


概要
学完了Map的全部内容,我们再回头开开Map的框架图。
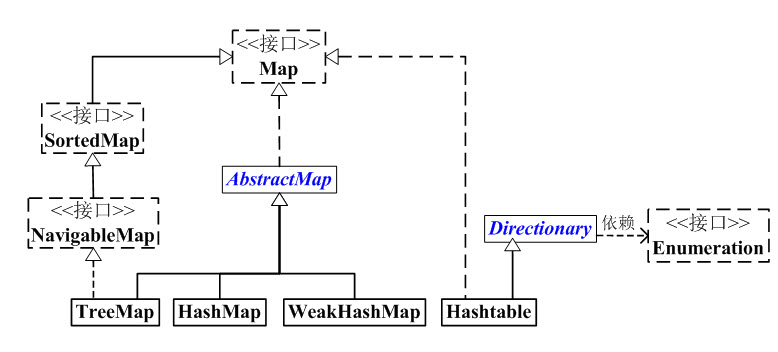
本章内容包括:
第1部分 Map概括
第2部分 HashMap和Hashtable异同
第3部分 HashMap和WeakHashMap异同
转载请注明出处:http://www.cnblogs.com/skywang12345/admin/EditPosts.aspx?postid=3311126
第1部分 Map概括
(01) Map 是“键值对”映射的抽象接口。
(02) AbstractMap 实现了Map中的绝大部分函数接口。它减少了“Map的实现类”的重复编码。
(03) SortedMap 有序的“键值对”映射接口。
(04) NavigableMap 是继承于SortedMap的,支持导航函数的接口。
(05) HashMap, Hashtable, TreeMap, WeakHashMap这4个类是“键值对”映射的实现类。它们各有区别!
HashMap 是基于“拉链法”实现的散列表。一般用于单线程程序中。
Hashtable 也是基于“拉链法”实现的散列表。它一般用于多线程程序中。
WeakHashMap 也是基于“拉链法”实现的散列表,它一般也用于单线程程序中。相比HashMap,WeakHashMap中的键是“弱键”,当“弱键”被GC回收时,它对应的键值对也会被从WeakHashMap中删除;而HashMap中的键是强键。
TreeMap 是有序的散列表,它是通过红黑树实现的。它一般用于单线程中存储有序的映射。
第2部分 HashMap和Hashtable异同
第2.1部分 HashMap和Hashtable的相同点
HashMap和Hashtable都是存储“键值对(key-value)”的散列表,而且都是采用拉链法实现的。
存储的思想都是:通过table数组存储,数组的每一个元素都是一个Entry;而一个Entry就是一个单向链表,Entry链表中的每一个节点就保存了key-value键值对数据。
添加key-value键值对:首先,根据key值计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据数组索引找到Entry(即,单向链表),再遍历单向链表,将key和链表中的每一个节点的key进行对比。若key已经存在Entry链表中,则用该value值取代旧的value值;若key不存在Entry链表中,则新建一个key-value节点,并将该节点插入Entry链表的表头位置。
删除key-value键值对:删除键值对,相比于“添加键值对”来说,简单很多。首先,还是根据key计算出哈希值,再计算出数组索引(即,该key-value在table中的索引)。然后,根据索引找出Entry(即,单向链表)。若节点key-value存在与链表Entry中,则删除链表中的节点即可。
上面介绍了HashMap和Hashtable的相同点。正是由于它们都是散列表,我们关注更多的是“它们的区别,以及它们分别适合在什么情况下使用”。那接下来,我们先看看它们的区别。
第2.2部分 HashMap和Hashtable的不同点
1 继承和实现方式不同
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
HashMap的定义:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { ... }
Hashtable的定义:
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable { ... }
从中,我们可以看出:
1.1 HashMap和Hashtable都实现了Map、Cloneable、java.io.Serializable接口。
实现了Map接口,意味着它们都支持key-value键值对操作。支持“添加key-value键值对”、“获取key”、“获取value”、“获取map大小”、“清空map”等基本的key-value键值对操作。
实现了Cloneable接口,意味着它能被克隆。
实现了java.io.Serializable接口,意味着它们支持序列化,能通过序列化去传输。
1.2 HashMap继承于AbstractMap,而Hashtable继承于Dictionary
Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。Dictionary类是JDK 1.0的引入的。虽然Dictionary也支持“添加key-value键值对”、“获取value”、“获取大小”等基本操作,但它的API函数比Map少;而且 Dictionary一般是通过Enumeration(枚举类)去遍历,Map则是通过Iterator(迭代器)去遍历。 然而‘由于Hashtable也实现了Map接口,所以,它即支持Enumeration遍历,也支持Iterator遍历。关于这点,后面还会进一步说明。
AbstractMap是一个抽象类,它实现了Map接口的绝大部分API函数;为Map的具体实现类提供了极大的便利。它是JDK 1.2新增的类。
2 线程安全不同
Hashtable的几乎所有函数都是同步的,即它是线程安全的,支持多线程。
而HashMap的函数则是非同步的,它不是线程安全的。若要在多线程中使用HashMap,需要我们额外的进行同步处理。 对HashMap的同步处理可以使用Collections类提供的synchronizedMap静态方法,或者直接使用JDK 5.0之后提供的java.util.concurrent包里的ConcurrentHashMap类。
3 对null值的处理不同
HashMap的key、value都可以为null。
Hashtable的key、value都不可以为null。
我们先看看HashMap和Hashtable “添加key-value”的方法
HashMap的添加key-value的方法



1 // 将“key-value”添加到HashMap中 2 public V put(K key, V value) { 3 // 若“key为null”,则将该键值对添加到table[0]中。 4 if (key == null) 5 return putForNullKey(value); 6 // 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。 7 int hash = hash(key.hashCode()); 8 int i = indexFor(hash, table.length); 9 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 10 Object k; 11 // 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出! 12 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 13 V oldValue = e.value; 14 e.value = value; 15 e.recordAccess(this); 16 return oldValue; 17 } 18 } 19 20 // 若“该key”对应的键值对不存在,则将“key-value”添加到table中 21 modCount++; 22 addEntry(hash, key, value, i); 23 return null; 24 } 25 26 // putForNullKey()的作用是将“key为null”键值对添加到table[0]位置 27 private V putForNullKey(V value) { 28 for (Entry<K,V> e = table[0]; e != null; e = e.next) { 29 if (e.key == null) { 30 V oldValue = e.value; 31 e.value = value; 32 // recordAccess()函数什么也没有做 33 e.recordAccess(this); 34 return oldValue; 35 } 36 } 37 // 添加第1个“key为null”的元素都table中的时候,会执行到这里。 38 // 它的作用是将“设置table[0]的key为null,值为value”。 39 modCount++; 40 addEntry(0, null, value, 0); 41 return null; 42 }
Hashtable的添加key-value的方法
1 // 将“key-value”添加到Hashtable中 2 public synchronized V put(K key, V value) { 3 // Hashtable中不能插入value为null的元素!!! 4 if (value == null) { 5 throw new NullPointerException(); 6 } 7 8 // 若“Hashtable中已存在键为key的键值对”, 9 // 则用“新的value”替换“旧的value” 10 Entry tab[] = table; 11 // Hashtable中不能插入key为null的元素!!! 12 // 否则,下面的语句会抛出异常! 13 int hash = key.hashCode(); 14 int index = (hash & 0x7FFFFFFF) % tab.length; 15 for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { 16 if ((e.hash == hash) && e.key.equals(key)) { 17 V old = e.value; 18 e.value = value; 19 return old; 20 } 21 } 22 23 // 若“Hashtable中不存在键为key的键值对”, 24 // (01) 将“修改统计数”+1 25 modCount++; 26 // (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子) 27 // 则调整Hashtable的大小 28 if (count >= threshold) { 29 // Rehash the table if the threshold is exceeded 30 rehash(); 31 32 tab = table; 33 index = (hash & 0x7FFFFFFF) % tab.length; 34 } 35 36 // (03) 将“Hashtable中index”位置的Entry(链表)保存到e中 Entry<K,V> e = tab[index]; 37 // (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。 38 tab[index] = new Entry<K,V>(hash, key, value, e); 39 // (05) 将“Hashtable的实际容量”+1 40 count++; 41 return null; 42 }
根据上面的代码,我们可以看出:
Hashtable的key或value,都不能为null!否则,会抛出异常NullPointerException。
HashMap的key、value都可以为null。 当HashMap的key为null时,HashMap会将其固定的插入table[0]位置(即HashMap散列表的第一个位置);而且table[0]处只会容纳一个key为null的值,当有多个key为null的值插入的时候,table[0]会保留最后插入的value。
4 支持的遍历种类不同
HashMap只支持Iterator(迭代器)遍历。
而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
Enumeration 是JDK 1.0添加的接口,只有hasMoreElements(), nextElement() 两个API接口,不能通过Enumeration()对元素进行修改 。
而Iterator 是JDK 1.2才添加的接口,支持hasNext(), next(), remove() 三个API接口。HashMap也是JDK 1.2版本才添加的,所以用Iterator取代Enumeration,HashMap只支持Iterator遍历。
5 通过Iterator迭代器遍历时,遍历的顺序不同
HashMap是“从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
Hashtabl是“从后往前”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
HashMap和Hashtable都实现Map接口,所以支持获取它们“key的集合”、“value的集合”、“key-value的集合”,然后通过Iterator对这些集合进行遍历。
由于“key的集合”、“value的集合”、“key-value的集合”的遍历原理都是一样的;下面,我以遍历“key-value的集合”来进行说明。
HashMap 和Hashtable 遍历"key-value集合"的方式是:(01) 通过entrySet()获取“Map.Entry集合”。 (02) 通过iterator()获取“Map.Entry集合”的迭代器,再进行遍历。
HashMap的实现方式:先“从前向后”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
1 // 返回“HashMap的Entry集合” 2 public Set<Map.Entry<K,V>> entrySet() { 3 return entrySet0(); 4 } 5 // 返回“HashMap的Entry集合”,它实际是返回一个EntrySet对象 6 private Set<Map.Entry<K,V>> entrySet0() { 7 Set<Map.Entry<K,V>> es = entrySet; 8 return es != null ? es : (entrySet = new EntrySet()); 9 } 10 // EntrySet对应的集合 11 // EntrySet继承于AbstractSet,说明该集合中没有重复的EntrySet。 12 private final class EntrySet extends AbstractSet<Map.Entry<K,V>> { 13 ... 14 public Iterator<Map.Entry<K,V>> iterator() { 15 return newEntryIterator(); 16 } 17 ... 18 } 19 // 返回一个“entry迭代器” 20 Iterator<Map.Entry<K,V>> newEntryIterator() { 21 return new EntryIterator(); 22 } 23 // Entry的迭代器 24 private final class EntryIterator extends HashIterator<Map.Entry<K,V>> { 25 public Map.Entry<K,V> next() { 26 return nextEntry(); 27 } 28 } 29 private abstract class HashIterator<E> implements Iterator<E> { 30 // 下一个元素 31 Entry<K,V> next; 32 // expectedModCount用于实现fail-fast机制。 33 int expectedModCount; 34 // 当前索引 35 int index; 36 // 当前元素 37 Entry<K,V> current; 38 39 HashIterator() { 40 expectedModCount = modCount; 41 if (size > 0) { // advance to first entry 42 Entry[] t = table; 43 // 将next指向table中第一个不为null的元素。 44 // 这里利用了index的初始值为0,从0开始依次向后遍历,直到找到不为null的元素就退出循环。 45 while (index < t.length && (next = t[index++]) == null) 46 ; 47 } 48 } 49 50 public final boolean hasNext() { 51 return next != null; 52 } 53 54 // 获取下一个元素 55 final Entry<K,V> nextEntry() { 56 if (modCount != expectedModCount) 57 throw new ConcurrentModificationException(); 58 Entry<K,V> e = next; 59 if (e == null) 60 throw new NoSuchElementException(); 61 62 // 注意!!! 63 // 一个Entry就是一个单向链表 64 // 若该Entry的下一个节点不为空,就将next指向下一个节点; 65 // 否则,将next指向下一个链表(也是下一个Entry)的不为null的节点。 66 if ((next = e.next) == null) { 67 Entry[] t = table; 68 while (index < t.length && (next = t[index++]) == null) 69 ; 70 } 71 current = e; 72 return e; 73 } 74 75 ... 76 }
Hashtable的实现方式:先从“后向往前”的遍历数组;对数组具体某一项对应的链表,则从表头开始往后遍历。
1 public Set<Map.Entry<K,V>> entrySet() { 2 if (entrySet==null) 3 entrySet = Collections.synchronizedSet(new EntrySet(), this); 4 return entrySet; 5 } 6 7 private class EntrySet extends AbstractSet<Map.Entry<K,V>> { 8 public Iterator<Map.Entry<K,V>> iterator() { 9 return getIterator(ENTRIES); 10 } 11 ... 12 } 13 14 private class Enumerator<T> implements Enumeration<T>, Iterator<T> { 15 // 指向Hashtable的table 16 Entry[] table = Hashtable.this.table; 17 // Hashtable的总的大小 18 int index = table.length; 19 Entry<K,V> entry = null; 20 Entry<K,V> lastReturned = null; 21 int type; 22 23 // Enumerator是 “迭代器(Iterator)” 还是 “枚举类(Enumeration)”的标志 24 // iterator为true,表示它是迭代器;否则,是枚举类。 25 boolean iterator; 26 27 // 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。 28 protected int expectedModCount = modCount; 29 30 Enumerator(int type, boolean iterator) { 31 this.type = type; 32 this.iterator = iterator; 33 } 34 35 // 从遍历table的数组的末尾向前查找,直到找到不为null的Entry。 36 public boolean hasMoreElements() { 37 Entry<K,V> e = entry; 38 int i = index; 39 Entry[] t = table; 40 /* Use locals for faster loop iteration */ 41 while (e == null && i > 0) { 42 e = t[--i]; 43 } 44 entry = e; 45 index = i; 46 return e != null; 47 } 48 49 // 获取下一个元素 50 // 注意:从hasMoreElements() 和nextElement() 可以看出“Hashtable的elements()遍历方式” 51 // 首先,从后向前的遍历table数组。table数组的每个节点都是一个单向链表(Entry)。 52 // 然后,依次向后遍历单向链表Entry。 53 public T nextElement() { 54 Entry<K,V> et = entry; 55 int i = index; 56 Entry[] t = table; 57 /* Use locals for faster loop iteration */ 58 while (et == null && i > 0) { 59 et = t[--i]; 60 } 61 entry = et; 62 index = i; 63 if (et != null) { 64 Entry<K,V> e = lastReturned = entry; 65 entry = e.next; 66 return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e); 67 } 68 throw new NoSuchElementException("Hashtable Enumerator"); 69 } 70 71 // 迭代器Iterator的判断是否存在下一个元素 72 // 实际上,它是调用的hasMoreElements() 73 public boolean hasNext() { 74 return hasMoreElements(); 75 } 76 77 // 迭代器获取下一个元素 78 // 实际上,它是调用的nextElement() 79 public T next() { 80 if (modCount != expectedModCount) 81 throw new ConcurrentModificationException(); 82 return nextElement(); 83 } 84 85 ... 86 87 }
6 容量的初始值 和 增加方式都不一样
HashMap默认的容量大小是16;增加容量时,每次将容量变为“原始容量x2”。
Hashtable默认的容量大小是11;增加容量时,每次将容量变为“原始容量x2 + 1”。
HashMap默认的“加载因子”是0.75, 默认的容量大小是16。
1 // 默认的初始容量是16,必须是2的幂。 2 static final int DEFAULT_INITIAL_CAPACITY = 16; 3 4 // 默认加载因子 5 static final float DEFAULT_LOAD_FACTOR = 0.75f; 6 7 // 指定“容量大小”的构造函数 8 public HashMap(int initialCapacity) { 9 this(initialCapacity, DEFAULT_LOAD_FACTOR); 10 }
当HashMap的 “实际容量” >= “阈值”时,(阈值 = 总的容量 * 加载因子),就将HashMap的容量翻倍。
1 // 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。 2 void addEntry(int hash, K key, V value, int bucketIndex) { 3 // 保存“bucketIndex”位置的值到“e”中 4 Entry<K,V> e = table[bucketIndex]; 5 // 设置“bucketIndex”位置的元素为“新Entry”, 6 // 设置“e”为“新Entry的下一个节点” 7 table[bucketIndex] = new Entry<K,V>(hash, key, value, e); 8 // 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小 9 if (size++ >= threshold) 10 resize(2 * table.length); 11 }
Hashtable默认的“加载因子”是0.75, 默认的容量大小是11。
1 // 默认构造函数。 2 public Hashtable() { 3 // 默认构造函数,指定的容量大小是11;加载因子是0.75 4 this(11, 0.75f); 5 }
当Hashtable的 “实际容量” >= “阈值”时,(阈值 = 总的容量 x 加载因子),就将变为“原始容量x2 + 1”。
1 // 调整Hashtable的长度,将长度变成原来的(2倍+1) 2 // (01) 将“旧的Entry数组”赋值给一个临时变量。 3 // (02) 创建一个“新的Entry数组”,并赋值给“旧的Entry数组” 4 // (03) 将“Hashtable”中的全部元素依次添加到“新的Entry数组”中 5 protected void rehash() { 6 int oldCapacity = table.length; 7 Entry[] oldMap = table; 8 9 int newCapacity = oldCapacity * 2 + 1; 10 Entry[] newMap = new Entry[newCapacity]; 11 12 modCount++; 13 threshold = (int)(newCapacity * loadFactor); 14 table = newMap; 15 16 for (int i = oldCapacity ; i-- > 0 ;) { 17 for (Entry<K,V> old = oldMap[i] ; old != null ; ) { 18 Entry<K,V> e = old; 19 old = old.next; 20 21 int index = (e.hash & 0x7FFFFFFF) % newCapacity; 22 e.next = newMap[index]; 23 newMap[index] = e; 24 } 25 } 26 }
7 添加key-value时的hash值算法不同
HashMap添加元素时,是使用自定义的哈希算法。
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
HashMap添加元素时,是使用自定义的哈希算法。
1 static int hash(int h) { 2 h ^= (h >>> 20) ^ (h >>> 12); 3 return h ^ (h >>> 7) ^ (h >>> 4); 4 } 5 6 // 将“key-value”添加到HashMap中 7 public V put(K key, V value) { 8 // 若“key为null”,则将该键值对添加到table[0]中。 9 if (key == null) 10 return putForNullKey(value); 11 // 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。 12 int hash = hash(key.hashCode()); 13 int i = indexFor(hash, table.length); 14 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 15 Object k; 16 // 若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出! 17 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 18 V oldValue = e.value; 19 e.value = value; 20 e.recordAccess(this); 21 return oldValue; 22 } 23 } 24 25 // 若“该key”对应的键值对不存在,则将“key-value”添加到table中 26 modCount++; 27 addEntry(hash, key, value, i); 28 return null; 29 }
Hashtable没有自定义哈希算法,而直接采用的key的hashCode()。
1 public synchronized V put(K key, V value) { 2 // Hashtable中不能插入value为null的元素!!! 3 if (value == null) { 4 throw new NullPointerException(); 5 } 6 7 // 若“Hashtable中已存在键为key的键值对”, 8 // 则用“新的value”替换“旧的value” 9 Entry tab[] = table; 10 int hash = key.hashCode(); 11 int index = (hash & 0x7FFFFFFF) % tab.length; 12 for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { 13 if ((e.hash == hash) && e.key.equals(key)) { 14 V old = e.value; 15 e.value = value; 16 return old; 17 } 18 } 19 20 // 若“Hashtable中不存在键为key的键值对”, 21 // (01) 将“修改统计数”+1 22 modCount++; 23 // (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子) 24 // 则调整Hashtable的大小 25 if (count >= threshold) { 26 // Rehash the table if the threshold is exceeded 27 rehash(); 28 29 tab = table; 30 index = (hash & 0x7FFFFFFF) % tab.length; 31 } 32 33 // (03) 将“Hashtable中index”位置的Entry(链表)保存到e中 34 Entry<K,V> e = tab[index]; 35 // (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。 36 tab[index] = new Entry<K,V>(hash, key, value, e); 37 // (05) 将“Hashtable的实际容量”+1 38 count++; 39 return null; 40 }
8 部分API不同
Hashtable支持contains(Object value)方法,而且重写了toString()方法;
而HashMap不支持contains(Object value)方法,没有重写toString()方法。
最后,再说说“HashMap和Hashtable”使用的情景。
其实,若了解它们之间的不同之处后,可以很容易的区分根据情况进行取舍。例如:(01) 若在单线程中,我们往往会选择HashMap;而在多线程中,则会选择Hashtable。(02),若不能插入null元素,则选择Hashtable;否则,可以选择HashMap。
但这个不是绝对的标准。例如,在多线程中,我们可以自己对HashMap进行同步,也可以选择ConcurrentHashMap。当HashMap和Hashtable都不能满足自己的需求时,还可以考虑新定义一个类,继承或重新实现散列表;当然,一般情况下是不需要的了。
第3部分 HashMap和WeakHashMap异同
3.1 HashMap和WeakHashMap的相同点
1 它们都是散列表,存储的是“键值对”映射。
2 它们都继承于AbstractMap,并且实现Map基础。
3 它们的构造函数都一样。
它们都包括4个构造函数,而且函数的参数都一样。
4 默认的容量大小是16,默认的加载因子是0.75。
5 它们的“键”和“值”都允许为null。
6 它们都是“非同步的”。
3.2 HashMap和WeakHashMap的不同点
1 HashMap实现了Cloneable和Serializable接口,而WeakHashMap没有。
HashMap实现Cloneable,意味着它能通过clone()克隆自己。
HashMap实现Serializable,意味着它支持序列化,能通过序列化去传输。
2 HashMap的“键”是“强引用(StrongReference)”,而WeakHashMap的键是“弱引用(WeakReference)”。
WeakReference的“弱键”能实现WeakReference对“键值对”的动态回收。当“弱键”不再被使用到时,GC会回收它,WeakReference也会将“弱键”对应的键值对删除。
这个“弱键”实现的动态回收“键值对”的原理呢?其实,通过WeakReference(弱引用)和ReferenceQueue(引用队列)实现的。 首先,我们需要了解WeakHashMap中:
第一,“键”是WeakReference,即key是弱键。
第二,ReferenceQueue是一个引用队列,它是和WeakHashMap联合使用的。当弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。 WeakHashMap中的ReferenceQueue是queue。
第三,WeakHashMap是通过数组实现的,我们假设这个数组是table。
接下来,说说“动态回收”的步骤。
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
将“键值对”添加到WeakHashMap中时,添加的键都是弱键。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02) 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到queue队列中。
例如,当我们在将“弱键”key添加到WeakHashMap之后;后来将key设为null。这时,便没有外部外部对象再引用该了key。
接着,当Java虚拟机的GC回收内存时,会回收key的相关内存;同时,将key添加到queue队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的“弱键”;同步它们,就是删除table中被GC回收的“弱键”对应的键值对。
例如,当我们“读取WeakHashMap中的元素或获取WeakReference的大小时”,它会先同步table和queue,目的是“删除table中被GC回收的‘弱键’对应的键值对”。删除的方法就是逐个比较“table中元素的‘键’和queue中的‘键’”,若它们相当,则删除“table中的该键值对”。
3.3 HashMap和WeakHashMap的比较测试程序
1 import java.util.HashMap; 2 import java.util.Iterator; 3 import java.util.Map; 4 import java.util.WeakHashMap; 5 import java.util.Date; 6 import java.lang.ref.WeakReference; 7 8 /** 9 * @desc HashMap 和 WeakHashMap比较程序 10 * 11 * @author skywang 12 * @email kuiwu-wang@163.com 13 */ 14 public class CompareHashmapAndWeakhashmap { 15 16 public static void main(String[] args) throws Exception { 17 18 // 当“弱键”是String时,比较HashMap和WeakHashMap 19 compareWithString(); 20 // 当“弱键”是自定义类型时,比较HashMap和WeakHashMap 21 compareWithSelfClass(); 22 } 23 24 /** 25 * 遍历map,并打印map的大小 26 */ 27 private static void iteratorAndCountMap(Map map) { 28 // 遍历map 29 for (Iterator iter = map.entrySet().iterator(); 30 iter.hasNext(); ) { 31 Map.Entry en = (Map.Entry)iter.next(); 32 System.out.printf("map entry : %s - %s\n ",en.getKey(), en.getValue()); 33 } 34 35 // 打印HashMap的实际大小 36 System.out.printf(" map size:%s\n\n", map.size()); 37 } 38 39 /** 40 * 通过String对象测试HashMap和WeakHashMap 41 */ 42 private static void compareWithString() { 43 // 新建4个String字符串 44 String w1 = new String("W1"); 45 String w2 = new String("W2"); 46 String h1 = new String("H1"); 47 String h2 = new String("H2"); 48 49 // 新建 WeakHashMap对象,并将w1,w2添加到 WeakHashMap中 50 Map wmap = new WeakHashMap(); 51 wmap.put(w1, "w1"); 52 wmap.put(w2, "w2"); 53 54 // 新建 HashMap对象,并将h1,h2添加到 WeakHashMap中 55 Map hmap = new HashMap(); 56 hmap.put(h1, "h1"); 57 hmap.put(h2, "h2"); 58 59 // 删除HashMap中的“h1”。 60 // 结果:删除“h1”之后,HashMap中只有 h2 ! 61 hmap.remove(h1); 62 63 // 将WeakHashMap中的w1设置null,并执行gc()。系统会回收w1 64 // 结果:w1是“弱键”,被GC回收后,WeakHashMap中w1对应的键值对,也会被从WeakHashMap中删除。 65 // w2是“弱键”,但它不是null,不会被GC回收;也就不会被从WeakHashMap中删除。 66 // 因此,WeakHashMap中只有 w2 67 // 注意:若去掉“w1=null” 或者“System.gc()”,结果都会不一样! 68 w1 = null; 69 System.gc(); 70 71 // 遍历并打印HashMap的大小 72 System.out.printf(" -- HashMap --\n"); 73 iteratorAndCountMap(hmap); 74 75 // 遍历并打印WeakHashMap的大小 76 System.out.printf(" -- WeakHashMap --\n"); 77 iteratorAndCountMap(wmap); 78 } 79 80 /** 81 * 通过自定义类测试HashMap和WeakHashMap 82 */ 83 private static void compareWithSelfClass() { 84 // 新建4个自定义对象 85 Self s1 = new Self(10); 86 Self s2 = new Self(20); 87 Self s3 = new Self(30); 88 Self s4 = new Self(40); 89 90 // 新建 WeakHashMap对象,并将s1,s2添加到 WeakHashMap中 91 Map wmap = new WeakHashMap(); 92 wmap.put(s1, "s1"); 93 wmap.put(s2, "s2"); 94 95 // 新建 HashMap对象,并将s3,s4添加到 WeakHashMap中 96 Map hmap = new HashMap(); 97 hmap.put(s3, "s3"); 98 hmap.put(s4, "s4"); 99 100 // 删除HashMap中的s3。 101 // 结果:删除s3之后,HashMap中只有 s4 ! 102 hmap.remove(s3); 103 104 // 将WeakHashMap中的s1设置null,并执行gc()。系统会回收w1 105 // 结果:s1是“弱键”,被GC回收后,WeakHashMap中s1对应的键值对,也会被从WeakHashMap中删除。 106 // w2是“弱键”,但它不是null,不会被GC回收;也就不会被从WeakHashMap中删除。 107 // 因此,WeakHashMap中只有 s2 108 // 注意:若去掉“s1=null” 或者“System.gc()”,结果都会不一样! 109 s1 = null; 110 System.gc(); 111 112 /* 113 // 休眠500ms 114 try { 115 Thread.sleep(500); 116 } catch (InterruptedException e) { 117 e.printStackTrace(); 118 } 119 // */ 120 121 // 遍历并打印HashMap的大小 122 System.out.printf(" -- Self-def HashMap --\n"); 123 iteratorAndCountMap(hmap); 124 125 // 遍历并打印WeakHashMap的大小 126 System.out.printf(" -- Self-def WeakHashMap --\n"); 127 iteratorAndCountMap(wmap); 128 } 129 130 private static class Self { 131 int id; 132 133 public Self(int id) { 134 this.id = id; 135 } 136 137 // 覆盖finalize()方法 138 // 在GC回收时会被执行 139 protected void finalize() throws Throwable { 140 super.finalize(); 141 System.out.printf("GC Self: id=%d addr=0x%s)\n", id, this); 142 } 143 } 144 }
运行结果:
-- HashMap -- map entry : H2 - h2 map size:1 -- WeakHashMap -- map entry : W2 - w2 map size:1 -- Self-def HashMap -- map entry : CompareHashmapAndWeakhashmap$Self@1ff9dc36 - s4 map size:1 -- Self-def WeakHashMap -- GC Self: id=10 addr=0xCompareHashmapAndWeakhashmap$Self@12276af2) map entry : CompareHashmapAndWeakhashmap$Self@59de3f2d - s2 map size:1
更多内容
01. Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
02. Java 集合系列11之 Hashtable详细介绍(源码解析)和使用示例
03. Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例
04. Java 集合系列13之 WeakHashMap详细介绍(源码解析)和使用示例
05. Java 集合系列14之 Map总结(HashMap, Hashtable, TreeMap, WeakHashMap等使用场景)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix