

AOP探索笔记
C#应用AOP说明
NFramework 轻量级ORM框架
AOP介绍
什么是AOP
AOP是aspect-oriented programming的简写。AOP的研究逐渐成为热门,有关AOP的描述,在CSDN文章中也有人做了比较周详的描述,也有一些对描述的争论。《aspectj in action》的描述我认为最为经典,理由是:该书是aspectj研发者的手笔,而aspectj目前也是最成熟AOP的工具之一。
对方法调用的拦截,有人把他作为对AOP的解释,同大多数人相同,我不这样认为。AOP的主要作用是解决对象之间的横向关系,一种正交的错综复杂的关系。传统的OOP不能非常好的或说是非常容易的解决这个问题。这就是AOP有机会得以发扬光大的原因之一。那么AOP是怎么解决这个问题呢?编织(weave),把对象间的相关行为按照特定的规则编织到一起。而前面提到的拦截仅仅是为完成编织而采用的手段。拦截不是目的,编织才是。反过来说,编织不仅仅是拦截,他包括了多种知识和技术。这种编织的过程既能是静态的也能是动态的,就像OOP中的先期绑定和后期绑定。
AOP在c#中的研究比java中的研究要落后好几年。能达到应用级的几乎没有(至少java更有一个aspectj,当前版本为1.2)。或许是我孤陋寡闻,网络上能找到的比较知名的恐怕只有loom和aspect#了,说他们还属于试验室的成果一点也不为过。那么是否就是说AOP在c#的实现非常难呢?回答:是,也不是。java和c#的语言特征如此相像(他们有一起的祖先c++)。没有理由说java能实现,而c#不行。那么问题在哪里呢?这是c#的AOP的研究,大多数人坚持的一点是不能修改已有的c#语言规范,只能对c#语言进行扩展。同时产生的程式集(assembly)必须能够被clr调用和执行。另外还要考虑程式的性能。如果ms没有在c#乃至.net中对AOP内建的支持(如目前所做的泛型的扩展),那么难度一定是存在的。
幸运的是,ms并没有完全忽略AOP,在.net的框架类库的设计中,我们能隐隐约约的找到AOP的设计思想(虽然这是ms类库实现者为解决特定的问题而采用的方法)。这也为我们在c#中实现AOP提供了设计思路。
AOP的功能及实现
关于AOP 在c#中的实现原理说不大清楚,因为MS没有将.Net Framework 开源,虽然传言.Net Framework即将开源。虽然如此,AOP的魅力仍然无法抵挡,例如,在一个复杂而且庞大的系统中,有些模块如日志模块,安全验证模块,它们从功能上来说是独立的模块,而在运用时却会穿插到系统其他的所有模块中。在传统的OOP编程中我们无法避免的在众多地方存在这样的代码:
 Log LogEntity = new Log();
Log LogEntity = new Log();2
LogEntity.Text = ”…”;3
LogEntity.Write();4
这样做的结果是无可避免的耦合,当我们对Log类进行了改动,就只能在整个系统的代码中去找这些代码了,多么可怕的工作量!AOP是怎么解决这个问题的?下面给出转载的一个例子,它同时也告诉我们如何实现AOP。
由于篇幅较长,在这里我给出两个链接:
http://www.c-sharpcorner.com/UploadFile/raviraj.bhalerao/aop12062005022058AM/aop.aspx
http://www.cnblogs.com/sleeper520/archive/2008/11/04/1326457.html
NFramework介绍
已经基本了结了AOP的功能及实现,再来看看使用AOP复杂一点的例子,加深对AOP的认识。
NFramework是一个轻量级ORM框架,据作者moneystar的描述,它是一个较之IBatis.NET和NHibernate更为优秀的ORM层框架。以下是作者对NFramework的介绍:
NHibernate目前可谓如日中天,许多人都在谈论它,并且也得到了广泛的应用,但在我的项目经历中,即使应用NHibernate这样的好工具也有痛苦的时候,大量的xml文件让我们眼花缭乱,简单易学的HQL语言却又常常不能满足我们的要求。特别是随着系统的复杂性越来越高,再加上人员的流动,最终xml堆积如山,若干事件以后不再有人记得那个xml文件是用来做什么的了。NHibernate本身对SQL的封装做的很好,但或许这也成为了我们的束缚,对于非常复杂的业务问题,我们的调试变得更困难,要在代码与数个xml文件之间不停的查阅以期快速定位问题的所在,这增加了我们的调试难度。
IBatis.NET
IBatis.NET考虑到了这种情况,因此它将SQL释放出来,让我们可以一目了然。但同样也存在xml数据量过多的情况。随着系统的不断升级,我们不得不考虑膨胀的xml文件对内存的占用问题。当然,IBatis.NET可以快速的溶入到现有的项目中,在不改变既有方案的前提下为我们提供一种新的思路来解决实际的问题,这是一个不错的优点。但纵观NHibernate也好、IBatis.NET也好,其应用代码中都有一些严重的重复问题,比如说OpenSession、CloseSession、GetFactory类似这样的代码,这对只关注业务的开发人员来说也是一个不小的工作量。
NFramework
NFramework在设计ORM时,充分考虑了目前流行了ORM框架,如NHibernate、IBatis.NET这两个流行的产品。当然NFramework也不可能没有缺点,但它为开发人员考虑的更多。首先从部署的角度来讲,NFramework没有采用xml文件作为ORM的映射描述,而是采用了扩展元数据的方式,这在很大程度上减轻了维护xml文件的负担,在部署时也只是一个简单的DLL文件。
NFramework中的实体(Entity)本身没有包括任何CRUD相关的方法,因此可以说是一个“轻量级的实体”,你不必担心由于大量的对实体对象的new操作导致系统占用资源过多而性能有所下降。NFramework中的实体只包括映射的元数据与对象属性,因此它是轻量级的,在我们的实际测试中,在用户大量的并发操作时,创建新实体对象占用的资源微乎其微。在做到轻量级的同时,NFramework并没有以降低映射的灵活性和效率性为前提,通过自定义的元数据,不但可以映射出数据表、视图、字段、字段类型、字段长度的映射关系,还可以轻松映射出多表之间的关联信息。下面我们来比较一下NFramework与以NHibernate为代表的ORM框架之间的不同。
|
比较项目 |
NFramework |
NHibernate |
|
速度 |
直接使用DLL做为载体,因此速度较快(当然,这里使用了反射,速度主要取决于反射的速度)。 |
视配置文件的大小,另外有文件的IO操作,另外大量的xml文件,对内存也提出了比较大的要求。 |
|
易用性 |
简单,和操作正常的类一样。 |
相对复杂,需要对了解每一个xml文件配置节属性,有一定的学习难度。 |
|
可维护性 |
简单,可以直接用代码跟踪调试。 |
相对复杂,每个XML文件都需仔细校验,无法在编译期间检查错误。 |
|
可部署性 |
方便部署,只需复制实体的DLL,如果实体有变化在编译期就可发现错误 |
相对麻烦,每个XML文件都要被部署到服务器,对于遗漏的文件将产生运行时错误,无法被早期发现,并且设置xml文件的路径都是比较繁琐的事情。 |
|
映射效率性 |
晚期绑定,因此对于数据表字段的类型、大小等更改不影响代码,映射效率高。 |
早期绑定,对于数据表的更改要将所有相关的XML配置文件也重新修改,对于配置文件较多的情况无疑会产生巨大的工作量 |
|
灵活性 |
由于实体要被编译成DLL的形式,因此灵活性相对较差 |
非常灵活,这归功于XML文件的灵活性 |
NFramework源码:
探索NFramework中的AOP
下面我们按流程分解NFramework中的AOP
NFramework中AOP技术实现数据库事务级操作.
TransactionAopProperty
public bool IsAopTransaction: 是否使用Aop提供的事务.
public IsolationLevelEnum IsoLationLevel: 标识事务级别.
private IDBUtil m_dbUtil = null;: 数据访问接口.
方法GetDBUtil(): 用当前级别实例化数据访问接口,并开启事务.
 public IDBUtil GetDBUtil()
public IDBUtil GetDBUtil()2
 {
{
3
 ITransaction trans = Factory.GetTransaction();
ITransaction trans = Factory.GetTransaction();4
trans.BeginTransaction(m_level);5
m_dbUtil = trans as IDBUtil;6
// 返回实例7
return m_dbUtil;8
 }
}9
方法Commit()和Rollback()用于提交和回滚事务.
 拦截后的具体操作.
拦截后的具体操作.
19
AopAspect
SyncProcessMessage(IMessage msg): 当标记有AopProperty的方法调用时,AopProperty拦截方法调用的消息, 生成新的消息池, 新的消息池调用SyncProcessMessage(IMessage msg)方法来进行消息调用前的操作.
public IMessage SyncProcessMessage(IMessage msg)2
{ 3
IMethodCallMessage call = msg as IMethodCallMessage;4
string methodName = call.MethodName;5
// 调用开始之前处理6
ProcessBeforeMessage(call);7
IBeforeAdvice before = FindBeforeAdvice(methodName);8
if (before != null)9
 {
{10
before.BeforeAdvice(call);11
 }
} 12
IMessage retMsg = m_nextSink.SyncProcessMessage(msg);13
IMethodReturnMessage returnMsg = retMsg as IMethodReturnMessage;14
// 调用结束之后处理15
ProcessAfterMessage(returnMsg);16
IAfterAdvice after = FindAfterAdvice(methodName);17
if (after != null)18
{19
after.AfterAdvice(returnMsg);20
}21
return retMsg;22
}23
SyncProcessMessage(IMessage msg)工作流程如下:
1. 在消息池接收到消息msg并且调用SyncProcessMessage时, 它调用了ProcessBeforeMessage(call)
其中call即为msg. IMessage派生出Construction messages, Method call message,和Response message.
