


概要
本章是JUC系列的ConcurrentHashMap篇。内容包括:
ConcurrentHashMap介绍
ConcurrentHashMap原理和数据结构
ConcurrentHashMap函数列表
ConcurrentHashMap源码分析(JDK1.7.0_40版本)
ConcurrentHashMap示例
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3498537.html
ConcurrentHashMap介绍
ConcurrentHashMap是线程安全的哈希表。HashMap, Hashtable, ConcurrentHashMap之间的关联如下:
HashMap是非线程安全的哈希表,常用于单线程程序中。
Hashtable是线程安全的哈希表,它是通过synchronized来保证线程安全的;即,多线程通过同一个“对象的同步锁”来实现并发控制。Hashtable在线程竞争激烈时,效率比较低(此时建议使用ConcurrentHashMap)!因为当一个线程访问Hashtable的同步方法时,其它线程就访问Hashtable的同步方法时,可能会进入阻塞状态。
ConcurrentHashMap是线程安全的哈希表,它是通过“锁分段”来保证线程安全的。ConcurrentHashMap将哈希表分成许多片段(Segment),每一个片段除了保存哈希表之外,本质上也是一个“可重入的互斥锁”(ReentrantLock)。多线程对同一个片段的访问,是互斥的;但是,对于不同片段的访问,却是可以同步进行的。
关于HashMap,Hashtable以及ReentrantLock的更多内容,可以参考:
1. Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
2. Java 集合系列11之 Hashtable详细介绍(源码解析)和使用示例
3. Java多线程系列--“JUC锁”02之 互斥锁ReentrantLock
ConcurrentHashMap原理和数据结构
要想搞清ConcurrentHashMap,必须先弄清楚它的数据结构:
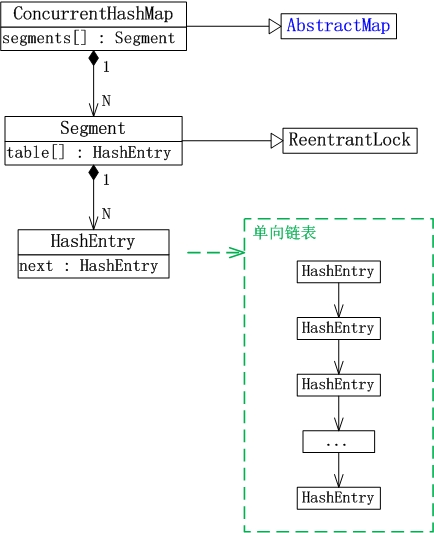
(01) ConcurrentHashMap继承于AbstractMap抽象类。
(02) Segment是ConcurrentHashMap中的内部类,它就是ConcurrentHashMap中的“锁分段”对应的存储结构。ConcurrentHashMap与Segment是组合关系,1个ConcurrentHashMap对象包含若干个Segment对象。在代码中,这表现为ConcurrentHashMap类中存在“Segment数组”成员。
(03) Segment类继承于ReentrantLock类,所以Segment本质上是一个可重入的互斥锁。
(04) HashEntry也是ConcurrentHashMap的内部类,是单向链表节点,存储着key-value键值对。Segment与HashEntry是组合关系,Segment类中存在“HashEntry数组”成员,“HashEntry数组”中的每个HashEntry就是一个单向链表。
对于多线程访问对一个“哈希表对象”竞争资源,Hashtable是通过一把锁来控制并发;而ConcurrentHashMap则是将哈希表分成许多片段,对于每一个片段分别通过一个互斥锁来控制并发。ConcurrentHashMap对并发的控制更加细腻,它也更加适应于高并发场景!
ConcurrentHashMap函数列表

// 创建一个带有默认初始容量 (16)、加载因子 (0.75) 和 concurrencyLevel (16) 的新的空映射。 ConcurrentHashMap() // 创建一个带有指定初始容量、默认加载因子 (0.75) 和 concurrencyLevel (16) 的新的空映射。 ConcurrentHashMap(int initialCapacity) // 创建一个带有指定初始容量、加载因子和默认 concurrencyLevel (16) 的新的空映射。 ConcurrentHashMap(int initialCapacity, float loadFactor) // 创建一个带有指定初始容量、加载因子和并发级别的新的空映射。 ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) // 构造一个与给定映射具有相同映射关系的新映射。 ConcurrentHashMap(Map<? extends K,? extends V> m) // 从该映射中移除所有映射关系 void clear() // 一种遗留方法,测试此表中是否有一些与指定值存在映射关系的键。 boolean contains(Object value) // 测试指定对象是否为此表中的键。 boolean containsKey(Object key) // 如果此映射将一个或多个键映射到指定值,则返回 true。 boolean containsValue(Object value) // 返回此表中值的枚举。 Enumeration<V> elements() // 返回此映射所包含的映射关系的 Set 视图。 Set<Map.Entry<K,V>> entrySet() // 返回指定键所映射到的值,如果此映射不包含该键的映射关系,则返回 null。 V get(Object key) // 如果此映射不包含键-值映射关系,则返回 true。 boolean isEmpty() // 返回此表中键的枚举。 Enumeration<K> keys() // 返回此映射中包含的键的 Set 视图。 Set<K> keySet() // 将指定键映射到此表中的指定值。 V put(K key, V value) // 将指定映射中所有映射关系复制到此映射中。 void putAll(Map<? extends K,? extends V> m) // 如果指定键已经不再与某个值相关联,则将它与给定值关联。 V putIfAbsent(K key, V value) // 从此映射中移除键(及其相应的值)。 V remove(Object key) // 只有目前将键的条目映射到给定值时,才移除该键的条目。 boolean remove(Object key, Object value) // 只有目前将键的条目映射到某一值时,才替换该键的条目。 V replace(K key, V value) // 只有目前将键的条目映射到给定值时,才替换该键的条目。 boolean replace(K key, V oldValue, V newValue) // 返回此映射中的键-值映射关系数。 int size() // 返回此映射中包含的值的 Collection 视图。 Collection<V> values()
ConcurrentHashMap源码分析(JDK1.7.0_40版本)
ConcurrentHashMap.java的完整源码如下:


1 /* 2 * ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms. 3 * 4 * 5 * 6 * 7 * 8 * 9 * 10 * 11 * 12 * 13 * 14 * 15 * 16 * 17 * 18 * 19 * 20 * 21 * 22 * 23 */ 24 25 /* 26 * 27 * 28 * 29 * 30 * 31 * Written by Doug Lea with assistance from members of JCP JSR-166 32 * Expert Group and released to the public domain, as explained at 33 * http://creativecommons.org/publicdomain/zero/1.0/ 34 */ 35 36 package java.util.concurrent; 37 import java.util.concurrent.locks.*; 38 import java.util.*; 39 import java.io.Serializable; 40 import java.io.IOException; 41 import java.io.ObjectInputStream; 42 import java.io.ObjectOutputStream; 43 import java.io.ObjectStreamField; 44 45 /** 46 * A hash table supporting full concurrency of retrievals and 47 * adjustable expected concurrency for updates. This class obeys the 48 * same functional specification as {@link java.util.Hashtable}, and 49 * includes versions of methods corresponding to each method of 50 * <tt>Hashtable</tt>. However, even though all operations are 51 * thread-safe, retrieval operations do <em>not</em> entail locking, 52 * and there is <em>not</em> any support for locking the entire table 53 * in a way that prevents all access. This class is fully 54 * interoperable with <tt>Hashtable</tt> in programs that rely on its 55 * thread safety but not on its synchronization details. 56 * 57 * <p> Retrieval operations (including <tt>get</tt>) generally do not 58 * block, so may overlap with update operations (including 59 * <tt>put</tt> and <tt>remove</tt>). Retrievals reflect the results 60 * of the most recently <em>completed</em> update operations holding 61 * upon their onset. For aggregate operations such as <tt>putAll</tt> 62 * and <tt>clear</tt>, concurrent retrievals may reflect insertion or 63 * removal of only some entries. Similarly, Iterators and 64 * Enumerations return elements reflecting the state of the hash table 65 * at some point at or since the creation of the iterator/enumeration. 66 * They do <em>not</em> throw {@link ConcurrentModificationException}. 67 * However, iterators are designed to be used by only one thread at a time. 68 * 69 * <p> The allowed concurrency among update operations is guided by 70 * the optional <tt>concurrencyLevel</tt> constructor argument 71 * (default <tt>16</tt>), which is used as a hint for internal sizing. The 72 * table is internally partitioned to try to permit the indicated 73 * number of concurrent updates without contention. Because placement 74 * in hash tables is essentially random, the actual concurrency will 75 * vary. Ideally, you should choose a value to accommodate as many 76 * threads as will ever concurrently modify the table. Using a 77 * significantly higher value than you need can waste space and time, 78 * and a significantly lower value can lead to thread contention. But 79 * overestimates and underestimates within an order of magnitude do 80 * not usually have much noticeable impact. A value of one is 81 * appropriate when it is known that only one thread will modify and 82 * all others will only read. Also, resizing this or any other kind of 83 * hash table is a relatively slow operation, so, when possible, it is 84 * a good idea to provide estimates of expected table sizes in 85 * constructors. 86 * 87 * <p>This class and its views and iterators implement all of the 88 * <em>optional</em> methods of the {@link Map} and {@link Iterator} 89 * interfaces. 90 * 91 * <p> Like {@link Hashtable} but unlike {@link HashMap}, this class 92 * does <em>not</em> allow <tt>null</tt> to be used as a key or value. 93 * 94 * <p>This class is a member of the 95 * <a href="{@docRoot}/../technotes/guides/collections/index.html"> 96 * Java Collections Framework</a>. 97 * 98 * @since 1.5 99 * @author Doug Lea 100 * @param <K> the type of keys maintained by this map 101 * @param <V> the type of mapped values 102 */ 103 public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> 104 implements ConcurrentMap<K, V>, Serializable { 105 private static final long serialVersionUID = 7249069246763182397L; 106 107 /* 108 * The basic strategy is to subdivide the table among Segments, 109 * each of which itself is a concurrently readable hash table. To 110 * reduce footprint, all but one segments are constructed only 111 * when first needed (see ensureSegment). To maintain visibility 112 * in the presence of lazy construction, accesses to segments as 113 * well as elements of segment's table must use volatile access, 114 * which is done via Unsafe within methods segmentAt etc 115 * below. These provide the functionality of AtomicReferenceArrays 116 * but reduce the levels of indirection. Additionally, 117 * volatile-writes of table elements and entry "next" fields 118 * within locked operations use the cheaper "lazySet" forms of 119 * writes (via putOrderedObject) because these writes are always 120 * followed by lock releases that maintain sequential consistency 121 * of table updates. 122 * 123 * Historical note: The previous version of this class relied 124 * heavily on "final" fields, which avoided some volatile reads at 125 * the expense of a large initial footprint. Some remnants of 126 * that design (including forced construction of segment 0) exist 127 * to ensure serialization compatibility. 128 */ 129 130 /* ---------------- Constants -------------- */ 131 132 /** 133 * The default initial capacity for this table, 134 * used when not otherwise specified in a constructor. 135 */ 136 static final int DEFAULT_INITIAL_CAPACITY = 16; 137 138 /** 139 * The default load factor for this table, used when not 140 * otherwise specified in a constructor. 141 */ 142 static final float DEFAULT_LOAD_FACTOR = 0.75f; 143 144 /** 145 * The default concurrency level for this table, used when not 146 * otherwise specified in a constructor. 