


JVM(三)内存回收(一)
最近花了相当长一段时间在看Hotspot JVM的GC和内存分配,本节先总结和回顾一下内存回收的相关知识点,内存的分配放到下节再讨论。
一、什么是JVM的GC
GC即Garbage Collection,大家都知道,写Java程序的时候,不需要像在C、C++中一样,显示的都调用delete去回收不再需要的对象的内存空间。其实现方式是在对象的析构函数中,将new出来的指针、数组等显示的delete(delete[] 数组)掉,从而到达目的。但是,Java中,只管new,不需要delete,而且也不允许你delete。那内存回收的哪些事都被谁管了呢?那就是GC Collector(垃圾回收器)。它会负责在JVM运行时,动态的分配和回收对象的内存。那么,究竟该怎么做呢?那垃圾回收器的设计是基于以下三个问题和二个假设进行的:
三个问题:
1. 哪些内存需要回收?
2. 什么时候回收?
3. 如何回收?
二个假设:
1. 假设大部分对象在很短的时间内会变得不可达;
2. 只存在少部分的老对象引用会转变为年轻对象的引用(Reference from old objects to yount objects only exist in small numbers)。
下面我就先说下自己对这两个假设的理解:
假设1,“假设大部分对象在很短的时间内会变得不可达” 这句话通俗点说就是,JVM中很多new出来的Object,大部分只会在短时间被引用,之后就不会再被使用了。比如,你在某个方法里面new了一个HashMap的对象,而这个对象除了在这个方法中使用之外,不会在其他任何地方使用,那么等这个方法调用完毕之后,这对象的内存就变成了假设1中所说的不可达了,而这种情况在实际的使用中是比较多,所以有此假设。如下:

public void method1(){ ..... Map<String,String> map = new HashMap<>(); // 在method1调用完毕之后,map引用所指的对象将变得不可达。 ..... }
假设2,“只存在少部分的老对象引用会转变为年轻对象的引用”,通俗点解释下年老对象和年轻对象,这个和现实生活中的老年人和年轻人类比,也有一个分割线(一般Hotspot中用这个参数来指定MaxTenuringThreshold),当某个对象的年龄大于这个值时,就是老对象,否则是年轻对象(这个只是狭义的理解,具体可以自行baidu、google Java的分代回收机制),后面也会提到。那么何为假设2所说的意思呢,就是,已经进入老年代的对象,很少有会转为年轻代对象的情况。举个例子,在某个对象obj的成员变量中有个HashMap对象map1,在使用obj的各个方法(private、public等)中会时常用到这个map1所引用的对象,一般情况下,如果obj是老年代对象,那么map1所引用的对象也会进入老年代,于是map1就是老年代的引用。而如果此时,有线程调用了obj1的该map1的setter方法,重置了map1引用,使之指向了另外一个刚刚new出来的新的HashMap对象,就出现了假设2中所说的,老对象的引用转变为新对象的引用的情况。但是,一般情况下,这种setter方法会被调用情况的比较少,于是就有了假设2的存在。如下:
public class Obj1{ private Map<String,String> map1 = null; ...... public Obj1(){ ...... map1 = new HashMap<>(); // 初始化 ...... } private void m1(){ ..... map1. put("ttt","yyy"); ... } public void m2(){ ..... map1. put("ttt2","yyy2"); ... } public void setMap1(Map<String,String> map){ this.map1 = map; // map1引用在此方法中被重置,而map所指的对象可能是一个刚创建出来的新对象 } ....... }
接着就来聊聊以上的三个问题。
二、哪些对象需要被回收
其实直观的感受是,不需要在任何时候任何地方再次使用的对象就可以被回收了。
这句话讲的很轻松,但实现起来却没那么容易,因为此时,其核心问题就变成了,如何找到这些“不需要在任何时候任何地方再次使用的对象”?
