
关于大型网站技术演进的思考(十九)--网站静态化处理—web前端优化—上(11)
网站静态化处理这个系列马上就要结束了,今天我要讲讲本系列最后一个重要的主题web前端优化。在开始谈论本主题之前,我想问大家一个问题,网站静态化处理技术到底是应该归属于web服务端的技术范畴还是应该归属于web前端的技术范畴,要回答清楚这个问题我们要明确下网站应用的本质到底是什么?网站的本质其实就是BS,这里的BS我没有带上架构二字,而就是指Browser和Server即浏览器和服务器,而网站静态化技术的作用目标就是让客户端即浏览器的用户体验更好,但是如果我们想让网站在浏览器上运行的更快,在更快的基础上能设计更多更好的用户体验功能,那么我们需要做的工作其实就不仅仅是着眼于浏览器本身,而是要把和浏览器相关的一切作用因子结合在一起考虑,这就是网站静态化技术的本源所在,所以有些朋友认为网站静态化技术其实是一个服务端技术多于web前端的技术,因此认为网站静态化技术是不属于web前端的范畴,我认为这种理解是不正确的,我想产生这种误导的原因是很多人都是狭义的理解web前端技术,认为web前端就是以javascript、css以及html所代表的技术,超出这个范畴的技术就不应该属于web前端范畴,我个人觉得这种理解也无可厚非,但是这种理解可能会让那些有追求的前端工程师产生一个不好的后果,这个后果就是不灵活的划分自己需要掌握的技术范畴,最终影响自身技术能力的突破,不管是web前端还是web服务端都应该把做好优秀的网站为己任。BS本身就是一个整体,只有二者结合起来才能产生网站,缺少其中任何一方,那又何来的网站呢?BS中的S就犹如蝴蝶效益里蝴蝶的翅膀,虽然蝴蝶看起来只是在亚马逊雨林轻轻的挥动了一下,可是这个挥动却能让相距千万里的太平洋上刮起可怕的飓风,因此本人对web前端有个新的认识,我们不应该把前端只是局限于javascript、css和html这些技术之上,而是应该把自己当做浏览器应用开发专家,一切用作于浏览器的技术和手段都是web前端工程师需要掌握的知识,就像时下的nodejs出现,逼得前端工程师不得不去做服务端开发,不要觉得这是被迫的,而要把它当做web前端的逆袭,认为这是理所当然的事情。
好了,我们现在回到web前端优化这个主题吧。Web前端优化技术的普及还是要归功于互联网两大巨头雅虎和谷歌的贡献,他们通过多年的积累和总结,将这些web前端优化的经验无偿的公布给全世界,从而推动了web前端的发展,这些技术都不是什么秘密,我在网上找到一篇讲解这些技巧的文章,文章就是《Web前端优化最佳实践及工具集锦》。
web前端优化技术和网站静态化技术使用目的是一致的,就是让网站变得更快,用户体验更好,我个人认为网站静态化技术其实就是web前端优化的一部分,只不过网站静态化技术是通过服务端的大规模技术改造来实现web前端技术优化,而服务端的这种改造的目的就是让整个网站的后台技术架构更加切合web前端的要求,从而能更好的实现web前端优化。我这里之所以能如此评价网站静态化技术,其实说明网站静态化技术和web前端优化技术一定存在某种强烈的切合点,我个人认为这个切合点就是它们背后使用的理论基点是一致的。那么它们之间这个切合的理论基点到底是什么呢?
优秀的网站应该是用户体验好的网站,当人们使用这个网站感觉爽,好评不断,那么这个网站就是一个用户体验优秀的网站,但是用户体验好的网站就是网站布局精美,图片很炫,人性化设计到位这么简单吗?这些要素都是网站使用者的感受,但是对于网站设计和开发人员而言,再好的网站一定要解决一个根本问题,那就是网站加载的速度要快,如果网站加载速度不快,你就算把网站设计的再漂亮,估计也会搞的无人问津,说到这里,是不是有较真的朋友不信我的结论呢?我把前面引用文章里的一张图再给大家瞧瞧,如下图所示:
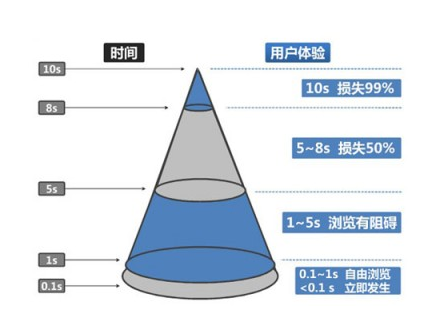
其实当我们开发网站如果只考虑如何把网站做的漂亮而忽视网站的性能,我们就会发现漂亮的网站和网站的性能其实是矛与盾的关系,例如精美的图片往往需要高质量的图片格式,而高质量的图片格式就意味图片会变得很大,那么在图片通过网络加载时候就需要花费更多的时间,所以我们在设计和开发优秀网站时候,漂亮和效率是需要我们认真权衡的,认真思考的,最终要找到一个最好的方式实现二者的平衡,同时更加充分的发挥双方的潜在价值。而直观的用户体验好这其实更多的是一个设计问题,而解决用户体验好的根基:速度问题,这就是一个技术问题了。
要解决网站的速度和效率问题,那么我们就得思考网站的载体计算机到底哪些因素会影响网站的速度和效率。其实计算机的本质很简单,那就是计算和存储,计算主要是CPU来完成,而计算机用于存储的介质就多了,它们主要是内存、硬盘,如果是网站应用还有个很关键的存储介质需要考虑那就是网络了。那么计算机用于计算和存储的这些介质的效率是怎样的一个情况呢?这个问题我在以前一篇文章里有过阐述,这篇文章就是《关于如何提高Web服务端并发效率的异步编程技术》
这篇文章的其他内容太多了,我把关键部分在本文摘抄一遍,内容如下:
对于一个网络请求的处理,是由两个不同类型的操作共同完成,这两个操作是CPU的计算操作和IO操作,如果我们以处理效率角度来评判这两个操作,CPU操作效率是光速的,而IO操作就不尽然了,计算机里的IO操作就是对存储数据介质的操作,计算机里有如下几个介质可以存储数据,它们分别是:CPU的一级缓存、二级缓存、内存、硬盘和网络,一级缓存存储和读取数据的能力接近光速,它比二级缓存快个5倍到6倍,但是不管是一级缓存还是二级缓存,它们存储数据量太少了,做不了什么大事情,下面就是内存了,以一级缓存的效率做参照,一级缓存比内存速度快100多倍,到了硬盘存储和读取数据效率就更慢了,一级缓存比硬盘要快1000多万倍,到了网络就慢的更不像话了,一级缓存比网络要快一亿多倍,可见一个请求处理的效率瓶颈都是由IO引起的。
由此可见网站的速度和效率问题似乎都是由存储即IO造成的。不过我们不能因为感觉发现问题根源在于存储,而就忽视对CPU的思考,所以我先讲讲CPU和网站性能的关系吧。CPU是计算机用于做计算的设备,现在的电脑能看电影,能听歌,可以和朋友聊天,还能用于工作,这些令人称奇的功能其实到了CPU这里也就是通过加减乘除这类基本的数学运算完成的,说到这个真是难以让人想象,读书时候学数学总是觉得那么枯燥乏味,没想到如此强大的人类神器居然就是通过数学运算得来的,难怪有国外科学家说宇宙都是通过数学运算得来的,这还是有道理的。不过网站背后的数学运算却有着自己的特点,虽然CPU计算能力很强,但是在实际场景下很多业务的计算其实很消耗时间的,如果网站某些请求响应背后的运算是需要消耗太多的时间,那么这个时候CPU也就会成为网站性能的瓶颈所在,网站应用有个重要的特点,这个特点有个专有名词描述那就是网站的实时性,根据网站实时性的特点,那么就要求我们网站每个请求所包含的计算都要简单和快捷,简单快捷的计算也就让每个请求背后所包含的业务性运算要更加简单,这也就是为什么很多人会说互联网的网站和企业的web应用相比,互联网的业务逻辑比较简单的道理,但是随着网站的规模扩大,业务模式越来越丰富,这个时候网站在某些业务环节不可避免的变得复杂,假如这些复杂的业务又需要实时的反应给用户,那么CPU不能快速完成业务计算就是网站的效率问题的根源了,例如我在存储系列里说到的海量数据的计算操作,就是这样的场景之一,那么这个时候我们该如何来做了?
碰到这个问题,我们首先要明确一个问题,计算出现了瓶颈,那么最直接的手段就是增加计算机的计算能力,比如使用运算更快的CPU,但是更快的CPU面对快速增长的业务而言,增加的效率是非常有限的,所以在CPU这块出现了多核技术,我们可以把一个计算任务拆分成诺干个子运算,这些子运算在不同CPU上计算,最终把结果汇总起来,但是这个手段和用更快的CPU手段一样,面对快速增长的业务很快就会达到性能瓶颈,最终我们发现我们的业务计算任务其实已经超出了单机计算机的能力,如是乎分布式技术出现了,我们这回不再是在CPU上做文章了,而是使用多台计算机联合计算,但是分布式计算系统是需要网络进行互联的,而网络是计算和存储里最大的短板,再加以现在互联网的所使用的计算资源规模达到了超乎想象的程度,我们发现想通过扩展计算机的计算能力来解决网站快速响应的问题基本是一件无法完成的任务,那么这个时候我们又该怎么办呢?
这个时候我们就要转化思路了,因为当网站的计算瓶颈问题已经到了这个地步了,我们再去更加深入挖掘计算机的计算能力这对最终的结果影响已经意义不大了,因此我们只能从计算的相关方哪里寻找问题的解决方案。那什么是相关方呢?仔细分析计算相关方的确太多了,但是有一个最根本的相关方就是用户的实际业务需求了,用户可能认为自己的业务需求都是很明确的,例如电商里的用户想查询自己的交易数据,但是这个业务问题转移到网站的开发人员和业务人员,面对这么多用户的交易查询那就是一个超级复杂的计算问题,如是网站的业务和开发人员就会根据自己系统本身的特点和问题,进一步思考用户业务计算问题的本质,谈论业务计算本质这个问题如果展开细化是非常复杂的,因为现实的业务场景实在是太多太复杂了,但是放到网站实时计算这个角度,其实有一个很简单的解决思路,我们回顾下我们前面讨论的计算瓶颈问题,其实这个问题的本质不是计算能否成功完成的问题,而是计算是否能及时完成的问题,如果用户的请求计算的确是没法很快完成,那么我们就不要让用户觉得这个计算是能很快的完成,这个做法也有一个专有名词那就是异步计算,但是如果我们把难以快速完成的计算都这么来处理,虽然让用户感觉网站已经很坦诚的告诉自己能力有限啊,但是苛刻的用户可不一定会买这个账,因此当有同类型网站使用新的技术手段解决了快速实时计算问题后,假如我们的网站还是驻步不前,那么后果就会很严重了,那么这个时候我们又该如何突破了?
那么我们就得进一步思考计算本身到底哪里出现了影响速度的问题,计算本身包含三个方面,首先是用于计算的计算资源,再就是做运算的工具即CPU,最后是计算的最终结果,如果业务计算慢的原因是因为数据量太大了,CPU很难快速完成,那么这个时候我们有一些手段可以解决这个问题,我们可以把海量数据做一个分类,例如存储系列里说的历史交易数据和当日交易数据的分类,当日数据因为数据量有限在一定条件下可以快速计算出来,面对历史数据,如果我们的计算结果最终是很简单的而且在一定时间范围里是不会变化的,那么我们可不可以这么考虑,让这些结果提前计算出来,然后将结果存储在效率更高的存储设备里例如内存,当用户请求操作这个业务计算时候我们只需要直接读取缓存里的计算结果就行了,这样就避免了计算,同时计算结果存储在效率高效的缓存里,用户获得响应的速度也会快多了,这个其实就是网站静态化技术里ESI技术背后的深意了。
当然当我们要解决网站性能问题,不太可能单独从计算或者存储一个维度来思考,一般都是把双方放在一起思考,按照我前面提到计算和存储介质的效率问题,我们发现存储其实是最容易影响网站效率的痛点,实际情况也是如此,当网站发生计算瓶颈问题之前,更多的效率问题还是由存储所导致的,而且复杂计算过程也是需要存储参入才能正常完成,例如计算过程里的中间结果当超出CPU缓存大小后我们就不得不将中间结果放到内存里,当内存也不够的时候我们就得放到硬盘里,所以解决计算效率问题也受到存储性能很大的影响。假如我们还是按照木桶理论来理解这个问题,我们发现不管是单纯的存储问题还是计算和存储混合的问题,最终的短板都是其中效率最差的哪一方,而计算和存储里效率最差的一方就是网络了,不过有些马虎的朋友可能说现在宽带好快了,我在网上下载一部几个G的电影也就几十秒,甚至有时比我硬盘拷贝还快,像你说网络是最大的短板其实不准确的,这位朋友的想法的确有他的道理,但是不是每个人使用的网络都是你那么快呢,而且现在移动互联网已经普了及,移动互联网速度比普通宽带就差多了,而且你在移动设备上使用网络流量越大,成本也就越高,如果你认为我说的这些问题都不算啥,网络还和地域的距离有关,你宽带很快,你想访问大洋彼岸美国的网站(这个网站在中国没有任何缓存处理),访问速度肯定还是快不起来,而且互联网的连通路径本身也很复杂,例如你感觉自己访问的是一个上海本土的网站,但是这个网站说不定好多重要服务器是放置在北京,这么复杂的网络环境,这么多不可控的因素还会影响网络的传输效率,网络谈何能说自己性能比硬盘强呢?
由此我们就可以发现谷歌和雅虎总结的web前端优化技巧以及我这里谈的网站静态化技术大部分都是围绕如何解决网络传输效率来进行了,因为它是整个木桶最大的短板,我们只有首先解决了这个短板,那么再去解决其他因素的效率问题,才能发挥其作用。这里的这个解释也可以解答前不久一个网友问我,为什么我讲网站优化很少讲解如何编写高效的代码,而都是从一些和代码无关的角度来阐述的了,其实你想通过代码优化提升网站性能,你首先要解决好对网站效率影响更大更关键的要素例如网络通讯问题,否则你代码优化的再好,对最终效果影响都是有限的。
看来本文今天写不完了,关于存储和web前端优化的内容我将在下一篇文章进一步讨论。最后祝大家晚安,生活和工作愉快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号