147 */ 148 static final int DEFAULT_CONCURRENCY_LEVEL = 16; 149 150 /** 151 * The maximum capacity, used if a higher value is implicitly 152 * specified by either of the constructors with arguments. MUST 153 * be a power of two <= 1<<30 to ensure that entries are indexable 154 * using ints. 155 */ 156 static final int MAXIMUM_CAPACITY = 1 << 30; 157 158 /** 159 * The minimum capacity for per-segment tables. Must be a power 160 * of two, at least two to avoid immediate resizing on next use 161 * after lazy construction. 162 */ 163 static final int MIN_SEGMENT_TABLE_CAPACITY = 2; 164 165 /** 166 * The maximum number of segments to allow; used to bound 167 * constructor arguments. Must be power of two less than 1 << 24. 168 */ 169 static final int MAX_SEGMENTS = 1 << 16; // slightly conservative 170 171 /** 172 * Number of unsynchronized retries in size and containsValue 173 * methods before resorting to locking. This is used to avoid 174 * unbounded retries if tables undergo continuous modification 175 * which would make it impossible to obtain an accurate result. 176 */ 177 static final int RETRIES_BEFORE_LOCK = 2; 178 179 /* ---------------- Fields -------------- */ 180 181 /** 182 * holds values which can't be initialized until after VM is booted. 183 */ 184 private static class Holder { 185 186 /** 187 * Enable alternative hashing of String keys? 188 * 189 * <p>Unlike the other hash map implementations we do not implement a 190 * threshold for regulating whether alternative hashing is used for 191 * String keys. Alternative hashing is either enabled for all instances 192 * or disabled for all instances. 193 */ 194 static final boolean ALTERNATIVE_HASHING; 195 196 static { 197 // Use the "threshold" system property even though our threshold 198 // behaviour is "ON" or "OFF". 199 String altThreshold = java.security.AccessController.doPrivileged( 200 new sun.security.action.GetPropertyAction( 201 "jdk.map.althashing.threshold")); 202 203 int threshold; 204 try { 205 threshold = (null != altThreshold) 206 ? Integer.parseInt(altThreshold) 207 : Integer.MAX_VALUE; 208 209 // disable alternative hashing if -1 210 if (threshold == -1) { 211 threshold = Integer.MAX_VALUE; 212 } 213 214 if (threshold < 0) { 215 throw new IllegalArgumentException("value must be positive integer."); 216 } 217 } catch(IllegalArgumentException failed) { 218 throw new Error("Illegal value for 'jdk.map.althashing.threshold'", failed); 219 } 220 ALTERNATIVE_HASHING = threshold <= MAXIMUM_CAPACITY; 221 } 222 } 223 224 /** 225 * A randomizing value associated with this instance that is applied to 226 * hash code of keys to make hash collisions harder to find. 227 */ 228 private transient final int hashSeed = randomHashSeed(this); 229 230 private static int randomHashSeed(ConcurrentHashMap instance) { 231 if (sun.misc.VM.isBooted() && Holder.ALTERNATIVE_HASHING) { 232 return sun.misc.Hashing.randomHashSeed(instance); 233 } 234 235 return 0; 236 } 237 238 /** 239 * Mask value for indexing into segments. The upper bits of a 240 * key's hash code are used to choose the segment. 241 */ 242 final int segmentMask; 243 244 /** 245 * Shift value for indexing within segments. 246 */ 247 final int segmentShift; 248 249 /** 250 * The segments, each of which is a specialized hash table. 251 */ 252 final Segment<K,V>[] segments; 253 254 transient Set<K> keySet; 255 transient Set<Map.Entry<K,V>> entrySet; 256 transient Collection<V> values; 257 258 /** 259 * ConcurrentHashMap list entry. Note that this is never exported 260 * out as a user-visible Map.Entry. 261 */ 262 static final class HashEntry<K,V> { 263 final int hash; 264 final K key; 265 volatile V value; 266 volatile HashEntry<K,V> next; 267 268 HashEntry(int hash, K key, V value, HashEntry<K,V> next) { 269 this.hash = hash; 270 this.key = key; 271 this.value = value; 272 this.next = next; 273 } 274 275 /** 276 * Sets next field with volatile write semantics. (See above 277 * about use of putOrderedObject.) 278 */ 279 final void setNext(HashEntry<K,V> n) { 280 UNSAFE.putOrderedObject(this, nextOffset, n); 281 } 282 283 // Unsafe mechanics 284 static final sun.misc.Unsafe UNSAFE; 285 static final long nextOffset; 286 static { 287 try { 288 UNSAFE = sun.misc.Unsafe.getUnsafe(); 289 Class k = HashEntry.class; 290 nextOffset = UNSAFE.objectFieldOffset 291 (k.getDeclaredField("next")); 292 } catch (Exception e) { 293 throw new Error(e); 294 } 295 } 296 } 297 298 /** 299 * Gets the ith element of given table (if nonnull) with volatile 300 * read semantics. Note: This is manually integrated into a few 301 * performance-sensitive methods to reduce call overhead. 302 */ 303 @SuppressWarnings("unchecked") 304 static final <K,V> HashEntry<K,V> entryAt(HashEntry<K,V>[] tab, int i) { 305 return (tab == null) ? null : 306 (HashEntry<K,V>) UNSAFE.getObjectVolatile 307 (tab, ((long)i << TSHIFT) + TBASE); 308 } 309 310 /** 311 * Sets the ith element of given table, with volatile write 312 * semantics. (See above about use of putOrderedObject.) 313 */ 314 static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i, 315 HashEntry<K,V> e) { 316 UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e); 317 } 318 319 /** 320 * Applies a supplemental hash function to a given hashCode, which 321 * defends against poor quality hash functions. This is critical 322 * because ConcurrentHashMap uses power-of-two length hash tables, 323 * that otherwise encounter collisions for hashCodes that do not 324 * differ in lower or upper bits. 325 */ 326 private int hash(Object k) { 327 int h = hashSeed; 328 329 if ((0 != h) && (k instanceof String)) { 330 return sun.misc.Hashing.stringHash32((String) k); 331 } 332 333 h ^= k.hashCode(); 334 335 // Spread bits to regularize both segment and index locations, 336 // using variant of single-word Wang/Jenkins hash. 337 h += (h << 15) ^ 0xffffcd7d; 338 h ^= (h >>> 10); 339 h += (h << 3); 340 h ^= (h >>> 6); 341 h += (h << 2) + (h << 14); 342 return h ^ (h >>> 16); 343 } 344 345 /** 346 * Segments are specialized versions of hash tables. This 347 * subclasses from ReentrantLock opportunistically, just to 348 * simplify some locking and avoid separate construction. 349 */ 350 static final class Segment<K,V> extends ReentrantLock implements Serializable { 351 /* 352 * Segments maintain a table of entry lists that are always 353 * kept in a consistent state, so can be read (via volatile 354 * reads of segments and tables) without locking. This 355 * requires replicating nodes when necessary during table 356 * resizing, so the old lists can be traversed by readers 357 * still using old version of table. 358 * 359 * This class defines only mutative methods requiring locking. 360 * Except as noted, the methods of this class perform the 361 * per-segment versions of ConcurrentHashMap methods. (Other 362 * methods are integrated directly into ConcurrentHashMap 363 * methods.) These mutative methods use a form of controlled 364 * spinning on contention via methods scanAndLock and 365 * scanAndLockForPut. These intersperse tryLocks with 366 * traversals to locate nodes. The main benefit is to absorb 367 * cache misses (which are very common for hash tables) while 368 * obtaining locks so that traversal is faster once 369 * acquired. We do not actually use the found nodes since they 370 * must be re-acquired under lock anyway to ensure sequential 371 * consistency of updates (and in any case may be undetectably 372 * stale), but they will normally be much faster to re-locate. 373 * Also, scanAndLockForPut speculatively creates a fresh node 374 * to use in put if no node is found. 375 */ 376 377 private static final long serialVersionUID = 2249069246763182397L; 378 379 /** 380 * The maximum number of times to tryLock in a prescan before 381 * possibly blocking on acquire in preparation for a locked 382 * segment operation. On multiprocessors, using a bounded 383 * number of retries maintains cache acquired while locating 384 * nodes. 385 */ 386 static final int MAX_SCAN_RETRIES = 387 Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1; 388 389 /** 390 * The per-segment table. Elements are accessed via 391 * entryAt/setEntryAt providing volatile semantics. 392 */ 393 transient volatile HashEntry<K,V>[] table; 394 395 /** 396 * The number of elements. Accessed only either within locks 397 * or among other volatile reads that maintain visibility. 398 */ 399 transient int count; 400 401 /** 402 * The total number of mutative operations in this segment. 403 * Even though this may overflows 32 bits, it provides 404 * sufficient accuracy for stability checks in CHM isEmpty() 405 * and size() methods. Accessed only either within locks or 406 * among other volatile reads that maintain visibility. 407 */ 408 transient int modCount; 409 410 /** 411 * The table is rehashed when its size exceeds this threshold. 412 * (The value of this field is always <tt>(int)(capacity * 413 * loadFactor)</tt>.) 414 */ 415 transient int threshold; 416 417 /** 418 * The load factor for the hash table. Even though this value 419 * is same for all segments, it is replicated to avoid needing 420 * links to outer object. 