

Feature Extractor[SENet]
0.背景
这个模型是《Deep Learning高质量》群里的牛津大神Weidi Xie在介绍他们的VGG face2时候,看到对应的论文《VGGFace2: A dataset for recognising faces across pose and age》中对比实验涉及到的SENet,其结果比ResNet-50还好,所以也学习学习。
github上的SENet
CNN是通过用局部感受野,基于逐通道基础上,去融合空间信息来提取信息化的特征,对于图像这种数据来说很成功。不过,为了增强CNN模型的表征能力,许多现有的工作主要用在增强空间编码上,比如ResNet,DenseNet。
Jie Hu等人(momenta公司,很厉害的一公司)另辟蹊径,主要关注通道上可做点。为了与这些基于增强空间编码的方法对比,通过引入一个新的结构单元,称之为“挤压和激励模块”(Squeeze-and-Excitation),就是通过显示的对卷积层特征之间的通道相关性进行建模来提升模型的表征能力;并以此提出了特征重校准机制:通过使用全局信息去选择性的增强可信息化的特征并同时压缩那些无用的特征。
1.SE构建块
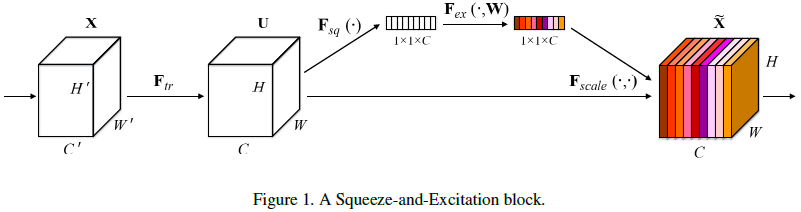
图1.1 SE模块结构图
如图1.1所示,其实SE网络就是通过不断的堆叠这个SE模块而成的网络,就如
- Googlenet是基于Inception模块;
- ResNet 网络是基于ResNet模块:
- DenseNet是基于DenseNet模块一样。
从图1.1中,假设张量\(X\in R^{W'\times H'\times C'}\),卷积操作为\(F_{tr}\),从而得到新的张量\(U\in R^{W\times H\times C}\)。到这里都是传统的卷积过程而已,然后基于\(U\),接下来开始挤压和激励:
- 挤压:将\(U\)固定通道维度不变,对每个feature map进行处理,从而得到一个基于通道的描述符\(1\times 1\times C\),即用一个标量来描述一个map;
如图1.2所示,作者提出的所谓挤压就是针对每个通道的feature map,进行一次GAP(全局平均池化):
即将这个feature map表示的矩阵所有值相加,求其平均值
- 激励:(个人觉得有点attention的意思),将挤压得到的通道描述符\(1\times 1\times C\)作为每个通道的权重,基于\(U\)重新生成一个\(\widetilde{X}\).
如图1.2所示,就是先对挤压后得到的\(1\times 1\times C\)的向量基础上先进行一次FC层转换,然后用ReLU激活函数层,然后在FC层转换,接着采用sigmoid激活函数层,该层就是为了模仿LSTM中门的概念,通过这个来控制信息的流通量
其中,\(\delta\)是ReLU函数,\(W_1\in R^{\frac{C}{r}\times C}\),\(W_2\in R^{C\times \frac{C}{r}}\),为了限制模型的复杂程度并且增加泛化性,就通过两层FC层围绕一个非线性映射来形成一个"瓶颈",其中\(r\)作者选了16,最后在得到了所谓的门之后,只要简单的将每个通道的门去乘以原来对应的每个feature map,就能控制每个feature map的信息流通量了
从上述描述就可以看出,这其实算是一个构建网络块的方法,可以应用到inception和resnet等网络上,从而具有普适性,如图1.2所示.
