
Hadoop| 集群的搭建
大数据生态体系

1. Hadoop组成

HDFS(Hadoop Distributed File System)架构概述
NameNode目录--主刀医生(nn); DataNode(dn)数据; Secondary NameNode(2nn)助手;
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
YARN框架 常驻 + 临时
ResourceManager(RM) 组长;
NodeManager 组员;
Client客户;Job Submission来任务了 ---->> ApplicationMaster,任务结束它就卸任了;
ApplicationMaster(AM)临时项目任务负责人,由RM任命监视等;
容器Container:底层没有虚拟,只虚拟了应用层,但仍可以隔离cup和内存;(与虚拟机的区别);可以在一个机器里开3个容器(都要是一样的如3个window,因为系统底层没变;)
占cpu内存用来运行任务如APP Mster;

MapReduce架构概述 计算引擎

查看Hadoop目录结构
[kris@hadoop101 hadoop-2.7.2]$ ll
总用量 52
drwxr-xr-x. 2 kris kris 4096 5月 22 2017 bin
drwxr-xr-x. 3 kris kris 4096 5月 22 2017 etc
drwxr-xr-x. 2 kris kris 4096 5月 22 2017 include
drwxr-xr-x. 3 kris kris 4096 5月 22 2017 lib
drwxr-xr-x. 2 kris kris 4096 5月 22 2017 libexec
-rw-r--r--. 1 kris kris 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 kris kris 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 kris kris 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 kris kris 4096 5月 22 2017 sbin
drwxr-xr-x. 4 kris kris 4096 5月 22 2017 share
重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
2. Hadoop运行环境搭建
环境的准备
如果是克隆的虚拟机需要做的是改用户名、静态IP、物理地址
1. 改用户名:
编辑vim /etc/sysconfig/network #sentos6.8
改HOSTNAME=那一行
NETWORKING=yes
HOSTNAME=hadoop101
vim /etc/hostname #sentos7
hadoop101
2. 设置静态IP
改ip: 编辑vim /etc/sysconfig/network-scripts/ifcfg-eth0
改成
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="eth0"
IPADDR=192.168.1.101
PREFIX=24
GATEWAY=192.168.1.1
DNS1=192.168.1.1
3. 改物理地址
删除第一行的“eth0”, 并将第二行的eth1改为 “eth0”
[root@hadoop101 桌面]# vim /etc/udev/rules.d/70-persistent-net.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:5f:8e:d9", ATTR{type}=="1", KERNEL=="eth*",
NAME="eth0"
如果是新创建的虚拟机,额外的操作为
合理配置内存和硬盘, 比如内存4G,硬盘50G
1. 安装好linux
/boot 200M
/swap 2g
/ 剩余
2. 安装VMTools
3. 关闭防火墙
sudo service iptables stop
sudo chkconfig iptables off
配置/etc/hosts
vim /etc/hosts
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
192.168.1.109 hadoop109
创建一个一般用户kris,给他配置密码
useradd kris
passwd kris
配置这个用户为sudoers
vim /etc/sudoers
在root ALL=(ALL) ALL
添加kris ALL=(ALL) NOPASSWD:ALL
保存时wq!强制保存
在/opt目录下创建两个文件夹module和software,并把所有权赋给kris
mkdir /opt/module /opt/software
chown kris:kris /opt/module /opt/software
关机,快照,克隆
从这里开始要以一般用户登陆
搞一个分发脚本 cd ~ vim xsync 内容如下:
#!/bin/bash
#xxx /opt/module
if (($#<1))
then
echo '参数不足'
exit
fi
fl=$(basename $1)
pdir=$(cd -P $(dirname $1); pwd)
for host in hadoop102 hadoop103
do
rsync -av $pdir/$fl $host:$pdir
done
修改文件权限,复制移动到/home/kris/bin目录下
chmod +x xsync
配置免密登陆
1. 生成密钥对
[kris@hadoop101 ~]$ cd .ssh
[kris@hadoop101 .ssh]$ ssh-keygen -t rsa
ssh-keygen -t rsa 三次回车
2. 发送公钥到本机
ssh-copy-id hadoop101 输入一次密码
3. 分别ssh登陆一下所有虚拟机
ssh hadoop102
exit
ssh hadoop103
exit
4. 把/home/kris/.ssh 文件夹发送到集群所有服务器
xsync /home/kris/.ssh ##发送.ssh/是不会成功的;不要加最后的/
在一台机器上安装Java和Hadoop,并配置环境变量,并分发到集群其他机器
配置环境变量,在文件末尾添加 sudo vim /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source使得配置文件立即生效
source /etc/profile
[kris@hadoop101 module]$ sudo xsync /etc/profile //将配置文件发送到其他机器
sudo:xsync:找不到命令
[kris@hadoop101 module]$ sudo scp /etc/profile root@hadoop102:/etc/profile
[kris@hadoop101 module]$ sudo scp /etc/profile root@hadoop103:/etc/profile
在hadoop102/hadoop103各执行 source/etc/profile
在其他机器分别执行source /etc/profile
配置文件的配置
pwd $JAVA_HOME
$HADOOP_HOME/etc/hadoop
配置hadoop-env.sh,yarn-env.sh,mapred-env.sh文件,配置Java_HOME
配置Slaves hadoop101 hadoop102 hadoop103
core-site.xml 指定HDFS中NameNode的地址 hdfs://hadoop101:9000;指定Hadoop运行时产生文件的存储目录 /opt/module/hadoop-2.7.2/data/tmp
hdfs-site.xml 指定HDFS数据的副本数量 为3,就3台机器; 这些副本肯定分布在不同的服务器上;指定hadoop辅助名称节点(secondaryNameNode)主机配置 hadoop103:50090;
mapred-site.xml 指定历史服务器地址hadoop103:10020;历史服务器web端地址hadoop103:19888; 指定MR运行在YARN上;
yarn-site.xml Reducer获取数据的方式;指定YARN的ResourceManager的地址(服务器)hadoop102;日志聚集功能使用,日志保留时间设置为7天;
###所有配置文件都在$HADOOP_HOME/etc/hadoop
14. 首先配置hadoop-env.sh,yarn-env.sh,mapred-env.sh文件,配置Java_HOME
在每个文件第二行添加 export JAVA_HOME=/opt/module/jdk1.8.0_144
15. 配置Core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
16. 配置hdfs-site.xml
<!-- 数据的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
17. 配置yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
18. 配置mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop103:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop103:19888</value>
</property>
启动历史服务器:mr-jobhistory-daemon.sh start historyserver
19. 配置slaves;配置时多一个空格/空行都不可以;
hadoop101
hadoop102
hadoop103
20. 分发配置文件
xsync /opt/module/hadoop-2.7.2/etc
21. 格式化Namenode 在hadoop102
在hadoop101上启动 hdfs namenode -format
22. 启动hdfs
在hadoop101上启动 start-dfs.sh
23. 在配置了Resourcemanager机器上执行
在Hadoop102上启动start-yarn.sh
25 关 stop-dfs.sh stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
3. Hadoop运行模式
包括:本地模式、伪分布式模式以及完全分布式模式。
本地式
可运行的程序只有MapReduce(程序);而yarn(内存和cup),HDFS(硬盘)是给MapReduce提供运行的环境;
本地式用的不是hdfs,而是本地的硬盘;而调度的资源也不是来自yarn而是本地的操作系统;
.xml文件就是输入;grep是执行jar包的哪个主类,一个jar包可以有多个主类和主方法;输入文件夹--输出文件夹(起始没有这个文件夹,否则会报错)--' 模板正则等 '
wordcount是一个主类
伪分布式
一台电脑搭出一个集群;HDFS分3个组建NameNode、DataNode、Secondary NameNode; yarn是分4个组建,实际只搭2个ResourceManage和NodeManager,
既是NameNode也是DataNode;既是ResourceManager也是NodeManager,这些进程都跑在一台机器上;
集群
见之前配置
启动
hdfs namenode -format 格式化HDFS,在hadoop101上; 首次启动格式化 hadoop-daemon.sh start namenode 单独启动NameNode hadoop-daemon.sh start datanode 单独启动DataNode
start-dfs.sh 启动hdfs
start-yarn.sh 启动yarn
启动前必须保证NameNode和DataNode已经启动 启动ResourceManager; 启动NodeManager hadoop fs -put wcinput/ / 往集群的跟目录中上传一个wcinput文件 158 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /output
分发脚本:
[kris@hadoop100 hadoop-2.7.2]$ dirname /opt/module/hadoop-2.7.2/
/opt/module
[kris@hadoop100 hadoop-2.7.2]$ dirname hadoop-2.7.2
.
[kris@hadoop100 hadoop-2.7.2]$ cd -P .
[kris@hadoop100 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
遍历所有的主机名
##########集群分发脚本
#!/bin/bash
#xxx /opt/module
if (($#<1))
then
echo '参数不足'
exit
fi
fl=$(basename $1) #文件名 basename /opt/module/hadoop-2.7.2/-->>hadoop-2.7.2
pdir=$(cd -P $(dirname $1); pwd) 父目录 dirname /opt/module/hadoop-2.7.2/ --->> /opt/module
for host in hadoop102 hadoop103 hadoop104
do
rsync -av $pdir/$fl $host:$pdir
done
scp安全拷贝、rsync远程同步工具
[atguigu@hadoop101 /]$ scp -r /opt/module root@hadoop102:/opt/module //-r是递归; 要拷贝的-->目的地
[atguigu@hadoop103 opt]$ scp -r atguigu@hadoop101:/opt/module root@hadoop104:/opt/module //可在不同服务之间传输;
[atguigu@hadoop101 opt]$ rsync -av /opt/software/ hadoop102:/opt/software //rsync只能从本机到其他 ;-a归档拷贝、-v显示复制过程
用scp发送
scp -r hadoop100:/opt/module/jdk1.8.0_144 hadoop102:/opt/module/
用rsync发送
[kris@hadoop100 module]$ rsync -av hadoop-2.7.2/ hadoop102:/opt/module/ 把当前目录下的全发过去了;-a归档拷贝、-v显示复制过程;
[kris@hadoop102 module]$ ls
bin include jdk1.8.0_144 libexec NOTICE.txt README.txt share
etc input lib LICENSE.txt output sbin wcinput
[kris@hadoop102 module]$ ls | grep -v jdk
过滤删除只剩jdk的
[kris@hadoop102 module]$ ls | grep -v jdk | xargs rm -rf
[kris@hadoop100 module]$ ll
总用量 12
drwxr-xr-x. 12 kris kris 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 kris kris 4096 7月 22 2017 jdk1.8.0_144
-rw-rw-r--. 1 kris kris 223 1月 15 17:13 xsync
[kris@hadoop100 module]$ chmod +x xsync
[kris@hadoop100 module]$ ll
总用量 12
drwxr-xr-x. 12 kris kris 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 kris kris 4096 7月 22 2017 jdk1.8.0_144
-rwxrwxr-x. 1 kris kris 223 1月 15 17:13 xsync
[kris@hadoop100 module]$
[kris@hadoop100 module]$ ./xsync /opt/module/jdk1.8.0_144
注意:拷贝过来的/opt/module目录,别忘了在hadoop101、hadoop102、hadoop103上修改所有文件的,所有者和所有者组。sudo chown kris:kris -R /opt/module
拷贝过来的配置文件别忘了source一下/etc/profile 。
配置ssh无秘钥登陆;
[kris@hadoop100 module]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/kris/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/kris/.ssh/id_rsa.
Your public key has been saved in /home/kris/.ssh/id_rsa.pub.
The key fingerprint is:
fd:15:a4:68:6e:88:c3:a1:f4:64:1b:aa:95:12:02:4a kris@hadoop100
The key's randomart image is:
+--[ RSA 2048]----+
|.E . |
|+ . o |
|o . . = o . . |
| . o O = = . |
| . = * S + . |
| + . . . . |
| . . |
| |
| |
+-----------------+
[kris@hadoop100 module]$ ssh-copy-id hadoop100 #给自己也发一份
[kris@hadoop100 module]$ ssh-copy-id hadoop101
[kris@hadoop100 module]$ ssh-copy-id hadoop102
[kris@hadoop100 module]$ ssh-copy-id hadoop103
[kris@hadoop100 module]$ ssh-copy-id hadoop104
100给100、101、102、103、104都赋权了;100<==>100双向通道已经建立,我能到自己了;可以把这个双向通道copy给其他的;
[kris@hadoop100 .ssh]$ ll
总用量 16
-rw-------. 1 kris kris 396 1月 15 18:45 authorized_keys 把公钥放在已授权的keys里边,它跟公钥里边内容是一样的;
-rw-------. 1 kris kris 1675 1月 15 18:01 id_rsa 秘钥
-rw-r--r--. 1 kris kris 396 1月 15 18:01 id_rsa.pub 公钥
-rw-r--r--. 1 kris kris 2025 1月 15 17:37 known_hosts
[kris@hadoop102 .ssh]$ ll
总用量 4
-rw-------. 1 kris kris 396 1月 15 18:04 authorized_keys
[kris@hadoop100 module]$ ./xsync /home/kris/.ssh #给其他账户发送.ssh ;发送 .ssh/
sending incremental file list
.ssh/
.ssh/id_rsa
.ssh/id_rsa.pub
.ssh/known_hosts
sent 4334 bytes received 73 bytes 8814.00 bytes/sec
total size is 4096 speedup is 0.93
sudo cp xsync /bin #copy到bin目录,就可全局使用;
[kris@hadoop100 module]$ xsync /opt/module/hadoop-2.7.2/
清理数据(每一台):
[kris@hadoop100 ~]$ cd $HADOOP_HOME
[kris@hadoop100 hadoop-2.7.2]$ rm -rf data logs
101 102 103
NameNode ResourceManager SecondaryNameNode
DataNode DataNode DataNode
NodeManager NodeManager NodeManager
格式化创建namenode hdfs namenode -format
在101上启动HDFS: start-dfs.sh (101namenode)
在Hadoop102上启动 start-yarn.sh
关闭:
[kris@hadoop101 hadoop-2.7.2]$ stop-dfs.sh
Stopping namenodes on [hadoop101]
hadoop101: stopping namenode
hadoop101: stopping datanode
hadoop102: stopping datanode
hadoop103: stopping datanode
Stopping secondary namenodes [hadoop103]
hadoop103: stopping secondarynamenode
[kris@hadoop102 hadoop-2.7.2]$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
hadoop102: stopping nodemanager
hadoop103: stopping nodemanager
hadoop101: stopping nodemanager
no proxyserver to stop
jpsall脚本:
#!/bin/bash
for i in hadoop101 hadoop102 hadoop103
do
echo "-------$i-------"
ssh $i "source /etc/profile && jps" | grep -v jps
done
Windows中hosts的配置
在windows系统中,HOST文件位于系统盘C:\Windows\System32\drivers\etc中
Hosts是一个没有扩展名的系统文件,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”。
hosts文件能加快域名解析,对于要经常访问的网站,我们可以通过在Hosts中配置域名和IP的映射关系,提高域名解析速度。
hosts文件可以方便局域网用户在很多单位的局域网中,可以分别给这些服务器取个容易记住的名字,然后在Hosts中建立IP映射,这样以后访问的时候,只要输入这个服务器的名字就行了。
hosts文件可以屏蔽一些网站,对于自己想屏蔽的一些网站我们可以利用Hosts把该网站的域名映射到一个错误的IP或本地计算机的IP,这样就不用访问了。
根据这个HOSTS文件的作用看的出来 ,如果是别有用心的病毒把你的HOSTS文件修改了!(例如把一个正规的网站改成一个有病毒的网站的IP)。那么你就会打开一个带有病毒的网站,你可想而知你的后果了吧!
查看Windows IP 配置
C:\Users\Administrator>ipconfig /displaydns
修改hosts后生效的方法:Windows 开始 -> 运行 -> 输入cmd -> 在CMD窗口输入 ipconfig /flushdns
Linux 终端输入: sudo rcnscd restart

host中的配置没有被识别到,那么是否是因为字符或者换行等原因呢?于是:
查看了host文件的字符:

发现其结尾是CR而没有LF,这不符合windows下面的换行风格,所以将其风格进行转换。notepad中转换方式:
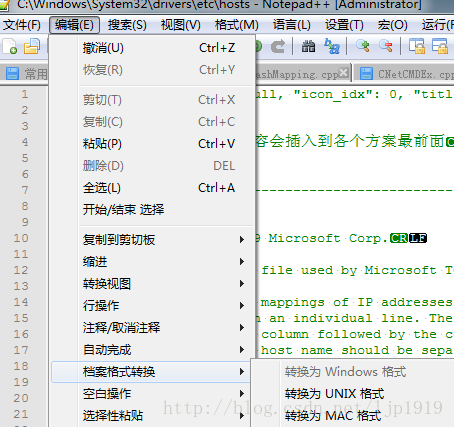
转换风格之后:
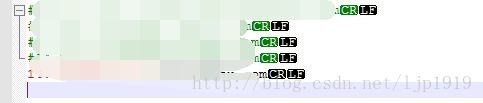
至此,可以实现对该域名的ip配置。此外还需要注意:ip地址与域名间至少要有一空格,另外在最后一行书写映射时一定要加上回车再保存以避免最后一行不生效。
Hadoop默认端口及其含义
fs.defaultFS 访问 HDFS 文件系统的 URI 加一个 RPC 端口, 不加端口的话,默认是 8020, 或者 9000
ResourceManager 服务启动后,会默认启动一个 http 端口 8088
Jobhistoryserver 服务的命令变成了 mapred,而非 yarn。这是因为 Jobhistoryserver 服务是基于 MapReduce 的,Jobhistoryserver 服务启动后,会运行一个 http 端口,默认端口号是 19888,可以通过访问此端
口查看每个任务的历史运行情况
1)dfs.namenode.http-address:50070
2)SecondaryNameNode辅助名称节点端口号:50090
3)dfs.datanode.address:50010
4)fs.defaultFS:8020 或者9000
5)yarn.resourcemanager.webapp.address:8088
|
|
hadoop2.x |
Hadoop3.x |
|
访问HDFS端口 |
50070 |
9870 |
|
访问MR执行情况端口 |
8088 |
8088 |
|
历史服务器 |
19888 |
19888 |
|
客户端访问集群端口 |
9000 |
8020 |


