
Hadoop| HDFS-HA高可用 | Yarn-HA
1. HDFS-HA
在分布式文件系统 HDFS 中,NameNode 是 master 角色,当 NameNode 出现故障后,整个 HDFS 将不可用,所以保证 NameNode 的稳定性至关重要。在 Hadoop1.x 版本中,HDFS 只支持一个
NameNode,为了保证稳定性,只能靠 SecondaryNameNode 来实现,而 SecondaryNameNode 不能做到热备,而且恢复的数据也不是最新的元数据。基于此,从 Hadoop2.x 版本开始,HDFS 开始支持多个
NameNode,这样不但可以实现 HDFS 的高可用,而且还可以横行扩容 HDFS 的存储规模。
在实际的企业应用中,使用最多的是双 NameNode 架构,也就是一个 NameNode 处于 Active(活跃) 状态,另一个 NameNode 处于 Standby(备用)状态,通过这种机制,实现 NameNode 的双机热备高可
用功能。
原理
在高可用的 NameNode 体系结构中,只有 Active 状态的 NameNode 是正常工作的,Standby 状态的 NameNode 处于随时待命状态,它时刻去同步 Active 状态 NameNode 的元数据。一旦 Active 状态的
NameNode 不能工作,可以通过手工或者自动切换方式将 Standby 状态的 NameNode 转变为 Active 状态,保持 NameNode 持续工作。这就是两个高可靠的 NameNode 的实现机制。
NameNode 主、备之间的切换可以通过手动或者自动方式来实现,作为线上大数据环境,都是通过自动方式来实现切换的,为保证自动切换,NameNode 使用 ZooKeeper 集群进行仲裁选举。基本的思路是
HDFS 集群中的两个 NameNode 都在 ZooKeeper 中注册,当 Active 状态的 NameNode 出故障时,ZooKeeper 能马上检测到这种情况,它会自动把 Standby 状态切换为 Active 状态。
ZooKeeper(ZK)集群作为一个高可靠系统,能够为集群协作数据提供监控,并将数据的更改随时反馈给客户端。HDFS 的热备功能依赖 ZK 提供的两个特性:错误监测、活动节点选举。
HDFS 通过 ZK 实现高可用的机制:
每个 NameNode 都会在 ZK 中注册并且持久化一个 session 标识,一旦 NameNode 失效了,那么 session 也将过期,而 ZK 也会通知其他的 NameNode 发起一个失败切换。ZK 提供了一个简单的机制来保证只
有一个 NameNode 是活动的,那就是独占锁,如果当前的活动 NameNode 失效了,那么另一个 NameNode 将获取 ZK 中的独占锁,表明自己是活动的节点。
ZKFailoverController(ZKFC)是 ZK 集群的客户端,用来监控 NN 的状态信息,每个运行 NameNode 的节点必须要运行一个 ZKFC。
ZKFC 提供以下功能:
- 健康检查,ZKFC 定期对本地的 NN 发起 health-check 的命令,如果 NN 正确返回,那么 NN 被认为是 OK 的,否则被认为是失效节点;
- session管理,当本地 NN 是健康的时候,ZKFC 将会在 ZK 中持有一个 session,如果本地 NN 又正好是 Active,那么 ZKFC 将持有一个短暂的节点作为锁,一旦本地 NN 失效了,那么这个节点就会被自动删除;
- 基础选举,如果本地 NN 是健康的,并且 ZKFC 发现没有其他 NN 持有这个独占锁,那么它将试图去获取该锁,一旦成功,那么它就开始执行 Failover,然后变成 Active 状态的 NN 节点;Failover 的过程分两步,首先对之前的 NameNode 执行隔离(如果需要的话),然后将本地 NameNode 切换到 Active 状态。
双 NameNode 架构中元数据一致性如何保证
从 Hadoop2.x 版本后,HDFS 采用了一种全新的元数据共享机制,即通过 Quorum Journal Node(JournalNode)集群或者 network File System(NFS)进行数据共享。NFS 是操作系统层面的,而 JournalNode 是 Hadoop 层面的,成熟可靠、使用简单方便,所以,这里我们采用 JournalNode 集群进行元数据共享。
JournalNode 集群以及与 NameNode 之间如何共享元数据,如下图所示
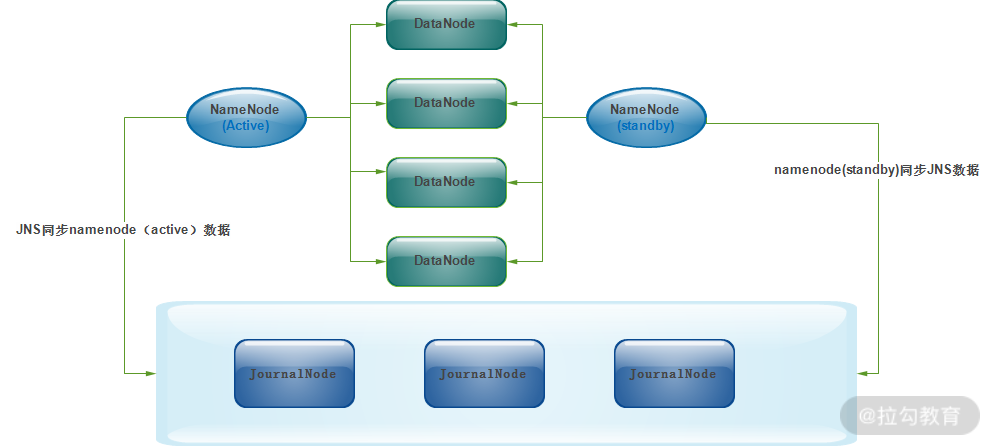
由图可知,JournalNode 集群可以几乎实时的去 NameNode 上拉取元数据,然后保存元数据到 JournalNode 集群;同时,处于 standby 状态的 NameNode 也会实时的去 JournalNode 集群上同步 JNS 数据,通
过这种方式,就实现了两个 NameNode 之间的数据同步。
JournalNode 集群内部是如何实现的呢?
两个 NameNode 为了数据同步,会通过一组称作 JournalNodes 的独立进程进行相互通信。当 Active 状态的 NameNode 元数据有任何修改时,会告知大部分的 JournalNodes 进程。同时,Standby 状态的 NameNode 也会读取 JNs 中的变更信息,并且一直监控 EditLog (事务日志)的变化,并把变化应用于自己的命名空间。Standby 可以确保在集群出错时,元数据状态已经完全同步了。
JournalNode 集群的内部运行架构图
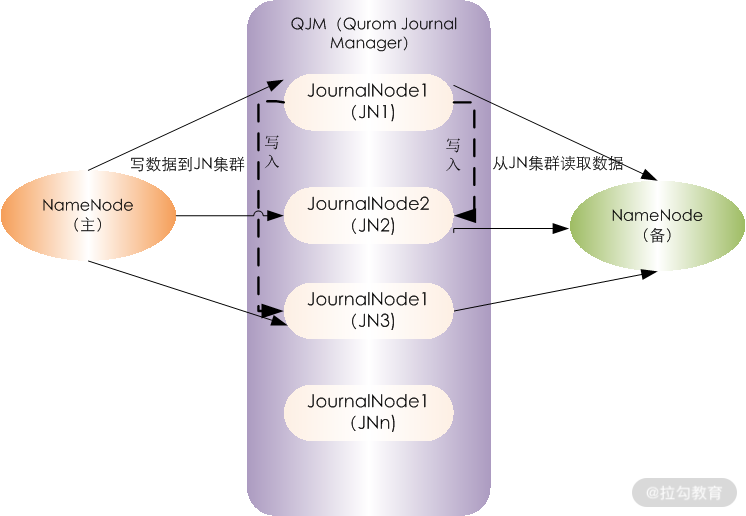
由图可知,JN1、JN2、JN3 等是 JournalNode 集群的节点,QJM(Qurom Journal Manager)的基本原理是用 2N+1 台 JournalNode 存储 EditLog,每次写数据操作有 N/2+1 个节点返回成功,那么本次写操作
才算成功,保证数据高可用。当然这个算法所能容忍的是最多有 N 台机器挂掉,如果多于 N 台挂掉,算法就会失效。
ANN 表示处于 Archive 状态的 NameNode,SNN 表示处于 Standbye 状态的 NameNode,QJM 从 ANN 读取数据写入 EditLog 中,然后 SNN 从 EditLog 中读取数据,进而应用到自身。
双 NameNode 高可用 Hadoop 集群架构
作为 Hadoop 的第二个版本,Hadoop2.x 最大的变化是 NameNode 可实现高可用,以及计算资源管理器 Yarn。构建一个线上高可用的 Hadoop 集群系统,这里有两个重点,一是
NameNode 高可用的构建,二是资源管理器 Yarn 的实现,通过 Yarn 实现真正的分布式计算和多种计算框架的融合。
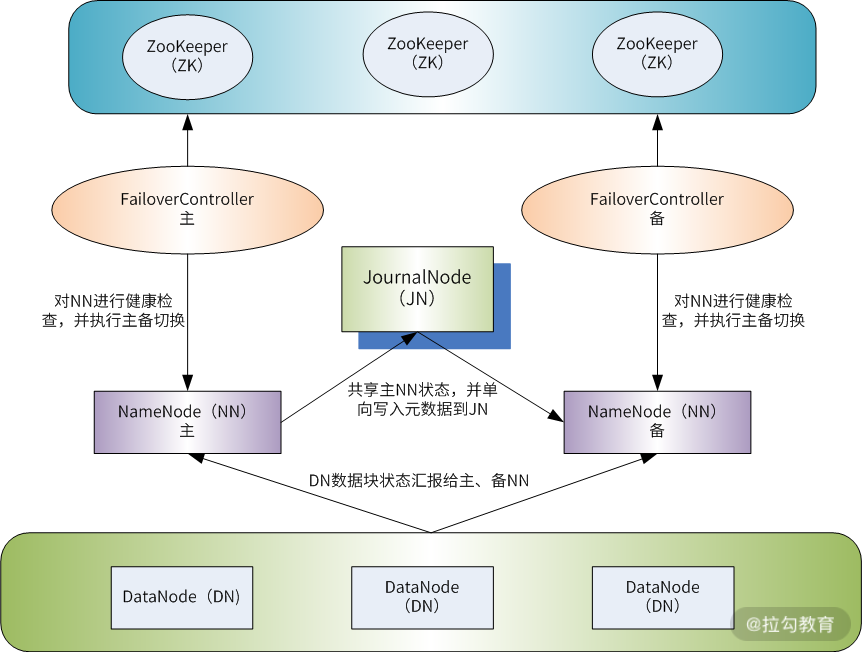
此架构主要解决了两个问题
- 一是 NameNode 元数据同步问题,
- 二是主备 NameNode 切换问题,由图可知,解决主、备 NameNode 元数据同步是通过 JournalNode 集群来完成的,而解决主、备 NameNode切换可通过 ZooKeeper 来完成。
ZooKeeper 是一个独立的集群,在两个 NameNode 上还需要启动一个 failoverController(zkfc)进程,该进程作为 ZooKeeper 集群的客户端存在,通过 zkfc 可以实现与 ZooKeeper 集群的交互和状态监测。
HA(High Available),即高可用(7*24小时不中断服务)
单点故障即有一台机器挂了导致全部都挂了;HA就是解决单点故障,就是针对NameNode;
主Active:读写、从standby只读;所依赖的服务都必须是高可用的;
两种解决共享空间的方案:NFS、QJM(主流的)

奇数台机器;QJM跟zookeeper(数据全局一致;半数以上的机器存活就可以提供服务)高可用的方式一模一样,;
QJM也是基于Paxos算法,系统容错不能超过n-1/2, 5台容错2台;
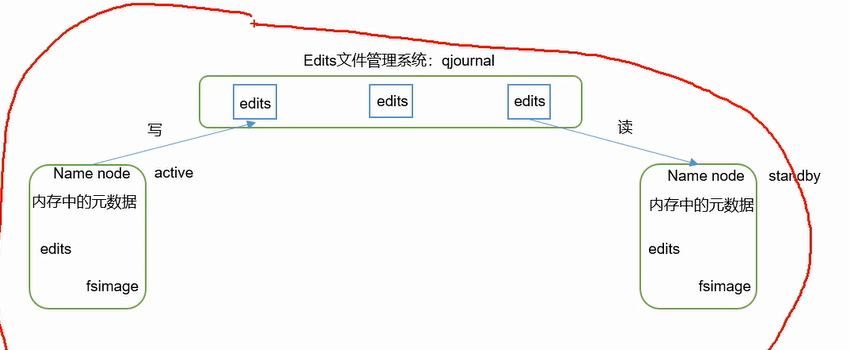
这个架构只能手动决定哪个是active哪个是standby;必须只能有一个active!!如果出现两个NameNode,即两个都是active,它可能还不报错,那么可能会导致整个集群的数据都是错的,问题很严重!两个AA
的情况叫脑裂(split brain缩写sb)。
standby要想变成active,要确保active那个,需要安全可靠的zookeeper(文件系统+通知机制)第三方来联系两方 ---> 实现故障的自动转移;
由Zkfc来联系zookeeper,并不是namenode直接联系,(zookeeper客户端);HA是hadoop2.0才有的,namenode在1.0时就有了;没有把zkfc写进namenode是为了保持NameNode的健壮性,没有zkfc之前
就已经运行的很好了(鲁棒性);NameNode和Zkfc虽然是两个进程但它们是绑定到一起的。