421 * @serial 422 */ 423 final float loadFactor; 424 425 Segment(float lf, int threshold, HashEntry<K,V>[] tab) { 426 this.loadFactor = lf; 427 this.threshold = threshold; 428 this.table = tab; 429 } 430 431 final V put(K key, int hash, V value, boolean onlyIfAbsent) { 432 HashEntry<K,V> node = tryLock() ? null : 433 scanAndLockForPut(key, hash, value); 434 V oldValue; 435 try { 436 HashEntry<K,V>[] tab = table; 437 int index = (tab.length - 1) & hash; 438 HashEntry<K,V> first = entryAt(tab, index); 439 for (HashEntry<K,V> e = first;;) { 440 if (e != null) { 441 K k; 442 if ((k = e.key) == key || 443 (e.hash == hash && key.equals(k))) { 444 oldValue = e.value; 445 if (!onlyIfAbsent) { 446 e.value = value; 447 ++modCount; 448 } 449 break; 450 } 451 e = e.next; 452 } 453 else { 454 if (node != null) 455 node.setNext(first); 456 else 457 node = new HashEntry<K,V>(hash, key, value, first); 458 int c = count + 1; 459 if (c > threshold && tab.length < MAXIMUM_CAPACITY) 460 rehash(node); 461 else 462 setEntryAt(tab, index, node); 463 ++modCount; 464 count = c; 465 oldValue = null; 466 break; 467 } 468 } 469 } finally { 470 unlock(); 471 } 472 return oldValue; 473 } 474 475 /** 476 * Doubles size of table and repacks entries, also adding the 477 * given node to new table 478 */ 479 @SuppressWarnings("unchecked") 480 private void rehash(HashEntry<K,V> node) { 481 /* 482 * Reclassify nodes in each list to new table. Because we 483 * are using power-of-two expansion, the elements from 484 * each bin must either stay at same index, or move with a 485 * power of two offset. We eliminate unnecessary node 486 * creation by catching cases where old nodes can be 487 * reused because their next fields won't change. 488 * Statistically, at the default threshold, only about 489 * one-sixth of them need cloning when a table 490 * doubles. The nodes they replace will be garbage 491 * collectable as soon as they are no longer referenced by 492 * any reader thread that may be in the midst of 493 * concurrently traversing table. Entry accesses use plain 494 * array indexing because they are followed by volatile 495 * table write. 496 */ 497 HashEntry<K,V>[] oldTable = table; 498 int oldCapacity = oldTable.length; 499 int newCapacity = oldCapacity << 1; 500 threshold = (int)(newCapacity * loadFactor); 501 HashEntry<K,V>[] newTable = 502 (HashEntry<K,V>[]) new HashEntry[newCapacity]; 503 int sizeMask = newCapacity - 1; 504 for (int i = 0; i < oldCapacity ; i++) { 505 HashEntry<K,V> e = oldTable[i]; 506 if (e != null) { 507 HashEntry<K,V> next = e.next; 508 int idx = e.hash & sizeMask; 509 if (next == null) // Single node on list 510 newTable[idx] = e; 511 else { // Reuse consecutive sequence at same slot 512 HashEntry<K,V> lastRun = e; 513 int lastIdx = idx; 514 for (HashEntry<K,V> last = next; 515 last != null; 516 last = last.next) { 517 int k = last.hash & sizeMask; 518 if (k != lastIdx) { 519 lastIdx = k; 520 lastRun = last; 521 } 522 } 523 newTable[lastIdx] = lastRun; 524 // Clone remaining nodes 525 for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { 526 V v = p.value; 527 int h = p.hash; 528 int k = h & sizeMask; 529 HashEntry<K,V> n = newTable[k]; 530 newTable[k] = new HashEntry<K,V>(h, p.key, v, n); 531 } 532 } 533 } 534 } 535 int nodeIndex = node.hash & sizeMask; // add the new node 536 node.setNext(newTable[nodeIndex]); 537 newTable[nodeIndex] = node; 538 table = newTable; 539 } 540 541 /** 542 * Scans for a node containing given key while trying to 543 * acquire lock, creating and returning one if not found. Upon 544 * return, guarantees that lock is held. UNlike in most 545 * methods, calls to method equals are not screened: Since 546 * traversal speed doesn't matter, we might as well help warm 547 * up the associated code and accesses as well. 548 * 549 * @return a new node if key not found, else null 550 */ 551 private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { 552 HashEntry<K,V> first = entryForHash(this, hash); 553 HashEntry<K,V> e = first; 554 HashEntry<K,V> node = null; 555 int retries = -1; // negative while locating node 556 while (!tryLock()) { 557 HashEntry<K,V> f; // to recheck first below 558 if (retries < 0) { 559 if (e == null) { 560 if (node == null) // speculatively create node 561 node = new HashEntry<K,V>(hash, key, value, null); 562 retries = 0; 563 } 564 else if (key.equals(e.key)) 565 retries = 0; 566 else 567 e = e.next; 568 } 569 else if (++retries > MAX_SCAN_RETRIES) { 570 lock(); 571 break; 572 } 573 else if ((retries & 1) == 0 && 574 (f = entryForHash(this, hash)) != first) { 575 e = first = f; // re-traverse if entry changed 576 retries = -1; 577 } 578 } 579 return node; 580 } 581 582 /** 583 * Scans for a node containing the given key while trying to 584 * acquire lock for a remove or replace operation. Upon 585 * return, guarantees that lock is held. Note that we must 586 * lock even if the key is not found, to ensure sequential 587 * consistency of updates. 588 */ 589 private void scanAndLock(Object key, int hash) { 590 // similar to but simpler than scanAndLockForPut 591 HashEntry<K,V> first = entryForHash(this, hash); 592 HashEntry<K,V> e = first; 593 int retries = -1; 594 while (!tryLock()) { 595 HashEntry<K,V> f; 596 if (retries < 0) { 597 if (e == null || key.equals(e.key)) 598 retries = 0; 599 else 600 e = e.next; 601 } 602 else if (++retries > MAX_SCAN_RETRIES) { 603 lock(); 604 break; 605 } 606 else if ((retries & 1) == 0 && 607 (f = entryForHash(this, hash)) != first) { 608 e = first = f; 609 retries = -1; 610 } 611 } 612 } 613 614 /** 615 * Remove; match on key only if value null, else match both. 616 */ 617 final V remove(Object key, int hash, Object value) { 618 if (!tryLock()) 619 scanAndLock(key, hash); 620 V oldValue = null; 621 try { 622 HashEntry<K,V>[] tab = table; 623 int index = (tab.length - 1) & hash; 624 HashEntry<K,V> e = entryAt(tab, index); 625 HashEntry<K,V> pred = null; 626 while (e != null) { 627 K k; 628 HashEntry<K,V> next = e.next; 629 if ((k = e.key) == key || 630 (e.hash == hash && key.equals(k))) { 631 V v = e.value; 632 if (value == null || value == v || value.equals(v)) { 633 if (pred == null) 634 setEntryAt(tab, index, next); 635 else 636 pred.setNext(next); 637 ++modCount; 638 --count; 639 oldValue = v; 640 } 641 break; 642 } 643 pred = e; 644 e = next; 645 } 646 } finally { 647 unlock(); 648 } 649 return oldValue; 650 } 651 652 final boolean replace(K key, int hash, V oldValue, V newValue) { 653 if (!tryLock()) 654 scanAndLock(key, hash); 655 boolean replaced = false; 656 try { 657 HashEntry<K,V> e; 658 for (e = entryForHash(this, hash); e != null; e = e.next) { 659 K k; 660 if ((k = e.key) == key || 661 (e.hash == hash && key.equals(k))) { 662 if (oldValue.equals(e.value)) { 663 e.value = newValue; 664 ++modCount; 665 replaced = true; 666 } 667 break; 668 } 669 } 670 } finally { 671 unlock(); 672 } 673 return replaced; 674 } 675 676 final V replace(K key, int hash, V value) { 677 if (!tryLock()) 678 scanAndLock(key, hash); 679 V oldValue = null; 680 try { 681 HashEntry<K,V> e; 682 for (e = entryForHash(this, hash); e != null; e = e.next) { 683 K k; 684 if ((k = e.key) == key || 685 (e.hash == hash && key.equals(k))) { 686 oldValue = e.value; 687 e.value = value; 688 ++modCount; 689 break; 690 } 691 } 692 } finally { 693 unlock(); 694 } 695 return oldValue; 696 } 697 698 final void clear() { 699 lock(); 700 try { 701 HashEntry<K,V>[] tab = table; 702 for (int i = 0; i < tab.length ; i++) 703 setEntryAt(tab, i, null); 704 ++modCount; 705 count = 0; 706 } finally { 707 unlock(); 708 } 709 } 710 } 711 712 // Accessing segments 713 714 /** 715 * Gets the jth element of given segment array (if nonnull) with 716 * volatile element access semantics via Unsafe. (The null check 717 * can trigger harmlessly only during deserialization.) Note: 718 * because each element of segments array is set only once (using 719 * fully ordered writes), some performance-sensitive methods rely 720 * on this method only as a recheck upon null reads. 721 */ 722 @SuppressWarnings("unchecked") 723 static final <K,V> Segment<K,V> segmentAt(Segment<K,V>[] ss, int j) { 724 long u = (j << SSHIFT) + SBASE; 725 return ss == null ? null : 726 (Segment<K,V>) UNSAFE.getObjectVolatile(ss, u); 727 } 728 729 /** 730 * Returns the segment for the given index, creating it and 731 * recording in segment table (via CAS) if not already present. 