

爬虫入门 手写一个Java爬虫
本文内容 涞源于 罗刚 老师的 书籍 << 自己动手写网络爬虫一书 >> ;
本文将介绍 1: 网络爬虫的是做什么的? 2: 手动写一个简单的网络爬虫;
1: 网络爬虫是做什么的? 他的主要工作就是 跟据指定的url地址 去发送请求,获得响应, 然后解析响应 , 一方面从响应中查找出想要查找的数据,另一方面从响应中解析出新的URL路径,
然后继续访问,继续解析;继续查找需要的数据和继续解析出新的URL路径 .
这就是网络爬虫主要干的工作. 下面是流程图:
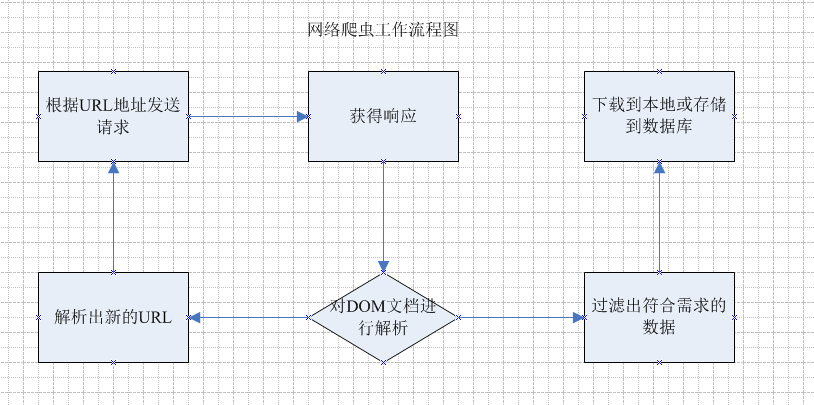
通过上面的流程图 能大概了解到 网络爬虫 干了哪些活 ,根据这些 也就能设计出一个简单的网络爬虫出来.
一个简单的爬虫 必需的功能:
1: 发送请求和获取响应
2: 解析页面元素
3: 过滤和存储符合需求的数据
4: 处理URL路径
下面是包结构:

下面就上核心代码:
public void crawling(String[] seeds) { //使用种子初始化 URL 队列 System.out.println("MyCrawler: 使用种子初始化 URL 队列, 程序开始."); Links.addUnvisitedUrlQueue(seeds); //循环条件:是否 还有有效的待访问链接 while (Links.hasUnVisitedUrlList()) { //先从待访问的序列中取出第一个 String url = Links.fetchHeadOfUnVisitedUrlQueue(); //将已经访问过的链接放入已访问的链接中; Links.addVisitedUrlSet(url); //根据URL得到page Page page = Requests.request(url); //对page进行解析:---- 解析DOM的某个标签 System.out.println("PageParserUtils: 解析页面出页面中所有的 a 标签"); Elements es = PageParserUtils.select(page, "a"); es.stream().map(Element::toString).forEach(System.out::println); //对page进行解析:---- 得到新的链接 System.out.println("PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 "); Set<String> links = PageParserUtils.getLinks(page, "img"); // Links管理类 新增链接 System.out.println("Links: 可以将解析出来的链接 添加到 待访问链接队列中 "); links.stream().filter(link -> link.startsWith("http://www.baidu.com")).forEach(Links::addUnvisitedUrlQueue); //对page进行处理: 将保存文件 System.out.println("Files: 将页面保存到本地"); Files.saveToLocal(page); } System.out.println("MyCrawler: 所有的有效链接已访问结束, 程序退出."); }
下面是运行结果:
MyCrawler: 使用种子初始化 URL 队列, 程序开始. Links: 新增爬取路径: http://www.baidu.com Links: 取出待访问的url : http://www.baidu.com PageParserUtils: 解析页面出页面中所有的 a 标签 <a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a> <a href="http://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a> <a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a> <a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a> <a href="http://tieba.baidu.com" name="tj_trtieba" class="mnav">贴吧</a> <a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1" name="tj_login" class="lb">登录</a> <a href="//www.baidu.com/more/" name="tj_briicon" class="bri" style="display: block;">更多产品</a> <a href="http://home.baidu.com">关于百度</a> <a href="http://ir.baidu.com">About Baidu</a> <a href="http://www.baidu.com/duty/">使用百度前必读</a> <a href="http://jianyi.baidu.com/" class="cp-feedback">意见反馈</a> PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 Links: 可以将解析出来的链接 添加到 待访问链接队列中 Links: 新增爬取路径: http://www.baidu.com/img/gs.gif Links: 新增爬取路径: http://www.baidu.com/img/bd_logo1.png Files: 将页面保存到本地 文件:www.baidu.com.html已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com.html Links: 取出待访问的url : http://www.baidu.com/img/gs.gif PageParserUtils: 解析页面出页面中所有的 a 标签 PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 Links: 可以将解析出来的链接 添加到 待访问链接队列中 Files: 将页面保存到本地 文件:www.baidu.com_img_gs.gif.gif已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_gs.gif.gif Links: 取出待访问的url : http://www.baidu.com/img/bd_logo1.png PageParserUtils: 解析页面出页面中所有的 a 标签 PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 Links: 可以将解析出来的链接 添加到 待访问链接队列中 Files: 将页面保存到本地 文件:www.baidu.com_img_bd_logo1.png.png已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_bd_logo1.png.png MyCrawler: 所有的有效链接已访问结束, 程序退出.
下面是代码地址:
crawlLearn: java 爬虫入门 (gitee.com)
文章参考:
1: 自己动手写网络爬虫;
2: https://github.com/CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
本文首发于2017年11月18号, 于2021年5月20日重做整理和修改.