两个zkfc怎么决定谁初始化就是active呢,谁快谁就是active; 是active状态它会在zookeeper中有一个临时节点,zkfc会尝试看看zookeeper中有没有这个临时节点,如果没有我就变成这个临时节点,成为
active,慢的一看有了,就变成standby;
NameNode发生假死,zkfc就会把zookeeper中的临时节点删除,去通知另外一个namenode的zkfc,让它去成为active,这个namenode就会去强行杀死假死的namenode,防止脑裂!如果杀不死就自定义一
个脚本强制它关机,成功之后才会变成active。
现在合并fsimage是由standby来完成的,没有secondaryNameNode;
在module目录下创建一个ha文件夹
mkdir ha
将/opt/module/下的 hadoop-2.7.2拷贝到/opt/module/ha目录下
cp -r hadoop-2.7.2/ /opt/module/ha/
删除data logs等文件
配置
配置core-site.xml
<configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/ha/hadoop-2.7.2/data/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 端口号9000 or 8020-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop101:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop102:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop101:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop102:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/kris/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/ha/hadoop-2.7.2/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
发送到其他机器
xsync ha
启动HDFS-HA集群
1. 在各个JournalNode节点上,输入以下命令启动journalnode服务 sbin/hadoop-daemons.sh start journalnode //加个s就可以3台一块启动;都启动之后才能格式化namenode;只能格式化一次! 2. 在[nn1]上,对其进行格式化,并启动 bin/hdfs namenode -format 19/02/13 02:15:00 INFO util.GSet: Computing capacity for map NameNodeRetryCache 19/02/13 02:15:00 INFO util.GSet: VM type = 64-bit 19/02/13 02:15:00 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB 19/02/13 02:15:00 INFO util.GSet: capacity = 2^15 = 32768 entries 19/02/13 02:15:01 INFO namenode.FSImage: Allocated new BlockPoolId: BP-26035536-192.168.1.101-1549995301800 19/02/13 02:15:01 INFO common.Storage: Storage directory /opt/module/ha/hadoop-2.7.2/data/tmp/dfs/name has been successfully formatted. 19/02/13 02:15:02 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 19/02/13 02:15:02 INFO util.ExitUtil: Exiting with status 0 19/02/13 02:15:02 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop101/192.168.1.101 ************************************************************/ 启动namenode: sbin/hadoop-daemon.sh start namenode 3. 在[nn2]上,同步nn1的元数据信息 bin/hdfs namenode -bootstrapStandby ...... STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2017-05-22T10:49Z STARTUP_MSG: java = 1.8.0_144 ************************************************************/ 19/02/21 17:56:25 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 19/02/21 17:56:25 INFO namenode.NameNode: createNameNode [-bootstrapStandby] ===================================================== About to bootstrap Standby ID nn2 from: Nameservice ID: mycluster Other Namenode ID: nn1 Other NN's HTTP address: http://hadoop101:50070 Other NN's IPC address: hadoop101/192.168.1.101:9000 Namespace ID: 411281390 Block pool ID: BP-1462258257-192.168.1.101-1550740170734 Cluster ID: CID-d20dda0d-49d1-48f4-b9e8-2c99b72a15c2 Layout version: -63 isUpgradeFinalized: true ===================================================== 19/02/13 02:16:51 INFO common.Storage: Storage directory /opt/module/ha/hadoop-2.7.2/data/tmp/dfs/name has been successfully formatted. 19/02/13 02:16:51 INFO namenode.TransferFsImage: Opening connection to http://hadoop101:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:1640720426:0:CID-81cbaa0d-6a6f-4932-98ba-ff2a46d87514 19/02/13 02:16:51 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds 19/02/13 02:16:52 INFO namenode.TransferFsImage: Transfer took 0.02s at 0.00 KB/s 19/02/13 02:16:52 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 351 bytes. 19/02/13 02:16:52 INFO util.ExitUtil: Exiting with status 0 19/02/13 02:16:52 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop102/192.168.1.102 ************************************************************/ 出现这个信息是:(只需格式化一次;) Re-format filesystem in Storage Directory /opt/module/ha/hadoop-2.7.2/data/tmp/dfs/name ? (Y or N) N
Format aborted in Storage Directory /opt/module/ha/hadoop-2.7.2/data/tmp/dfs/name
19/02/21 19:06:50 INFO util.ExitUtil: Exiting with status 5 ##这个是退出状态!
