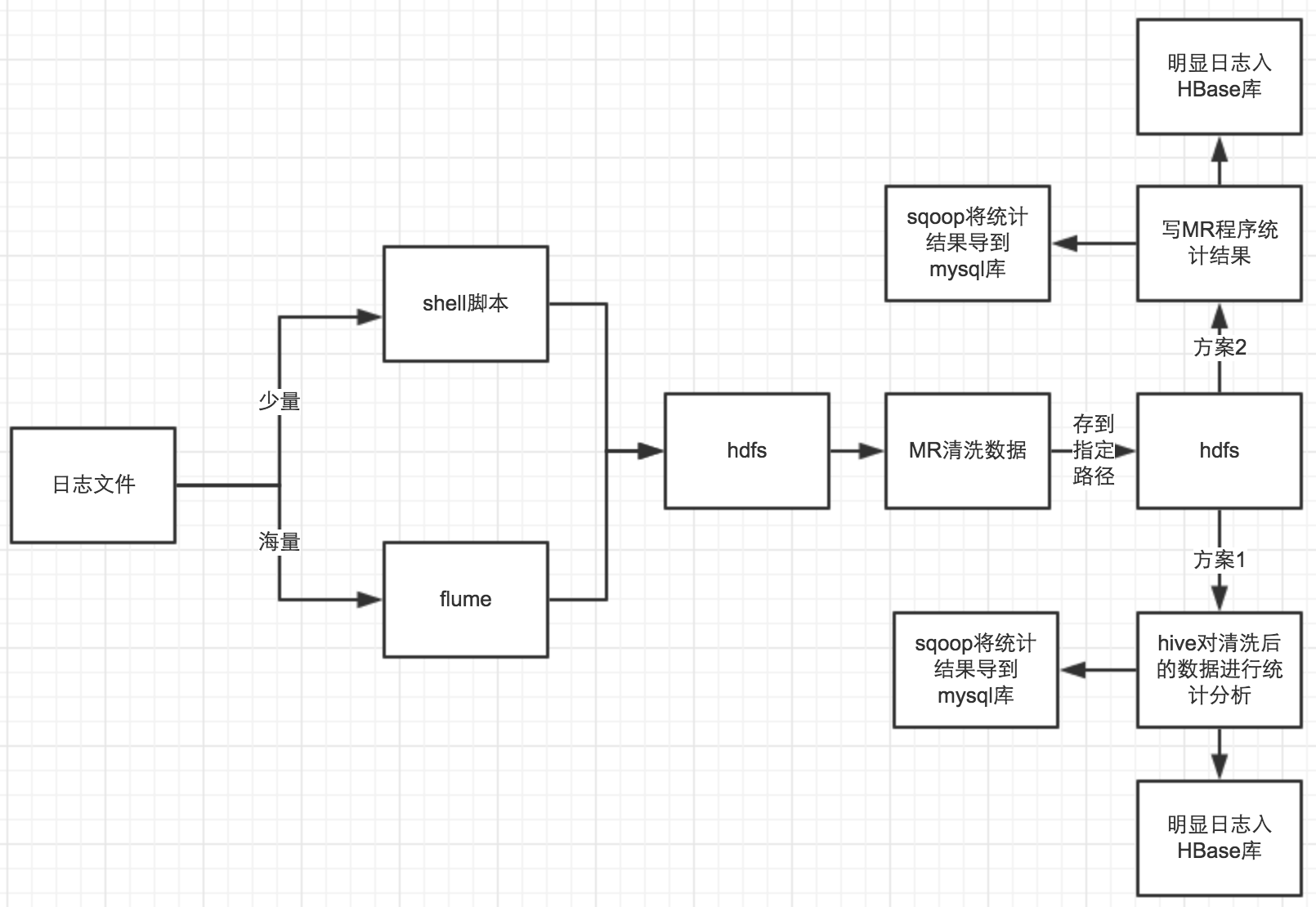
由于是在Retina屏下截取的,所以分辨率会有点高,若网络有故障,估计图会展示不了,因而,下面我也用文字描述一下整个流程。
首先我们需要获取这些日志文件,获取的方式有多种,这里我们只列出了比较工作中使用的2种方式,少量的日志可以直接使用脚本上传到HDFS,海量日志可以使用Flume进行上传到HDFS,然后我们将上传在HDFS到日志进行清洗(按指标清洗,去掉一些异常数据),将清洗后到数据重定向到新的HDFS目录中,接下来我们可以按指标来进行统计结果,统计的方式,这里我也列出了工作中使用的2种方式,一种是编写MR任务进行统计,另一种是使用hive来统计,最后将统计的结果使用sqoop导出到mysql或是oracle中保存(明晰存储在HBase中)。到这里整理工作就算是结束,至于如何使用统计出来的数据,这里不是我们所考虑的范围。
4.源码
关于源代码,目前有些部分代码要从源代码中分离出来,到时候我会把这个日志分析系统项目的代码放在Github上,整理完后链接到时候会放在这片博文的下面。另外有什么问题可以加群咨询,或发邮件给我,我会尽我所能给予帮助。与君共勉!
邮箱:smartloli.org@gmail.com
QQ群(Hive与AI实战【新群】):935396818
QQ群(Hadoop - 交流社区1):424769183
QQ群(Kafka并不难学):825943084
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!