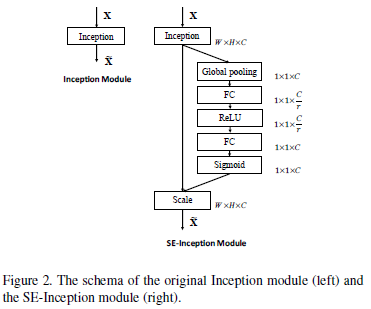
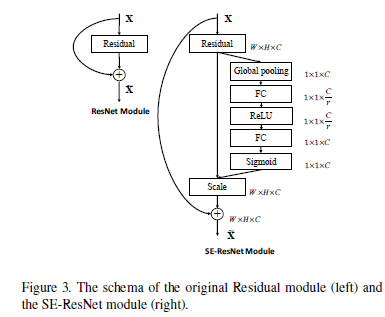
图1.2 将SE方法用在Inception模块和ResNet模块上的改进对比图
在后续的实验中,作者也发现了SE机制可以在网络的不同层上自适应对应所扮演的角色,例如:
- 泛化性:在较低的层上,它可以学习去激励可信息化的特征,从而加强较低层级表征的信息共享质量;
- 具像性:在较高的层上,SE模块变得越来越具体化,对不同的输入有高度的具体类别响应。
所以,通过SE模块进行特征重校准的好处是可以基于整个网络不断的累加下去。
2. 实验结果
通过将SE模块这个概念用在Inception、ResNet、ResNeXt(见最下面参考文献)、Inception-ResNet-V2等模块上,就能很简单快速的得到对应的改变模型,如图1.2(只有inception和resnet对应模块)。当然引入了新的部分,在所需要的浮点数操作、计算时间以及参数量上就有负担了,通过对ResNet-50进行对比:
- 对于浮点数操作来说,基于\(224*224\)大小的输入基础上,一次前向传播,ResNet-50大致需要3.86 GFlops,而SE-ResNet-50大致需要3.87GFlops;
- 对于所需要时间来说,假设minibatch为256,图片大小还是\(224*224\)则ResNet-50需要164ms,而SE-Resnet
-50大致需要167ms;- 对于额外的参数量,也就是通过两个FC层引入的参数量\(\frac{2}{r}\sum^S_{s=1}N_s\cdot C^2_s\),假设r=16,则ResNet-50需要大致25百万的参数量;而SE-ResNet-50大致需要额外增加2.5百万的参数量。
综上所述,增加的负担还是不大的。
下面po下具体的模型结构和对应的结果
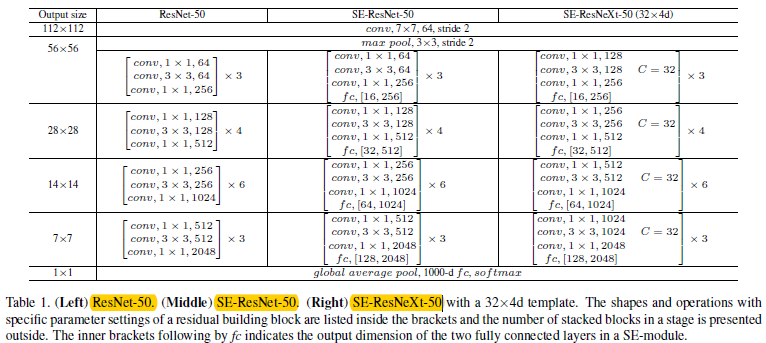
图2.1 ResNet-50,SE-ResNet-50,SE-ResNeXt-50的结构图
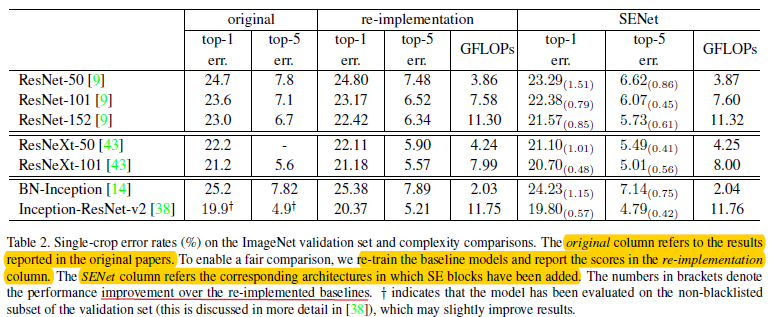
图2.2 不同模型下的结果对比
2.1. r的值的影响
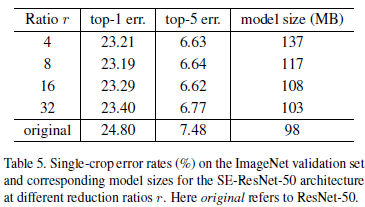
图2.1.1 不同r的值的结果
2.2 基于imagenet数据集上的结果

图2.2.1 不同模型在imagenet下的结果,其中SENet是SE-ResNeXt
2.3 不同层下SE的表现
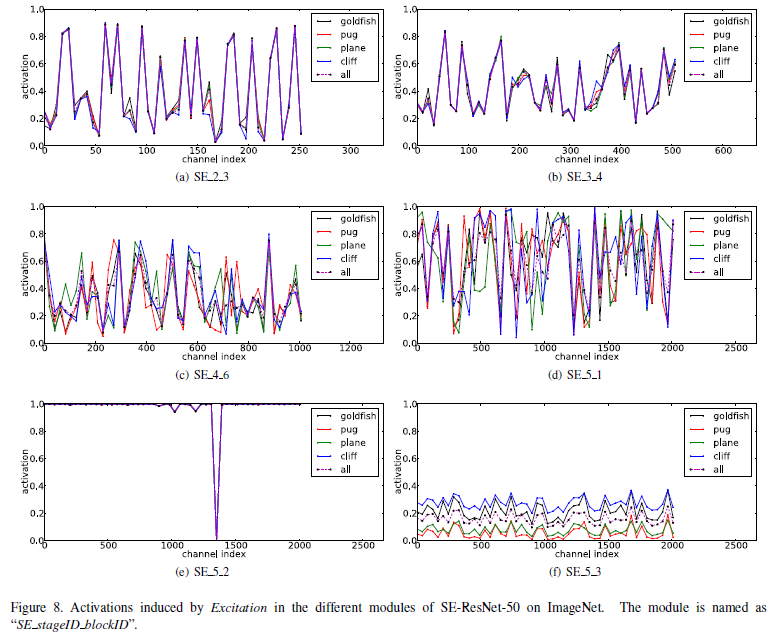
图2.3.1 不同层下SE的作用
如图2.3.1所示,在较低层上,SE的表现是让信息更有共享性,不同类型下,该层的神经元激活值基本相同,即泛化性;而到了高层,越来越趋向于分开不同的类别,不同类型下,该层的神经元激活值明显不同,即具像性。
参考文献:
[ResNeXt] - S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017.