732 * 733 * @param k the index 734 * @return the segment 735 */ 736 @SuppressWarnings("unchecked") 737 private Segment<K,V> ensureSegment(int k) { 738 final Segment<K,V>[] ss = this.segments; 739 long u = (k << SSHIFT) + SBASE; // raw offset 740 Segment<K,V> seg; 741 if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { 742 Segment<K,V> proto = ss[0]; // use segment 0 as prototype 743 int cap = proto.table.length; 744 float lf = proto.loadFactor; 745 int threshold = (int)(cap * lf); 746 HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap]; 747 if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) 748 == null) { // recheck 749 Segment<K,V> s = new Segment<K,V>(lf, threshold, tab); 750 while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) 751 == null) { 752 if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s)) 753 break; 754 } 755 } 756 } 757 return seg; 758 } 759 760 // Hash-based segment and entry accesses 761 762 /** 763 * Get the segment for the given hash 764 */ 765 @SuppressWarnings("unchecked") 766 private Segment<K,V> segmentForHash(int h) { 767 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; 768 return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u); 769 } 770 771 /** 772 * Gets the table entry for the given segment and hash 773 */ 774 @SuppressWarnings("unchecked") 775 static final <K,V> HashEntry<K,V> entryForHash(Segment<K,V> seg, int h) { 776 HashEntry<K,V>[] tab; 777 return (seg == null || (tab = seg.table) == null) ? null : 778 (HashEntry<K,V>) UNSAFE.getObjectVolatile 779 (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); 780 } 781 782 /* ---------------- Public operations -------------- */ 783 784 /** 785 * Creates a new, empty map with the specified initial 786 * capacity, load factor and concurrency level. 787 * 788 * @param initialCapacity the initial capacity. The implementation 789 * performs internal sizing to accommodate this many elements. 790 * @param loadFactor the load factor threshold, used to control resizing. 791 * Resizing may be performed when the average number of elements per 792 * bin exceeds this threshold. 793 * @param concurrencyLevel the estimated number of concurrently 794 * updating threads. The implementation performs internal sizing 795 * to try to accommodate this many threads. 796 * @throws IllegalArgumentException if the initial capacity is 797 * negative or the load factor or concurrencyLevel are 798 * nonpositive. 799 */ 800 @SuppressWarnings("unchecked") 801 public ConcurrentHashMap(int initialCapacity, 802 float loadFactor, int concurrencyLevel) { 803 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) 804 throw new IllegalArgumentException(); 805 if (concurrencyLevel > MAX_SEGMENTS) 806 concurrencyLevel = MAX_SEGMENTS; 807 // Find power-of-two sizes best matching arguments 808 int sshift = 0; 809 int ssize = 1; 810 while (ssize < concurrencyLevel) { 811 ++sshift; 812 ssize <<= 1; 813 } 814 this.segmentShift = 32 - sshift; 815 this.segmentMask = ssize - 1; 816 if (initialCapacity > MAXIMUM_CAPACITY) 817 initialCapacity = MAXIMUM_CAPACITY; 818 int c = initialCapacity / ssize; 819 if (c * ssize < initialCapacity) 820 ++c; 821 int cap = MIN_SEGMENT_TABLE_CAPACITY; 822 while (cap < c) 823 cap <<= 1; 824 // create segments and segments[0] 825 Segment<K,V> s0 = 826 new Segment<K,V>(loadFactor, (int)(cap * loadFactor), 827 (HashEntry<K,V>[])new HashEntry[cap]); 828 Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; 829 UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0] 830 this.segments = ss; 831 } 832 833 /** 834 * Creates a new, empty map with the specified initial capacity 835 * and load factor and with the default concurrencyLevel (16). 836 * 837 * @param initialCapacity The implementation performs internal 838 * sizing to accommodate this many elements. 839 * @param loadFactor the load factor threshold, used to control resizing. 840 * Resizing may be performed when the average number of elements per 841 * bin exceeds this threshold. 842 * @throws IllegalArgumentException if the initial capacity of 843 * elements is negative or the load factor is nonpositive 844 * 845 * @since 1.6 846 */ 847 public ConcurrentHashMap(int initialCapacity, float loadFactor) { 848 this(initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL); 849 } 850 851 /** 852 * Creates a new, empty map with the specified initial capacity, 853 * and with default load factor (0.75) and concurrencyLevel (16). 854 * 855 * @param initialCapacity the initial capacity. The implementation 856 * performs internal sizing to accommodate this many elements. 857 * @throws IllegalArgumentException if the initial capacity of 858 * elements is negative. 859 */ 860 public ConcurrentHashMap(int initialCapacity) { 861 this(initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); 862 } 863 864 /** 865 * Creates a new, empty map with a default initial capacity (16), 866 * load factor (0.75) and concurrencyLevel (16). 867 */ 868 public ConcurrentHashMap() { 869 this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); 870 } 871 872 /** 873 * Creates a new map with the same mappings as the given map. 874 * The map is created with a capacity of 1.5 times the number 875 * of mappings in the given map or 16 (whichever is greater), 876 * and a default load factor (0.75) and concurrencyLevel (16). 877 * 878 * @param m the map 879 */ 880 public ConcurrentHashMap(Map<? extends K, ? extends V> m) { 881 this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1, 882 DEFAULT_INITIAL_CAPACITY), 883 DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); 884 putAll(m); 885 } 886 887 /** 888 * Returns <tt>true</tt> if this map contains no key-value mappings. 889 * 890 * @return <tt>true</tt> if this map contains no key-value mappings 891 */ 892 public boolean isEmpty() { 893 /* 894 * Sum per-segment modCounts to avoid mis-reporting when 895 * elements are concurrently added and removed in one segment 896 * while checking another, in which case the table was never 897 * actually empty at any point. (The sum ensures accuracy up 898 * through at least 1<<31 per-segment modifications before 899 * recheck.) Methods size() and containsValue() use similar 900 * constructions for stability checks. 901 */ 902 long sum = 0L; 903 final Segment<K,V>[] segments = this.segments; 904 for (int j = 0; j < segments.length; ++j) { 905 Segment<K,V> seg = segmentAt(segments, j); 906 if (seg != null) { 907 if (seg.count != 0) 908 return false; 909 sum += seg.modCount; 910 } 911 } 912 if (sum != 0L) { // recheck unless no modifications 913 for (int j = 0; j < segments.length; ++j) { 914 Segment<K,V> seg = segmentAt(segments, j); 915 if (seg != null) { 916 if (seg.count != 0) 917 return false; 918 sum -= seg.modCount; 919 } 920 } 921 if (sum != 0L) 922 return false; 923 } 924 return true; 925 } 926 927 /** 928 * Returns the number of key-value mappings in this map. If the 929 * map contains more than <tt>Integer.MAX_VALUE</tt> elements, returns 930 * <tt>Integer.MAX_VALUE</tt>. 931 * 932 * @return the number of key-value mappings in this map 933 */ 934 public int size() { 935 // Try a few times to get accurate count. On failure due to 936 // continuous async changes in table, resort to locking. 937 final Segment<K,V>[] segments = this.segments; 938 int size; 939 boolean overflow; // true if size overflows 32 bits 940 long sum; // sum of modCounts 941 long last = 0L; // previous sum 942 int retries = -1; // first iteration isn't retry 943 try { 944 for (;;) { 945 if (retries++ == RETRIES_BEFORE_LOCK) { 946 for (int j = 0; j < segments.length; ++j) 947 ensureSegment(j).lock(); // force creation 948 } 949 sum = 0L; 950 size = 0; 951 overflow = false; 952 for (int j = 0; j < segments.length; ++j) { 953 Segment<K,V> seg = segmentAt(segments, j); 954 if (seg != null) { 955 sum += seg.modCount; 956 int c = seg.count; 957 if (c < 0 || (size += c) < 0) 958 overflow = true; 959 } 960 } 961 if (sum == last) 962 break; 963 last = sum; 964 } 965 } finally { 966 if (retries > RETRIES_BEFORE_LOCK) { 967 for (int j = 0; j < segments.length; ++j) 968 segmentAt(segments, j).unlock(); 969 } 970 } 971 return overflow ? Integer.MAX_VALUE : size; 972 } 973 974 /** 975 * Returns the value to which the specified key is mapped, 976 * or {@code null} if this map contains no mapping for the key. 977 * 978 * <p>More formally, if this map contains a mapping from a key 979 * {@code k} to a value {@code v} such that {@code key.equals(k)}, 980 * then this method returns {@code v}; otherwise it returns 981 * {@code null}. (There can be at most one such mapping.) 982 * 983 * @throws NullPointerException if the specified key is null 984 */ 985 public V get(Object key) { 986 Segment<K,V> s; // manually integrate access methods to reduce overhead 987 HashEntry<K,V>[] tab; 988 int h = hash(key); 989 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; 990 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && 991 (tab = s.table) != null) { 992 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile 993 (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); 994 e != null; e = e.next) { 995 K k; 996 if ((k = e.key) == key || (e.hash == h && key.equals(k))) 997 return e.value; 998 } 999 } 1000 return null; 1001 } 1002 1003 /** 1004 * Tests if the specified object is a key in this table. 1005 * 1006 * @param key possible key 1007 * @return <tt>true</tt> if and only if the specified object 1008 * is a key in this table, as determined by the 1009 * <tt>equals</tt> method; <tt>false</tt> otherwise. 