从前面的 JVM(二)JVM内存布局 章节中我们了解到,JVM运行时的内存分布包括:堆、JVM栈、方法区、native方法栈、程序计数器。其中JVM栈、native方法栈、程序计数器都是线程私有的,其生命周期是和线程同步的,即它们是随线程生随线程灭,所以,不需要GC参与这些内存区域的对象的内存回收,那么仅剩下堆(Heap)、方法区需要GC来进行管理。于是,我们初步确定了GC要管理的对象位于堆和方法区。但是并未解决如何找到这些不再被使用的对象的问题。为此,聪明的前辈们研究出了一下一些算法
1. 引用计数算法
即分析一个对象有多少个引用在指向它,如果当指向这个对象的个数为0的时候,则该对象肯定是“不再被使用的对象”了,即可以被回收了,且看如下代码
public void m1(){ String str = new String("hello world"); // 这个时候,str 指向了String 对象“hello world”, 其引用数为1 String str1 = str; // 对象“hello world”引用数为2 String str2 = str; // 对象“hello world”引用数为3 ...... str2 = null; // 对象“hello world”引用数为2 str1 = null; // 对象“hello world”引用数为1 str = null; // 对象“hello world”引用数为0,此时将不再有引用指向对象“hello world”了,其他任何线程、任何地方都无法再引用到这个对象了,于是,GC会认为这个对象能够被清除了。 }
但是这个算法存在一个很明显的问题,就是当两个对象循环引用的时候,各自的引用数都不为0(实际上为1)时,而这两个对象此时实际上不会被任何其他线程在任何时候使用了,但是,各自所占用的内存将无法被回收,因为其引用数不为0,且看如下代码:
public class ReferenceCountTest { static class A{ B bObj = null; } static class B{ A aObj = null; } public static void main(String[] args) { A aObj = new A(); B bObj = new B(); aObj.bObj = bObj; // B对象的引用数此时为2 bObj.aObj = aObj; // A对象的引用数此时为2 aObj = null; // A对象的引用数此时为1 bObj = null; // B对象的引用数此时为1 // 从此处开始,不会可能再在其他地方访问到A和B的两个实例对象, // 但是,很明显其引用数不会为0,如果采用引用数为0即可清除的算法,这两个对象占用的内存将永远得不到回收 // .............. } }
2. GC Roots算法(可达性分析算法)
引用计数算法,虽然简单、高效,但是,存在很明显的缺陷,所以不得不再去寻找新的算法来解决“寻找可回收对象”的问题。GC Roots算法就是为此而生的。目前主流的商用具有自动内存管理的语言中,基本都是使用该算法来判断对象是否可以被回收的对象,如Java、C#等。其基本思路就是,首先选定一系列GC Roots对象作为根节点,然后逐一分析这些GC Roots对象,顺着这些对象往下搜索,如果能够以这些对象为起点,能到达的对象,就称为可到达对象,否则称为不可到达对象。请看下图
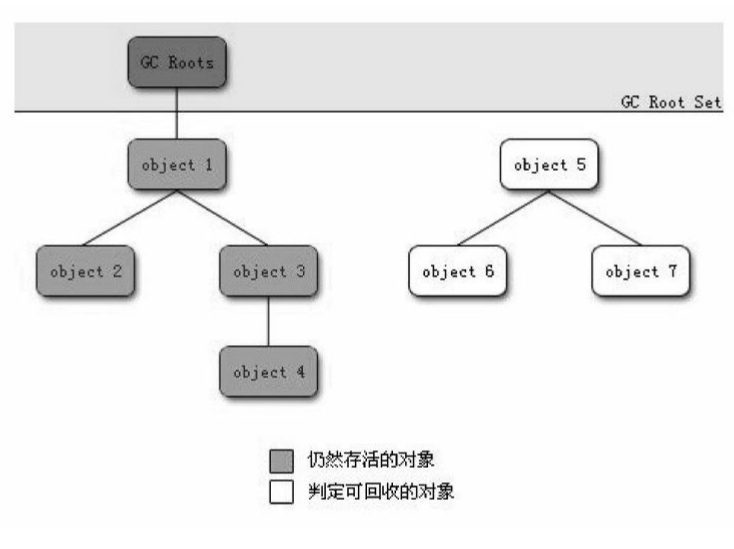
从图中可以看出,object1、object2、object3、object4为可到达对象(因为可以从GC Roots到达),而object5、object6、object7则不可到达(无法从GC Roots到达),那么这三个对象(object5、object6、object7)即为可被回收的对象。而且很显然。这三个对象就是“引用计数算法”中的对象相互引用的典型案例,其每个对象的引用数都不为0。好的,这里确实解决了“如何找到可被回收对象”的问题。但是,还有一个问题未解决,就是如何确定这些GC Roots对象?
回顾前面 JVM(二)JVM内存布局 的内容,可以知道,GC Roots对象应该存在如下区域
- JVM 栈中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中的JNI(即native方法)中引用的对象
至此,解决了第一个问题。
三、什么时候回收
有人会问,这个有什么好考虑的,把上面找到的对象的内存都直接回收了,不就完了吗?乍一看,似乎并没错,仔细分析,还是欠考虑。为什么这么说呢?
