

一个无锁消息队列引发的血案(五)——RingQueue(中) 休眠的艺术
目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
开篇
这几天研究了一下 disruptor .Net版,由于.Net版跟进不及时,网上只有 v2.10 版。没仔细研究,但可以肯定的是跟最新的Java版 disruptor 3.30 是有不少区别的。我也用这个 2.10 的.Net版本写了跟我们的问题相似的测试程序,得到的结果跟 Java 版的 disruptor 3.30 差不多。我还下载了 C++ 版的,不过看了一下,就扔一旁了,一个原因是版本太低,另一个原因是动不动就 boost,动不动就C++11,我是崇尚轻便、依赖小的,真要用我还不如自己写一个,所以我也懒得用他们来测,我已经在着手把 disruptor 3.3 的原理搬到 C++ 上来。
为了方便,我把修改的 disruptor .Net 版上传到了github:https://github.com/shines77/Disruptor.Net,其中 VS2013-Net 4.5 是VS 2013使用 .Net Framework 4.5的版本,因为原版使用的是 .Net 4.0,但升级到 4.5 某些文件要修改一下,所以分成了两个版本。经过我的调整,.Net 4.5的版本更细致一些,x64 和 x86 是严格分开的,本质上并没有大的区别。disruptor .Net 2.10 原版的 github 地址是:https://github.com/disruptor-net/Disruptor-net。如果你不想下载完整的项目,也可以在这里 nPnCRingQueueTest.cs 查看测试代码,在 RingQueue\disruptor\csharp 目录下面。
RingQueue
我们先来看 RingQueue,在上一篇里其实有些 RingQueue 测试的截图,不知道有没有细心的读者发现谁快谁慢,快多少?我们来看一下截图:
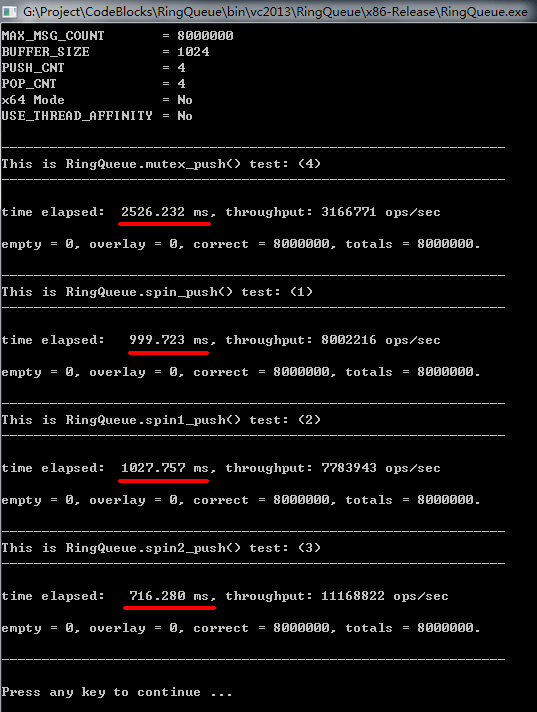
我们可以看到,混合自旋锁 spin2_push() 最快,而使用操作系统的互斥锁版本 mutex_push() 最慢,前者是后者的 3.5 倍左右。
经过多次测试我们发现,其实 spin_push(),spin1_push(),spin2_push() 速度差不多,但 spin2_push() 相对稳定一些,由于多线程程序受影响的因素很多,所以实际测试的时候,会发现每次结果都不太一样,但总体来看,spin2_push() 是里面最稳定的。
那么,我们来看看 q3.h 的测试结果:

我们发现,q3.h 比 操作系统的互斥锁版本还要慢一些,细心的读者肯定会问,为什么 q3.h 测试的时候只用了4个线程?而前面却用了8个线程。这是由于 q3.h 本身代码的限制,当总线程数大于实际CPU核心数时会很慢很慢,因为我的CPU是4核的,所以它只能用 PUSH_CNT = 2, POP_CNT = 2 来测试,实际上,即使前面那些测试也用2个 push 线程和2个 pop 线程,结果还是要比 q3.h 快的,有兴趣的朋友可以自己试一下。此外,q3.h 通过修改是可以解决这个限制的,这是后话。
综上可得,我们的混合自旋锁 spin2_push() 的效率还是不错的,是 q3.h 的 4.18 倍左右,spin2_push() 的实际用时的最小值其实比 716 毫秒要小很多,甚至最快的时候可以达到 580 毫秒左右。
这里重新说明一下我的测试环境:
CPU: Intel Q8200 2.4G / 4核
系统: Windows 7 sp1 / 64bit
内存: 4G / DDR2 1066 (双通道)
编译平台: Visual Studio 2013 Ultimate update 2 (自带的 cl.exe)
以上的结果都是在 x86 模式下测得的(64位系统是兼容x86模式的),由于 x64 模式下 Sleep(1) 效率有问题,这将导致系统互斥锁版本变得非常慢(要十几秒或几十秒),估计系统互斥锁也用了类似 Sleep(1) 的代码。我们用到了 Sleep(1) 代码的 spin_push(),spin1_push(),spin2_push() 也会受一点影响,不过影响很小很小。至于为什么会这样还不太清楚,所以没用 x64 模式来测。
spin2_push()
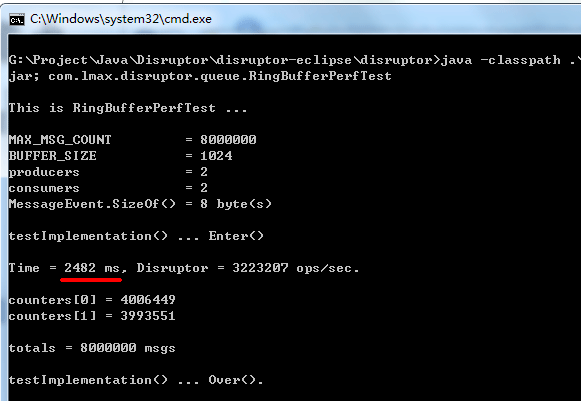
为什么 spin2_push() 这么快呢?通过这些天的研究和比较,我分别测试了 Java 版的 disruptor 3.30 和 .Net 版的 disruptor 2.10,下面给出两者的测试结果:
Java 版的 disruptor 3.30:
.Net 版的 disruptor 2.10:
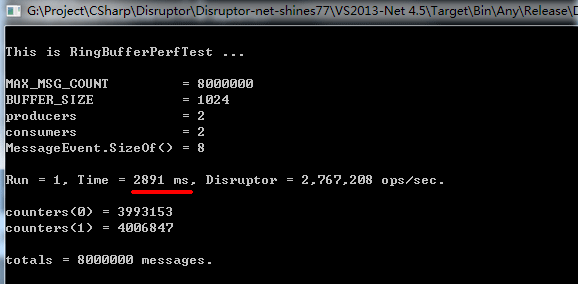
这里你一定想知道为什么 disruptor 这么慢?其实我也很想知道。。。
我们注意到,disruptor 给我们带来了新的视野,多种多样的场景(1P + 1C,1P + 多C,多P + 1C),以及各式各样的消息处理方式,是值得我们学习的一个好东西。尤其是在单生产者或单消费者模式下,是可以简化的,这是我们原来没考虑过的,这里也暂不考虑,我们还是以多生产者+多消费者模式来讨论,因为单生产者或单消费者模式相对简单很多。
disruptor 在单生产者+单消费者(1 producer + 1 comsumer)的时候,还是非常快的,这个时候的确是 lock-free 的,其实此时不仅仅是 lock-free 的,而且还是 wait-free 的,除了队列满了或空了的时候要等待以外(这个每种方法都是必须等待的)。不过,由于 disruptor 并未完全为 1P + 1C 模式特别优化,只是考虑了 1P + 多C,所以其消费者并不是 wait-free 的。虽然 disruptor 的 1P + 1C 模式很快,但其实还可以更快。而实际测试来看,1P + nC 模式(单生产者+多消费者)也不见得快,实测中 2P + 2C 倒是比 1P + 3C 还要快一些,原因不明。
这里可以参考《Disruptor使用指南》一文,disruptor 为我们提供了很多场景,最常用的是 EventHandler,EventHandler 是让每个 EventProcessor 从队列中取出消息并都处理一遍,即消息是被重复处理的,由于我们要实现的是多生产者、多消费者的 FIFO(先入先出)的消息队列,所以 EventHandler 不符合。参考该文的叙述,我们知道只有 WorkerPool + WorkHandler 模式才符合我们的场景:


这里还要指出的一点是,就在写本文的同时,我在看单生产者 SingleProducerSequencer.java 的 publish() 函数时(其中的 cursor 是一个Sequence类),发现:

转到 Sequence.java 里,Sequence::set() 函数定义如下:(其实之前我一直以为 set 就是单纯的一个写入操作而已,而且也不懂 putOrderLong() 具体是什么意思)

通过网上的搜索,我意外的发现,其实 UNSAFE.putOrderedLong(this, VALUE_OFFSET, value); 这个函数内部使用了一个全局自旋锁来保证写入/存储的顺序,可参考《源码剖析之sun.misc.Unsafe》。

不仅仅如此,Java 所有 Unsafe 的原子操作(CompareAndSwap等)里面都使用了这个spinlock,具体可以参考该文。这个spinlock是一个 static 的静态变量,所以所有这些操作都可能会导致一定的自旋,虽然这个自旋等待的时间也许很短很短,但这跟单一的CAS局部循环是不一样的,因为单一的CAS等原子操作只要处理的地址不一样,锁住的 Cache Line 就跟别的地方的原子操作的地址很可能是不一样的,被阻塞而互相影响的可能性比较小。而 spinlock 锁住的是同一条 Cache Line,要阻塞都一起阻塞。不过这个影响很难评估,但至少这不是一个好的做法。
spinlock 的代码是这样的:

所以,不管 disruptor 想出多么好的 lock-free, wait-free 算法,其内部的实现里必然包含了“锁”, 所以永远不可能是“无锁”的。其实在 disruptor 3.30 (Java版) 里,即使是在多生产者+多消费者模式里,disruptor 还真的实现了 lock-free 的方法(如果不算Unsafe 的锁的话),但是多用了一个跟 BUFFER_SIZE 一样大小的数组来记录 Flag,然后每次生产者还要在一个包含所有消费者的序号数组(记录每个消费者已读取的序号)里找出一个最小的来,这个消耗也不见得是很小的,虽然可能会比非 lock-free 的方法要快一些。
至于为什么这么慢,还在进一步研究中,可能有一部分还是跟语言本身有点关系。而且 disruptor 还存在一个问题,就是线程越多越慢,而 spin2_push() 线程越多则越快,不过也有个极限,但是这符合我们常说的线程数最好设置为 CPU总核心数 的两倍左右的经验值。此外,关于 disruptor 我会另外写一篇文章详细讨论。
跟 q3.h 比
我们在第四篇 (四)RingQueue(上) 自旋锁 里面有提到,我们之所以选择自旋锁是因为 q3.h 可以认为是由两个 lock-free 结构和两个 “锁” 构成的,所以我们不妨直接用一个 “自旋锁” 。比如 push(),CAS循环领取序号的时候,所有 push() 线程都会在这上面竞争,竞争主要在 q->head.first 所在的 Cache Line 的被锁而缓存失效的问题,而 head = q->head.first; tail = q->tail.second; 也会受其他地方写入该值时导致缓存失效。然后是确认提交成功后的序列化过程,这个过程是一个真正的“锁”,会导致别的线程被阻塞。而且 q3.h 的失误就在于没在这个地方做合理的休眠,这就导致了当总的线程数超过核心数的时候,某个线程阻塞了别的线程,而这个线程又得不到时间片,从而导致livelock,虽然最终该线程还是可以获得时间片,但是其他线程已经白白的等了很久了,而且没有休眠,CPU占用一直是很高的,整个过程又很慢。所以解决这个问题,就是在这个“锁”的过程中,适当的自旋、yield()或休眠一下。这个“锁”本身不会造成缓存行失效,但是如果 q->head.second 被写入新值的时候,还是会导致伪共享(False Sharing)的问题。同理,pop() 的分析也类似。这里跟 spin2_push() 来比的话,有点是产生竞争的线程数少了一半(假设生产者和消费者线程是一样多的),缺点是竞争的点多了,自旋锁竞争的点只有一个,就是锁的循环上,只要进了锁,由于只有一个线程能获得写入和读取的权力,此时对RingBuffer内部的操作并不会产生伪共享(False Sharing)问题,因为“一夫当关,万夫莫开”。
q3.h 的另一个问题是,在第三篇文章里也说过了,就是 head.first,head.second,tail.first,tail.second 四个变量应该在 4 条不同的Cache Line(缓存行)上,以减少缓存失效的问题(即伪共享)。这点 disruptor 是做得很好的,也许 q3.h 解决了这些毛病以后会快一点,但不知道会快多少,以后有时间我会加进去试一下,不过肯定是比 disruptor 现在的版本改成 C++ 是要慢的,这可以肯定。
spin2_push()
那么,现在我们来看看我们的混合自旋锁 spin2_push(),可查阅 RingQueue.h 中的 spin2_push_() 函数:
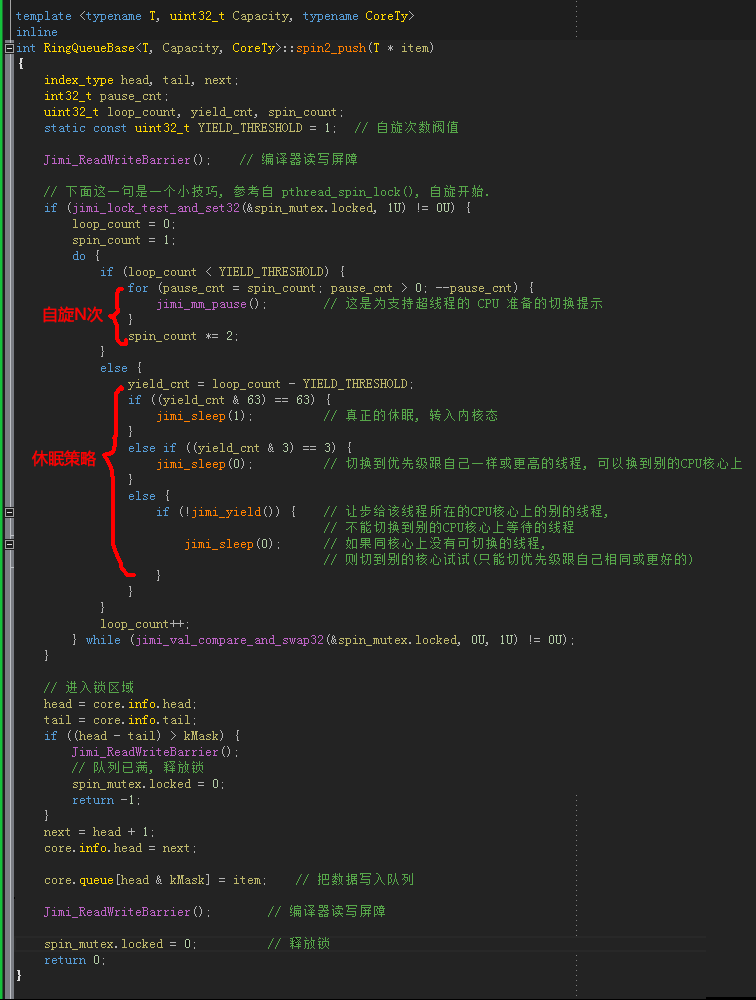
在上一篇的末尾,我提到了 Thread.Yield(),yield 是让步、低头、出让的意思,也就是说把CPU的主动权交给别的线程。前面也说到 DengHe.Net (老邓) 曾经贴过的用反射工具查看的 C# 源码,其实不是 Thread.Yield(),而应该是 System.Threading 下面的 SpinWait() 类。这里注意,不是 Thread.SpinWait(n),Thread.SpinWait(n) 其实是一个自旋 n 次的循环,而 Thread.Yield() 被定义为 Windows API SwitchToThread(),spin2_push() 里面的 jimi_yield() 在 Windows 上就是定义为 SwitchToThread(),该函数是一个很特殊的函数,在上图的 jimi_yield() 的注释里我已经写了,它的功能是让步给该线程所在的CPU核心上的别的等待线程(但不能切换到别的CPU核心上的等待线程),后面我们也会详细讨论。
而我们提到的 SpinWait() 类则跟我们这个 spin2_push() 长得很像,其实我们是模仿它的。SpinWait.cs 的源码可以在网上查到,我已经上传至 github 上:SpinWait.cs,在 RingQueue 项目里的 \douban 目录下面。
我们来看一下 SpinWait.cs 长什么样子?我们来看两个比较重要的地方:

还有 SpinOne() :

你可以看到,我对 SpinOne() 做了几点改进,SLEEP_0_EVERY_HOW_MANY_TIMES 改为了4,SLEEP_1_EVERY_HOW_MANY_TIMES 改为了64,这是执行 Sleep(0) 和 Sleep(1) 的间隔值,这是为了计算 % 是使用位运算效率高一点,其实这个地方用 % 也没多大区别,即用 5 和 20 也是可以的,不过根据我的经验 20 可以稍微设大一点,尤其是在 x64 模式下,前面我也稍微提到过原因,这是一个经过多次测试后得出的经验值,具体的可自己试情况调整。
其实关键的地方是自旋次数的设定,你可以看到 SpinWait.cs 用的阀值是 10,而 spin2_push() 里面有的是 1(设置成2也可以),其实这是一个很关键的地方,这个地方决定了混合自旋锁的性能,它是由你要锁的区域进行的操作持续多长时间而决定的,锁持有的时间短的话,我们自旋的次数就应该要少,而持有的时间长,则可以设大一点,但是不能太大,太大的化就会一直自旋而浪费 CPU 时间。因为我们与其让它自旋很久,不如看看别的线程有没有需要,有需要的话,我们先切换到别的线程,把时间片让给它。如果别的线程也不需要时间片,重复一点的次数后,我们就让线程进入休眠状态,即Sleep(1)。这里 Sleep(0) 并不是休眠,而是切换到跟自己相同优先级或更高优先级的线程,后面我们会讲,spin2_push() 的函数的截图里也有详细的注释和说明。
我们把 SpinWait.cs 中 SpinOne() 函数的这个策略称之为 “休眠策略”,而如何更好的进行休眠,则是一种“休眠的艺术”。
我们先来研究一下操作系统的 进程/线程 调度原理。
进程/线程调度
操作系统中,CPU 进程/线程调度有很多种策略,Unix 系统使用的是时间片算法,而 Windows 则属于抢先式的。
Linux
在时间片算法中,所有的进程排成一个队列。操作系统按照他们的顺序,给每个进程分配一段时间,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程。如果进程在时间片结束前挂起或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它将被移到队列的末尾。
Windows
所谓抢先式操作系统,就是说如果一个进程得到了 CPU 时间,除非它自己主动放弃使用 CPU,否则将完全霸占 CPU 。因此可以看出,在抢先式操作系统中,操作系统假设所有的进程都是“人品很好”的,会主动让出 CPU 。
在抢先式操作系统中,假设有若干进程,操作系统会根据他们的优先级、饥饿时间(已经多长时间没有使用过 CPU 了),给他们算出一个总的优先级来。操作系统就会把 CPU 交给总优先级最高的这个进程。当进程执行完毕或者自己主动挂起后,操作系统就会重新计算一次所有进程的总优先级,然后再挑一个优先级最高的把 CPU 控制权交给他。
分蛋糕
我们用分蛋糕的场景来描述这两种算法。假设有源源不断的蛋糕(源源不断的时间),一副刀叉(一个CPU),10个等待吃蛋糕的人(10 个进程)。
如果是 Unix/Linux 操作系统来负责分蛋糕,那么他会这样定规矩:每个人上来吃 1 分钟,时间到了换下一个。最后一个人吃完了就再从头开始。于是,不管这10个人是不是优先级不同、饥饿程度不同、饭量不同,每个人上来的时候都可以吃 1 分钟。当然,如果有人本来不太饿,或者饭量小,吃了30秒钟之后就吃饱了,那么他可以跟操作系统说:我已经吃饱了(挂起)。于是操作系统就会让下一个人接着来,而刚吃饱的会被安排到队伍的最后面。
如果是 Windows 操作系统来负责分蛋糕,那么场面就很有意思了。他会这样定规矩:我会根据你们的优先级、饥饿程度去给你们每个人计算一个优先级。优先级最高的那个人,可以上来吃蛋糕——吃到你不想吃为止。等这个人吃完了,我再重新根据优先级、饥饿程度来计算每个人的优先级,然后再分给优先级最高的那个人。
这样看来,这个场面就有意思了——有的人是年轻MM,而且长得漂亮,因此天生就拥有高优先级,于是她就可以经常来吃蛋糕。而另外一个人可能是个穷屌丝,而且长得也挫,所以优先级特别低,于是好半天了才轮到他一次(因为随着时间的推移,他会越来越饥饿,因此算出来的总优先级就会越来越高,因此总有一天会轮到他的)。而且,如果一不小心让一个大胖子得到了刀叉,因为他饭量大,可能他会霸占着蛋糕连续吃很久很久,导致旁边的人在那里咽口水……
而且,还可能会有这种情况出现:操作系统现在计算出来的结果,5号漂亮MM总优先级最高,而且高出别人一大截。因此就叫5号来吃蛋糕。5号吃了一小会儿,觉得没那么饿了,于是说“我不吃了”(挂起)。因此操作系统就会重新计算所有人的优先级。因为5号刚刚吃过,因此她的饥饿程度变小了,于是总优先级变小了;而其他人因为多等了一会儿,饥饿程度都变大了,所以总优先级也变大了。不过这时候仍然有可能5号的优先级比别的都高,只不过现在只比其他的高一点点——但她仍然是总优先级最高的啊。因此操作系统就会说:5号MM上来吃蛋糕……(5号MM心里郁闷,这不刚吃过嘛……人家要减肥……谁叫你长那么漂亮,获得了那么高的优先级)。
以上参考自:《理解 Thread.Sleep 函数》 http://www.cnblogs.com/ILove/archive/2008/04/07/1140419.html
(楼主后记:本来是在写此文之前搜索一下“C# SpinWait”,没想到看到这么一篇文章,正好用来解释操作系统的调度原理,本来我对 Linux 和 Windows 的调度区别并不是特别清楚,看了这篇文章后,正好弥补了这个问题。)
Thread.Sleep(n)
我们前面提到5号MM说“我吃饱了,先不吃了”(挂起),这是怎么实现的?在 C# 中,就是使用 Thread.Sleep(n) 实现的,类似的 Windows API 是:Sleep(n); ,Linux API 是:sleep(n); usleep(n); 等,而对于 Java 来说,就是 Thread.sleep(n); 。那么 Thread.Sleep(n) 是什么意思呢?在 Windows 下,意思就是,我先休息 n 毫秒,不参与 CPU 的竞争。投射到分蛋糕的场景上就是,你们先吃,我吃得够饱了,未来半个小时内我都不想吃了,我让出位置,先休息 30 分钟再来。而在 Linux 下,意思也是一样的,唯一的区别可能就是休眠完成后怎么归队的问题。
在进程/线程休眠足够的时候后,重新参与 CPU 竞争的时候,在 Windows 下,是否是立刻把这个时间片分配给这个从休眠状态重新归队进程/线程,还是按照它的饥饿程度(因为休眠了许久)和线程的优先级,即休眠完成后重新计算的总的优先等级,跟其他进程/线程一起参与竞争,以选出一个总的优先级别最高的,再把时间片分配给该总优先级最高的进程/线程,而不一定是该重新被唤醒的进程/线程。不过从合理性的角度,前者更合理,因为后者可能导致即使你结束休眠了,但是由于可能你总的优先级别怎么都抢不过别进程/线程,而导致休眠结束后,可能会被延迟很久才能重新获得时间片,这看起来不太科学。但是 Windows 可能选择的是后者,MSDN 里提到,即使是 Sleep(0) ,也可能不一定保证会立刻被执行,进程/线程只是被设置为准备就绪状态。准备就绪的意思就是声明我要重新参与 CPU 的竞争了。
关于这个细节,我们来看看 MSDN 中 MSDN: Sleep() function 是怎么说的:


中文大意是:
| 在 Sleep 的间隔时间结束后,线程准备运行。如果你指定的休眠时间是 0 毫秒,那么线程将放弃剩余的时间片,但保持准备就绪状态。需要注意的是这个准备就绪的线程不能保证立刻被运行。因此,线程可能不能立刻被运行直到休眠一定的时间间隔以后。想了解更详细的信息,可以参阅 Scheduling Priorities (调度优先级) 。 |
而 Scheduling Priorities (调度优先级) 里提到:

中文大意是:
|
操作系统对待相同优先级别的线程是平等的,操作系统以 轮叫循环 的方式分配时间片给最高优先级的线程。如果这个优先级别没有准备就绪的线程,系统将以 轮叫循环 的方式分配时间片给下一个优先级别的线程。如果一个高优先级别的线程变成可运行的,那么系统将终止低优先级的线程(即不允许它完成本来属于它的时间片),并且分配一个完整的时间片给更高级别的线程。想了解更多信息,请参阅 Context Switches (上下文切换) 。 |
名词解释:Round-robin scheduling (轮叫调度):以一定的时间间隔,轮流的方式执行相应的任务。
参考:http://en.wikipedia.org/wiki/Round-robin_scheduling
由此可知,《理解 Thread.Sleep 函数》一文中所说的也不完全正确,其实 Windows 也是有时间片概念的,只不过它不像 Linux 那样是平均分配的,抢先式的意思是,高优先级的线程如果有需要,是可以叫低优先级的线程让出时间片的,比较“霸道”。而整个系统调度依然是按某个时间片间隔来轮询(轮循)的,来决定选择那个线程来运行。一般来说,Windows 这个时间片大约是 10-15 ms 左右。这也是 Sleep() 函数默认设置下的最小精度,可以通过 timeBeginPeriod() 函数来修改这个最小精度。
而 Scheduling Priorities (调度优先级) 末段也提到:

中文大意是:
| 然而,如果有一个线程在等待其他低优先级的线程来完成某些任务,则一定要阻塞那些处于等待中的高优先级线程的运行。为了实现这个目的,可以使用 Wait Function (等待系列函数),critical section (临界区),或者 Sleep() 函数,SleepEx() 函数,或者 SwitchToThread() 函数。这些对于线程运行一个循环来说是一些可优选的方案。否则,处理器可能成为死锁状态(deadlocked),因为低优先级的线程可能永远都不会被调度到。 |
在这一段话里,微软暗示了我们,要进行良好的休眠和线程切换管理,是要分别使用 Sleep() 和 SwitchToThread() 函数的,而 jimi_yield() 在 Windows 下就等价于 SwitchToThread()。这跟我们前面提到的 SpinWait.cs 里是如出一辙的,我们分别使用了 Sleep(0),Sleep(1) 和 SwitchToThread()。而 Wait Functions 和 临界区,则没有研究过,临界区没什么好研究的,倒是 WaitForSingleObject() 这些函数跟 Sleep() 之间的差别倒是值得研究一下,不过好像没有那个地方用到这个技巧,所以暂时不予考虑。
Sleep(0)、Sleep(1) 和 SwitchToThread() 不得不说的故事
由于上了首页,我就写简单点,力求完整。
- Sleep(0):从前面的一些描述,我们已经大概知道在 Windows 上 Sleep(0) 是一个很特殊的东西,关于这点,MSDN上的 Sleep() function 是这么说的:

请注意深红色框住的部分,dwMilliseconds 的值为 0 时,会使线程放弃剩余的时间片,把时间片让给与该线程拥有相同优先级的其他已准备就绪的线程。如果没有相同优先级的线程没有已经准备就绪的,则 Sleep(0) 立刻返回,并且继续运行。这个行为从 Windows Server 2003 开始改变(以前的行为是,让步给所有准备就绪的线程,而不是仅仅让步给跟该线程优先级相同的线程)。同时,我们看到,这段文字上面还写着粗体的 Windows XP,我的猜想,这个改变是从 Win2003 开始,但是 WinXP 晚期的版本,比如SP2,SP3,可能也跟着改了。
综上,Sleep(0) 的行为应该是这样的,会放弃当前的时间片,让步给相同优先级的其他准备就绪的线程,这个线程可以是任何CPU核心上的线程,当然也可以让步给优先级比它高的线程(其实这个时候不是让步,而是被硬抢的,因为“抢先式”的原则),这跟很多文章所描述的也一致,不然你只看 MSDN,会以为只会让步给相同优先级的其他线程。这里还有一个问题,就是说 Sleep(0) 会立刻返回,但我们最前面翻译的那一段文字里又说可能不能保证立即被执行,似乎也不矛盾,有能被让步的线程则让步,没有的话就立即返回。
用一句概括就是:切换到任何 CPU 核心上的相同或更高优先级的等候线程,如果没有这样的线程则立刻返回。
- Sleep(1),Sleep(n):这个比较好理解,这是真正的挂起线程,进入休眠状态,并切换至内核,把自己置为准备就绪状态,然后至少 n 毫秒之后再唤醒,由于 Windows 系统调度的最小精度有可能大于 1 毫秒,所以真正的休眠时间由该最小精度决定,这个精度据说可以用 timeBeginPeriod() 函数修改,否则一般为 10-15 毫秒,即使 timeBeginPeriod() 修改为 1 毫秒,也可能因为时间片的关系,实际的休眠时间还是有可能大于 1 毫秒。跟 Sleep(0) 不同的地方是,Sleep(1) 是真正的放弃了时间片,而前者只是让步而已。
- SwitchToThread():这个函数更为特殊,如果说 Sleep(0) 是 Linux 没有的功能(Linux的usleep(0)据说没有这个效果,而且非常非常慢,由于我没有装 Linux 真机,也只能从网上的文章来推断),那么跟 SwitchToThread() 行为类似的函数在 Linux 上压根就没有,我们来看一下 MSDN :

大意是:使当前线程让步给当前 CPU 核心上的其他准备就绪的线程,由操作系统来选择下一个被运行的线程。这里提到的是 “current processor”,就是当前线程所在的 CPU 处理器,一般情况下,一个线程被分配到一个 CPU 核心上之后,不到万不得已,一般是不会随意切换 CPU 核心的,因为切换之后,很可能导致缓存失效,需要重新加载,所以除非有必要,不然一般是不会随意更换的。所以,这里 SwitchToThread() 切换到的线程就是原本就在这个 CPU 核心上等候的线程。
我们再来看一下后边的备注:

切换(让步)执行会在当前线程的 CPU 核心上持续长达一个线程调度时间片,操作系统不会让别的 CPU 核心上的线程迁移到该核心上运行,即使这个 CPU 核处于空闲或者正在运行一个低等级的线程。
在切换到的线程时间片结束后,操作系统重新安排执行的线程。重新调度取决于切换到的线程的优先级以及其他可运行线程的状态。
总结,SwitchToThread():让步给当前 CPU 核心上等待的其他线程,但只持续一个线程调度时间片,此阶段不会运行别的核心上的等待线程。时间片结束后有当前的状态和优先级选择一个线程继续运行。
该函数还有一个特点,就是如果没有合适的线程来切换时,会返回 0 值,并且继续当前线程的执行。如果有合适的线程来切换,则返回非 0 值。
另一个很重要的特性是,它会让步给比它线程优先级低的线程,这也是唯一一个可以这么做的函数,Sleep(0) 只能切换到相同或更高优先级的线程。
相互关系图
我们来看一张图:

事实上,不要以为有了他们就万事大吉了,Sleep(1) + Sleep(0) + SwitchToThread() 依然还是有些缺陷的,这在 Sleep() 和 SwitchToThread() 的 MSND 说明里都有提到。例如 SwitchToThread():如果一个 IOCP 程序运行在一个四核的CPU上,我们一般会设置 (CPU * 2 + 2) 个工作线程,即 8 至 10 个。现在每个 CPU 核心都有线程在跑,现在线程 X 在核心 A 上调用了 SwitchToThread(),可是它要等的资源在线程 Y 那里,而线程 Y 属于核心 D,并且被休眠了。此时,你调用 SwitchToThread(),知道切换到原本就是核心 A 上的线程 Z,却切换不到线程 Y,而工作线程优先级是相同的,一个线程没跑完之前,也不主动挂起的话,别的线程是得不到运行的,那么线程 X 等待的线程 Y 所持有的资源将得不到释放,所以有可能造成“死锁”(deadlock)。造成这样的原因是 SwitchToThread() 不能让别的核心上的等待线程切换到本核心上,如果它允许线程 Y 迁移过来,那么线程 Y 得到运行,持有的资源就可能得到释放,从而避免“死锁”。
可是,另一方面,Sleep(0) 就很好吗?也不,同样的场景,线程 X 在核心 A 上调用 Sleep(0),它要等的资源依然是在线程 Y 那里,可是这次不同的是,线程 Y 的优先级要比线程 X 低,线程 X 调用了 Sleep(0) 以后,的确是把 CPU 的控制权交出去了,也可以执行别的核心上的等待线程,可是 Sleep(0) 有一个问题,它只能切换到跟当前线程相同或更高优先级的线程,而线程 Y 的优先级比它低。就这样,虽然线程 X 挂起了,可是线程 Y 始终得不到运行,线程 X 想要的资源也释放不了,最终造成“死锁”。
当然这种情况可能不一定会完全死锁,因为操作系统会出来干预,干预的办法有两种,一种是适当的时间改变一下某些线程的优先级,从而让情况得到改变;另 一种是我们前面说过的,通过一个根据饥饿程度和线程优先级综合考虑的综合优先级,当这个综合优先级变得很大时,低优先级的线程也会得到运行。具体是哪一种 不得而知,因为看不到 Windows 的源码。前者是在一个老外的文章看到的,估计也是猜测,从实际上来看,Windows 的确会偶尔改善一下这种“死锁”的状况,但整个过程是很缓慢的,因为这个调整要比较长的时间才会处理一次。没完全死锁,但也活不好,相对于“活锁” (livelock)。
这时,你可能会说,我们让线程 Y 的优先级跟线程 X 一样或更高不就好了吗?不过问题还是存在的,虽然这样线程 Y 的确是可能能得到运行的,但由于等待的线程不止一个,分到时间片的线程不一定是线程 Y,而线程 Y 还是要等到其他线程再给机会让它运行才能释放相应的资源。这么看来 Sleep(0) 问题没 SwitchToThread() 那么严重,但是 SwitchToThread() 的好处就是如果不切换 CPU 核心的话,那么线程所用到的缓存数据可能还在缓存中,而不需要重新加载,如果迁移到别的核心上,缓存很可能会失效,而从新加载缓存有可能是一个很耗时的过程,各有利弊。
其实前面讲到的 Sleep(0) 和 SwitchToThread() 都会导致线程切换,也就会出现著名的 上下文切换 (Context Switches) 问题,可是我们的程序里为什么没有因为这个损失很大呢。一方面,当你在循环里自旋 N 次以后,如果还是获取不了想要的资源,适当的转去干别的事是基本无害的,只要不跟别的 CPU 发生缓存或者总线竞争即可,甚至你做一次上下文切换的时间,刚好让这个竞争变小了。我们知道单线程的时候,“单体”的效率是最高的,因为没有争抢,所以如果竞争者减少了,甚至减少到一个竞争者,那岂不是最高的效率吗。可是为什么我们不干脆就用一个线程来干事情就好了?一方面,一个线程释放了锁资源以后,还是要做一下善后工作的,这个处理善后工作的时间,如果有多个线程,那么就有可能有线程能在这个空档时间抢到资源去干事,这样填补了因为处理善后而空白的时间。如果这个善后,也就是一般所说的逻辑处理时间,越长的话,那么多线程的作用就越明显。比如一个游戏服务端程序,接受到一个数据包,要解包,解完包要根据收到的数据做相应的逻辑处理,这个过程可能不短,还可能包括一些数据库操作。如果单线程的话,一方面有些 CPU 核心闲置了,另一方面,在处理这个游戏逻辑的过程,不能让别的 CPU 去接后面的活来干事。
放在本文的消息队列道理也是一样的,虽然锁持有的时间非常短,但我们就是要在这冲突和竞争中在适当的时候抓过这个空档,尽量填满这个空档,同时适当的时候让步或休眠一下,减少竞争,这样通过的线程会更多。自旋只会让竞争越来越激烈,而从上面我们得知,如果一个休眠策略只有 Sleep(0) 或只有 SwitchToThread() 都是不完整的,最好把这两者加上真正的休眠 Sleep(n) 加进来(n >= 1),这样可以一定程度的防止“死锁”,也由于有真正的休眠,会让竞争更平滑一点。
sched_yield()
说完了 Windows 上的休眠策略,我们来看看 Linux 的让步/Yield方法,这个函数叫做 sched_yield() 。

这个函数在 Linux 上异常的简洁,看说明也很清楚:让当前线程放弃CPU使用权,同时把这个线程移动到它静态优先级的调度队列末尾,并且从调度队列中找一个合适的线程来运行。如果当前线程的线程优先级列表是最高的,那么该函数立刻返回,当前线程将继续运行。说明也提到,战略性的使用 sched_yield() 将有助于减少竞争来提高性能,同时也要避免不必要的和不适当的使用 sched_yield() ,从而导致上下文切换,这也会降低系统的性能。
这样看来,Linux 也是有优先级概念的(其实不可能没有,没有的话就变成三个和尚没水喝了)。通过查询相关资料,我们得知 Linux 有三种调度策略,第一种是 SCHED_RR,也就是跟 Windows 相似的 “round-robin” 轮叫策略,实时调度策略,以时间片轮转。当进程的时间片用完,系统将重新分配时间片,并置于就绪队列尾部。放在队列尾保证了所有具有相同优先级的 RR 任务的调度公平性;第二种是 SCHED_FIFO,即 “first-in, first-out”,先进先出策略,实时调度策略,先到先服务,一旦占用 CPU 则一直运行,一直运行到有更高优先级任务到达或自己主动放弃;还有一种是 SCHED_OTHER,分时调度策略,普通线程默认使用这个策略。SCHED_OTHER 是不支持使用优先级的,而 SCHED_FIFO 和 SCHED_RR 支持优先级的使用,他们分别为 1 和 99,数值越大优先级越高。
跟 Windows 不同的地方是,Linux 是允许为不用的线程指定不同的调度策略的,其中 SCHED_RR 和 SCHED_FIFO 都是实时策略,SCHED_OTHER 是分时策略,在用户态使用的,如果有实时策略的线程需要运行,那么会从 SCHED_OTHER 的普通线程抢得使用权,这有点类似 Windows 的抢先式,不过区别是只有实时策略的线程才能这么干。
参考自:《sched_yield()函数 高级进程管理》,《Linux内核的三种调度策略》,《linux内核的三种调度方法》。
其他
其实我们在研究 Sleep(0),Sleep(1),SwitchToThread() 的道路上并不寂寞,在 MSDN:Sleep() Function 的评论中,第二个回复里有一个链接,截图如下:
当初我为了研究得更透彻一些,搜索了很多资料,几乎任何一个有用的信息都没放过,stackoverflow.com 搜集到的很多东西如今都没有什么用途了,因为我们大体上弄清楚了,都浓缩在前面的描述中。而就是上面这个文章,还是写得比较有见地的,《Sleep Variation Investigated》,不过这篇文章也引出了他自己写的另一篇文章,请看图:

文章提到说最好不要用 Sleep(0) 的文章是:《In Praise of Idleness》,这篇文章有着跟我们类似的观点,他也分析了 Sleep(0),Sleep(1) 和 YieldProcessor() (这个相当于 _mm_pause() 指令,只对支持超线程的CPU有效)。其实他教我们不要用 Sleep(0),事实上,我们要用,我们要做的是如何更好的使用 Sleep(0),避免使用它带来的不利情况。我们不仅要用,而且还要用好。不过他的文章很多东西写的都是正确的,也是细致的,可以拜读一下,结论稍微偏激了点。我也是通过这篇文章了解到了 Facebook 的开源库 folly 的 SmallLocks.h,folly 在这方便做得不太好。你也可以通过本文的第二篇可以看到,我本来是想对各个开源库的 spin-lock 做一个完整的比较的,可以学到一点东西,我的代码也有借鉴了一小部分。
(以下部分内容于 2015/01/30 22:11 新增)
归纳
紧接上一篇的末尾,我们把 Windows 和 Linux 下的休眠策略归纳总结一下,如下图:
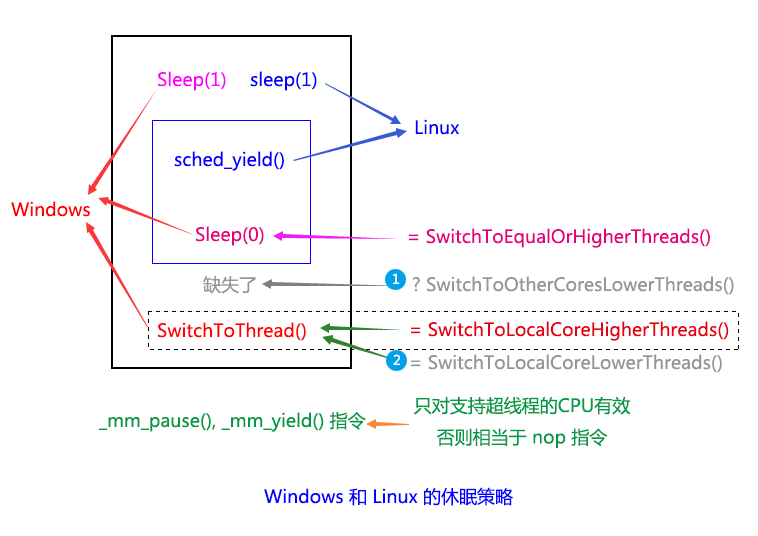
我们可以看到,Linux 下的 sched_yield() 虽然包括了 Windows 下的 Sleep(0) 和 SwitchToThread() 的部分功能(图中蓝色框和虚线框所标注的部分),但缺少了上图中两个灰色文字的功能,即 ① SwitchToOtherCoresLowerThreads() 和 ② SwitchToLocalCoreLowerThreads()(其实这个函数应该包括相同优先级的情况,但由于名字太长,故省略了Equal)。而 Windows 下,则缺失了 ① SwitchToOtherCoresLowerThreads() 这个功能。也就是说,Linux 下面没有切换到低优先级线程的功能,而 Windows 虽然提供了 SwitchToThread(),可以切换到本核心上的低优先级线程,却也依然缺少了切换到别的核心上低优先级线程的能力,即 ① SwitchToOtherCoresLowerThreads() 这个功能。
也就是说,Windows 和 Linux 的策略即使合起来用,依然是不完整的。可是我仔细的想了一下,上面的说法其实是不太正确的。sched_yield() 其实并不是不能切换到低优先级的线程,根据上篇提到 Linux 上的三种不同调度策略,sched_yiled() 是有可能切换到比自己优先级低的线程上的,比如 SCHED_FIFO(先进先出策略)或者 SCHED_RR(轮叫策略刚好轮到低优先级的线程)。只不过,不能特别指定切换到当前线程所在的核心上的其他线程,也就是类似 Windows 上 SwitchToThread() 的功能。
而 Windows 上,虽然看起来好像更完整,却也真正的缺少了切换到别的核心上的低优先级线程的功能,即 ① SwitchToOtherCoresLowerThreads()。
首先来看 Linux 上,缺少了只切换到当前核心的等待线程上的功能,如果切换的线程原来是在别的核心上的,那么有可能会导致切换到的线程所使用的缓存失效,被迫重新加载,导致影响性能。(这个不知道 Linux 的策略是如何选择的,可能要看下源码才能明白,但是有一点是可以肯定的,就算 Linux 在某些调度策略里(比如 SCHED_OTHER,这是普通线程所采用的策略),会优先选择本来就在当前核心上等待的线程,但是当当前核心上没有适合的等待线程的时候,Windows 的 SwitchToThread() 会立刻返回,而 Linux 应该还是会选择别的核心上的其他等待线程来执行;而如果是另外两种调度策略的话,则基本上可能不会优先选择当前核心上的等待线程,尤其是 SCHED_FIFO 策略)。
但从总体上来看,Linux 使用了三种不同的调度策略,是要比 Windows 单一的轮叫循环策略要好一点,至少你有可能通过不同的策略的组合来实现更有效的调度方案。
而 Windows 上虽然在一定程度上有避免这种线程迁移到别的 CPU 核心上运行的可能,却由于缺少切换到别的核心上低优先级线程的功能,而导致策略上的不完整,虽然 Windows 可能可以根据线程饥饿程度来决定要不要切换到这些本不能切换过去的低优先级线程,不过这个过程肯定是比较缓慢的,不太可控的,从而在某些特殊情况下可能会造成某种程度上的“死锁”。
所以 Linux 和 Windows 的调度策略各有千秋,总体上来看,Linux 好像稍微好那么一点,因为毕竟选择要多一些,只要设计得当,情况可能会好一点。但总体上,两者都有不足和缺陷,不够完整。
更完整的调度
那么怎样才能更完整呢?答案可能你也能猜到,通过前面的分析,我们想提供更完整的细节和可控的参数,让调度更完整和随心所欲。也就是根据我们的想法,指哪打哪,想切去哪就切去哪,无孔不入。我们需要一个更强大的接口,这个接口应该要考虑几乎所有可能的情况,功能强大而不失灵活性,甚至有些时候还会有一定的侵略性。我们只是提供一个接口,具体怎么玩,玩成什么样,我们不管,玩崩了那是程序员自己的事情(崩倒是应该不会,但是可能会混乱)。
我们把这个接口暂时定义为 scheduler_switch()(本来想叫 scheduler_switch_thread(),还是短一点好),函数模型大致为:
int scheduler_switch(pthread_array_t *threads, pthread_priority_t priority_threshold, int priority_type, cpuset_t cpu_mask, int force_now, int slice_count);
threads: 表示一组线程,我们从这一组线程里,通过后面的几个参数一起来决定最终选择切换到哪一个线程,该线程必需是处于准备就绪状态的,即会把已经在运行的线程排除掉。该值为 NULL 时表示从系统所有的等候线程里挑选,即跟 sched_yield() 默认的行为一致。
priority_threshold:表示线程优先级的阀值,由后面的 priority_type 来决定是高于这个阀值、低于这个阀值、等于这个阀值或者大于等于这个阀值,等等。该值为 -1 时表示使用当前线程的优先级。
priority_type: 决定 priority_threshold 的比较类型,可分为:>,<,==,>=,<= 等类型。
cpu_mask: 允许切换到的 CPU 核心的 mask 值,该值为 0 时表示只切换到线程当前所在的核心,不为 0 时,每一个 bit 位表示一个 CPU 核心,该值类似 CPU 亲缘性的 cpuset_t 。
force_now: 为 1 时,表示指定的切换线程立刻获得时间片,而不受系统优先级和调度策略的限制,强制运行的时间片个数由 slice_count 参数决定;为 0 时,表示指定切换的线程会等待系统来决定是否立刻得到时间片运行,可能会被安排到一个很短的等候队列里。
slice_count: 表示切换过去后运行的时间片个数,如果为 0 时,则由系统决定具体运行多少个时间片。
返回值: 如果成功切换返回 0,如果切换失败返回 -1(即没有可切换的线程)。
我所说的侵略性是,你可以决定切换以后会持续运行多少个时间片而不会被中断,而且如果你通过 threads 指定的线程组如果没有立刻得到时间片的权力的时候,可以通过 force_now 参数来强制获得时间片,即让系统本来下一个会得到该时间片的线程排在我们指定的线程运行完相应的时间片后再把时间片让给它。如果你指定的 slice_count 值过大,可能会使得其他线程得不到时间片运行,也许这个值应该设置一个上限,比如 100 个或 256 个时间片之类的。
你可以看到,这个接口函数几乎囊括了 Windows 和 Linux 已存在的所有调度函数的功能,并且进行了一定程度的增强和扩展,并且有一定的灵活性,如果你觉得还有不够完整的地方,也可以告诉我。至于如何实现它,我们并不关心,我们只要知道理论上是否可以实现即可,而具体的实现方法可以通过研究 Linux 内核源码来办到。也许并不一定很容易实现,但从理论上,我们还是有可能做得到的。Windows 上由于不开源,我们没什么办法,也许研究 ReactOS 是一种选择,但是 ReactOS 是基于 WindowsNT 内核的,技术可能有些陈旧(注:ReactOS 是一个模仿 Windows NT 和 Windows 2000 的开源操作系统项目,请参考 [wikipedia:ReactOS] )。
Linux 内核
下载 Linux Kernel 源码:
(建议下载 2.6.32.65 和 最新的稳定版 3.18.4,Android 是在 2.6 的基础上修改的,有兴趣也可以直接拿 Android 的内核来改。)
Ubuntu 14.04 LTS 的内核版本是 3.13 (参考:Ubuntu发行版列表)
可参考的文章:
注:通过阅读 Linux 内核的源码,sched_yield() 真正的执行过程并不是我前面描述的那样的,正确的过程应该是:先在当前线程所在的核心上遍历合适的任务线程,如果有的话,就切换到该线程;如果没有的话,目前我还不确定会不会从别的核心上的 RunQueue 迁移任务线程到当前核心来运行,按道理讲应该是这样的。如果是这样,那么 sched_yield() 跟 Windows 的 Sleep(0) 的唯一区别就是:Sleep(0) 不会切换到比自己的优先级别低的线程,而 sched_yield() 可以,Sleep(0) 的策略也应该跟 sched_yield() 类似,先在被核心上找,没有再去别的核心上找。但是,这里我就不修正前面的描述了,请自行注意一下。
因为 3.18.4 的 Linux 改动比较大,也变得复杂了很多,比较难读懂,找 schedule() 函数的位置都花了很大的力气……,因此这里以 2.6 版本的为例。
通过阅读 2.6.32.65 版本的 Linux 内核源码,我们知道实现系统调度的函数是:schedule(void),这跟我们这个接口比较类似,实现的功能也是大致一样。schedule(void) 的功能是从当前核心上的 RunQueue 里找到下一个可运行的任务线程,并切换MMU、寄存器状态以及堆栈值,即通常说的上下文切换(Context Switch)。
通过 /include/linux/smp.h 和 /arch/x86/include/asm/smp.h 或 /arch/arm/include/asm/smp.h,我们可以得知,smp_processor_id() 返回的是 CPU 核心的一个编号,x86 上是通过 percpu_read(cpu_number),arm 上是通过 current_thread_info()->cpu 获得。这样 rq = cpu_rq(cpu); 取得的 RunQueue 就是每个 CPU 核心上独立的运行(任务线程)队列。
/* * schedule() is the main scheduler function. */ asmlinkage void __sched schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: preempt_disable(); cpu = smp_processor_id(); /* 获取当前 CPU 核心编号 */ rq = cpu_rq(cpu); rcu_sched_qs(cpu); prev = rq->curr; switch_count = &prev->nivcsw; release_kernel_lock(prev); need_resched_nonpreemptible: schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); spin_lock_irq(&rq->lock); update_rq_clock(rq); clear_tsk_need_resched(prev); if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { if (unlikely(signal_pending_state(prev->state, prev))) prev->state = TASK_RUNNING; else deactivate_task(rq, prev, 1); switch_count = &prev->nvcsw; } pre_schedule(rq, prev); /* 准备调度? */ if (unlikely(!rq->nr_running)) idle_balance(cpu, rq); put_prev_task(rq, prev); /* 记录之前任务线程的运行时间, 更新平均运行时间和平均overlap时间. */ next = pick_next_task(rq); /* 从最高优先级的线程类别开始遍历, 直到找到下一个可运行的任务线程. */ if (likely(prev != next)) { sched_info_switch(prev, next); perf_event_task_sched_out(prev, next, cpu); rq->nr_switches++; rq->curr = next; ++*switch_count; /* 上下文切换, 同时释放 runqueue 的自旋锁. */ context_switch(rq, prev, next); /* unlocks the rq */ /* * the context switch might have flipped the stack from under * us, hence refresh the local variables. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); } else spin_unlock_irq(&rq->lock); post_schedule(rq); if (unlikely(reacquire_kernel_lock(current) < 0)) goto need_resched_nonpreemptible; preempt_enable_no_resched(); /* 是否需要重新调度 */ if (need_resched()) goto need_resched; } EXPORT_SYMBOL(schedule);
其中有一个很关键的函数是 pick_next_task(rq),作用是寻找下一个最高优先级的可运行任务。有一点可以确定的是,是优先在本核心上的 RunQueue 上遍历的,但看不太出来是否会在本核心上没有适合的任务线程时,会从别的核心上的 RunQueue 迁移任务过来,这个部分可能要看 struct sched_class 的 pick_next_task() 的实现,这个应该是一个函数指针。pick_next_task(rq) 的源码如下:↓↓↓
/* * Pick up the highest-prio task: */ static inline struct task_struct * pick_next_task(struct rq *rq) { const struct sched_class *class; struct task_struct *p; /* * Optimization: we know that if all tasks are in * the fair class we can call that function directly: */ /* fair_sched_class 是分时调度策略, 包括 SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE 三种策略, */ /* 从 __setscheduler() 函数得知. */ if (likely(rq->nr_running == rq->cfs.nr_running)) { p = fair_sched_class.pick_next_task(rq); if (likely(p)) return p; } /* sched_class_highest = &rt_sched_class; 即实时调度策略, */ /* 包括 SCHED_FIFO 和 SCHED_RR, 从 __setscheduler() 函数得知. */ class = sched_class_highest; for ( ; ; ) { p = class->pick_next_task(rq); if (p) return p; /* * Will never be NULL as the idle class always * returns a non-NULL p: */ class = class->next; } }
这个问题我们先打住,以后再研究,或者交给有兴趣的同学去研究,有什么成果的话麻烦告诉我一下。
scheduler_switch()
我们回顾一下 scheduler_switch() 的原型,如下:
int scheduler_switch(pthread_array_t *threads, pthread_priority_t priority_threshold, int priority_type, cpuset_t cpu_mask, int force_now, int slice_count);
这里的 pthread_array_t *threads,表示的一组线程,之所以想设置这个参数,是因为 q3.h 在 push() 和 pop() 的时候,确认提交成功与否的过程是需要序列化的,如果这个过程中的线程调度能够按我们想要的顺序调度,并且加上适当的休眠机制的话,可能可以减少竞争和提高效率。
请注意下面代码里第 22 和 23 行:
1 static inline int 2 push(struct queue *q, void *m) 3 { 4 uint32_t head, tail, mask, next; 5 int ok; 6 7 mask = q->head.mask; 8 9 do { 10 head = q->head.first; 11 tail = q->tail.second; 12 if ((head - tail) > mask) 13 return -1; 14 next = head + 1; 15 ok = __sync_bool_compare_and_swap(&q->head.first, head, next); 16 } while (!ok); 17 18 q->msgs[head & mask] = m; 19 asm volatile ("":::"memory"); 20 21 /* 这个地方是一个阻塞的锁, 对提交的过程进行序列化, 即从序号小的到大的一个个依次放行. */ 22 while (unlikely((q->head.second != head))) 23 _mm_pause(); 24 25 q->head.second = next; 26 27 return 0; 28 }
因为这里第 22, 23 行并没有休眠策略,直接是在原地自旋,在竞争比较激烈,且间隔时间很短的情况下(评价一个竞争的状况有两个参数,一个是多少人在竞争,另一个参数是产生竞争的频率,即间隔多久会产生一次竞争。竞争者越多,而且竞争间隔也很短的话,那么代表竞争是非常激烈的,我们这里的情况就是这样),没有休眠策略很可能导致互相激烈的争抢资源,而且也会让 q3.h 在 push() 和 pop() 总线程数大于 CPU 核心总数的时候,产生介于 ”活锁” 和 “死锁” 之间的这么一种异常状态的问题。此时,队列推进非常慢,而且有多慢似乎有点看脸,有时候可能要一分钟或几分钟不等。
如果这个时候,能够把还没轮到的线程先休眠,然后按次序依次唤醒(是按照我们自己的 sequence 序号 head 来唤醒,而不是线程自己进入休眠状态的顺序,因为从第 16 行结束到第 22 行,这里的执行顺序是不确定的,有可能序号大的线程先执行到第 22 行,而序号小的因为线程被挂起了,因而晚一点才执行到第 22 行,所以唤醒的时候是依据我们自己的序号 head 从小到大依次唤醒)。但是这样也会出现一个问题,就是当某个核心正在运行的线程(我们设这个CPU 核心为 X,线程为A)执行到第 22 行时,由于序号 head 大于 q->head.second 很多,那么需要切换到别的线程或者进入休眠状态。如果此时选择切换,此时 head = q->head.second 的线程(我们设这个线程为B)会被选取且被唤醒,可是问题来了,这个有时间片的 CPU 核心 X 很可能不是 head = q->head.second 这个的线程 B 原来所在的核心(我们设这个核心为 Y),如果要唤醒的话则需要从原来的核心 Y 迁移到当前的核心 X 来,这当然不是我们想看到的,如果可以在核心 Y 上执行线程 B,这是最理想的选择了。如果可以的话,我们会中断核心 Y 上正在运行的线程 C,然后把时间片交给线程 B 来运行。依此类推,那么有可能下一个被唤醒的线程也不在当前拥有时间片的 CPU 核心上,那么又将导致类似的中断。如果这种中断太多,那么效率自然也会受到一定影响。所以,如果有一个更好的统筹规划方法就再好不过了,可是,似乎这样的规划策略不太好实现。
要么我们允许线程频繁的迁移,或者我们可以按某个比例允许两种情况都出现,例如:0.4的概率允许被唤醒的线程迁移到当前的核心,0.6的概率不迁移,采用打断要唤醒的线程所在的核心的方式(总的概率为1.0)。或者我们允许一次唤醒两个相邻的线程(指序号 head 邻近),我们设这两个线程分别为线程 A 和 B,那么当 A 通过之后,紧接着就是该唤醒 B 了,我们让线程 B 早一点唤醒,然后让其自旋并等待通过(这其实跟现在的 q3.h 很像,不同的是我们加了休眠策略,是可以应付任意线程数的 push() 和 pop() 的)。而且如果两个线程原来所在的核心刚好交叉的话,即线程 A 原来是在核心 X 上的,线程 B 原来是在核心 Y 上的,现在核心 Y 的线程在请求 sched_yield(),现在要唤醒的线程是 A 和 B,那么我们让 B 在核心 Y 上运行,并且打断核心 X 上的线程,让其运行线程 A。当然,我们会先执行打断的过程,让线程 A 在核心 X 上运行,然后再在核心 Y 上切换到线程 B 运行,如果可以这么安排先后的话,如果不能这样做,两者同时进行也是可以的。如果不是交叉的话,也增加了两个线程中的其中一个可能在它原来的核心上的机率。
我们为什么没有在 pthread_array_t *threads 这一组线程上使用先进先出的队列呢,一是前面说过的,像 q3.h 这个问题,线程进入休眠的顺序不一定是我们想要的顺序,第二个原因是,像我们这个问题,本身就是一个 FIFO 队列问题,里面再套一个 FIFO 队列似乎也不合理。但是,的确有些时候还是需要这种 FIFO 的 threads 的,也不矛盾,我们让先进入的序号值比后进入的序号值小即可。为了简化逻辑,我们可以用固定数组存储元素(事先必需先指定队列大小),用两个单向链表来实现插入和遍历的方法,一个是active_list,另一个是free_list,遍历的时候使用序号做为选择的依据,从而变成一个按序号大小顺序出列的队列。
警告:其实这个部分感觉有点画蛇添足,不过我写了就不准备删了,有一部分也是我曾经思考过的东西,只是写出来好像没有想象中的理想,但可以做为一个思考的方向。
其实在 写完上一篇 到 准备写这篇文章之前 的某一天,我看到了这么一篇文章,《条件变量的陷阱与思考》,也可以说是及时雨,感觉好像跟我的文章能沾上一点边,我因此而特意查看了 glibc 源码里关于 pthread_cond_xxxx() 部分的相关代码,对条件变量有了进一步的认识。由于没深入研究,只是觉得条件变量的实现并不是想象中的那么简单,至少它整个机制跟我前面提到的唤醒进制是不太一样,我们总想实现一个完美的唤醒机制,事实上可能很难实现我们心中那最完美的方式,因为有些东西在多线程编程中是不可调和的。同时因为 POSIX 规范为了简化实现,使用的时候跟 Windows 是有很些区别的。看了这篇文章后,才发现我原来对 pthread 的条件变量理解并不到位,原本以为跟 Windows 的 Event (事件) 很类似,虽然我知道一些两者的区别,主要集中在 CreateEvent() 的手动和自动模式, PulseEvent() 和 pthread_cond_broadcast() 之间的区别。由于我从没真正的使用过它,所以真正的区别是看了这篇文章才知道的,最大的区别主要来自于实现的逻辑,POSIX 规范为了简化实现,条件变量必须跟一个 pthread_mutex_t 配合使用才能正确发生作用,这跟 Windows 的 WaitForSingleObject() 和 ResetEvent() 是有些不同的,Windows 上的 Event 相关函数内部已经包含了这个互斥操作了,相当来说比较直观和易用一些,但 pthread_cond_t 更灵活一些。
也许你会说,既然我们可能在内核里用 scheduler_switch(),为什么参数的定义却用了 pthread 的类型,其实如果原理实现了,改成内核的 kthread,或者内核和 pthread 分别实现两套函数,也是可以的,这不是大问题。
设计 scheduler_switch() 这个东西是启发式的,我们的目的是想让休眠策略能够更完整的为我们服务,如果能改进则更好,实现不了或不好实现也不打紧,也算是抛砖引玉,希望对你有所启发。
待续
更新记录:2015/01/30 22:11 更新了从 [归纳] 开始的后面部分,此部分内容也就是 第六篇:休眠的艺术 [续] 的内容。
感谢你的阅读,如果你觉得写得不错的话,麻烦点一下推荐,或者评论一下,这样下次你找这个文章就可以从首页的 “我赞” 和 “我评” 里面找到了。
RingQueue
RingQueue 的GitHub地址是:https://github.com/shines77/RingQueue,也可以下载UTF-8编码版:https://github.com/shines77/RingQueue-utf8。 我敢说是一个不错的混合自旋锁,你可以自己去下载回来看看,支持Makefile,支持CodeBlocks, 支持Visual Studio 2008, 2010, 2013等,还支持CMake,支持Windows, MinGW, cygwin, Linux, Mac OSX等等。
目录
(一)起因 (二)混合自旋锁 (三)q3.h 与 RingBuffer
(四)RingQueue(上) 自旋锁 (五)RingQueue(中) 休眠的艺术
上一篇:一个无锁消息队列引发的血案(四)——月:RingQueue(上) 自旋锁
下一篇:一个无锁消息队列引发的血案(六)——RingQueue(中) 休眠的艺术 [续]
.