1010 * @throws NullPointerException if the specified key is null 1011 */ 1012 @SuppressWarnings("unchecked") 1013 public boolean containsKey(Object key) { 1014 Segment<K,V> s; // same as get() except no need for volatile value read 1015 HashEntry<K,V>[] tab; 1016 int h = hash(key); 1017 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; 1018 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && 1019 (tab = s.table) != null) { 1020 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile 1021 (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); 1022 e != null; e = e.next) { 1023 K k; 1024 if ((k = e.key) == key || (e.hash == h && key.equals(k))) 1025 return true; 1026 } 1027 } 1028 return false; 1029 } 1030 1031 /** 1032 * Returns <tt>true</tt> if this map maps one or more keys to the 1033 * specified value. Note: This method requires a full internal 1034 * traversal of the hash table, and so is much slower than 1035 * method <tt>containsKey</tt>. 1036 * 1037 * @param value value whose presence in this map is to be tested 1038 * @return <tt>true</tt> if this map maps one or more keys to the 1039 * specified value 1040 * @throws NullPointerException if the specified value is null 1041 */ 1042 public boolean containsValue(Object value) { 1043 // Same idea as size() 1044 if (value == null) 1045 throw new NullPointerException(); 1046 final Segment<K,V>[] segments = this.segments; 1047 boolean found = false; 1048 long last = 0; 1049 int retries = -1; 1050 try { 1051 outer: for (;;) { 1052 if (retries++ == RETRIES_BEFORE_LOCK) { 1053 for (int j = 0; j < segments.length; ++j) 1054 ensureSegment(j).lock(); // force creation 1055 } 1056 long hashSum = 0L; 1057 int sum = 0; 1058 for (int j = 0; j < segments.length; ++j) { 1059 HashEntry<K,V>[] tab; 1060 Segment<K,V> seg = segmentAt(segments, j); 1061 if (seg != null && (tab = seg.table) != null) { 1062 for (int i = 0 ; i < tab.length; i++) { 1063 HashEntry<K,V> e; 1064 for (e = entryAt(tab, i); e != null; e = e.next) { 1065 V v = e.value; 1066 if (v != null && value.equals(v)) { 1067 found = true; 1068 break outer; 1069 } 1070 } 1071 } 1072 sum += seg.modCount; 1073 } 1074 } 1075 if (retries > 0 && sum == last) 1076 break; 1077 last = sum; 1078 } 1079 } finally { 1080 if (retries > RETRIES_BEFORE_LOCK) { 1081 for (int j = 0; j < segments.length; ++j) 1082 segmentAt(segments, j).unlock(); 1083 } 1084 } 1085 return found; 1086 } 1087 1088 /** 1089 * Legacy method testing if some key maps into the specified value 1090 * in this table. This method is identical in functionality to 1091 * {@link #containsValue}, and exists solely to ensure 1092 * full compatibility with class {@link java.util.Hashtable}, 1093 * which supported this method prior to introduction of the 1094 * Java Collections framework. 1095 1096 * @param value a value to search for 1097 * @return <tt>true</tt> if and only if some key maps to the 1098 * <tt>value</tt> argument in this table as 1099 * determined by the <tt>equals</tt> method; 1100 * <tt>false</tt> otherwise 1101 * @throws NullPointerException if the specified value is null 1102 */ 1103 public boolean contains(Object value) { 1104 return containsValue(value); 1105 } 1106 1107 /** 1108 * Maps the specified key to the specified value in this table. 1109 * Neither the key nor the value can be null. 1110 * 1111 * <p> The value can be retrieved by calling the <tt>get</tt> method 1112 * with a key that is equal to the original key. 1113 * 1114 * @param key key with which the specified value is to be associated 1115 * @param value value to be associated with the specified key 1116 * @return the previous value associated with <tt>key</tt>, or 1117 * <tt>null</tt> if there was no mapping for <tt>key</tt> 1118 * @throws NullPointerException if the specified key or value is null 1119 */ 1120 @SuppressWarnings("unchecked") 1121 public V put(K key, V value) { 1122 Segment<K,V> s; 1123 if (value == null) 1124 throw new NullPointerException(); 1125 int hash = hash(key); 1126 int j = (hash >>> segmentShift) & segmentMask; 1127 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck 1128 (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment 1129 s = ensureSegment(j); 1130 return s.put(key, hash, value, false); 1131 } 1132 1133 /** 1134 * {@inheritDoc} 1135 * 1136 * @return the previous value associated with the specified key, 1137 * or <tt>null</tt> if there was no mapping for the key 1138 * @throws NullPointerException if the specified key or value is null 1139 */ 1140 @SuppressWarnings("unchecked") 1141 public V putIfAbsent(K key, V value) { 1142 Segment<K,V> s; 1143 if (value == null) 1144 throw new NullPointerException(); 1145 int hash = hash(key); 1146 int j = (hash >>> segmentShift) & segmentMask; 1147 if ((s = (Segment<K,V>)UNSAFE.getObject 1148 (segments, (j << SSHIFT) + SBASE)) == null) 1149 s = ensureSegment(j); 1150 return s.put(key, hash, value, true); 1151 } 1152 1153 /** 1154 * Copies all of the mappings from the specified map to this one. 1155 * These mappings replace any mappings that this map had for any of the 1156 * keys currently in the specified map. 1157 * 1158 * @param m mappings to be stored in this map 1159 */ 1160 public void putAll(Map<? extends K, ? extends V> m) { 1161 for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) 1162 put(e.getKey(), e.getValue()); 1163 } 1164 1165 /** 1166 * Removes the key (and its corresponding value) from this map. 1167 * This method does nothing if the key is not in the map. 1168 * 1169 * @param key the key that needs to be removed 1170 * @return the previous value associated with <tt>key</tt>, or 1171 * <tt>null</tt> if there was no mapping for <tt>key</tt> 1172 * @throws NullPointerException if the specified key is null 1173 */ 1174 public V remove(Object key) { 1175 int hash = hash(key); 1176 Segment<K,V> s = segmentForHash(hash); 1177 return s == null ? null : s.remove(key, hash, null); 1178 } 1179 1180 /** 1181 * {@inheritDoc} 1182 * 1183 * @throws NullPointerException if the specified key is null 1184 */ 1185 public boolean remove(Object key, Object value) { 1186 int hash = hash(key); 1187 Segment<K,V> s; 1188 return value != null && (s = segmentForHash(hash)) != null && 1189 s.remove(key, hash, value) != null; 1190 } 1191 1192 /** 1193 * {@inheritDoc} 1194 * 1195 * @throws NullPointerException if any of the arguments are null 1196 */ 1197 public boolean replace(K key, V oldValue, V newValue) { 1198 int hash = hash(key); 1199 if (oldValue == null || newValue == null) 1200 throw new NullPointerException(); 1201 Segment<K,V> s = segmentForHash(hash); 1202 return s != null && s.replace(key, hash, oldValue, newValue); 1203 } 1204 1205 /** 1206 * {@inheritDoc} 1207 * 1208 * @return the previous value associated with the specified key, 1209 * or <tt>null</tt> if there was no mapping for the key 1210 * @throws NullPointerException if the specified key or value is null 1211 */ 1212 public V replace(K key, V value) { 1213 int hash = hash(key); 1214 if (value == null) 1215 throw new NullPointerException(); 1216 Segment<K,V> s = segmentForHash(hash); 1217 return s == null ? null : s.replace(key, hash, value); 1218 } 1219 1220 /** 1221 * Removes all of the mappings from this map. 1222 */ 1223 public void clear() { 1224 final Segment<K,V>[] segments = this.segments; 1225 for (int j = 0; j < segments.length; ++j) { 1226 Segment<K,V> s = segmentAt(segments, j); 1227 if (s != null) 1228 s.clear(); 1229 } 1230 } 1231 1232 /** 1233 * Returns a {@link Set} view of the keys contained in this map. 1234 * The set is backed by the map, so changes to the map are 1235 * reflected in the set, and vice-versa. The set supports element 1236 * removal, which removes the corresponding mapping from this map, 1237 * via the <tt>Iterator.remove</tt>, <tt>Set.remove</tt>, 1238 * <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt> 1239 * operations. It does not support the <tt>add</tt> or 1240 * <tt>addAll</tt> operations. 1241 * 1242 * <p>The view's <tt>iterator</tt> is a "weakly consistent" iterator 1243 * that will never throw {@link ConcurrentModificationException}, 1244 * and guarantees to traverse elements as they existed upon 1245 * construction of the iterator, and may (but is not guaranteed to) 1246 * reflect any modifications subsequent to construction. 1247 */ 1248 public Set<K> keySet() { 1249 Set<K> ks = keySet; 1250 return (ks != null) ? ks : (keySet = new KeySet()); 1251 } 1252 1253 /** 1254 * Returns a {@link Collection} view of the values contained in this map. 1255 * The collection is backed by the map, so changes to the map are 1256 * reflected in the collection, and vice-versa. The collection 1257 * supports element removal, which removes the corresponding 1258 * mapping from this map, via the <tt>Iterator.remove</tt>, 1259 * <tt>Collection.remove</tt>, <tt>removeAll</tt>, 1260 * <tt>retainAll</tt>, and <tt>clear</tt> operations. It does not 1261 * support the <tt>add</tt> or <tt>addAll</tt> operations. 1262 * 1263 * <p>The view's <tt>iterator</tt> is a "weakly consistent" iterator 1264 * that will never throw {@link ConcurrentModificationException}, 1265 * and guarantees to traverse elements as they existed upon 1266 * construction of the iterator, and may (but is not guaranteed to) 1267 * reflect any modifications subsequent to construction. 