
Generative Adversarial Nets[Introduction]
0. 背景
通过阅读书籍《Pro Deep Learning with TensorFlow: A Mathematical Approach to Advanced Artificial Intelligence in Python》的第6章第4节的《Generative Adversarial Networks》,知道了不少前置知识。
GAN中蕴含了基于游戏论中的零和(zero-sum)游戏的理论。GAN有2个网络,一个生成器(G)和一个判别器(D),两者互相竞争。生成器为了愚弄判别器使得判别器无法区分输入的数据是来自真实数据还是来自它生成的假数据;而生成器是为了学习判别当前的数据是来自真实数据还是来自G造假的数据。这个游戏论问题的最优解就是他俩达到了nash平衡,即G生成的假数据的分布和原始真实数据的分布是基本一致的,而且当前判别器对真实数据和造假数据输出的概率只能是0.5。
纳什平衡有这样的前提:决策圈中的个体是独立的,不合作,不横向沟通,然后每个个体在猜测决策圈里其他人的选择后,做出自己认为最优的决策。这样的决策简单组合起来,就叫纳什平衡。纳什均衡点的通俗说明就是就说当所有人都不可能通过改变自己策略来获得更加高的收益时,此时这个策略组合达为纳什平衡。来自这里
假设真实数据的分布是\(P_x\);假数据是先从一个先验分布为\(P_z\)采样得到噪音数据z,然后将其输入到生成网络G得到\(G(z)\)。其中假数据\(G(z)\)是通过生成器表示的分布\(P_g\)生成的。平衡状态时候\(P_x(x)\)与\(P_g(G(z))\)逼近一致,即:
也就是真实数据x与假数据\(G(z)\)无法区分。真实分布\(P_x\)与生成器的分布\(P_g\)基本一致。
而在讲解后续原理之前,先介绍下零和(zero-sum)游戏,nash平衡,最小最大(Maximin)形式。
0.1. 最大最小和最小最大问题
在一场游戏中,每个参赛者都希望最大化他们各自的收益,增强他们获胜的概率。假设一个游戏有N个参赛者。对于参赛者i的最大最小策略,就是最大化他与其他N-1个参赛者之间的比赛;参赛者i的收益就是其在未知道其他人的操作的情况下自己完全确定的操作的最大值。因此最大最小策略\(s_i^*\)和最大值\(L_i^*\)可以表示成如下:
下面用例子来解释:

图0.1.1 参赛者A和B不同操作下的收益表格
在图0.1.1中,每个格子中的2元组第一个元素是A的收益,第二个是B的收益,其中A可选的操作是\(L_1\),\(L_2\),\(L_3\);B可选的操作是\(M_1\),\(M_2\)。
- 最大最小策略:即某个竞争者认为其他竞争者会期望他是最小化的收益(恶意揣测别人),所以他需要在自己每个操作的最小化收益中最大化他的收益:
- A如果选择\(L_1\),那么他此刻最小收益就是4;如果选择\(L_2\),他此刻最小收益是-20;如果选择\(L_3\),他最小收益是-201。所以,在A的所有可能最小值中的最大值就是4,即对应的策略是\(L_1\)。
- B如果选择\(M_1\),他的最小收益是0.5;如果选择\(M_2\),他的最小收益是-41。所以在B的所有可能最小值中的最大值就是0.5,对应策略就是\(M_1\)。
一旦达到了平衡,最后的行为组合是(\(L_1,M_1\)),各自收益是(6,2)。可以看出虽然每个竞争者通过各自的最大最小策略选择了各自的行为,不过事实上的收益还是会有所不同的。
- 最小最大策略:某个竞争者选择的策略是基于其他竞争者的选择基础上,可能的最大值中的最小值。
- 对于A来说,如果B选择了\(M_1\),则A的最大值可以是10;如果B选择了\(M_2\),则A的最大值可以是8.所以B可能会让A得到最大值中的最小值即8,从而A最后会选择\(L_3\)
- 对于B来说,如果A选择了\(L_1\),则B的最大值可以是2;如果A选择\(L_2\),则B的最大值可以是2;如果A选择\(L_3\),则B的最大值可以是8。而B猜测A会让B拿到最大值中的最小值2.(当前策略搭配作者没写)
可以看出,最小最大值的结果总是大于等于最大最小值的结果,当然这与如何定义最大最小和最小最大有关了。
0.2. 零和(zero-sum)游戏
在游戏论中,零和游戏是一个数学概念,主要思想就是,每个竞争者的收益或者是损失是基于其他人的损失或者收益的。作为一个系统来看待,就是整个系统的收益和损失其实是0,一切都是系统内部的运动而已。
这里再举个2人的例子,假设A和B在互相对比,零和游戏可以表示成一个收益矩阵的形式。如图
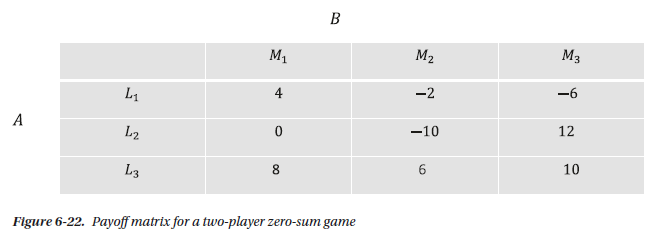
图0.2.1 A和B的零和游戏的收益矩阵图
图0.2.1中,矩阵每个元素表示的是A的收益,该矩阵中没有B的收益,B的收益即每个元素的相反数。
- 对于A:
- 采用最大最小策略:即针对自己不同的行为的最小值中选择最大的那个,从而其三个行为对应的最小值为{-2,-10,6}。所以A选择6,对应策略是\(L_3\),此时对应的B是选择了\(M_2\);
- 采用最小最大策略:即针对别人的选择导致的自己的最大值中选择最小的那个,从而其最大值为{8,6,12}。所以A选择6,对应的策略还是\(L_3\),次数对应B的旋转还是\(M_2\).
从这个例子中发现在零和游戏中最大最小的收益等于其最小最大的收益。
- 对于B:
- 采用最大最小策略:针对B自己来说,其最小值分别为{-8,-6,-12},从中选择最大值-6,对应的操作是\(M_2\),当然此时对应A的行为是\(L_3\);
- 采用最小最大策略:针对A的不同选择导致的最大值中选择最小的那个,其最大值分别为{6,10,-6},选择最小值为-6。此时B的操作是\(M_2\),对应A的行为是\(L_3\)
零和游戏总结:不管是A还是B,他们选择最大最小策略还是最小最大策略,他们最后都收敛于\(L_3,M_2\),对应的收益是\(6,-6\)。而且最小最大和最大最小值与他们在使用最小最大策略时的实际值一致;
上述观点可以导出一个很重要的事实:在零和游戏中,一个竞争者的最小最大策略可以产生针对两个竞争者实际的策略,如果他们同时都使用了最小最大或者最大最小策略。也就是盯着一个竞争者进行分析,就能得到所有人的行为策略。
0.3. 最小最大和鞍(saddle)点
零和游戏问题涉及到2个竞争者A和B,A的收益\(U(x,y)\)可以表示成:$$\hat U = \min_y\max_xU(x,y)$$。这里x表示A的操作,y表示B的操作。这里x,y表示当A和B到达策略平衡的时候的值,即他们如果持续相信自己的最小最大或者最大最小策略的判断的话,他们将保持当前的行为不改变。对于一个零和的2人游戏,最小最大或者最大最小将会得到一样的结果,并且该平衡不论竞争者选择最小最大还是最大最小策略都将保持与真实结果一致。同样因为最小最大值等于最大最小值,所以最小最大或者最大最小的顺序已经无关紧要了。我们让A和B各自独立的选择他们自己的策略计划中最好的策略,我们将会发现对于零和游戏,这些策略的组合将会有重叠,而重叠部分就是对于A和B不但是最好的,而且等同于他们自己的最小最大策略。这就是这场游戏的nash平衡。
目前位置,策略都是基于离散值,且基于收益矩阵的形式来解释。然而,策略也可以是连续值。比如在GAN中生成器和判别器的权重参数就是他们各自的策略。所以在进入GAN的世界之前,先再来看看关于A的收益函数\(f(x,y)\),这是一个关于两个连续值\(x,y\)的函数。如上面所述,在零和2人游戏中,最小最大和最大最小是一样的。所以最小最大的顺序就无所谓了:
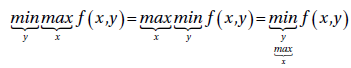
对于连续函数来说,只有当该函数达到了其鞍点才能得到解。而鞍点就是函数在当前位置上关于每个变量的梯度都为0.不过这并不表示当前是局部最小或者最大值的意思。反而,基于当前点朝着某些方向就能达到局部最小值,而相反方向就是局部最大值。所以我们可以使用多变量微积分的寻找鞍点的方法来解决这个问题。
- 计算驻点:计算函数\(f(x)\)关于向量\(x\)的梯度\(\triangledown_xf(x)\),并将其设为0;
- 判断是否是鞍点:计算该函数的hessian矩阵\(\triangledown^2_xf(x)\),即关于梯度向量\(\triangledown_xf(x)\)在求一次导。如果hessian矩阵同时有正和负的特征值,那么当前驻点就是鞍点
鞍点:对于多变量函数而言,当其hessian矩阵是一个非正定矩阵,则当前的点是一个鞍点。这是一个充分非必要条件。这里
举个例子:假设A的函数\(f(x,y)=x^2-y^2\),B的函数就是其相反数\(-x^2+y^2\)。
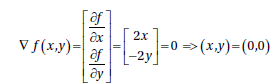
设为0时,得到的两个点分别为(0,0),这就是我们估计的点
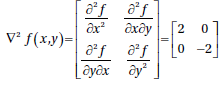
这个hessian矩阵对于任何值(x,y)都包含了(0,0),因为其同时有正和负的特征值2和-2.所以点(x,y)=(0,0)就是一个鞍点。也就是在一个零和最小最大或者最大最小游戏中,当达到平衡时,对于A的策略来说,设置为0的同时y应该也是0。
1. GAN损失函数和训练
在GAN中,生成器和判别器都试图在零和游戏中采用最小最大策略。在GAN中所谓的操作就是网络的参数值的变化。判别器就是试图区分输入的数据是真实数据还是G伪造出来的。换句话说,他会最大化函数:
即判别器试图对真实样本x输出1,对基于噪音数据z生成的伪造数据输出0。
- 对于真实数据,判别器的策略就是\(D(x)\)尽可能接近1,即\(logD(x)\)接近0。如果对真实数据判别错误,即\(D(x)\)越小于1,那么\(logD(x)\)越不断加速的小于0;
- 对于伪造数据,判别器是让\(D(G(z))\)接近于0,从而\(\left[log(1-D(G(z)))\right]\)接近于0。如果对于伪造数据判别错误,即\(D(G(z))\)越接近于1,则\(\left[log(1-D(G(z)))\right]\)越不断的加速的小于0。
所以最大情况就是0+0
当然,对于生成器G,他的收益就是让判别器的收益尽可能小。在零和游戏中,我们可以认为生成器就是与D有着相同函数,不过是相反的,即生成器是为了最大化下面的函数:
他生成假数据\(G(z)\),并为了让判别器\(D(G(z))\)越接近于1,此时\(\left[log(1-D(G(z)))\right]\)越不断的加速的小于0。也就是对于判别器\(-\left[log(1-D(G(z)))\right]\)值就会越来越大。不过可惜的是生成器是影响不了\(V(D,G)\)的第一项的,因为在生成器中,完全不涉及到真实数据样本的参数。
生成器G和判别器D在零和游戏中采用最小最大策略进行不断的训练。判别器为了最大化收益\(U(D,G)\):
同时,生成器为了最大化收益\(V(D,G)\):
因为第一项不存在生成器中,故而:
正如之前所说的,在2人的零和游戏中,不需要独立的考虑他们的最小最大策略,只要考虑一个竞争者的最小最大收益策略即可。这里我们拿判别器的最小最大公式,当游戏达到了纳什平衡的时候:
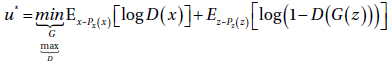 (1.6)
(1.6)
在\(u^*\)中的\(\hat G\)和\(\hat D\)值是对于两个网络的最优值,他们已经无法再提升他们的得分了,同时\((\hat G,\hat D)\)是D的收益函数\(E_{x\sim P_x(x)}\left[logD(x)\right]+E_{z\sim P_z(z)}\left[log(1-D(G(z)))\right]\)的鞍点。
可以将上面的优化过程简单划分成2个部分:
- 让D最大化他的收益函数;
- 让G最小化D的收益函数
每一次的操作都是假设对方行为固定的基础上优化自己的损失函数的。所以最终,可以采用梯度下降的方式来计算所需要的鞍点,因为ML的求解包多是计算最小值而不是最大值,所以判别器的目标函数可以乘以个-1,然后让D最小化这个新的目标函数。
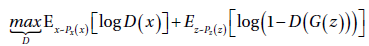
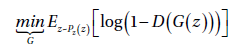
下面就是基于ML的迭代方法来训练GAN的过程:

2. 生成器的梯度消失问题
通常来说,训练的开始,生成器生成的数据是很不同于真实数据的,因此判别器是很容易进行判别的。这导致\(D(G(z))\)接近0.所以梯度\(\triangledown_{\theta_G}\left[\frac{1}{m}\sum_{i=1}^mlog\left(1-D(G(z^{(i)}))\right)\right]\)就饱和了。导致生成器G的参数有梯度消失的问题。为了解决这个问题,不最小化\(E_{z\sim P_z(z)}\left[log(1-D(G(z)))\right]\), 而是最大化\(E_{z\sim P_z(z)}\left[logG(z)\right]\),即最小化\(E_{z\sim P_z(z)}\left[-logG(z)\right]\)。这样让训练方法不再是纯粹的最小最大游戏,不过也是一个近似的方法,且有助于解决训练早期梯度饱和的问题。
参考文献:
[] - Santanu Pattanayak .Pro Deep Learning with TensorFlow: A Mathematical Approach to Advanced Artificial Intelligence in Python Paperback. Dec 7, 2017

 浙公网安备 33010602011771号
浙公网安备 33010602011771号