
object detection[rfcn]
0 - 背景
从rcnn,spp,fast rcnn, faster rcnn,yolo,ssd,这里又有个新模型叫rfcn,即Region-based Fully Convolutional Networks,R-FCN。虽然其比yolo,ssd出来的晚,不过看模型结构,更多的是针对faster rcnn的一个改进。
一路走来,不同模型都是为了解决不同的痛点而提出的:
- rcnn证明了cnn提取的特征的有效性;
- 而spp解决了如何应对不同尺度feature map的问题;
- fast rcnn通过roi pooling将需要应用到多个候选框上的基CNN模型进行共享,加快了速度并且提升了准确度;
- 而faster rcnn为了更进一步的共享基CNN,将本来需要由SS算法提取候选框的任务一并放入基CNN中,从而提出了RPN子网络;
那么问题来了,fast rcnn发明的ROI pooling中间是由全连接层存在,从而将前面的ROIpooling后的feature map 映射成两个部分(对象分类,坐标回归);而越来越多的基CNN,如googlenet,resnet等全卷积网络证明了不要全链接层,效果不但更好,而且能适应不同尺度的图片无压力。本着解决下一个痛点的原则,rfcn应运而生。
1 - rfcn
我们可以说rfcn是基于faster rcnn的基础上对roi pooling这部分进行了改进。那么我们为了消灭fast rcnn的roi pooling中的全连接层的最naive的想法自然就是丢弃全连接层(起到了融合特征和特征映射的作用),直接将roi pooling的生成的feature map 连接到最后的分类和回归层即可。不过作者们通过做实验发现,这样的结果导致的对象检测结果很差,并且受到《Deep residual learning for image recognition》的启发,认为这主要是:基CNN本身是对图像分类设计的,具有图像移动不敏感性;而对象检测领域却是图像移动敏感的,所以二者之间产生了矛盾。从而对roi pooling进行了很神奇的设计

图1.1 rfcn结构图
如图1.1所示,网络的第一印象,结构大体和faster rcnn很像,都是有个RPN子网络用来训练并生成一堆基于当前图像的对象候选框,而ROI Pooling 就不一样。
2 - 改进的ROI Pooling
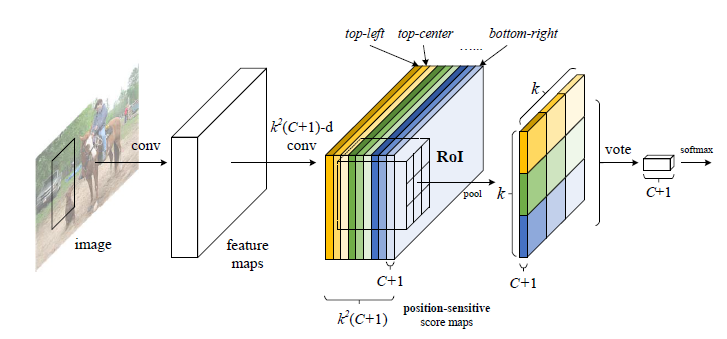
图2.1 rfcn中ROI Pooling结构图
如图2.1所示,假设图像经过了基CNN,到达了最后一层feature maps,接下来就是如fast rcnn中一样,提取当前feature map的ROI区域了,然而rfcn不是直接这么干。这里我们设计一个位置敏感的ROI Pooling:将fast rcnn中的ROI 划分成\(k*k\)大小,即图片中本来获取的ROI区域,将其分成\(k*k\)个区域(这里k=3,即分成9个部分)。假设该数据集一共由\(C\)类,那么再加个背景类,一共是\(C+1\)类。我们希望对每个类别都有各自的位置感应。
所以我们要设计的位置敏感得分map如图2.1中position-sensitive score maps(即从之前基CNN的feature maps,假设有n个通道,通过一样的卷积连接结构生成当前的相同大小map且有\(k^2(C+1)通道的位置敏感得分maps\))。就是几个大色块并列的部分:每个色块表示对对象的特定位置进行敏感,而且每个色块大小中有\(C+1\)个map,所以该区域一共有\(k^2(C+1)\)个map,其中每个map的大小和之前那个基CNN的feature map大小一致。
那么接下来就需要介绍具体的怎么从position-sensitive score maps得到图2.1中右边那个\(k*k\)大小,通道为\(C+1\)的map了。
这里就不贴论文公式了,我们以图解释
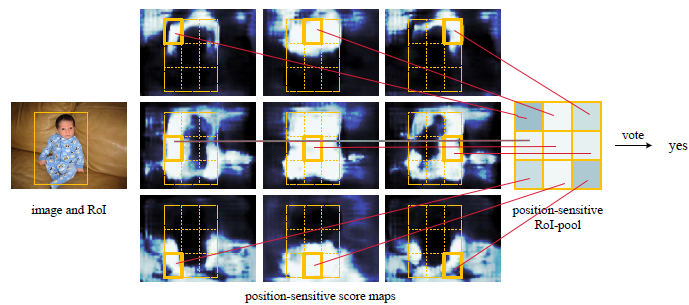
图2.2,从位置敏感得分map到位置敏感ROI pooling
2.1 ROI区域的分类
图2.2是在一个类别下而不是\(C+1\)个类别同时进行。假设我们图2.1的位置敏感map中\(k=3\),那么当前一共有:
| ___________________ | ___________________ | ___________________ |
|---|---|---|
| \(cls_1\{1,2,3,...,C+1\}\) | \(cls_2\{1,2,3,...,C+1\}\) | \(cls_3\{1,2,3,...,C+1\}\) |
| \(cls_4\{1,2,3,...,C+1\}\) | \(cls_5\{1,2,3,...,C+1\}\) | \(cls_6\{1,2,3,...,C+1\}\) |
| \(cls_7\{1,2,3,...,C+1\}\) | \(cls_8\{1,2,3,...,C+1\}\) | \(cls_9\{1,2,3,...,C+1\}\) |
这么9个不同颜色的feature maps,其中每个feature maps中都有\(C+1\)个feature map。
| _______ | _______ | _______ |
|---|---|---|
| 左上 | 中上 | 右上 |
| 左中 | 中间 | 右中 |
| 左下 | 中下 | 右下 |
上述为划分成\(k*k\),且\(k=3\)情况下的位置对应关系
| _______ | _______ | _______ |
|---|---|---|
| \(cls_1\{1\}\) | \(cls_2\{1\}\) | \(cls_3\{1\}\) |
| \(cls_4\{1\}\) | \(cls_5\{1\}\) | \(cls_6\{1\}\) |
| \(cls_7\{1\}\) | \(cls_8\{1\}\) | \(cls_9\{1\}\) |
- 1 - 首先处理类别为1的部分,即如上面表格所示:
- 2 - 如图2.2中,就是这抽取出来的9个feature map,然后如图2.2所示,对每个feature map按照各自敏感的区域,将其框出来:比如在这9个feature map中第一个表示左上位置,那么提取这个feature map的ROI区域,然后将其分成\(k*k\)的网格,提取其表示的左上位置,即第一个网格;同理第二个表示中上的feature map提取其\(k*k\)的网格中第二个网格,因为当前feature map表示的是中上位置,当前map的第二个网格也表示中上位置;
- 3 - 对抽取出来的部分进行求均值,然后按照位置组成一个\(k*k\),即\(3*3\)大小的矩阵;
- 4 - 对这个\(k*k\)大小的矩阵求和,得到一个值。
- 5 - 对类别\(2\sim (C+1)\)分别进行步骤1-4的操作,从而最终得到一个\(1*(C+1)\)这样的向量(如图2.1),将这个向量进行softmax,从而估计当前feature map对应的ROI区域是什么类别
2.2 ROI区域的回归
上面说到了从基CNN的feature map得到ROI pooling直到softmax的分类,这里接着说如何微调ROI本身的区域,这部分与分类其实很相似:
| ______________ | ______________ | ______________ |
|---|---|---|
| \(reg_1\{x,y,w,h\}\) | \(reg_2\{x,y,w,h\}\) | \(reg_3\{x,y,w,h\}\) |
| \(reg_4\{x,y,w,h\}\) | \(reg_5\{x,y,w,h\}\) | \(reg_6\{x,y,w,h\}\) |
| \(reg_7\{x,y,w,h\}\) | \(reg_8\{x,y,w,h\}\) | \(reg_9\{x,y,w,h\}\) |
- 1 - 如图2.1的位置敏感maps是有\(k^2(C+1)\)个通道的,我们依然从基CNN的feature map部分连接出一个\(4k^2\)通道的maps(与位置敏感maps并列),用来做候选框坐标微调,如上面表格所示;
- 2 - 如分类部分的步骤1-4一样的操作,最后得到一个\(1*4\)的向量,即\(x,y,w,h\)
- 3 - 按照之前的那些模型一样去计算目标函数即可
问题
问:为什么需要做如图2.2这种特定map的特定区域的选取,而不是直接在特定map上将整个ROI区域都选取?
答:将k设为1就行了,就是整个ROI选取,作者做过实验的,效果不好。