1268 */ 1269 public Collection<V> values() { 1270 Collection<V> vs = values; 1271 return (vs != null) ? vs : (values = new Values()); 1272 } 1273 1274 /** 1275 * Returns a {@link Set} view of the mappings contained in this map. 1276 * The set is backed by the map, so changes to the map are 1277 * reflected in the set, and vice-versa. The set supports element 1278 * removal, which removes the corresponding mapping from the map, 1279 * via the <tt>Iterator.remove</tt>, <tt>Set.remove</tt>, 1280 * <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt> 1281 * operations. It does not support the <tt>add</tt> or 1282 * <tt>addAll</tt> operations. 1283 * 1284 * <p>The view's <tt>iterator</tt> is a "weakly consistent" iterator 1285 * that will never throw {@link ConcurrentModificationException}, 1286 * and guarantees to traverse elements as they existed upon 1287 * construction of the iterator, and may (but is not guaranteed to) 1288 * reflect any modifications subsequent to construction. 1289 */ 1290 public Set<Map.Entry<K,V>> entrySet() { 1291 Set<Map.Entry<K,V>> es = entrySet; 1292 return (es != null) ? es : (entrySet = new EntrySet()); 1293 } 1294 1295 /** 1296 * Returns an enumeration of the keys in this table. 1297 * 1298 * @return an enumeration of the keys in this table 1299 * @see #keySet() 1300 */ 1301 public Enumeration<K> keys() { 1302 return new KeyIterator(); 1303 } 1304 1305 /** 1306 * Returns an enumeration of the values in this table. 1307 * 1308 * @return an enumeration of the values in this table 1309 * @see #values() 1310 */ 1311 public Enumeration<V> elements() { 1312 return new ValueIterator(); 1313 } 1314 1315 /* ---------------- Iterator Support -------------- */ 1316 1317 abstract class HashIterator { 1318 int nextSegmentIndex; 1319 int nextTableIndex; 1320 HashEntry<K,V>[] currentTable; 1321 HashEntry<K, V> nextEntry; 1322 HashEntry<K, V> lastReturned; 1323 1324 HashIterator() { 1325 nextSegmentIndex = segments.length - 1; 1326 nextTableIndex = -1; 1327 advance(); 1328 } 1329 1330 /** 1331 * Set nextEntry to first node of next non-empty table 1332 * (in backwards order, to simplify checks). 1333 */ 1334 final void advance() { 1335 for (;;) { 1336 if (nextTableIndex >= 0) { 1337 if ((nextEntry = entryAt(currentTable, 1338 nextTableIndex--)) != null) 1339 break; 1340 } 1341 else if (nextSegmentIndex >= 0) { 1342 Segment<K,V> seg = segmentAt(segments, nextSegmentIndex--); 1343 if (seg != null && (currentTable = seg.table) != null) 1344 nextTableIndex = currentTable.length - 1; 1345 } 1346 else 1347 break; 1348 } 1349 } 1350 1351 final HashEntry<K,V> nextEntry() { 1352 HashEntry<K,V> e = nextEntry; 1353 if (e == null) 1354 throw new NoSuchElementException(); 1355 lastReturned = e; // cannot assign until after null check 1356 if ((nextEntry = e.next) == null) 1357 advance(); 1358 return e; 1359 } 1360 1361 public final boolean hasNext() { return nextEntry != null; } 1362 public final boolean hasMoreElements() { return nextEntry != null; } 1363 1364 public final void remove() { 1365 if (lastReturned == null) 1366 throw new IllegalStateException(); 1367 ConcurrentHashMap.this.remove(lastReturned.key); 1368 lastReturned = null; 1369 } 1370 } 1371 1372 final class KeyIterator 1373 extends HashIterator 1374 implements Iterator<K>, Enumeration<K> 1375 { 1376 public final K next() { return super.nextEntry().key; } 1377 public final K nextElement() { return super.nextEntry().key; } 1378 } 1379 1380 final class ValueIterator 1381 extends HashIterator 1382 implements Iterator<V>, Enumeration<V> 1383 { 1384 public final V next() { return super.nextEntry().value; } 1385 public final V nextElement() { return super.nextEntry().value; } 1386 } 1387 1388 /** 1389 * Custom Entry class used by EntryIterator.next(), that relays 1390 * setValue changes to the underlying map. 1391 */ 1392 final class WriteThroughEntry 1393 extends AbstractMap.SimpleEntry<K,V> 1394 { 1395 WriteThroughEntry(K k, V v) { 1396 super(k,v); 1397 } 1398 1399 /** 1400 * Set our entry's value and write through to the map. The 1401 * value to return is somewhat arbitrary here. Since a 1402 * WriteThroughEntry does not necessarily track asynchronous 1403 * changes, the most recent "previous" value could be 1404 * different from what we return (or could even have been 1405 * removed in which case the put will re-establish). We do not 1406 * and cannot guarantee more. 1407 */ 1408 public V setValue(V value) { 1409 if (value == null) throw new NullPointerException(); 1410 V v = super.setValue(value); 1411 ConcurrentHashMap.this.put(getKey(), value); 1412 return v; 1413 } 1414 } 1415 1416 final class EntryIterator 1417 extends HashIterator 1418 implements Iterator<Entry<K,V>> 1419 { 1420 public Map.Entry<K,V> next() { 1421 HashEntry<K,V> e = super.nextEntry(); 1422 return new WriteThroughEntry(e.key, e.value); 1423 } 1424 } 1425 1426 final class KeySet extends AbstractSet<K> { 1427 public Iterator<K> iterator() { 1428 return new KeyIterator(); 1429 } 1430 public int size() { 1431 return ConcurrentHashMap.this.size(); 1432 } 1433 public boolean isEmpty() { 1434 return ConcurrentHashMap.this.isEmpty(); 1435 } 1436 public boolean contains(Object o) { 1437 return ConcurrentHashMap.this.containsKey(o); 1438 } 1439 public boolean remove(Object o) { 1440 return ConcurrentHashMap.this.remove(o) != null; 1441 } 1442 public void clear() { 1443 ConcurrentHashMap.this.clear(); 1444 } 1445 } 1446 1447 final class Values extends AbstractCollection<V> { 1448 public Iterator<V> iterator() { 1449 return new ValueIterator(); 1450 } 1451 public int size() { 1452 return ConcurrentHashMap.this.size(); 1453 } 1454 public boolean isEmpty() { 1455 return ConcurrentHashMap.this.isEmpty(); 1456 } 1457 public boolean contains(Object o) { 1458 return ConcurrentHashMap.this.containsValue(o); 1459 } 1460 public void clear() { 1461 ConcurrentHashMap.this.clear(); 1462 } 1463 } 1464 1465 final class EntrySet extends AbstractSet<Map.Entry<K,V>> { 1466 public Iterator<Map.Entry<K,V>> iterator() { 1467 return new EntryIterator(); 1468 } 1469 public boolean contains(Object o) { 1470 if (!(o instanceof Map.Entry)) 1471 return false; 1472 Map.Entry<?,?> e = (Map.Entry<?,?>)o; 1473 V v = ConcurrentHashMap.this.get(e.getKey()); 1474 return v != null && v.equals(e.getValue()); 1475 } 1476 public boolean remove(Object o) { 1477 if (!(o instanceof Map.Entry)) 1478 return false; 1479 Map.Entry<?,?> e = (Map.Entry<?,?>)o; 1480 return ConcurrentHashMap.this.remove(e.getKey(), e.getValue()); 1481 } 1482 public int size() { 1483 return ConcurrentHashMap.this.size(); 1484 } 1485 public boolean isEmpty() { 1486 return ConcurrentHashMap.this.isEmpty(); 1487 } 1488 public void clear() { 1489 ConcurrentHashMap.this.clear(); 1490 } 1491 } 1492 1493 /* ---------------- Serialization Support -------------- */ 1494 1495 /** 1496 * Save the state of the <tt>ConcurrentHashMap</tt> instance to a 1497 * stream (i.e., serialize it). 1498 * @param s the stream 1499 * @serialData 1500 * the key (Object) and value (Object) 1501 * for each key-value mapping, followed by a null pair. 1502 * The key-value mappings are emitted in no particular order. 1503 */ 1504 private void writeObject(java.io.ObjectOutputStream s) throws IOException { 1505 // force all segments for serialization compatibility 1506 for (int k = 0; k < segments.length; ++k) 1507 ensureSegment(k); 1508 s.defaultWriteObject(); 1509 1510 final Segment<K,V>[] segments = this.segments; 1511 for (int k = 0; k < segments.length; ++k) { 1512 Segment<K,V> seg = segmentAt(segments, k); 1513 seg.lock(); 1514 try { 1515 HashEntry<K,V>[] tab = seg.table; 1516 for (int i = 0; i < tab.length; ++i) { 1517 HashEntry<K,V> e; 1518 for (e = entryAt(tab, i); e != null; e = e.next) { 1519 s.writeObject(e.key); 1520 s.writeObject(e.value); 1521 } 1522 } 1523 } finally { 1524 seg.unlock(); 1525 } 1526 } 1527 s.writeObject(null); 1528 s.writeObject(null); 1529 } 1530 1531 /** 1532 * Reconstitute the <tt>ConcurrentHashMap</tt> instance from a 1533 * stream (i.e., deserialize it). 1534 * @param s the stream 1535 */ 1536 @SuppressWarnings("unchecked") 1537 private void readObject(java.io.ObjectInputStream s) 1538 throws IOException, ClassNotFoundException { 1539 // Don't call defaultReadObject() 1540 ObjectInputStream.GetField oisFields = s.readFields(); 1541 final Segment<K,V>[] oisSegments = (Segment<K,V>[])oisFields.get("segments", null); 1542 1543 final int ssize = oisSegments.length; 1544 if (ssize < 1 || ssize > MAX_SEGMENTS 1545 || (ssize & (ssize-1)) != 0 ) // ssize not power of two 1546 throw new java.io.InvalidObjectException("Bad number of segments:" 1547 + ssize); 1548 int sshift = 0, ssizeTmp = ssize; 1549 while (ssizeTmp > 1) { 1550 ++sshift; 1551 ssizeTmp >>>= 1; 1552 } 1553 UNSAFE.putIntVolatile(this, SEGSHIFT_OFFSET, 32 - sshift); 1554 UNSAFE.putIntVolatile(this, SEGMASK_OFFSET, ssize - 1); 1555 UNSAFE.putObjectVolatile(this, SEGMENTS_OFFSET, oisSegments); 1556 1557 // set hashMask 1558 UNSAFE.putIntVolatile(this, HASHSEED_OFFSET, randomHashSeed(this)); 1559 1560 // Re-initialize segments to be minimally sized, and let grow. 1561 int cap = MIN_SEGMENT_TABLE_CAPACITY; 1562 final Segment<K,V>[] segments = this.segments; 1563 for (int k = 0; k < segments.length; ++k) { 1564 Segment<K,V> seg = segments[k]; 1565 if (seg != null) { 1566 seg.threshold = (int)(cap * seg.loadFactor); 1567 seg.table = (HashEntry<K,V>[]) new HashEntry[cap]; 1568 } 1569 } 1570 1571 // Read the keys and values, and put the mappings in the table 1572 for (;;) { 1573 K key = (K) s.readObject(); 1574 V value = (V) s.readObject(); 1575 if (key == null) 1576 break; 1577 put(key, value); 1578 } 1579 } 1580 1581 // Unsafe mechanics 1582 private static final sun.misc.Unsafe UNSAFE; 1583 private static final long SBASE; 1584 private static final int SSHIFT; 1585 private static final long TBASE; 1586 private static final int TSHIFT; 1587 private static final long HASHSEED_OFFSET; 1588 private static final long SEGSHIFT_OFFSET; 1589 private static final long SEGMASK_OFFSET; 1590 private static final long SEGMENTS_OFFSET; 1591 1592 static { 1593 int ss, ts; 1594 try { 1595 UNSAFE = sun.misc.Unsafe.getUnsafe(); 1596 Class tc = HashEntry[].class; 1597 Class sc = Segment[].class; 1598 TBASE = UNSAFE.arrayBaseOffset(tc); 1599 SBASE = UNSAFE.arrayBaseOffset(sc); 1600 ts = UNSAFE.arrayIndexScale(tc); 1601 ss = UNSAFE.arrayIndexScale(sc); 1602 HASHSEED_OFFSET = UNSAFE.objectFieldOffset( 1603 ConcurrentHashMap.class.getDeclaredField("hashSeed")); 1604 SEGSHIFT_OFFSET = UNSAFE.objectFieldOffset( 1605 ConcurrentHashMap.class.getDeclaredField("segmentShift")); 1606 SEGMASK_OFFSET = UNSAFE.objectFieldOffset( 1607 ConcurrentHashMap.class.getDeclaredField("segmentMask")); 1608 SEGMENTS_OFFSET = UNSAFE.objectFieldOffset( 1609 ConcurrentHashMap.class.getDeclaredField("segments")); 1610 } catch (Exception e) { 1611 throw new Error(e); 1612 } 1613 if ((ss & (ss-1)) != 0 || (ts & (ts-1)) != 0) 1614 throw new Error("data type scale not a power of two"); 1615 SSHIFT = 31 - Integer.numberOfLeadingZeros(ss); 1616 TSHIFT = 31 - Integer.numberOfLeadingZeros(ts); 1617 } 1618 1619 }
下面从ConcurrentHashMap的创建,获取,添加,删除这4个方面对ConcurrentHashMap进行分析。
1 创建
下面以ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel)来进行说明。
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
// 参数有效性判断
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// concurrencyLevel是“用来计算segments的容量”
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
// ssize=“大于或等于concurrencyLevel的最小的2的N次方值”
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 初始化segmentShift和segmentMask
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
// 哈希表的初始容量
// 哈希表的实际容量=“segments的容量” x “segments中数组的长度”
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// “哈希表的初始容量” / “segments的容量”
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// cap就是“segments中的HashEntry数组的长度”
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// segments
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
说明:
(01) 前面我们说过,ConcurrentHashMap采用了“锁分段”技术;在代码中,它通过“segments数组”对象来保存各个分段。segments的定义如下:
final Segment<K,V>[] segments;
concurrencyLevel的作用就是用来计算segments数组的容量大小。先计算出“大于或等于concurrencyLevel的最小的2的N次方值”,然后将其保存为“segments的容量大小(ssize)”。
(02) initialCapacity是哈希表的初始容量。需要注意的是,哈希表的实际容量=“segments的容量” x “segments中数组的长度”。
(03) loadFactor是加载因子。它是哈希表在其容量自动增加之前可以达到多满的一种尺度。
ConcurrentHashMap的构造函数中涉及到的非常重要的一个结构体,它就是Segment。下面看看Segment的声明:
static final class Segment<K,V> extends ReentrantLock implements Serializable { ... transient volatile HashEntry<K,V>[] table; // threshold阈,是哈希表在其容量自动增加之前可以达到多满的一种尺度。 transient int threshold; // loadFactor是加载因子 final float loadFactor; Segment(float lf, int threshold, HashEntry<K,V>[] tab) { this.loadFactor = lf; this.threshold = threshold; this.table = tab; } ... }
说明:Segment包含HashEntry数组,HashEntry保存了哈希表中的键值对。
此外,还需要说明的Segment继承于ReentrantLock。这意味着,Segment本质上就是可重入的互斥锁。
HashEntry的源码如下:
static final class HashEntry<K,V> { final int hash; // 哈希值 final K key; // 键 volatile V value; // 值 volatile HashEntry<K,V> next; // 下一个HashEntry节点 HashEntry(int hash, K key, V value, HashEntry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } ... }
说明:和HashMap的节点一样,HashEntry也是链表。这就说明,ConcurrentHashMap是链式哈希表,它是通过“拉链法”来解决哈希冲突的。
2 获取
下面以get(Object key)为例,对ConcurrentHashMap的获取方法进行说明。
public V get(Object key) { Segment<K,V> s; // manually integrate access methods to reduce overhead HashEntry<K,V>[] tab; int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; // 获取key对应的Segment片段。 // 如果Segment片段不为null,则在“Segment片段的HashEntry数组中”中找到key所对应的HashEntry列表; // 接着遍历该HashEntry链表,找到于key-value键值对对应的HashEntry节点。 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE); e != null; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null; }
说明:get(Object key)的作用是返回key在ConcurrentHashMap哈希表中对应的值。
它首先根据key计算出来的哈希值,获取key所对应的Segment片段。
如果Segment片段不为null,则在“Segment片段的HashEntry数组中”中找到key所对应的HashEntry列表。Segment包含“HashEntry数组”对象,而每一个HashEntry本质上是一个单向链表。
接着遍历该HashEntry链表,找到于key-value键值对对应的HashEntry节点。
下面是hash()的源码
private int hash(Object k) { int h = hashSeed; if ((0 != h) && (k instanceof String)) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // Spread bits to regularize both segment and index locations, // using variant of single-word Wang/Jenkins hash. h += (h << 15) ^ 0xffffcd7d; h ^= (h >>> 10); h += (h << 3); h ^= (h >>> 6); h += (h << 2) + (h << 14); return h ^ (h >>> 16); }
3 增加
下面以put(K key, V value)来对ConcurrentHashMap中增加键值对来进行说明。
public V put(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); // 获取key对应的哈希值 int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; // 如果找不到该Segment,则新建一个。 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); return s.put(key, hash, value, false); }
说明:
(01) put()根据key获取对应的哈希值,再根据哈希值找到对应的Segment片段。如果Segment片段不存在,则新增一个Segment。
(02) 将key-value键值对添加到Segment片段中。
final V put(K key, int hash, V value, boolean onlyIfAbsent) { // tryLock()获取锁,成功返回true,失败返回false。 // 获取锁失败的话,则通过scanAndLockForPut()获取锁,并返回”要插入的key-value“对应的”HashEntry链表“。 HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { // tab代表”当前Segment中的HashEntry数组“ HashEntry<K,V>[] tab = table; // 根据”hash值“获取”HashEntry数组中对应的HashEntry链表“ int index = (tab.length - 1) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { // 如果”HashEntry链表中的当前HashEntry节点“不为null, if (e != null) { K k; // 当”要插入的key-value键值对“已经存在于”HashEntry链表中“时,先保存原有的值。 // 若”onlyIfAbsent“为true,即”要插入的key不存在时才插入”,则直接退出; // 否则,用新的value值覆盖原有的原有的值。 if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { // 如果node非空,则将first设置为“node的下一个节点”。 // 否则,新建HashEntry链表 if (node != null) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; // 如果添加key-value键值对之后,Segment中的元素超过阈值(并且,HashEntry数组的长度没超过限制),则rehash; // 否则,直接添加key-value键值对。 if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { // 释放锁 unlock(); } return oldValue; }
说明:
put()的作用是将key-value键值对插入到“当前Segment对应的HashEntry中”,在插入前它会获取Segment对应的互斥锁,插入后会释放锁。具体的插入过程如下:
(01) 首先根据“hash值”获取“当前Segment的HashEntry数组对象”中的“HashEntry节点”,每个HashEntry节点都是一个单向链表。
(02) 接着,遍历HashEntry链表。
若在遍历HashEntry链表时,找到与“要key-value键值对”对应的节点,即“要插入的key-value键值对”的key已经存在于HashEntry链表中。则根据onlyIfAbsent进行判断,若onlyIfAbsent为true,即“当要插入的key不存在时才插入”,则不进行插入,直接返回;否则,用新的value值覆盖原始的value值,然后再返回。
若在遍历HashEntry链表时,没有找到与“要key-value键值对”对应的节点。当node!=null时,即在scanAndLockForPut()获取锁时,已经新建了key-value对应的HashEntry节点,则”将HashEntry添加到Segment中“;否则,新建key-value对应的HashEntry节点,然后再“将HashEntry添加到Segment中”。 在”将HashEntry添加到Segment中“前,会判断是否需要rehash。如果在添加key-value键值之后,容量会超过阈值,并且HashEntry数组的长度没有超过限制,则进行rehash;否则,直接通过setEntryAt()将key-value键值对添加到Segment中。
在介绍rehash()和setEntryAt()之前,我们先看看自旋函数scanAndLockForPut()。下面是它的源码:
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) { // 第一个HashEntry节点 HashEntry<K,V> first = entryForHash(this, hash); // 当前的HashEntry节点 HashEntry<K,V> e = first; HashEntry<K,V> node = null; // 重复计数(自旋计数器) int retries = -1; // negative while locating node // 查找”key-value键值对“在”HashEntry链表上对应的节点“; // 若找到的话,则不断的自旋;在自旋期间,若通过tryLock()获取锁成功则返回;否则自旋MAX_SCAN_RETRIES次数之后,强制获取”锁“并退出。 // 若没有找到的话,则新建一个HashEntry链表。然后不断的自旋。 // 此外,若在自旋期间,HashEntry链表的表头发生变化;则重新进行查找和自旋工作! while (!tryLock()) { HashEntry<K,V> f; // to recheck first below // 1. retries<0的处理情况 if (retries < 0) { // 1.1 如果当前的HashEntry节点为空(意味着,在该HashEntry链表上上没有找到”要插入的键值对“对应的节点),而且node=null;则新建HashEntry链表。 if (e == null) { if (node == null) // speculatively create node node = new HashEntry<K,V>(hash, key, value, null); retries = 0; } // 1.2 如果当前的HashEntry节点是”要插入的键值对在该HashEntry上对应的节点“,则设置retries=0 else if (key.equals(e.key)) retries = 0; // 1.3 设置为下一个HashEntry。 else e = e.next; } // 2. 如果自旋次数超过限制,则获取“锁”并退出 else if (++retries > MAX_SCAN_RETRIES) { lock(); break; } // 3. 当“尝试了偶数次”时,就获取“当前Segment的第一个HashEntry”,即f。 // 然后,通过f!=first来判断“当前Segment的第一个HashEntry是否发生了改变”。 // 若是的话,则重置e,first和retries的值,并重新遍历。 else if ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) { e = first = f; // re-traverse if entry changed retries = -1; } } return node; }
说明:
scanAndLockForPut()的目标是获取锁。流程如下:
它首先会调用entryForHash(),根据hash值获取”当前Segment中对应的HashEntry节点(first),即找到对应的HashEntry链表“。
紧接着进入while循环。在while循环中,它会遍历”HashEntry链表(e)“,查找”要插入的key-value键值对“在”该HashEntry链表上对应的节点“。
若找到的话,则不断的自旋,即不断的执行while循环。在自旋期间,若通过tryLock()获取锁成功则返回;否则,在自旋MAX_SCAN_RETRIES次数之后,强制获取锁并退出。
若没有找到的话,则新建一个HashEntry链表,然后不断的自旋。在自旋期间,若通过tryLock()获取锁成功则返回;否则,在自旋MAX_SCAN_RETRIES次数之后,强制获取锁并退出。
此外,若在自旋期间,HashEntry链表的表头发生变化;则重新进行查找和自旋工作!