试想,如果你在内存几乎快要被占满的时候,如99%的内存已经被使用,再进行内存回收,势必会造成很高的回收时间成本(即回收一次会耗费比较长的时间);如果你在内存使用不到一半甚至更少的时候(如40%)才回收内存,则势必会造成频繁的内存回收动作。这两种情况下,都会造成JVM性能的急剧下降。在GC的世界里,存在一个永远都回避不了的问题,那就是“stop the world”,就是说在内存真正被回收的时候,整个JVM的所有用户线程都会被挂起,等待内存回收的线程完成之后,用户线程才会继续运行。由此可见,过快的内存回收动作会导致用户线程被频繁挂起,而过慢的回收动作则会造成用户线程过长时间的被挂起。因此,在内存回收的时候,JVM会提供相关的配置参数供Java程序员使用,从而能根据不同的java应用程序(如高并发的、高吞吐量等),选择合适的内存回收器(一般都执行不同的回收算法),以此来提高JVM的性能,提高应用程序的性能。所以,“什么时候被回收”与采用的什么样的垃圾回收算器以及相关的配置参数是紧密相关的,换句话说就是,与“怎么回收”是紧密相关的。
四、怎么回收
想象一下,在一片内存区域(如50MB)中,分布了50个对象(假设每个对象都是1MB),其中有一部分是可以被删除的对象,有一部分是不能被删除的对象,而且他们在实际情况下,一般都是交替的分布在这个内存区域的,如下图:
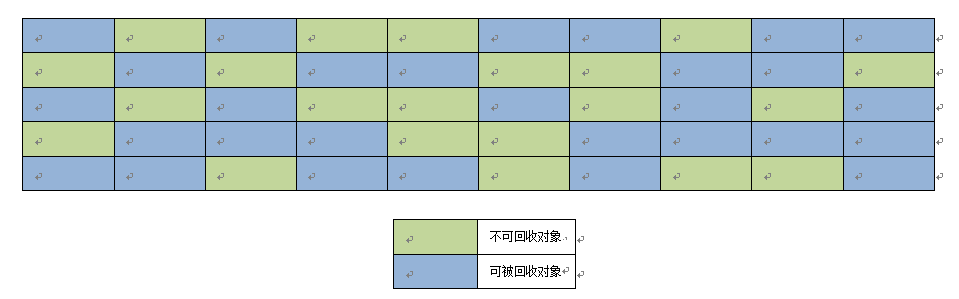
如果简单的把可回收的对象直接从内存中删除,很显然会造成内存碎片,如果你想再分配一个稍大的对象,如:5MB的对象,发现却无内存可用,而实际的可用内存是要大于5MB的。于是,整理内存又成为了必要,即,把零散的存活的对象统统整理到内存某一个区域,把零散的空闲内存整理到另外一个区域,这样,就能分配出来一个5MB的大对象了。
回收后,如下图:
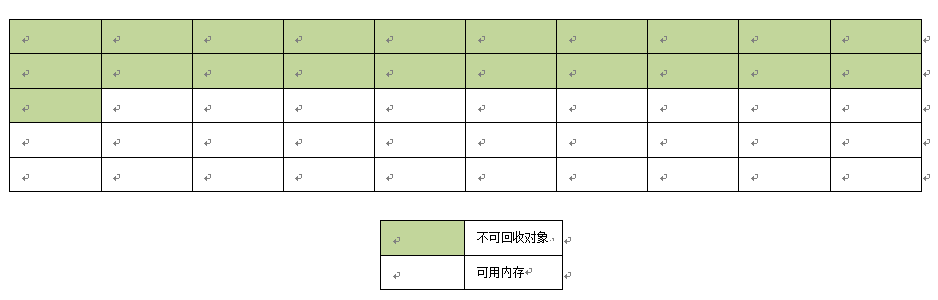
在这个例子中,我们潜意识的做了几件事情:
- 把可回收的对象标成了“浅蓝色”;
- 删除“浅蓝色”对象所占用的空间;
- 对内存进行了必要的整理(把可用对象统一复制到内存的某一区域,而使连续可用的内存分布在另一区域);
从而简单的完成了内存回收。下面我先介绍下通用的内存回收算法。
1. 内存回收算法
1.1 标记-清除(Mark-Sweep)
这个算法很简单,就是把找到的不可达对象,先进行一次标记,如例子中的“把不可用对象被标为浅蓝色”,然后在后一次的清理过程中,直接把这些带标记的对象清除掉,从而完成内存的回收。这个是最基本的算法,后续介绍的算法,基本都是基于此算法进行改造而成。因为它具有两个明显的不足:
-
- 效率问题,标记和清除的过程效率都不高;
- 内存碎片,如例子中如果不进行内存整理,势必会造成后续程序的运行过程中对大对象的分配无法实现,从而再次引发另一次内存回收,从而影响JVM的性能。
1.2 复制算法
为了解决效率问题,一种称为“复制”的算法应运而生。这种算法的基本思路是:把堆内存分为等额的两份,即各占50%,假设各自命名为A、B两块,这样,在分配内存的时候,只往在A中分配,当需要对A进行内存回收的时候,就把A中可达对象复制到B中,再统一回收掉A中的内存(这个回收只是简单的把堆顶指针移动到堆底即可,效率非常高),这样程序就能继续在A中进行内存分配了,完美的解决了效率和内存碎片问题。
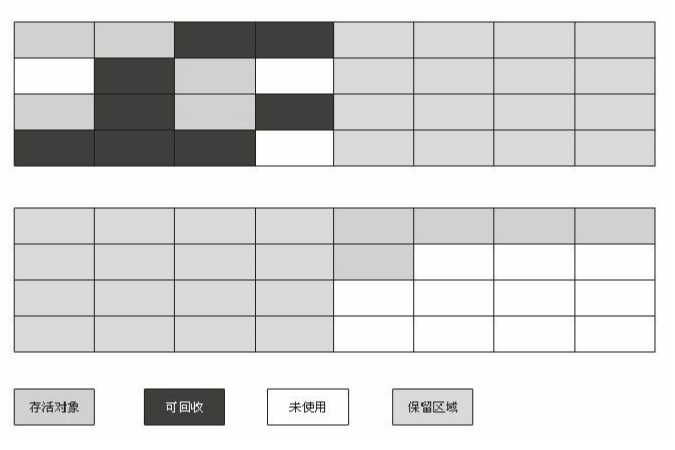