19/02/21 19:06:50 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop102/192.168.1.102
************************************************************/
4.启动[nn2]
sbin/hadoop-daemon.sh start namenode
6. 在[nn1]上,启动所有datanode; hadoop-daemons.sh是3台都启动datanode
sbin/hadoop-daemons.sh start datanode
##手动切换namenode
7.将[nn1]切换为Active
bin/hdfs haadmin -transitionToActive nn1
5. 查看是否Active
bin/hdfs haadmin -getServiceState nn1
http://hadoop101:50070/dfshealth.html#tab-overview
http://hadoop102:50070/dfshealth.html#tab-overview
配置HDFS-HA自动故障转移
(直接启动不需先按手动的启动方式)
配置好自动故障转移后手动模式就不可用了
Automatic failover is enabled for NameNode at hadoop102/192.168.1.102:9000
Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state.
If you are very sure you know what you are doing, please
specify the --forcemanual flag.
配置HDFS-HA自动故障转移
1.具体配置 ;在上个基础上添加如下:
(1)在hdfs-site.xml中增加
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(2)在core-site.xml文件中增加
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
2. 启动
(1)关闭所有HDFS服务:
sbin/stop-dfs.sh
(2)启动Zookeeper集群:
bin/zkServer.sh start
(3)初始化HA在Zookeeper中状态:(只初始化一次)
bin/hdfs zkfc -formatZK
19/02/13 02:04:02 INFO zookeeper.ClientCnxn: Socket connection established to hadoop102/192.168.1.102:2181, initiating session
19/02/13 02:04:02 INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop102/192.168.1.102:2181, sessionid = 0x268e2dee6e40000, negotiated timeout = 5000
19/02/13 02:04:02 INFO ha.ActiveStandbyElector: Session connected.
19/02/13 02:04:02 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
19/02/13 02:04:02 INFO zookeeper.ZooKeeper: Session: 0x268e2dee6e40000 closed
19/02/13 02:04:02 INFO zookeeper.ClientCnxn: EventThread shut down
(4)启动HDFS服务:
sbin/start-dfs.sh
hadoop101: starting namenode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-namenode-hadoop101.out
hadoop102: starting namenode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-namenode-hadoop102.out
hadoop102: starting datanode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-datanode-hadoop102.out
hadoop101: starting datanode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-datanode-hadoop101.out
hadoop103: starting datanode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-datanode-hadoop103.out
Starting journal nodes [hadoop101 hadoop102 hadoop103]
hadoop103: starting journalnode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-journalnode-hadoop103.out
hadoop102: starting journalnode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-journalnode-hadoop102.out
hadoop101: starting journalnode, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-journalnode-hadoop101.out
Starting ZK Failover Controllers on NN hosts [hadoop101 hadoop102]
hadoop101: starting zkfc, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-zkfc-hadoop101.out
hadoop102: starting zkfc, logging to /opt/module/ha/hadoop-2.7.2/logs/hadoop-kris-zkfc-hadoop102.out
3.验证
(1)将Active NameNode进程kill
kill -9 namenode的进程id ---> 另外一个namenode上位;
( 杀掉之后,可单独启动: sbin/hadoop-daemon.sh start namenode,启动之后它不会变成之前的active;而是standby)
(2) 将DFSZKFailoverController的进程kill
kill -9 8819 --->尽管它的namenode没有挂,但另外一个namenode也会上位,它变成standby
再启动它要先停止->sbin/stop-dfs.sh sbin/start-dfs.sh
(3)将Active NameNode机器断开网络
sudo service network stop ---> 把网络断开之后,配的隔离机制是sshfence尝试远程登录区杀敌hadoop101,直到把101网络连接上才杀死,102才成为active;
断网上位很容易脑裂,那边网已恢复就炸了;如果真的断网,它这个是不会自动切的是为了防脑裂。虽然可以通过配置断网可以直接上,但很危险;断网上不去反而安全。
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha
[mycluster]
[zk: localhost:2181(CONNECTED) 3] ls /hadoop-ha/mycluster
[ActiveBreadCrumb, ActiveStandbyElectorLock] 选举的关键节点,谁占领了这个节点谁就是active;
[zk: localhost:2181(CONNECTED) 4] get /hadoop-ha/mycluster/ActiveStandbyElectorLock
myclusternn1 hadoop101 �F(�>
cZxid = 0x10000000f
ctime = Wed Feb 13 02:16:22 CST 2019
mZxid = 0x10000000f
mtime = Wed Feb 13 02:16:22 CST 2019
pZxid = 0x10000000f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x268e2dee6e40002 临时节点,
dataLength = 33
numChildren = 0
进程
hadoop101 hadoop102 hadoop103
NameNode NameNode
JournalNode JournalNode JournalNode
DataNode DataNode DataNode
DFSZKFailoverController DFSZKFailoverController ZooKeeperMain(bin/zkCli.sh ,启动zookeeperd客户端)
ResourceManager ResourceManager
NodeManager NodeManager NodeManager
QuorumPeerMain QuorumPeerMain QuorumPeerMain (bin/zkServer.sh start 启动zookeeper服务器)
DFSZKFailoverController是Hadoop-2.7.0中HDFS NameNode HA实现的中心组件,它负责整体的故障转移控制等。
它是一个守护进程,通过main()方法启动,继承自ZKFailoverController。 zkfc
使用JournalNode实现两个NameNode(Active和Standby)之间数据的共享
2. YARN-HA配置
YARN-HA工作机制
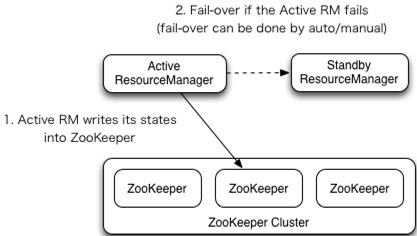
Yarn原生根zookeeper兼容很好,配置比较简单;
配置YARN-HA集群
yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> //混合服务还是shuffle,用shuffle确定reducer获取数据的方式 </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop101</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop102</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property>
yarn-site.xml 在hadoop101中配置好将其分发到其他机器:xsync etc/
启动zookeeper;3台其他都启动;
[kris@hadoop101 ~]$ /opt/module/zookeeper-3.4.10/bin/zkServer.sh start
启动hdfs
sbin/start-dfs.sh
启动YARN
(1)在hadoop101中执行:
sbin/start-yarn.sh
[kris@hadoop101 hadoop-2.7.2]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/ha/hadoop-2.7.2/logs/yarn-kris-resourcemanager-hadoop101.out
hadoop101: starting nodemanager, logging to /opt/module/ha/hadoop-2.7.2/logs/yarn-kris-nodemanager-hadoop101.out
hadoop103: starting nodemanager, logging to /opt/module/ha/hadoop-2.7.2/logs/yarn-kris-nodemanager-hadoop103.out
hadoop102: starting nodemanager, logging to /opt/module/ha/hadoop-2.7.2/logs/yarn-kris-nodemanager-hadoop102.out
(2)在hadoop102中执行:
sbin/yarn-daemon.sh start resourcemanager //脚本只在上面一台上启动了,hadoop102上的resourcemanager要手动启;
[kris@hadoop102 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/ha/hadoop-2.7.2/logs/yarn-kris-resourcemanager-hadoop102.out
(3)查看服务状态
bin/yarn rmadmin -getServiceState rm1 //rm1就是hadoop101; rm2为hadoop102
[kris@hadoop102 hadoop-2.7.2]$ bin/yarn rmadmin -getServiceState rm1
active
[kris@hadoop102 hadoop-2.7.2]$ bin/yarn rmadmin -getServiceState rm2
standby
http://hadoop101:8088/cluster http://hadoop102:8088/cluster -->它会重定向到hadoop101
hdfs-ha & yarn-ha
[kris@hadoop101 hadoop-2.7.2]$ jpsall
-------hadoop101-------
14288 ResourceManager
14402 NodeManager
13396 NameNode
14791 Jps
13114 QuorumPeerMain
13946 DFSZKFailoverController
13516 DataNode
13743 JournalNode
-------hadoop102-------
9936 NameNode
10352 ResourceManager
9569 JournalNode
9698 DFSZKFailoverController
9462 DataNode
9270 QuorumPeerMain
10600 Jps
10202 NodeManager
-------hadoop103-------
9073 Jps
8697 JournalNode
8522 QuorumPeerMain
8909 NodeManager
8590 DataNode