理解scanAndLockForPut()时,务必要联系”哈希表“的数据结构。一个Segment本身就是一个哈希表,Segment中包含了”HashEntry数组“对象,而每一个HashEntry对象本身是一个”单向链表“。
下面看看rehash()的实现代码。
private void rehash(HashEntry<K,V> node) { HashEntry<K,V>[] oldTable = table; // ”Segment中原始的HashEntry数组的长度“ int oldCapacity = oldTable.length; // ”Segment中新HashEntry数组的长度“ int newCapacity = oldCapacity << 1; // 新的阈值 threshold = (int)(newCapacity * loadFactor); // 新的HashEntry数组 HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity]; int sizeMask = newCapacity - 1; // 遍历”原始的HashEntry数组“, // 将”原始的HashEntry数组“中的每个”HashEntry链表“的值,都复制到”新的HashEntry数组的HashEntry元素“中。 for (int i = 0; i < oldCapacity ; i++) { // 获取”原始的HashEntry数组“中的”第i个HashEntry链表“ HashEntry<K,V> e = oldTable[i]; if (e != null) { HashEntry<K,V> next = e.next; int idx = e.hash & sizeMask; if (next == null) // Single node on list newTable[idx] = e; else { // Reuse consecutive sequence at same slot HashEntry<K,V> lastRun = e; int lastIdx = idx; for (HashEntry<K,V> last = next; last != null; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun; // 将”原始的HashEntry数组“中的”HashEntry链表(e)“的值,都复制到”新的HashEntry数组的HashEntry“中。 for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry<K,V> n = newTable[k]; newTable[k] = new HashEntry<K,V>(h, p.key, v, n); } } } } // 将新的node节点添加到“Segment的新HashEntry数组(newTable)“中。 int nodeIndex = node.hash & sizeMask; // add the new node node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; }
说明:rehash()的作用是将”Segment的容量“变为”原始的Segment容量的2倍“。
在将原始的数据拷贝到“新的Segment”中后,会将新增加的key-value键值对添加到“新的Segment”中。
setEntryAt()的源码如下:
static final <K,V> void setEntryAt(HashEntry<K,V>[] tab, int i, HashEntry<K,V> e) { UNSAFE.putOrderedObject(tab, ((long)i << TSHIFT) + TBASE, e); }
UNSAFE是Segment类中定义的“静态sun.misc.Unsafe”对象。源码如下:
static final sun.misc.Unsafe UNSAFE;
Unsafe.java在openjdk6中的路径是:openjdk6/jdk/src/share/classes/sun/misc/Unsafe.java。其中,putOrderedObject()的源码下:
public native void putOrderedObject(Object o, long offset, Object x);
说明:putOrderedObject()是一个本地方法。
它会设置obj对象中offset偏移地址对应的object型field的值为指定值。它是一个有序或者有延迟的putObjectVolatile()方法,并且不保证值的改变被其他线程立即看到。只有在field被volatile修饰并且期望被意外修改的时候,使用putOrderedObject()才有用。
总之,setEntryAt()的目的是设置tab中第i位置元素的值为e,且该设置会有延迟。
4 删除
下面以remove(Object key)来对ConcurrentHashMap中的删除操作来进行说明。
public V remove(Object key) { int hash = hash(key); // 根据hash值,找到key对应的Segment片段。 Segment<K,V> s = segmentForHash(hash); return s == null ? null : s.remove(key, hash, null); }
说明:remove()首先根据“key的计算出来的哈希值”找到对应的Segment片段,然后再从该Segment片段中删除对应的“key-value键值对”。
remove()的方法如下:
final V remove(Object key, int hash, Object value) { // 尝试获取Segment对应的锁。 // 尝试失败的话,则通过scanAndLock()来获取锁。 if (!tryLock()) scanAndLock(key, hash); V oldValue = null; try { // 根据“hash值”找到“Segment的HashEntry数组”中对应的“HashEntry节点(e)”,该HashEntry节点是一HashEntry个链表。 HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; HashEntry<K,V> e = entryAt(tab, index); HashEntry<K,V> pred = null; // 遍历“HashEntry链表”,删除key-value键值对 while (e != null) { K k; HashEntry<K,V> next = e.next; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { V v = e.value; if (value == null || value == v || value.equals(v)) { if (pred == null) setEntryAt(tab, index, next); else pred.setNext(next); ++modCount; --count; oldValue = v; } break; } pred = e; e = next; } } finally { // 释放锁 unlock(); } return oldValue; }
说明:remove()的目的就是删除key-value键值对。在删除之前,它会获取到Segment的互斥锁,在删除之后,再释放锁。
它的删除过程也比较简单,它会先根据hash值,找到“Segment的HashEntry数组”中对应的“HashEntry”节点。根据Segment的数据结构,我们知道Segment中包含一个HashEntry数组对象,而每一个HashEntry本质上是一个单向链表。 在找到“HashEntry”节点之后,就遍历该“HashEntry”节点对应的链表,找到key-value键值对对应的节点,然后删除。
下面对scanAndLock()进行说明。它的源码如下:
private void scanAndLock(Object key, int hash) { // 第一个HashEntry节点 HashEntry<K,V> first = entryForHash(this, hash); HashEntry<K,V> e = first; int retries = -1; // 查找”key-value键值对“在”HashEntry链表上对应的节点“; // 无论找没找到,最后都会不断的自旋;在自旋期间,若通过tryLock()获取锁成功则返回;否则自旋MAX_SCAN_RETRIES次数之后,强制获取”锁“并退出。 // 若在自旋期间,HashEntry链表的表头发生变化;则重新进行查找和自旋! while (!tryLock()) { HashEntry<K,V> f; if (retries < 0) { // 如果“遍历完该HashEntry链表,仍然没找到”要删除的键值对“对应的节点” // 或者“在该HashEntry链表上找到”要删除的键值对“对应的节点”,则设置retries=0 // 否则,设置e为下一个HashEntry节点。 if (e == null || key.equals(e.key)) retries = 0; else e = e.next; } // 自旋超过限制次数之后,获取锁并退出。 else if (++retries > MAX_SCAN_RETRIES) { lock(); break; } // 当“尝试了偶数次”时,就获取“当前Segment的第一个HashEntry”,即f。 // 然后,通过f!=first来判断“当前Segment的第一个HashEntry是否发生了改变”。 // 若是的话,则重置e,first和retries的值,并重新遍历。 else if ((retries & 1) == 0 && (f = entryForHash(this, hash)) != first) { e = first = f; retries = -1; } } }
说明:scanAndLock()的目标是获取锁。它的实现与scanAndLockForPut()类似,这里就不再过多说明。
总结:ConcurrentHashMap是线程安全的哈希表,它是通过“锁分段”来实现的。ConcurrentHashMap中包括了“Segment(锁分段)数组”,每个Segment就是一个哈希表,而且也是可重入的互斥锁。第一,Segment是哈希表表现在,Segment包含了“HashEntry数组”,而“HashEntry数组”中的每一个HashEntry元素是一个单向链表。即Segment是通过链式哈希表。第二,Segment是可重入的互斥锁表现在,Segment继承于ReentrantLock,而ReentrantLock就是可重入的互斥锁。
对于ConcurrentHashMap的添加,删除操作,在操作开始前,线程都会获取Segment的互斥锁;操作完毕之后,才会释放。而对于读取操作,它是通过volatile去实现的,HashEntry数组是volatile类型的,而volatile能保证“即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入”,即我们总能读到其它线程写入HashEntry之后的值。 以上这些方式,就是ConcurrentHashMap线程安全的实现原理。
ConcurrentHashMap示例
下面,我们通过一个例子去对比HashMap和ConcurrentHashMap。
1 import java.util.*; 2 import java.util.concurrent.*; 3 4 /* 5 * ConcurrentHashMap是“线程安全”的哈希表,而HashMap是非线程安全的。 6 * 7 * 下面是“多个线程同时操作并且遍历map”的示例 8 * (01) 当map是ConcurrentHashMap对象时,程序能正常运行。 9 * (02) 当map是HashMap对象时,程序会产生ConcurrentModificationException异常。 10 * 11 * @author skywang 12 */ 13 public class ConcurrentHashMapDemo1 { 14 15 // TODO: map是HashMap对象时,程序会出错。 16 //private static Map<String, String> map = new HashMap<String, String>(); 17 private static Map<String, String> map = new ConcurrentHashMap<String, String>(); 18 public static void main(String[] args) { 19 20 // 同时启动两个线程对map进行操作! 21 new MyThread("ta").start(); 22 new MyThread("tb").start(); 23 } 24 25 private static void printAll() { 26 String key, value; 27 Iterator iter = map.entrySet().iterator(); 28 while(iter.hasNext()) { 29 Map.Entry entry = (Map.Entry)iter.next(); 30 key = (String)entry.getKey(); 31 value = (String)entry.getValue(); 32 System.out.print(key+" - "+value+", "); 33 } 34 System.out.println(); 35 } 36 37 private static class MyThread extends Thread { 38 MyThread(String name) { 39 super(name); 40 } 41 @Override 42 public void run() { 43 int i = 0; 44 while (i++ < 6) { 45 // “线程名” + "-" + "序号" 46 String val = Thread.currentThread().getName()+i; 47 map.put(String.valueOf(i), val); 48 // 通过“Iterator”遍历map。 49 printAll(); 50 } 51 } 52 } 53 }
(某一次)运行结果:
1 - tb1, 1 - tb1, 1 - tb1, 1 - tb1, 2 - tb2, 2 - tb2, 1 - tb1, 3 - ta3, 1 - tb1, 2 - tb2, 3 - tb3, 1 - tb1, 2 - tb2, 3 - tb3, 1 - tb1, 4 - tb4, 3 - tb3, 2 - tb2, 4 - tb4, 1 - tb1, 2 - tb2, 5 - ta5, 1 - tb1, 3 - tb3, 5 - tb5, 4 - tb4, 3 - tb3, 2 - tb2, 4 - tb4, 1 - tb1, 2 - tb2, 5 - tb5, 1 - tb1, 6 - tb6, 5 - tb5, 3 - tb3, 6 - tb6, 4 - tb4, 3 - tb3, 2 - tb2, 4 - tb4, 2 - tb2,
结果说明:如果将源码中的map改成HashMap对象时,程序会产生ConcurrentModificationException异常。
更多内容
2. Java多线程系列--“JUC集合”02之 CopyOnWriteArrayList
3. Java多线程系列--“JUC集合”03之 CopyOnWriteArraySet



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix