

Recurrent Neural Network[SRU]
0.背景
对于如机器翻译、语言模型、观点挖掘、问答系统等都依赖于RNN模型,而序列的前后依赖导致RNN并行化较为困难,所以其计算速度远没有CNN那么快。即使不管训练的耗时程度,部署时候只要模型稍微大点,实时性也会受到影响。
Tao Lei等人基于对LSTM、GRU等模型的研究,提出了SRU模型。在保证速度的前提下,准确度也是没有多少损失。
1.SRU
Tao Lei等人通过将每一时间步的主要计算部分,优化为不要去依赖之前时间步的完整计算,从而能够容易的并行化。其结果示意图如图1.1。

图1.1 普通的RNN结构和SRU结构
大多数RNN模型如LSTM,GRU等都是通过门来控制信息流的传输,从而缓解梯度消失和爆炸的问题。
ps:其中所谓的门就是将输入向量连接到一个门层(向量),然后以sigmoid激活函数来计算当前的可流通量(通俗点说,就是得到一个sigmoid的值向量,去与所需要的其他状态向量逐点相乘,即每个维度上都有门控制)
在前馈神经网络中,特别是矩阵相乘是最耗时的部分了,而如果是两个矩阵逐点相乘,那计算量倒是少了好多。所以SRU的主要设计原理就是:门计算只依赖于当前输入的循环。这样就使得模型只有逐点矩阵相乘的计算是依赖于之前的时间步的。从而能够让网络容易的进行并行化。
我们基于参考文献[1]来进行对应的结构展示:

图1.2基础组件
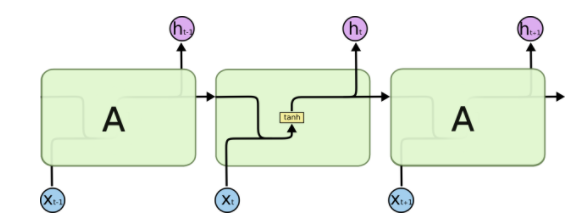
图1.3 标准RNN结构图
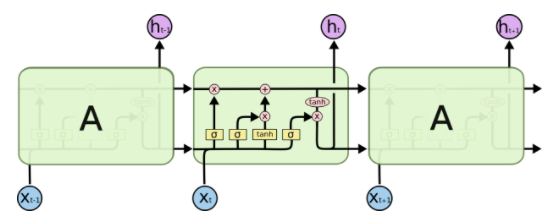
图1.4 LSTM结构图
现在主流的RNN结构都会在当前时间步上用到上一个时间步的隐藏层输出\(h_{t-1}\)。例如在LSTM中,遗忘门的计算\(f_t=\sigma(W_fx_t+R_fh_{t-1}+b_f)\)。其中涉及到的\(Rh_{t-1}\)就破坏了独立性和并行性。这样相似性的设计在GRU和其他RNN变种中都能找到。而SRU的设计是完全丢弃了当前时间步门的计算会依赖之前时间步的\(h_{t-1}\),\(c_{t-1}\)。所以现在的计算瓶颈是图1.5中式子1-3中的三个矩阵相乘了。在计算完\(\widetilde{x_t},f_t,r_t\)之后,剩下的就是逐点计算了,这时候就很快了。
SRU完整的公式如下:
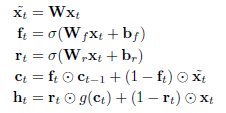
图1.5 SRU结构公式
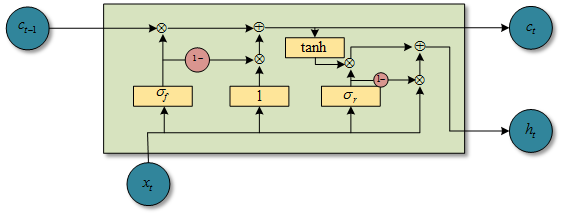
图1.6 SRU结构图(自己用visio画的)
2. SRU工程优化
优化SRU和在cuDNN LSTM中优化LSTM的套路差不多,其中主要涉及到2点:
- 所有时间步的矩阵相乘可以批次处理,这可以明显提升计算效率和GPU的使用。如将图1.5中的式子1-3的三个权重矩阵合并成一个大矩阵。如下:
其中n表示序列的长度,是将n个输入向量联合起来,即每个\(x_i\)都是一个向量,\(U\in R^{n \times 3d}\),d表示SRU模块中的隐藏层维度,当输入是一个mini-batch为k个序列的时候,U就是一个size为\((n,k,3d)\)的张量;
- 所有逐元素相乘的操作都可以放入一个kernel函数(cuda中的一个术语)中。如果不这么做。那么加法和sigmoid的激活函数就会分别需要调用各自独立的函数,并且增加额外的kernel运行延迟和数据移动的开销(这些都和gpu的计算有关,感兴趣的可以学习cuda)。
下面就是kernel函数的伪代码(CUDA的),其中省略了输入向量\(x_i\)本身的维度,只涉及到序列的长度,mini-batch的大小和SRU模块中隐藏层的维度:

图2.1 kernel函数伪代码
#python形式的cuda伪代码,因为gpu编程的特性,所以都是基于标量进行具体的操作的
def kernel(xTensor, UTensor, bFVector, bRVector, c0Matrix):
#xTensor:tensor for input, size is (n, k, d), means sequenceLength by minibatch by hiddenState
#UTensor:tensor for weight, size is (n, k, 3d) means sequenceLength by minibatch by [W,Wf,Wr],3d
#bFVector:vector for forget bias, size is (1,d)
#bRVector:vector for reset bias, size is (1,d)
#c0Matrix: matrix for SRU state,size is (k,d) means minibatch by hiddenState
h, c = np.zeros([n,k,d]), np.zeros([n,k,d])
#one sample in minibatch
for i in range(1,k):
#one dimension in
for j in range(1,d):
c = c0Matrix[i,j]
for l in range(1,n):
W, Wf, Wr = UTensor[l,i,j], UTensor[l,i,j+d], UTensor[l,i,j+2d]
f = sigmoid(Wf+bFVector[j])
r = sigmoid(Wr+bRVector[j])
c = f*c+(1-f)*W
h = f*tanh(c)+(1-r)*xTensor[l,i,j]
c[l,i,j] = c
h[l,i,j] = h
return h,c
如上面所示,通过GPU的网格等多线程操作,在外面2个for可以实现并行操作,最内部的for是基于序列顺序的,也就是在实现的时候,只有这个维度上是需要前后关联的,而在minibatch这个维度和hiddenState这个维度都可以分开,也就是都可以并行,只有sequence维度需要前后管理啊,那么这个维度放入寄存器中保持先后关系即可,而minibatch和hiddenState这两个维度可以看成是网格的x,y轴。
这就是矩阵逐元素相乘比矩阵相乘块的好处:gpu特喜欢这种逐元素相乘的;对矩阵相乘的,如果矩阵大了,还需要做分块处理。
通过如图2.2的结构设计,在实验上,可以发现速度还是有很可观的提升的。
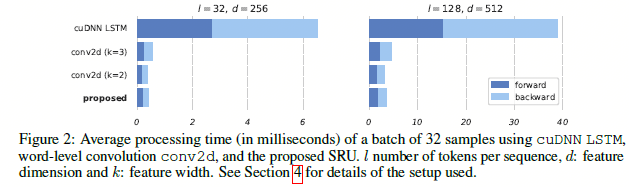
图2.2 SRU与其他模型的结果对比
参考文献:

