

solr6.6 导入 pdf/doc/txt/json/csv/xml文件
文本主要介绍通过solr界面dataimport工具导入文件,包括pdf、doc、txt 、json、csv、xml等文件,看索引结果有什么不同。其实关键是managed-schema、solrconfig.xml和data-config.xml(需要创建)这三个配置文件。
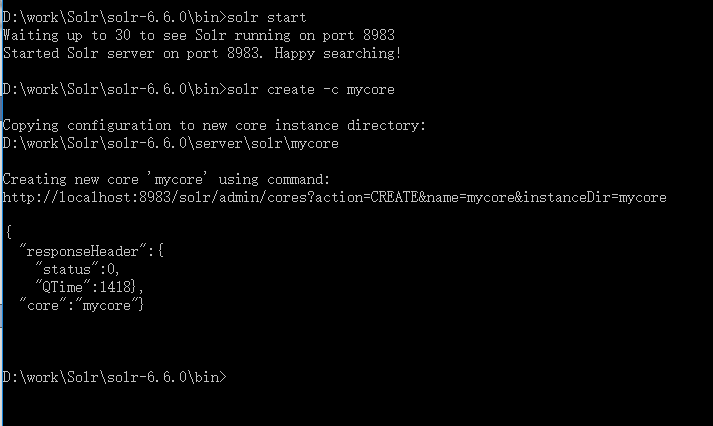
1、创建core
启动solr,创建mycore
solr start
solr create -c mycore
2、修改配置
2.1、创建data-config.xml文件
找到刚才创建的mycore文件夹,solr-6.6.0\server\solr\mycore,在下面的conf文件夹下建立data-config.xml文件,具体参见文件夹下solr-6.6.0\example\example-DIH\solr\tika\conf\tika-data-config.xml的内容:
<dataConfig> <dataSource type="BinFileDataSource"/> <document> <entity name="file" processor="FileListEntityProcessor" dataSource="null" baseDir="${solr.install.dir}/example/exampledocs" fileName=".*pdf" rootEntity="false"> <field column="file" name="id"/> <entity name="pdf" processor="TikaEntityProcessor" url="${file.fileAbsolutePath}" format="text"> <field column="Author" name="author" meta="true"/> <!-- in the original PDF, the Author meta-field name is upper-cased, but in Solr schema it is lower-cased --> <field column="title" name="title" meta="true"/> <field column="dc:format" name="format" meta="true"/> <field column="text" name="text"/> </entity> </entity> </document> </dataConfig>
修改如下:
<dataConfig> <dataSource type="BinFileDataSource"/> <document> <entity name="file" processor="FileListEntityProcessor" dataSource="null" baseDir="D:/work/Solr/Import" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)" rootEntity="false"> <field column="file" name="id"/> <field column="fileSize" name="fileSize"/> <field column="fileLastModified" name="fileLastModified"/> <field column="fileLastModified" name="fileLastModified"/> <field column="fileAbsolutePath" name="fileAbsolutePath"/> <entity name="pdf" processor="TikaEntityProcessor" url="${file.fileAbsolutePath}" format="text"> <field column="Author" name="author" meta="true"/> <!-- in the original PDF, the Author meta-field name is upper-cased, but in Solr schema it is lower-cased --> <field column="title" name="title" meta="true"/> <field column="text" name="text"/> </entity> </entity> </document> </dataConfig>
fileName :(必选)使用正则表达式匹配文件
baseDir : (必选) 文件目录
recursive : 是否递归的获取文件,默认false
rootEntity :在这里必须是false(除非你只想索引文件名)。在默认情况下,document元素下就是根实体了,如果没有根实体的话,直接在实体下面的实体将会被看做跟实体。
对于根实体对应的数据库中返回的数据的每一行,solr都将生成一个document
dataSource :如果你是用solr1.3,那就必须设为"null",因为它没使用任何dataSourde。不需要在solr1.4中指定它,它只是意味着我们不创建一个dataSource实例。在大多数情况下,
只有一个DataSource(JdbcDataSource),当使用FileListEntityProcessor 的时候DataSource不是必须的
processor:只有当datasource不是RDBMS时才是必须的
onError :默认是"abort","skip"表示跳过当前文档,"continue"表示对错误视而不见
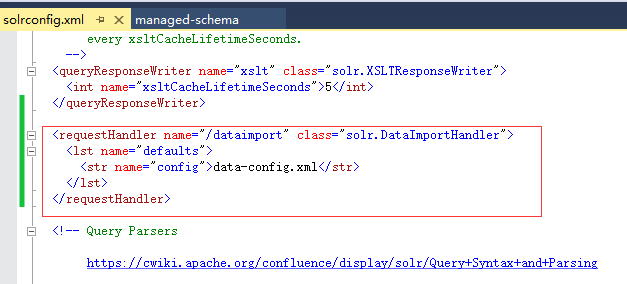
2.2、修改solrconfig.xml文件
增加如下内容:
<requestHandler name="/dataimport" class="solr.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
2.3、修改managed-schema
配置中文词库,具体参见:http://www.cnblogs.com/shaosks/p/7843218.html,增加如下内容:
<!-- mmseg4j fieldType--> <fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" /> </analyzer> </fieldType> <fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" /> </analyzer> </fieldType> <fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" /> </analyzer> </fieldType>
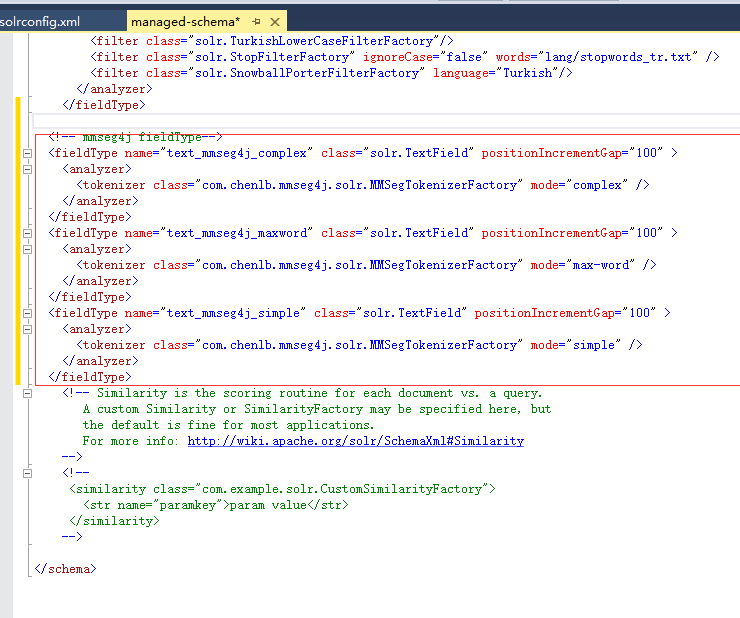
增加以下三列,因为id列默认已经有了,不用创建,注意title和text两个字段的类型用了上面的text_mmseg4j_complex
<field name="title" type="text_mmseg4j_complex" indexed="true" stored="true"/> <field name="text" type="text_mmseg4j_complex" indexed="true" stored="true" omitNorms ="true"/> <field name="author" type="string" indexed="true" stored="true"/> <field name="fileSize" type="long" indexed="true" stored="true"/> <field name="fileLastModified" type="date" indexed="true" stored="true"/> <field name="fileAbsolutePath" type="string" indexed="true" stored="true"/>
3、建立依赖的jar包
在mycore下面建立lib文件夹, 然后往lib目录copy一些 DIH依赖的jar包,这些包要么在solr-6.6.0\contrib\extraction\lib下面,要么在solr-6.6.0\dist下面,
样做的好处是每个core依赖的jar包都存放在各自core的子目录下分类存放,更方便管理,全部扔WEB-INF\lib下杂乱无章不好管理。如图:

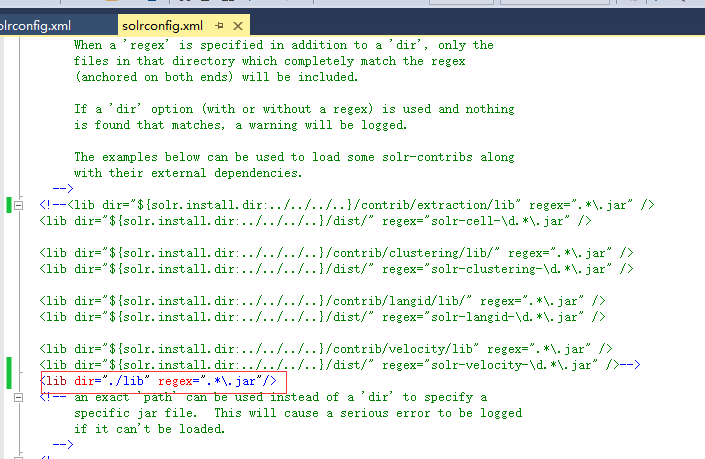
再修改solrconfig.xml文件
增加
<lib dir="./lib" regex=".*\.jar"/>
4、准备导入的pdf文件
在solr-6.6.0\bin的同级文件夹solr-6.6.0\ImportData下面有要导入的文件:

5、导入pdf
重启solr,打开浏览器,进入 solr导入界面导入pdf数据


6、查询数据
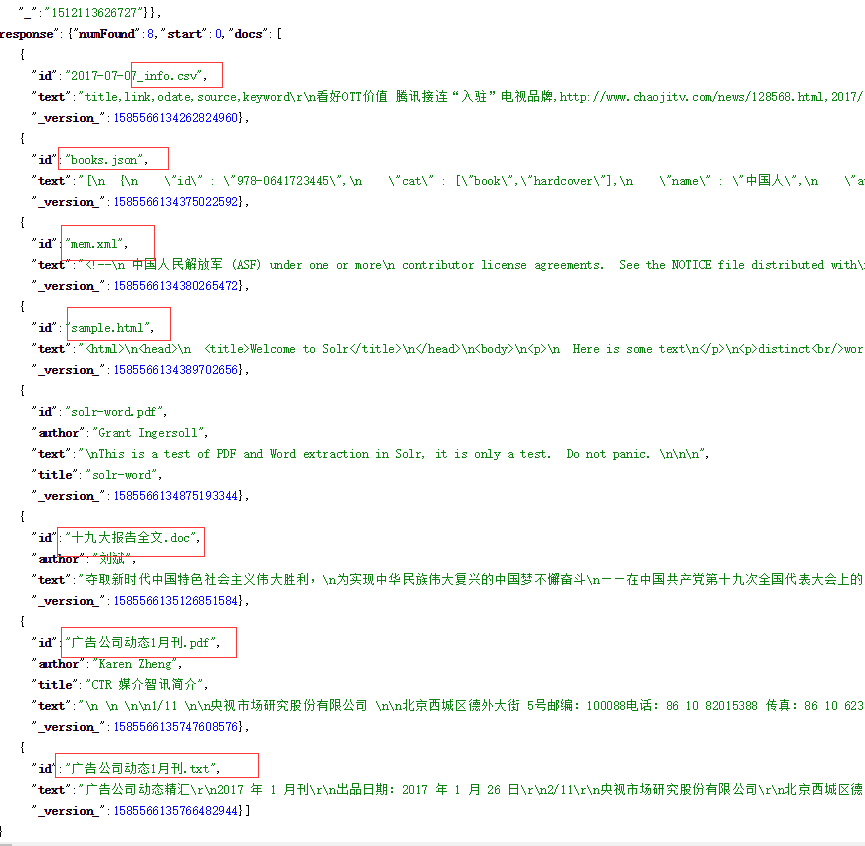
从索引结果可以看出,每种不同的文件,所有文件的主要内容都集中到text这一个字段中。索引这种索引方式适合doc,pdf,txt,html等这种非结构化文档,而对json、csv和json这种结构化文档就不合适了。
但是这种方式在索引docx格式的word文档发生问题,抽取不到数据,这个还不知道什么原因