不过,这个世界就是这么的有意思,当你解决了某些问题,总是可能连带的引发一些其他的问题。细心的读者可能会发现,虽然效率问题貌似被解决了,但是,原本1GB的内存空间,实际上只有500MB在使用,因为分配内存的时候,只在A半区进行;另外,虽然解决了内存整理的效率问题,但是,对象的复制问题还是存在,如果在A中存在很多的对象是可达对象,那么从A复制到B的对象的数量也是很多的,其效率也并不见得高。不过,好在,我们在文章的最前面就讲到了两个假设,其中一个就是,大部分的对象都会在很短的时间之内被清除,而实际上,也确实是这样。IMB的相关研究表明,98%的对象在新生对象都是“朝生夕死”的,所以根本没必要对A、B划分的时候采用1:1的比例进行,而是将内存分为一块较大的Eden区和两块同样大小的Survivor区,这样,在内存分配的时候,只使用Eden和其中一个Survivor区,当回收内存时,就把存活的对象一次性拷贝到另一个Survivor即可。默认情况下,Hotspot JVM的Eden:Survivor的比例为8:1,用户可以根据参数SurvivorRatio来指定分配比例。不过在极端情况下,Eden区和Survivor区的对象都存活的情况下,就无法把对象移动到Survivor区,那此时的内存分配就依赖其他内存(一般是老年代)进行分配担保。
内存的分配担保就好比我们去银行借款,如果我们信誉很好,在98%的情况下都能按时偿还,于是银行可能会默认我们下一次也能按时按量地偿还贷款,只需要有一个担保人能保证如果我不能还款时,可以从他的账户扣钱,那银行就认为没有风险了。内存的分配担保也一样,如果另外一块Survivor空间没有足够空间存放上一次新生代收集下来的存活对象时,这些对象将直接通过分配担保机制进入老年代。
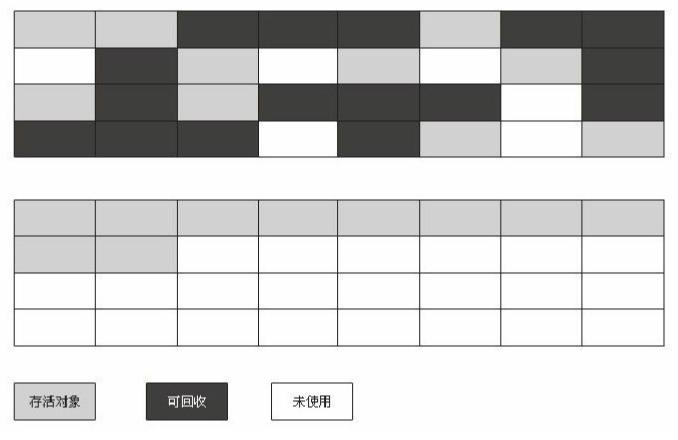
1.3 标记-整理算法
该算法主要用于老年代,因为老年代的对象基本都比较稳定,从前面提到的“假设2”也看得出。其原理基本和“标记-清除”算法类似,只是后续的“清除”操作被“整理”取代了。来。整理即把可用的对象移动到一侧,然后把端边界的另外一侧全部清除。如下图:
1.4 分代收集算法
当前商业虚拟机的垃圾收集都采用“分代收集”(Generational Collection)算法,这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
由于篇幅的限制,垃圾回收器的介绍考虑放到后面的章节中分享。不过也可以考虑不分享,毕竟,网上类似的文章已经非常非常多了。
参考:《深入理解Java虚拟机》
http://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html
https://www.dynatrace.com/resources/ebooks/javabook/how-garbage-collection-works/
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:从精于一开始 不积跬步无以至千里,不积小流无以成江海。
出处:http://www.cnblogs.com/scofield-1987/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步