

【原创】Linux环境下的图形系统和AMD R600显卡编程(9)——R600显卡的3D引擎和图形流水线
1. R600 3D引擎
R600核心是AMD一款非常重要的GPU核心,这个核心引入了统一处理器架构,其寄存器和指令集同以前的GPU 都完全不同,对其编程也有比较大的区别。
图1显示了R600 GPU 核心的硬件逻辑图,R600 GPU 包含并行数据处理阵列(DPP array)、命令处理器、内存控制器以及其他逻辑部件,R600的命令处理器读取驱动编写命令并解析命令,R600还要将硬件产生的“软中断”发送给CPU。R600的内存控制器能够访问R600 GPU核上的所有内存(VRAM内存,或者称本地内存)以及用户配置的系统内存(GTT内存),为了满足GPU 读写的需要,R600 GPU还要完成DMA控制器的功能。
CPU上运行的程序不能够直接写R600 GPU的本地内存,但是CPU程序能够命令R600将数据或者程序拷贝到R600 本地内存或者从本地内存拷贝数据到系统内存上。完整的能够在R600上运行的程序包含两个部分:一部分是在主机(CPU)上运行的程序,一部分是在R600处理器上运行的程序,处理图形应用时这部分程序称为Shader 程序,进行GPU 通用计算时,这部分程序称为Kernel 程序。
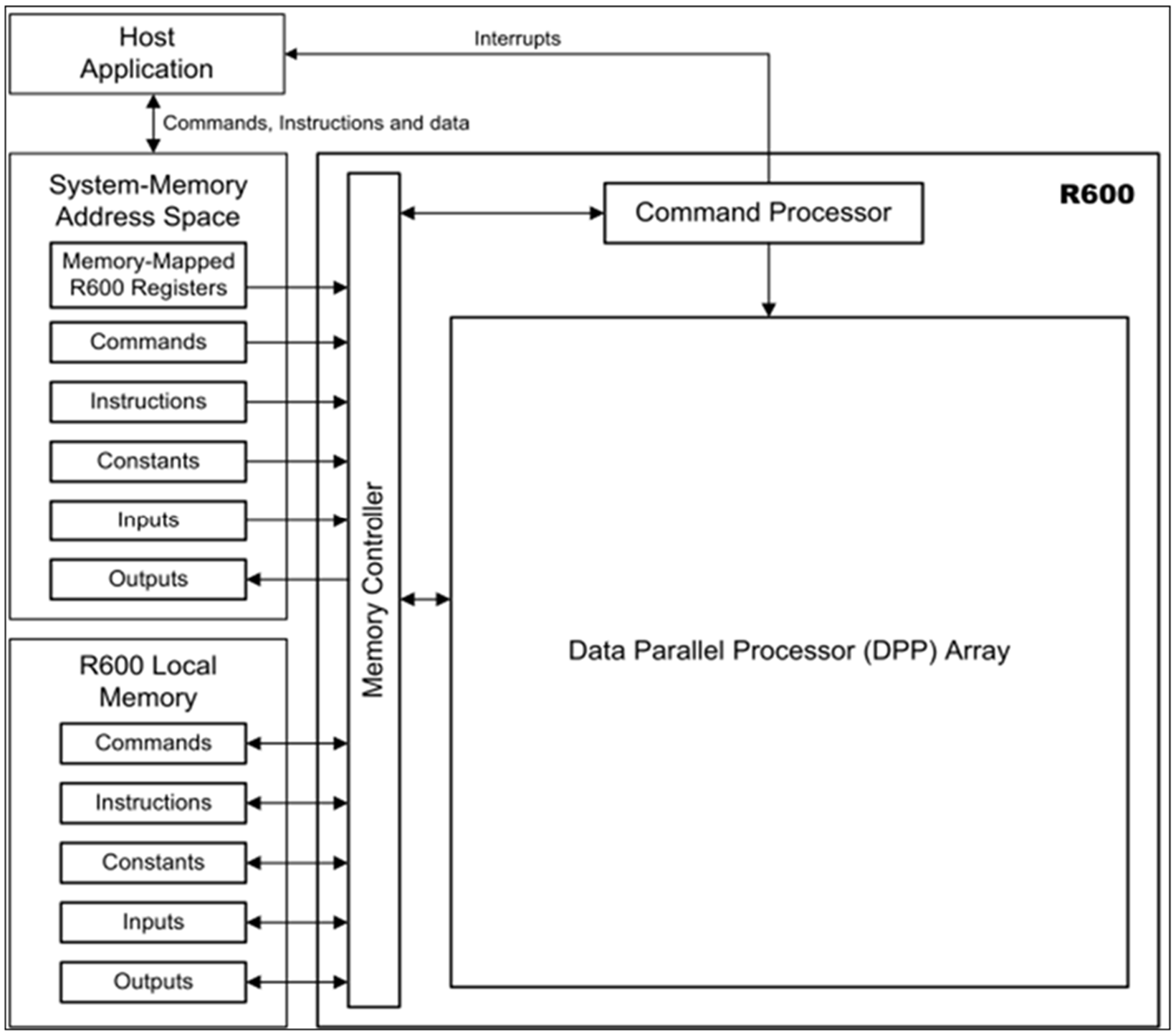
图1
本节内容全部来自AMD手册“R600 Instruction Set Architecture”。
2. R600 图形流水线
本节内容来自文档“Radeon R6xx/R7xx Acceleration”,阅读这篇文档之前,读者最好了解过3D图形流水线。
输入数据大体上按照“顶点处理”、“图元组装”、“光栅化”、“片段处理”、“输出”的过程流经图形硬件,在Shader Model 4.0中加入了Geometry shader和Tesselation shader,这两部分暂时不予以考虑。图2是AMD R600的图形流水线:

图2
命令处理
命令处理器阶段处理环形命令缓冲区和间接缓冲区中的命令流,命令处理器处理这些命令流的时候通常会产生一系列的写寄存器活动(后面会讨论一些寄存器的读写问题,有些寄存器只能使用命令流的形式写,而且无法读)。驱动设置好index buffer(GTT内存)并将index buffer告知硬件,被命令触发后,“顶点组装和细分器(vertex grouper and tesselator, VGT)”根据index buffer的地址将索引数据DMA到SPI (shader pipe interpolator,将为shader分配资源)上,同时将图元的连接信息发送给“图元组装器”(primitive assembly)。
顶点处理
所有的着色处理(shader processing,也即GPU核上进行的各种运算)都是在统一着色器块(unified shader block)中进行的,统一着色器块包含Sequencer (SQ,控制shader运行)和Shader pipe(SP)模块,每一个shader程序都能够访问一些通用寄存器,这些通用寄存器是在shader 程序运行之前(由SPI)动态分配的,SPI会往这些寄存器中加载合适的参数,这些参数包括顶点数据的基地址。然后SPI会为SQ启动程序执行过程,shader程序需要做的第一件事情就是取顶点数据,然后针对这个顶点运行shader程序,顶点处理shader的输出被放置到“着色器输出缓存”(shader export,SX)中(由于pixel 处理过程和vertex处理过程在同样的硬件上运行,所以pixel shader的输出也是放到SX 中),R600的顶点处理过程的输出包含两部分:Position Cache 放置顶点的坐标信息,Parameter Cache放置顶点的其他属性信息。
在没有Geometry shader的情况下,顶点数据的处理按照下面流程进行:
- VGT获取到一个指向index buffer的指针,VGT 遍历所有的索引并一个个发送到SPI 里面
- SPI将其输入缓存中的索引数据组成称为wavefront的向量(wavefront最多64个顶点)
- 当wavefront准备好后,SPI根据驱动提供的大小(驱动向 SQ_PGM_RESOURCE_VS 寄存器写入的)分配GPR(通用寄存器,所有的通用寄存器都是32*4=128bit的,可以存放一个四维的浮点数向量)和线程空间(thread space),然后这些索引被放入到GPR中(GPR 的id 是由谁指定的),shader core 被通知一个新的wavefront 准备好了;
- Shader core对Wavefront上的每个顶点运行顶点处理程序
- 顶点处理器根据GRP中的索引取出顶点数据(使用fetch指令或者单独的fetch程序)
- 顶点数据被取到GPR中
- Shader程序的其他部分继续运行
- Shader程序在SX的position Cache中分配空间,并将顶点的坐标信息(XYZW)输出到这片空间
- Shader程序在SX的Parameter cache中分配空间,将顶点的其他属性信息(颜色,纹理)发送到这片空间,程序退出
- SPI被告知一个wavefront的所有顶点处理完毕,SPI释放掉GPR
配置好渲染状态后,除了第4步外,上面的过程对用户(驱动程序)来说是透明的,第4步是按照用户编写的shader的程序的流程执行的。
片段处理
顶点处理完成后,顶点数据被发送到“图元组装器”(PA)中进行图元组装(注意到过程1已经将顶点连接信息发送给了图元组装器),PA的输出被发送给“扫描转换器”(scan convert,SC)进行扫描转换(光栅化过程,差值计算),SC会检查“深度缓存”(Depth buffer,DB)确定片段的可用性,这个检查过程会进行Early Z、Re-Z和HiZ处理(可以这么理解,SC 检查z buffer,如果片段的深度值比depth buffer 中的值还要大,则该片段被遮挡,在没有开启blending的情况下,这个片段可以扔掉,后续就不用处理了,如果开启了blending 的,则还要进行后续处理)。光栅化出来的片段被发送给SPI,再进入到shader core 里面进行最后的片段处理。片段处理器会进行取纹理、ALU计算以及内存读写操作。完成后,片段的几何信息(在屏幕坐标系中的坐标以及深度值)和颜色信息通过SX (vertex shader也会输出到SX中)发送到DB和CB中进行最后的处理。
顶点数据经过顶点处理流程后,进入光栅化阶段,由Scan Converter对各属性数据进行差值,形成片段数据,片段数据流经片段处理阶段着色,形成可选的像素(或者称为片段 fragment)。
由于R600是统一处理器架构,顶点处理和片段处理都在同样的硬件上进行,因此片段处理的过程和顶点处理的过程是类似的。R600片段处理阶段(包括光栅化阶段)按照如下流程进行:
- “图元组装器”(PA)从SX的position buffer中读出顶点的坐标信息,从VGT中读取出顶点连接信息,有了这两方面的信息后,就可以组装出图元;
- 组装出来的图元被发送到SC进行初步的扫描转换;(初步的扫描转换做了些什么工作,将大图元分成小的块tile)
- 初步扫描转换出来的块(tiles,有合适的翻译??)被送到SPI中进行最后的插值
- SPI分配GPR和线程空间(thread space)(根据驱动指定的大小);
- SC和SPI从SX的parameter cache中读取顶点的属性数据;
- SPI针对顶点属性计算出插值出来的每个像素的属性
- 将插值后的属性加载到GPR
- Shader core被告知一个pixel wavefront到来,准备执行pixel shader
- Shader core对wavefront里面的每一个片段运行pixel shader,pixel shader的结束部分包含将片段属性(颜色)输出到SX 的指令
- SPI被告知wavefront里面的所有片段处理完成,SPI释放GPR和线程空间
Pixel shader程序将计算的结果输出到SX后将会被送往指定的Render Target,可以一次最多配置8个Render Target。
最后的渲染
Pixel shader的输出被放到DB和CB中进行最后的处理(对应图1、图2和图3中的raseter operation 和merging 过程),这部分处理包括alpha 测试、深度测试和最后的融合(blending)。