ProcessBeforeMessage(call)
protected override void ProcessBeforeMessage(IMethodCallMessage call)2
{3
if (Attribute.GetCustomAttribute(call.MethodBase, typeof(TransactionAttribute)) != null)4
{5
AddBeforeAdvice(call.MethodName, new TransactionAopAdvice());6
}7
}8
它检查当前被调用的方法是否被标记有TransactionAttribute属性,如果有,将该方法与TransactionAopAdvice的键值对添加到AopAspect的m_beforeAdvice.
2. 从m_beforeAdvice中找到该方法名所对应的Advice.并调用它的BeforeAdvice(call)方法.
为什么要用m_beforeAdvice作为BeforeAdvice的容器? 由以上代码可以知道, 如果一个方法没有被TransactionAttribute标记, 那么它不会被添加到m_beforeAdvice, 反过来,如果方法被标记了,肯定会执行BeforeAdvice(). 那么这样做的公用只有在调用者的生存期中,反复调用该方法是节省了生成消耗?也许我考虑的不够周全.
BeforeAdvice(call)
if (callMsg == null)2
{3
return;4
}5
// 设置事务处理级别6
TransactionAopProperty transAop = Thread.CurrentContext.GetProperty(TransactionAopProperty.TRANSACTION_AOP_NAME) as TransactionAopProperty;7
if (transAop != null)8
{9
TransactionAttribute attr = (TransactionAttribute)Attribute.GetCustomAttribute(callMsg.MethodBase, typeof(TransactionAttribute));10
transAop.IsAopTransaction = true;11
transAop.IsoLationLevel = attr.IsoLationLevel;12
}13
BeforeAdvice反过来获取了TransactionAopProperty对象, 并赋值IsAopTransaction和IsolationLevel属性.
3. 传递给下一个消息池,直到方法被调用. 疑问: 方法执行的时候会使用到IDBUtil, 但是这个IDBUtil对象和 TransactionAopProperty中的IDBUtil 又有什么关系呢?
4. 方法处理完以后, 同样调用ProcessAfterMessage() 然后触发AfterMessage ()
AfterMessage ()
if (returnMsg == null)2
{3
return;4
}5
// 递交或回滚事务处理6
TransactionAopProperty transAop = Thread.CurrentContext.GetProperty(TransactionAopProperty.TRANSACTION_AOP_NAME) as TransactionAopProperty;7
if (transAop != null && transAop.IsAopTransaction == true)8
{9
if (returnMsg.Exception == null)10
{11
transAop.Commit();12
}13
else14
{15
transAop.Rollback();16
}17
}18
AfterMessage () 的任务是让transactionAopProperty 在 Commit()和RollBack()中调用一个. 即是决定transactionAopProperty中的IDBUtil 提交 或 回滚 .
流程结束, 回顾TransactionAopProperty, IDBUtil的定义及实现说明 Aop 引用了IDBUtil, Itransaction等接口. 也就是说如果要使用Aop来实现事务级数据库访问, 就要使Access类中的成员IDBUtil 与 TransactionAopProperty中的 IDBUtil 合二为一. 那么我们可以这样理解:直接使用IDBUtil的Access是数据访问层的非事务模式,而通过AOP 使用IDBUtil的Access是使用事务模式的数据访问层。

非事务模式的数据访问层
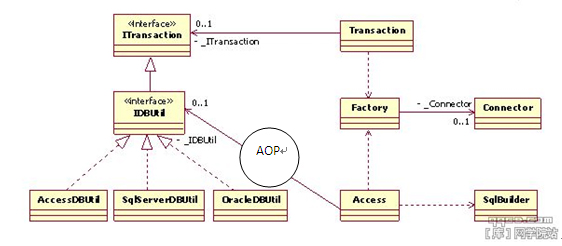
事务模式的数据访问层
现在,剩下的问题就是怎么合二为一?即怎么将TransactionAopProperty中的IDBUtil映射给Access?
protected IDBUtil DB2
{3
get 4
{5
if (m_dbUtil == null)6
{7
// 判断是否使用了Aop提供的事务8
TransactionAopProperty transAop = Thread.CurrentContext.GetProperty(TransactionAopProperty.TRANSACTION_AOP_NAME) as TransactionAopProperty;9
if (transAop != null && transAop.IsAopTransaction == true)10
{11
// 使用Aop提供的自动事务控制12
m_dbUtil = transAop.GetDBUtil();13
transAop.IsAopTransaction = true;14
}15
else16
{17
// 如果m_dbUtil为null,并且没有标记Aop事务,则不使用事务进行数据访问18
m_dbUtil = Factory.GetDBUtil();19
}20
}21
return m_dbUtil;22
}23
}24
非常聪明的方法,解决了引用的难题。注意判断条件中的transAop.IsAopTransaction == true,
还记得在什么时候IsAopTransaction被赋值为true了吗?这样做吧事务的范围锁定在方法级。
本文仅作交流,欢迎大家提出观点及意见。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!