
python魔法方法-自定义序列
自定义序列的相关魔法方法允许我们自己创建的类拥有序列的特性,让其使用起来就像 python 的内置序列(dict,tuple,list,string等)。
如果要实现这个功能,就要遵循 python 的相关的协议。所谓的协议就是一些约定内容。例如,如果要将一个类要实现迭代,可以实现__iter__() 或者 __getitem__()其中一个方法。
下面是一下相关的魔法方法:
-
__len__(self)
-
返回容器的长度。可变和不可变容器都要实现它,这是协议的一部分。
- __getitem__(self, key)
-
定义当某一项被访问时,使用self[key]所产生的行为。这也是可变容器和不可变容器协议的一部分。如果键的类型错误将产生TypeError;如果key没有合适的值则产生KeyError。
-
__setitem__(self, key, value)
-
定义当一个条目被赋值时,使用self[key] = value所产生的行为。这也是可变容器协议的一部分。而且,在相应的情形下也会产生KeyError和TypeError。
-
__delitem__(self, key)
-
定义当某一项被删除时所产生的行为。(例如del self[key])。这是可变容器协议的一部分。当你使用一个无效的键时必须抛出适当的异常。
-
__iter__(self)
-
返回一个迭代器,尤其是当内置的iter()方法被调用的时候,以及当使用for x in container:方式进行循环的时候。
-
迭代器要求实现next方法(python3.x中改为__next__),并且每次调用这个next方法的时候都能获得下一个元素,元素用尽时触发 StopIteration 异常。
-
而其实 for 循环的本质就是先调用对象的__iter__方法,再不断重复调用__iter__方法返回的对象的 next 方法,触发 StopIteration 异常时停止,并内部处理了这个异常,所以我们看不到异常的抛出。
这种关系就好像接口一样,如果回顾以前几篇的魔法方法,可以发现许多的内置函数得到的结果就是相应的魔法方法的返回值。
- 可迭代对象:对象实现了一个__iter__方法,这个方法负责返回一个迭代器。
- 迭代器:内部实现了next(python3.x为__next__)方法,真正负责迭代的实现。当迭代器内的元素用尽之后,任何的进一步调用都之后触发 StopIteration 异常,所以迭代器需要一个__iter__方
- 法来返回自身。所以大多数的迭代器本身就是可迭代对象。这使两者的差距进一步减少。
- 但是两者还是不同的,如果一个函数要求一个可迭代对象(iterable),而你传的迭代器(iterator)并没有实现__iter__方法,那么可能会出现错误。
- 不过一般会在一个类里同时实现这两种方法(即是可迭代对象又是迭代器),此时__iter__方法只要返回self就足够的了。当然也可以返回其它迭代器。
-
__reversed__(self)
-
实现当reversed()被调用时的行为。应该返回序列反转后的版本。仅当序列是有序的时候实现它,例如列表或者元组。
-
__contains__(self, item)
-
定义了调用in和not in来测试成员是否存在的时候所产生的行为。这个不是协议要求的内容,但是你可以根据自己的要求实现它。当__contains__没有被定义的时候,Python会迭代这个序列,并且当找到需要的值时会返回True。
-
__missing__(self, key)
-
其在dict的子类中被使用。它定义了当一个不存在字典中的键被访问时所产生的行为。(例如,如果我有一个字典d,当"george"不是字典中的key时,使用了d["george"],此时d.__missing__("george")将会被调用)。
下面是一个代码示例:
class Foo(object): def __init__(self, key, value): self.key = [] self.value = [] self.key.append(key) self.value.append(value)
self.__index = 0 def __len__(self): return len(self.key) def __getitem__(self, item): try: __index = self.key.index(item) return self.value[__index] except ValueError: raise KeyError('can not find the key') def __setitem__(self, key, value): if key not in self.key: self.key.append(key) self.value.append(value) else: __index = self.key.index(key) self.value[__index] = value def __delitem__(self, key): try: __index = self.key.index(key) del self.key[__index] del self.value[__index] except ValueError: raise KeyError('can not find the key') def __str__(self): result_list = [] for index in xrange(len(self.key)): __key = self.key[index] __value = self.value[index] result = __key, __value result_list.append(result) return str(result_list) def __iter__(self):return self def next(self): if self.__index == len(self.key): self.__index = 0 raise StopIteration() else: __key = self.key[self.__index] __value = self.value[self.__index] result = __key, __value self.__index += 1 return result def __reversed__(self): __result = self.value[:] __result.reverse() return __result def __contains__(self, item): if item in self.value: return True else: return False
这里创建一个模拟字典的类,这个类的内部维护了两个列表,key 负责储存键,value 负责储存值,两个列表通过索引的一一对应,从而达到模拟字典的目的。
首先,我们看看__len__方法,按照协议,这个方法应该返回容器的长度,因为这个类在设计的时候要求两个列表必须等长,所以理论上返回哪个列表的长度都是一样的,这里我选择返回 key 的长度。
然后是__getitem__方法。这个方法会在a['scolia']时,调用a.__getitem__('scolia')。也就是说这个方法定义了元素的获取,我这里的思路是先找到 key 列表中建的索引,然后用索引去 value 列表中找对应的元素,然后将其返回。然后为了进一步伪装成字典,我捕获了可能产生的 ValueError (这是 item 不在 key 列表中时触发的异常),并将其伪装成字典找不到键时的 KeyError。
理论上只要实现了上面两个方法,就可以得到一个不可变的容器了。但是我觉得并不满意所以继续拓展。
__setitem__(self, key, value)方法定义了 a['scolia'] = 'good' 这种操作时的行为,此时将会调用a.__setitem__('scolia', 'good') 因为是绑定方法,所以self是自动传递的,我们不用理。这里我也模拟了字典中对同一个键赋值时会造成覆盖的特性。这个方法不用返回任何值,所以return语句也省略了。
__delitem__(self, key)方法定义了del a['scolia'] 这类操作时候的行为,里面的‘scolia’就作为参数传进去。这里也进行了异常的转换。
只有实现里以上四个方法,就可以当做可变容器来使用了。
接下来的 __str__ 是对应于 str() 函数,在类的表示中会继续讨论,这里是为了 print 语句好看才加进去的,因为print语句默认就是调用str()函数。
__iter__和next方法在开头的时候讨论过了,这里是为了能让其进行迭代操作而加入的。
__reversed__(self)方法返回一个倒序后的副本,这里体现了有序性,当然是否需要还是要看个人。
__contains__实现了成员判断,这里我们更关心value列表中的数据,所以判断的是value列表。该方法要求返回布尔值。
下面是相应的测试:
a = Foo('scolia', 'good') a[123] = 321 a[456] = 654 a[789] = 987 print a del a[789] print a for x, y in a: print x, y print reversed(a) print 123 in a print 321 in a

-
__missing__(self, key)
class Boo(dict): def __new__(cls, *args, **kwargs): return super(Boo, cls).__new__(cls) def __missing__(self, key): return 'The key(%s) can not be find.'% key
测试:
b = Boo() b['scolia'] = 'good' print b['scolia'] print b['123']

当然你也可以在找不到 key 的时候触发异常,具体实现看个人需求。
只用__getitem__(self, item)实现支持for循环:
class Foo(object): def __init__(self, x): self.x = x self.__index = -1 def __getitem__(self, item): self.__index += 1 return self.x[self.__index]
测试:
a = Foo([1, 2, 3]) for x in a: print x

工作良好。
切片操作的实现:
有好奇的同学可能还会发现上面并没有出现序列的典型操作:切片的实现。
其实切片也是使用__getitem__(self, item)魔法方法的,先让我们看看当我们使用切片的时候,item参数会获得什么:
class Foo(object): def __init__(self, x): self.x = x def __getitem__(self, item): return item a = Foo(123) print a[1:2]
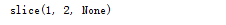
获得了一个类似函数的对象,其类型为:
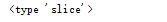
该类型由 slice 函数创建,感兴趣的同学可以使用 help 函数进行深入研究。
该函数的创建方法为: slice(stop)/slice(start, stop[, step]) 两种,一旦创建后,我们可以使用 start、stop、step属性来获取相应的值。
如果要让上面的例子支持切片,只需要修改__getitem__(self, item)处的代码:
def __getitem__(self, item): if isinstance(item, slice): return self.value[item.start:item.stop:item.step] else: try: __index = self.key.index(item) return self.value[__index] except ValueError: raise KeyError('can not find the key')
输出:
a = Foo('scolia', 'good') a[123] = 321 a[456] = 654 a[789] = 987 print a[:] print a[2:] print a[:3] print a[1:5] print a[1:10:2] print a[-4:-2]
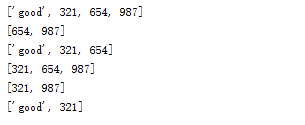
运行良好,切片功能支持完毕。
欢迎大家交流。
参考资料:戳这里

