
深度优先遍历
--------------------siwuxie095
深度优先遍历
看如下实例:
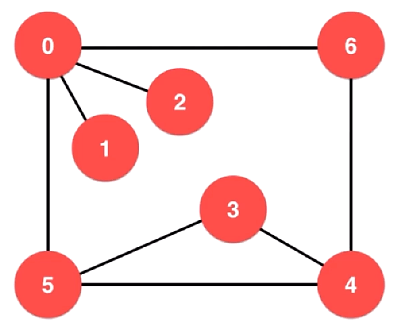
这张图的邻接表如下:

关于深度优先遍历,要把握两点:
(1)所谓深度优先,就是从一个点开始,不停地向下试,直到
试不下去为止。这个思路和树的深度优先是一致的
(2)图和树不一样的地方在于:树从根开始向下走, 一定有走
不通的时候,而图则存在环,不会走不通。因此,需要记录每一
个点是否被遍历过(访问过)。如果被遍历过了,在下面的遍历
中就不需要走了
以从 0 开始进行深度优先遍历为例(注意对照邻接表):
首先遍历和 0 相连的第一个没有被遍历的顶点,即 1
接着遍历和 1 相连的第一个没有被遍历的顶点,不存在。此路不通,退回到 0
接着遍历和 0 相连的下一个没有被遍历的顶点,即 2
接着遍历和 2 相连的第一个没有被遍历的顶点,不存在。此路不通,退回到 0
接着遍历和 0 相连的下一个没有被遍历的顶点,即 5
接着遍历和 5 相连的第一个没有被遍历的顶点,即 3。注意:0 已经被遍历过
接着遍历和 3 相连的第一个没有被遍历的顶点,即 4
接着遍历和 4 相连的第一个没有被遍历的顶点,即 6。注意:3 和 5 已经被遍历过
「其实到此为止,全部顶点已经遍历完毕」
接着遍历和 6 相连的第一个没有被遍历的顶点,不存在。此路不通,退回到 4
接着遍历和 4 相连的下一个没有被遍历的顶点,不存在。此路不通,退回到 3
接着遍历和 3 相连的下一个没有被遍历的顶点,不存在。此路不通,退回到 5
接着遍历和 5 相连的下一个没有被遍历的顶点,不存在。此路不通,退回到 0
接着遍历和 0 相连的下一个没有被遍历的顶点,不存在。至此,全部顶点遍历完毕
通过深度优先遍历,就将这样一个连通图中的所有顶点都访问了一遍
连通分量:求图中的连通分量的个数
深度优先遍历的一个最为典型的应用,即 求图中的连通分量的个数
看如下实例:

如上,是一张图的三个部分,即 三个连通分量
「连通分量和连通分量之间没有任何边相连」
如果给出一张图,只需要整体遍历一遍这张图,
即可求出这张图中的连通分量的个数
程序 1:
SparseGraph.h:
|
#ifndef SPARSEGRAPH_H #define SPARSEGRAPH_H
#include <iostream> #include <vector> #include <cassert> using namespace std;
// 稀疏图 - 邻接表 class SparseGraph {
private:
int n, m; //n 和 m 分别表示顶点数和边数 bool directed; //directed表示是有向图还是无向图 vector<vector<int>> g; //g[i]里存储的就是和顶点i相邻的所有顶点
public:
SparseGraph(int n, bool directed) { //初始化时,有n个顶点,0条边 this->n = n; this->m = 0; this->directed = directed; //g[i]初始化为空的vector for (int i = 0; i < n; i++) { g.push_back(vector<int>()); } }
~SparseGraph() {
}
int V(){ return n; } int E(){ return m; }
//在顶点v和顶点w之间建立一条边 void addEdge(int v, int w) {
assert(v >= 0 && v < n); assert(w >= 0 && w < n);
g[v].push_back(w); //(1)顶点v不等于顶点w,即不是自环边 //(2)且不是有向图,即是无向图 if (v != w && !directed) { g[w].push_back(v); }
m++; }
//hasEdge()判断顶点v和顶点w之间是否有边 //hasEdge()的时间复杂度:O(n) bool hasEdge(int v, int w) {
assert(v >= 0 && v < n); assert(w >= 0 && w < n);
for (int i = 0; i < g[v].size(); i++) { if (g[v][i] == w) { return true; } }
return false; }
void show() {
for (int i = 0; i < n; i++) { cout << "vertex " << i << ":\t"; for (int j = 0; j < g[i].size(); j++) { cout << g[i][j] << "\t"; } cout << endl; } }
//相邻点迭代器(相邻,即 adjacent) // //使用迭代器可以隐藏迭代的过程,按照一定的 //顺序访问一个容器中的所有元素 class adjIterator { private:
SparseGraph &G; //图的引用,即要迭代的图 int v; //顶点v int index; //相邻顶点的索引
public:
adjIterator(SparseGraph &graph, int v) : G(graph) { this->v = v; this->index = 0; }
//要迭代的第一个元素 int begin() { //因为有可能多次调用begin(), //所以显式的将index设置为0 index = 0; //如果g[v]的size()不为0 if (G.g[v].size()) { return G.g[v][index]; }
return -1; }
//要迭代的下一个元素 int next() { index++; if (index < G.g[v].size()) { return G.g[v][index]; }
return -1; }
//判断迭代是否终止 bool end() { return index >= G.g[v].size(); } }; };
//事实上,平行边的问题,就是邻接表的一个缺点 // //如果要在addEdge()中判断hasEdge(),因为hasEdge()是O(n)的复 //杂度,那么addEdge()也就变成O(n)的复杂度了 // //由于在使用邻接表表示稀疏图时,取消平行边(即在addEdge() //中加上hasEdge()),相应的成本比较高 // //所以,通常情况下,在addEdge()函数中就先不管平行边的问题, //也就是允许有平行边。如果真的要让图中没有平行边,就在所有 //边都添加进来之后,再进行一次综合的处理,将平行边删除掉
#endif |
DenseGraph.h:
|
#ifndef DENSEGRAPH_H #define DENSEGRAPH_H
#include <iostream> #include <vector> #include <cassert> using namespace std;
// 稠密图 - 邻接矩阵 class DenseGraph {
private:
int n, m; //n 和 m 分别表示顶点数和边数 bool directed; //directed表示是有向图还是无向图 vector<vector<bool>> g; //二维矩阵,存放布尔值,表示是否有边
public:
DenseGraph(int n, bool directed) { //初始化时,有n个顶点,0条边 this->n = n; this->m = 0; this->directed = directed; //二维矩阵:n行n列,全部初始化为false for (int i = 0; i < n; i++) { g.push_back(vector<bool>(n, false)); } }
~DenseGraph() {
}
int V(){ return n; } int E(){ return m; }
//在顶点v和顶点w之间建立一条边 void addEdge(int v, int w) {
assert(v >= 0 && v < n); assert(w >= 0 && w < n);
//如果顶点v和顶点w之间已经存在一条边, //则直接返回,即排除了平行边 if (hasEdge(v, w)) { return; }
g[v][w] = true; //如果是无向图,则g[w][v]处也设为true(无向图沿主对角线对称) if (!directed) { g[w][v] = true; }
m++; }
//hasEdge()判断顶点v和顶点w之间是否有边 //hasEdge()的时间复杂度:O(1) bool hasEdge(int v, int w) { assert(v >= 0 && v < n); assert(w >= 0 && w < n); return g[v][w]; }
void show() {
for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { cout << g[i][j] << "\t"; } cout << endl; } }
//相邻点迭代器(相邻,即 adjacent) class adjIterator { private:
DenseGraph &G; //图的引用,即要迭代的图 int v; //顶点v int index; //相邻顶点的索引
public:
adjIterator(DenseGraph &graph, int v) : G(graph) { this->v = v; this->index = -1; }
//要迭代的第一个元素 int begin() { //找第一个为true的元素,即为要迭代的第一个元素 index = -1; return next(); }
//要迭代的下一个元素 int next() { for (index += 1; index < G.V(); index++) { if (G.g[v][index]) { return index; } }
return -1; }
//判断迭代是否终止 bool end() { return index >= G.V(); } }; };
//addEdge()函数隐含着:当使用邻接矩阵表示稠密图时,已经 //不自觉的将平行边给去掉了,即在添加边时,如果发现已经 //存在该边,就不做任何操作,直接返回即可 // //事实上,这也是使用邻接矩阵的一个优势可以非常方便的处理 //平行边的问题 // //另外,由于使用的是邻接矩阵,可以非常快速的用O(1)的方式, //来判断顶点v和顶点w之间是否有边
#endif |
ReadGraph.h:
|
#ifndef READGRAPH_H #define READGRAPH_H
#include <iostream> #include <string> #include <fstream> #include <sstream> #include <cassert> using namespace std;
//从文件中读取图的测试用例 template <typename Graph> class ReadGraph {
public:
ReadGraph(Graph &graph, const string &filename) {
ifstream file(filename); string line; //一行一行的读取 int V, E;
assert(file.is_open());
//读取file中的第一行到line中 assert(getline(file, line)); //将字符串line放在stringstream中 stringstream ss(line); //通过stringstream解析出整型变量:顶点数和边数 ss >> V >> E;
//确保文件里的顶点数和图的构造函数中传入的顶点数一致 assert(V == graph.V());
//读取file中的其它行 for (int i = 0; i < E; i++) {
assert(getline(file, line)); stringstream ss(line);
int a, b; ss >> a >> b; assert(a >= 0 && a < V); assert(b >= 0 && b < V); graph.addEdge(a, b); } }
};
#endif |
Component.h:
|
#ifndef COMPONENT_H #define COMPONENT_H
#include <iostream> #include <cassert> using namespace std;
//通过深度优先遍历求图中的连通分量的个数(其中含有深度优先遍历的实现) template <typename Graph> class Component {
private:
Graph &G; //图的引用,即要进行深度优先遍历的图 bool *visited; //每个顶点是否被访问过(是否被遍历过) int ccount; //连通分量的个数 int *id; //同一个连通分量中的顶点,id相同,即表示相连
//将dfs()设置成私有函数 void dfs(int v) { //将访问过的顶点置为true visited[v] = true; id[v] = ccount; //注意:声明迭代器时,前面还要加 typename,表明 adjIterator //是 Graph 中的类型,而不是成员变量 typename Graph::adjIterator adj(G, v); for (int i = adj.begin(); !adj.end(); i = adj.next()) { //如果没有被访问过,接着访问相邻的顶点(递归) if (!visited[i]) { dfs(i); } } }
public:
Component(Graph &graph) : G(graph) {
visited = new bool[G.V()]; id = new int[G.V()]; ccount = 0; for (int i = 0; i < G.V(); i++) { visited[i] = false; id[i] = -1; }
//用深度优先遍历求图的连通分量的算法实现 for (int i = 0; i < G.V(); i++) { //如果当前访问的顶点没有被访问过,就 //对其进行深度优先遍历,并将和该顶点 //相连的所有顶点都访问一遍,最后没有 //被访问的顶点就一定在另外的连通分量 //中,将 ccount 进行 ++ 即可 if (!visited[i]) { dfs(i); ccount++; } }
}
~Component() { delete []visited; delete []id; }
int count() { return ccount; }
//判断顶点v和顶点w是否相连,即是否在同一连通分量中 bool isConnected(int v, int w) { assert(v >= 0 && v < G.V()); assert(w >= 0 && w < G.V()); return id[v] == id[w]; } };
#endif |
main.cpp:
|
#include "SparseGraph.h" #include "DenseGraph.h" #include "ReadGraph.h" #include "Component.h" #include <iostream> using namespace std;
int main() {
// TestG1.txt string filename1 = "testG1.txt"; //稀疏图 SparseGraph g1 = SparseGraph(13, false); ReadGraph<SparseGraph> readGraph1(g1, filename1); Component<SparseGraph> component1(g1); cout << "TestG1.txt, Component Count: " << component1.count() << endl;
cout << endl;
// TestG2.txt string filename2 = "testG2.txt"; //稀疏图 SparseGraph g2 = SparseGraph(7, false); ReadGraph<SparseGraph> readGraph2(g2, filename2); Component<SparseGraph> component2(g2); cout << "TestG2.txt, Component Count: " << component2.count() << endl;
system("pause"); return 0; }
//(1)图的深度优先遍历的复杂度: // //稀疏图 - 邻接表:O(V+E),通常情况下,E会比V大,所以也可以说是 O(E)。 //在邻接表的实现中,每一个顶点首先要访问,而每一个顶点的所有相邻顶点 //就构成总共的边数,也就是说,将所有的边也都访问了一次,没有进行其 //他多余的访问 // //稠密图 - 邻接矩阵:O(V^2),原因在于,当想要获得一个顶点的所有相邻 //顶点时,需要将图中的所有顶点都要扫一遍 // // //所以,对于稀疏图而言,通常使用邻接表的表达方式,它的效率就会更好 // // // //(2)另外,除了这里的无向图之外,深度优先遍历算法对有向图依然有效 // // // //(3)深度优先遍历还能用来检测图中是否有环,不过在无向图中查看是否 //有环,通常意义不大,但对于有向图来说,查看图中是否有环,就是非常有 //意义的一件事情 |
运行一览:

其中,testG1.txt 和 testG2.txt 的内容如下:


两个 txt 文件都可以分成两个部分:
(1)第一行:两个数字分别代表顶点数和边数
(2)其它行:每一行的两个数字表示一条边
寻路:获得两点间的一条路径
在进行深度优先遍历的过程中,也形成了一条一条的路径

如果想获得两点间的一条路径,就可以在深度优先遍历的过
程中找到。当然,这里并不能保证是最短路径
显然,需要在遍历的同时,对路径进行存储,具体做法:
遍历到某顶点的同时,存储一下是从哪个顶点遍历到了当前
顶点,即 存储当前顶点的上一个顶点
如果从 0 开始进行深度优先遍历,则遍历顺序为:
0、1、2、5、3、4、6
通过遍历顺序,就可以轻而易举地倒推出 0 到任意一个顶点
的具体路径
程序 2:(在程序 1 的基础上用 Path.h 替换 Component.h,
同时修改 main.cpp 即可)
Path.h:
|
#ifndef PATH_H #define PATH_H
#include <vector> #include <stack> #include <iostream> #include <cassert> using namespace std;
//通过深度优先遍历寻路 template <typename Graph> class Path {
private:
Graph &G; //图的引用,即要进行寻路的图 int s; //从顶点 s 到任意其它顶点的路径,s 即 source bool *visited; //每个顶点是否被访问过(是否被遍历过) int *from; //每访问一个顶点,就存储一下是从哪个顶点遍历到了当前顶点
void dfs(int v) {
visited[v] = true;
//注意:声明迭代器时,前面还要加 typename,表明 adjIterator //是 Graph 中的类型,而不是成员变量 typename Graph::adjIterator adj(G, v); for (int i = adj.begin(); !adj.end(); i = adj.next()) { if (!visited[i]) { from[i] = v; dfs(i); } } }
public:
Path(Graph &graph, int s) :G(graph) {
// 算法初始化 assert(s >= 0 && s < G.V());
visited = new bool[G.V()]; from = new int[G.V()]; for (int i = 0; i < G.V(); i++) { visited[i] = false; from[i] = -1; } this->s = s;
// 寻路算法 dfs(s); }
~Path() { delete []visited; delete []from; }
//从顶点s到顶点w是否有路:如果visited[w]为true, //表明从顶点s通过DFS访问到了顶点w,即有路 bool hasPath(int w) { assert(w >= 0 && w < G.V()); return visited[w]; }
//找到从顶点s到顶点w的路径:通过from数组从顶点w倒推回去, //并存储在栈中,最后再从栈中转存到向量中 void path(int w, vector<int> &vec) {
stack<int> s;
int p = w; //直到倒推到源顶点,它的from值为-1,即 from[s] = -1 while (p != -1) { s.push(p); p = from[p]; }
//为了安全起见,先将向量vector清空 vec.clear(); //只要栈不为空,就将栈顶元素放入向量中,并出栈 while (!s.empty()) { vec.push_back(s.top()); s.pop(); } }
//打印从顶点s到顶点w的路径 void showPath(int w) {
vector<int> vec; path(w, vec); for (int i = 0; i < vec.size(); i++) { cout << vec[i]; if (i == vec.size() - 1) { cout << endl; } else { cout << " -> "; } } } };
#endif |
main.cpp:
|
#include "SparseGraph.h" #include "DenseGraph.h" #include "ReadGraph.h" #include "Path.h" #include <iostream> using namespace std;
int main() {
string filename = "testG2.txt"; //稀疏图 SparseGraph g = SparseGraph(7, false); ReadGraph<SparseGraph> readGraph(g, filename); g.show(); cout << endl;
Path<SparseGraph> dfs(g, 0); cout << "DFS : "; dfs.showPath(6);
system("pause"); return 0; } |
运行一览:
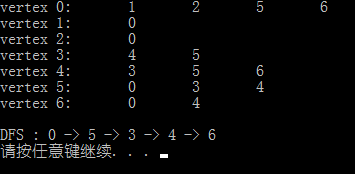
其中,testG2.txt 的内容同程序 1
【made by siwuxie095】
posted on 2017-07-05 09:23 siwuxie095 阅读(1464) 评论(0) 编辑 收藏 举报


