


20145218 《信息安全系统设计基础》第3周学习总结
20145218 《信息安全系统设计基础》第3周学习总结
教材学习内容总结
第二章 信息的表示和处理
- 计算机存储和处理信息以二值信号表示。
- 三种最重要的数字表示法
- 无符号:基于传统的二进制表示法,大于等于0
- 补码:有符号整数
- 浮点数:实数的科学计数法的以二进制为基数的版本
- 缓冲区溢出漏洞:计算机的表示法是用有限数量的位来对应一个数字编码,当结果太大不能表示时就会发生溢出。人为的溢出是有一定企图的,攻击者写一个超过缓冲区长度的字符串,植入到缓冲区这时可能会出现两种结果:一是过长的字符串覆盖了相邻的存储单元,引起程序运行失败,严重的可导致系统崩溃;另一个结果就是利用这种漏洞可以执行任意指令,甚至可以取得系统root特级权限。
2.1信息存储
字长
- 机器级程序将存储器视为一个非常大的字节数组,称为虚拟存储器。存储器的每个字节都能由唯一的数字来标识,称为地址。字长用来指明整数和指针数据的标称大小,虚拟地址空间的大小由字长决定,对于一个字长为w位的机器而言,虚拟地址的范围为0-2^w-1。
数据大小
- 程序可移植性的要求是使程序对不同数据类型的确切大小不敏感
- gcc -m32 可以在64位机上生成32位的代码
寻址和字节顺序
- 对于跨越多字节的程序对象,必须建立两个规则:
- 对象的地址是什么
- 在存储器中这些字节如何排列
- 多字节对象被存储为连续的字节序列,对象的地址为
所使用字节中最小的地址 - 大端法&小端法:最低有效字节在最前面的方式称为小端法,最高有效字节在最前面的方式称为大端法。字节顺序是网络编程的基础,小端是“高对高、低对低”,大端与之相反。
- 字节顺序可见的三种情况:
- 网络应用程序代码编写时必须遵循已建立的关于字节顺序的规则
- 反汇编器显示(确定可执行文件所表示的指令序列的工具)
- 编写规避正常的类型系统的程序时,可以使用强制类型转换来允许一种数据类型引用一个对象
- 练习
#include <stdio.h>
typedef unsigned char *byte_pointer;
void show_bytes(byte_pointer start,int len){
int i;
for(i=0;i<len;i++)
printf(" %.2x",start[i]);
printf("\n");
}
void show_int(int x){
show_bytes((byte_pointer)&x,sizeof(int));
}
void show_float(float x){
show_bytes((byte_pointer)&x,sizeof(float));
}
void show_pointer(void *x){
show_bytes((byte_pointer)&x,sizeof(void *));
}
void test_show_bytes(int val)
{
int ival=val;
float fval=(float)ival;
int *pval=&ival;
show_int(ival);
show_float(fval);
show_pointer(pval);
}
void main()
{
int val;
printf("please enter an int:\n");
scanf("%d",&val);
test_show_bytes(val);
}

使用sizeof来确定对象使用的字节数,sizeof(T)返回存储一个类型为T的对象所需字节数。
布尔代数
- 布尔代数起源于数学领域,是一个用于集合运算和逻辑运算的公式:〈B,∨,∧,¬ 〉。其中B为一个非空集合,∨,∧为定义在B上的两个二元运算,¬为定义在B上的一个一元运算。
- 通过布尔代数进行集合运算可以获取到不同集合之间的交集、并集或补集,进行逻辑运算可以对不同集合进行与、或、非。
- 所有逻辑运算都可以用与、或、非表达(最大式、最小式),而与或非可以用“与非”或“或非”表达,所以,只要一个与非门,就可以完成所有的逻辑运算。
- 位向量:表示有限集合,在实际应用中位向量用来对应集合编码。
- C语言的特性:支持按位布尔运算,确定一个位级表达式的结果的最好方法就是将十六进制转化为二进制进行运算后再转回十六进制。
C语言中的逻辑运算
- || OR
- && AND
- ! NOT
- 只要一个与非门,就可以完成所有的逻辑运算。
- 逻辑运算认为,所有非零参数都为TRUE,参数0为FALSE,返回值分别为1和0。
- 逻辑运算符和对应的位运算之间的重要区别是,如果对第一个参数求值就能确定表达式的结果,那么就不会对第二个参数求值,避免运算。
C语言中的移位运算
- 对于一个位表示为[xn-1,xn-2,…,x0]的操作数x,C表达式x<>k,但是它的行为有点微妙。一般而言,机器支持两种形式的右移:逻辑右移和算术右移。逻辑右移在左端补k个0,得到的结果是[0,…,0,xn-1,xn-2,…,xk]。算术右移是在左端补k个最高有效位的值,得到的结果是[xn-1,…,xn-1,xn-1,xn-2,…,xk]。
2.2整数表示
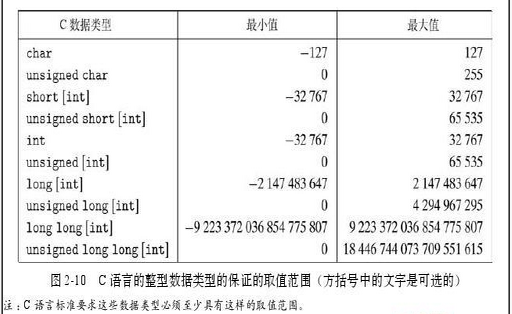
整形数据类型
- C语言支持多种整形数据类型——表示有限范围的整数。
- 要用C99中的“long long”类型,编译是要用 gcc -std=c99
无符号数的编码
- 假设一个整数数据类型有w位。我们可以将位向量写成x→,表示整个向量,或者写成[xw-1 ,xw-2,…,x0],表示向量中的每一位。把x→看做一个二进制表示的数,就获得了x→的无符号表示。
- 无符号二进制有一个很重要的属性,就是每个介于0~2^w-1之间的整数都有唯一一个w为的值编码,函数为一个双射。
补码编码
最常见的有符号数的计算机表示方式就是补码形式。在这个定义中,将字的最高有效位解释为负权。所能表示的数值范围[-2(w-1)~2(w-1)-1],在可表示的范围内每个数字 都有一个唯一的w位的补码编码,函数为一个双射。
注意
- 补码的利用寄存器的长度是固定的特性简化数学运算。想想钟表,12-1 等价于 12 + 11,利用补码可以把数学运算统一成加法,只要一个加法器就可以实现所有的数学运算。
- 补码的范围是不对称的:|TMin| = |TMax| + 1,也就是说,TMin没有与之对应的正数。这导致补码运算的某些特殊的属性,并且容易造成程序中细微的错误。之所以会有这样的不对称性,是因为一半的位模式(符号位设置为1的数)表示负数,而一半的数(符号位设置为0的数)表示非负数。因为0是非负数,也就意味着能表示的正数比负数少一个。
- 最大的无符号数值刚好比补码的最大值的两倍大一点:UMaxw = 2 TMaxw + 1。补码表示中所有表示负数的位模式在无符号表示中都变成了正数。
符号数的其他表示方法
- 反码:除了最高有效位的权是-(2w-1-1)而不是-2w-1,它和补码是一样的

- 原码:最高有效位是符号位用来确定剩下的位应该取负权还是正权。
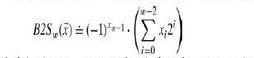
有符号数和无符号数之间的转换
- C语言允许在各种不同的数字数据类型之间做强制类型转换。将负数转换成无符号数可能会得到0。如果转换的无符号数太大以至于超出了补码能够表示的范围,可能会得到TMax。
- C语言允许有符号数与无符号数之间的转换,转换的原则是底层的位表示保持不变。
扩展一个数字的位表示
- 一种常见的运算是在不同字长的整数之间转换,同时又保持数值不变。
- 零扩展:将一个无符号数转换为一个更大的数据类型,只需要简单地在表示的开头添加0。
- 符号扩展:将一个补码数字转换为一个更大的数据类型,规则是在表示中添
加最高有效位的值的副本。由此可知,如果原始值的位表示为[xw-1,xw-2,…,x0],那么扩展后的表示就为[xw-1,…,xw-1,xw-1,xw-2,…,x0]。
截断数字
- 将一个w位的数假设我们不用额外的位来扩展一个数值,而是减少表示一个数字的位数。x=[xw-1 ,xw-2,…,x0]截断为一个k位的数字时,会丢弃高w-k位,得到一个位向量[xk-1 ,xk-2,…,x0],截断一个数字可能会改变他的值——溢出的一种形式。
注意
- 有符号数到无符号数的隐式强制类型转换导致了某些非直观的行为。而这些非直观的特性经常导致程序错误,并且这种包含隐式强制类型转换细微差别的错误很难被发现。因为这种强制类型转换是在代码中没有明确指示的情况下发生的,程序员经常忽视了它的影响。
2.3整数运算
无符号加法
- 考虑两个非负整数x和y,满足0≤x, y≤2w-1。每个数都能表示为w位无符号数字。然而,如果计算它们的和,我们就有一个可能的范围0≤x + y≤2w+1-2。表示这个和可能需要w + 1位。这种持续的“字长膨胀”意味着,要想完整地表示算术运算的结果,要对字长做限制。
- 无符号运算可以被视为一种模运算形式。无符号加法等价于计算和模上2w。可以通过简单的丢弃x + y的w + 1位表示的最高位,来计算这个数值。
- 溢出:一个算术运算溢出,是指完整的整数结果不能放到数据类型的总长限制中去。
补码加法

补码的非
- 范围在-2w-1≤x < 2w-1中的每个数字x都有+wt下的加法逆元。
- 对于范围在[-2(w-1),2(w-1))中的x,补码的非运算有如下两种情况:
x=-2^(w-1)时,为-2^(w-1)x>-2^(w-1)时,为-x
无符号乘法
- 范围在0≤x, y≤ 2w-1内的整数x和y可以表示为w位的无符号数,但是它们的乘积x · y的取值范围为0到(2w-1)2 = 22w-2w+1+1之间。这可能需要2w位来表示。不过,C语言中的无符号乘法被定义为产生w位的值,就是2w位的整数乘积的低w位表示的值。可以看作等价于计算乘积模2w。

- 因此,w位无符号乘法运算* wu的结果为:
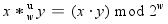
补码乘法
- c语言中的有符号乘法是通过将2w位的乘积截断为w位的方式实现的。也就是说,需要mod 2的w次幂。所以,对于无符号和补码乘法来说,乘法运算的位级表示都是一样的。
乘以常数
- 编译器使用了一项重要的优化,试着用移位和加法运算的组合来代替乘以常数因子的乘法。将整数拆成2的幂相加,再利用移位进行计算(左移),最后将结果相加。同理,对于非负数来说,算术右移k位与除以2^k是一样的。
- 们可以在移位之前“偏置”(biasing)这个值,通过这种方法修正这种不合适的舍入。这种技术利用的属性是:对于整数x和任意y > 0的y,有 「x/y例如,当x = -30且y = 4,我们有x + y - 1 = -27,而 「-30/4我们有x + y - 1 = -29,而 「-32/4这里0 ≤ r < y,得到(x + y - 1)/y = k + ( r + y - 1) / y,因此时,后面一项等于0,而当r > 0时,等于1。也就是说,通过给x增加一个偏量y - 1,然后再将除法向下舍入,当y整除x时,我们得到k,否则,就得到k + 1。因此,对于x < 0,如果在右移之前,先将x加上2k-1,那么我们就会得到正确舍入的结果了。
2.4浮点数
- 浮点表示对形如V = x×2y的有理数进行编码。它对执行涉及非常大的数字(|V |>>0)、非常接近于0(|V |<<1)的数字,以及更普遍地作为实数运算的近似值的计算,是很有用的。
IEEE浮点表示
IEEE浮点标准用V = (-1)^s × M × 2^E的形式来表示一个数:
- 符号:s决定这个数是负数(s=1)还是正数(s=0),而对于数值0的符号位解释作为特殊情况处理。
- 尾数:M是一个二进制小数,它的范围是1~2-ε,或者是0~1-ε。
- 阶码:E的作用是对浮点数加权,这个权重是2的E次幂(可能是负数)。
将浮点数的位表示划分为三个字段,分别对这些值进行编码:
- 一个单独的符号位s直接编码符号s。
- k位的阶码字段exp = ek-1…e1e0编码阶码E。
- n位小数字段frac = fn-1…f1 f0编码尾数M,但是编码出来的值也依赖于阶码字段的值是否等于0。
给定了位表示,根据exp的值,被编码的值可以分为以下三种情况:
-
情况1:规格化的值
当exp的位模式既不全为0(数值0),也不全为1(单精度数值为255,双精度数值为2047)时,都属于这类情况。在这种情况中,阶码字段被解释为以偏置(biased)形式表示的有符号整数。也就是说,阶码的值是E = e-Bias,其中e是无符号数,其位表示为ek-1…e1e0,而Bias是一个等于2k-1-1(单精度是127,双精度是1023)的偏置值。由此产生指数的取值范围,对于单精度是-126~+127,而对于双精度是-1022~+1023。
-
情况2:非规格化的值
当阶码域为全0时,所表示的数就是非规格化形式。在这种情况下,阶码值是E = 1 - Bias,而尾数的值是M = f,也就是小数字段的值,不包含隐含的开头的1。非规格化值要这样设置偏置值的原因是使阶码值为1-Bias而不是简单的-Bias似乎是违反直觉的。我们将很快看到,这种方式提供了一种从非规格化值平滑转换到规格化值的方法。
非规格化数有两个用途:
- 首先,它们提供了一种表示数值0的方法,因为使用规格化数,我们必须总是使M≥1,因此我们就不能表示0。
- 另外一个功能是表示那些非常接近于0.0的数。它们提供了一种属性,称为逐渐溢出,其中,可能的数值分布均匀地接近于0.0。
-
情况3:特殊值
当指阶码全为1的时候出现的。当小数域全为0时,得到的值表示无穷,当s = 0 时是+∞,或者当 s = 1时是-∞。当我们把两个非常大的数相乘,或者除以零时,无穷能够表示溢出的结果。
舍入
- 舍入:因为表示方法限制了浮点数的范围和精度,浮点运算只能近似地表示实数运算。因此,对于值x,我们一般想用一种系统的方法,能够找到“最接近的”匹配值x',它可以用期望的浮点形式表示出来。
- 在两个可能值的中间确定舍入方向:一种可选择的方法是维持实际数字的下界和上界。例如,我们可以确定可表示的值x-和x+,使得x的值位于它们之间:x- ≤ x≤ x+。
- IEEE浮点格式定义了四种不同的舍入方式
- 默认的方法是找到最接近的匹配,而其他三种可用于计算上界和下界。
- 其他三种方式产生实际值的确界。这些方法在一些数字应用中是很有用的。向零舍入方式把正数向下舍入,把负数向上舍入,得到值x^,使得| x ^|≤| x |。向下舍入方式把正数和负数都向下舍入,得到值x-,使得x-≤x。向上舍入方式把正数和负数都向上舍入,得到值x+,满足x≤x+。
浮点运算
IEEE标准指定了一个简单的规则,用来确定诸如加法和乘法这样的算术运算的结果。把浮点值x和y看成实数,而某个运算⊙定义在实数上,计算将产生Round (x ⊙ y),这是对实际运算的精确结果进行舍入后的结果。当参数中有一个是特殊值(如-0、-∞或NaN)时,IEEE标准定义了一些使之更合理的规则。例如,定义1/-0将产生-∞,而定义1/+0会产生+∞。
浮点加法
- 浮点加法是可交换的。
- 浮点加法不具有结合性,这是缺少的最重要的群属性。
- 浮点加法满足了单调性属性:如果a≥b,那么对于任何a、b以及x的值,除了NaN,都有x + a ≥ x + b。无符号或补码加法不具有这个实数(和整数)加法的属性。
浮点乘法
- 浮点乘法是可交换的
- 浮点乘法不具有结合性
- 浮点乘法的单位元为1.0
- 浮点乘法在加法上不具备分配性
- 对于任何a、b和c,并且a、b和c都不等于NaN,浮点乘法满足下列单调性:
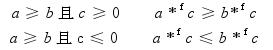
C语言中的浮点数
- 所有的C语言版本提供了两种不同的浮点数据类型:float和double。在支持IEEE浮点格式的机器上,这些数据类型就对应于单精度和双精度浮点。
- 较新版本的C语言,包括ISO C99,包含第三种浮点数据类型long double。对于许多机器和编译器来说,这种数据类型等价于double数据类型。不过对于Intel兼容机来说,GCC用80位“扩展精度”格式来实现这种数据类型,提供了比标准64位格式大得多的取值范围和精度。
- int、float、double相互转换
- int → float 不会溢出但有可能舍入
- int/float → double 结果保留精确数值
- double → float 可能溢出为±∞,由于精确度较小也有可能被舍入
- float/double → int 向零舍入,可能溢出。
课后练习题
- 练习题2.4
- 0x503c+0x8 =
0x5044 - 0x503c-0x40 =
0x4ffc - 0x503c+64 =
0x50a1 - 0x50ea-0x503c=
0xae
- 练习题2.6 写出0x00359141、0x4a564504的二进制表示
- 0x00359141 = 0000 0000 0011 0101 1001 0001 0100 0001
- 0x4a564504 = 0100 1010 0101 0110 0100 0101 0000 0100
- 练习题2.8 a = [01101001],b = [01010101]。计算:
- ~a = [10010110]
- ~b = [10101010]
- a&b = [01000001]
- a|b = [01111101]
- a^b = [00111100]
- 练习题2.11 写一段代码实现一个数组的头尾元素依次交换
#include<stdio.h>
#define MAX 10
void inplace_swap(int *x,int *y)
{
*y = *x^*y;
*x = *x^*y;
*y = *x^*y;
}
void reverse_array(int a[], int cnt)
{
int first,last;
for(first = 0,last = cnt-1;first<=last;first++,last--)
inplace_swap(&a[first], &a[last]);
}
void main()
{
int a[MAX];
int count,i;
printf("please enter the amount of numbers( no more than %d):\n",MAX);
scanf("%d",&count);
printf("please enter numbers('e' as the end)\n");
for(i = 1;i<=count;i++)
{
scanf("%d\n",&a[i-1]);
}
printf("the original array is as follow:\n");
for(i = 1;i<=count;i++)
{
printf("%d ",a[i-1]);
}
reverse_array(a, count);
printf("the new array is as follow:\n");
for(i = 1;i<=count;i++)
{
printf("%d ",a[i-1]);
}
}
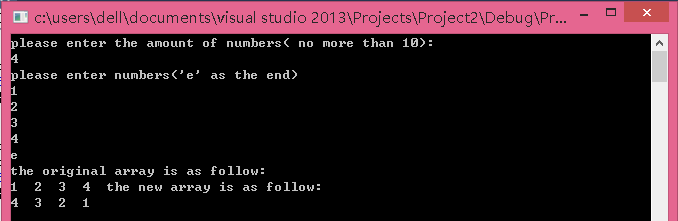
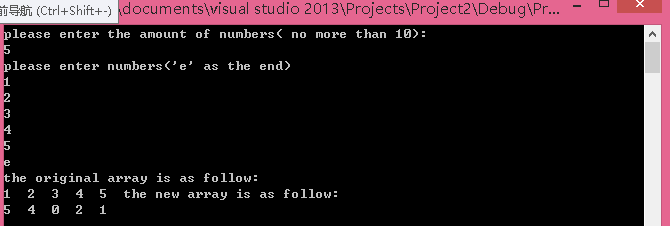
可以发现当数组长度为奇数的时候,输出的结果最中间的数字变为0。原因:在最后一次调用inplace_swap的时候,传入的first和last都是原数组中最中间的数字;在第一处*y = x^y时,y指向的数字就变为了0.此后,0变作为最中间的数字参与循环。解决办法:将循环条件中的first<=last 改为first<last(最中间的数字不会参与循环)即可。
- 练习题2.14 假设x和y的字节值分别为0x66和0x39。填写下表,指明各个 C 表达式的字节值。
x & y =0x20
x | y =0x7f
~x | ~y =0xdf
x&!y =0x00
x && y =0x01
x || y =0x01
!x || !y =0x00
课后作业中的问题和解决过程
-
练习题2.42
写一个函数div16,对任何整数参数,返回x/16的值。不能使用四则运算和任何条件运算符、比较运算符。(假设你的机器是32位,使用补码表示,右移都是算术右移)
int div16(int x)
{
int bias = (x>>31)&0xf;//如果是负数,bias就会变成f
return (x+bias)>>4;
}
不太理解如何证明负数运算时,加上bias(即f)之后就可以直接右移四位?
- 练习题2.25
以下代码试图计算数组a[]中所有元素的和,然而当参数length=0时,会发生存储器错误。试解释原因并修改代码。
#include<stdio.h>
#define MAX 100
float sum_elements(float a[], unsigned length)
{
int i;
float result = 0;
for (i =0;i<=length-1;i++)
{
result+=a[i];
}
return result;
}
void main()
{
float a[MAX];
unsigned number;
int i;
printf("Please enter the amount of numbers in your array:\n");
scanf("%u",&number);
if(number <0)
{
printf("Wrong!\n");
return;
}
if(number == 0)
{
printf("the result is:%f\n",sum_elements(a, number));
return;
}
else
{
printf("Please enter the elements:(the tail of array should be end by 'e')\n");
for(i = 0;i<=number-1;i++)
{
scanf("%f\n",&a[i]);
}
printf("the result is:%f\n",sum_elements(a, number));
return;
}
}
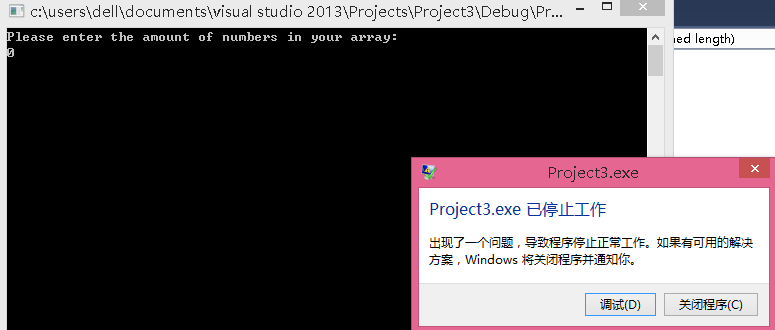
原因应该在“i<=length-1”与之前声明的“unsigned length”的矛盾中。因为当输入的length是0时,length-1=0-1(无符号数运算),即模数加法,得到的是Umax。而任何数都是小于Umax的,所以比较式恒为真。则循环会访问数组a中的非法元素。简单的处理办法就是将length声明为int型。但是声明后仍然有问题。
- 练习题2.44
E.x>0||-x>0
假设x=-2147483648(Tmin32),则x和-x都为负数
如何判断x的相反数是多少?
本周代码托管截图
其他(感悟、思考等,可选)
“精读”背后要多付出的精力、时间,与泛读甚至浏览完全不在同一个层次上。第二章一共60页,坚持每一页的每一句话都看到心里去,说不乏味不疲倦是不可能的。尤其是在假期期间,想要静下心来太难了,练习题要一个一个的去做,有代码要一个一个去试,这些都需要花费大量的时间和精力,但是这样的收获又是显著的;我开始跟随老师所提出的要点去走,跟着书中的思路去走,书中所提到的引用与老师所提到的要点就好像路标,我看到了所有的路标之后,路就变得格外好走。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 3/4 | 18/38 | |
| 第三周 | 500/1000 | 4/7 | 22/60 |
