

理解Docker(5):Docker 网络
本系列文章将介绍 Docker的相关知识:
(2)Docker 镜像
(3)Docker 容器的隔离性 - 使用 Linux namespace 隔离容器的运行环境
(4)Docker 容器的隔离性 - 使用 cgroups 限制容器使用的资源
(5)Docker 网络
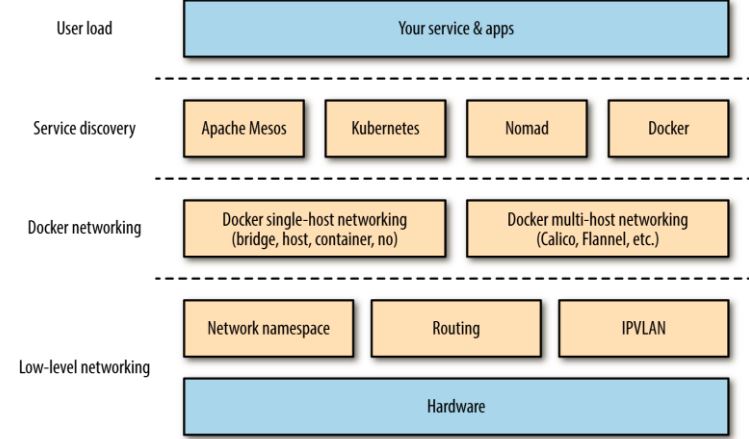
1. Docker 网络概况
用一张图来说明 Docker 网络的基本概况:
2. 四种单节点网络模式
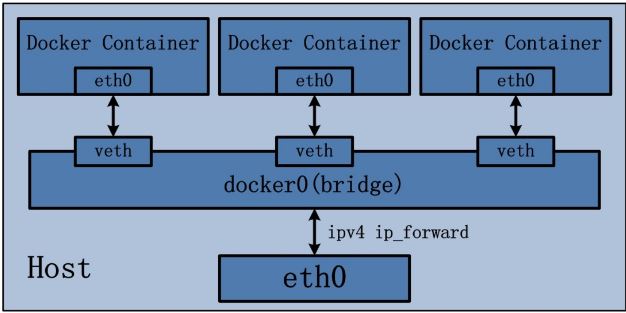
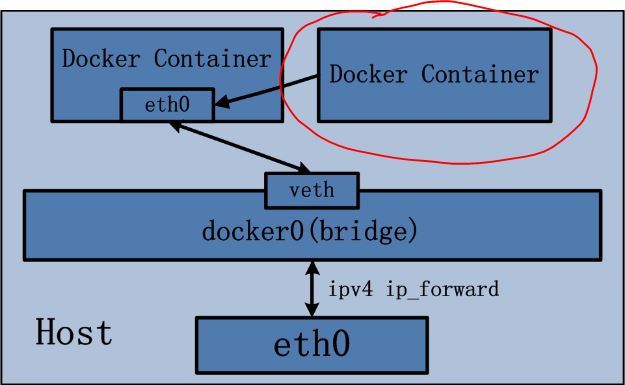
2.1 bridge 模式
Docker 容器默认使用 bridge 模式的网络。其特点如下:
- 使用一个 linux bridge,默认为 docker0
- 使用 veth 对,一头在容器的网络 namespace 中,一头在 docker0 上
- 该模式下Docker Container不具有一个公有IP,因为宿主机的IP地址与veth pair的 IP地址不在同一个网段内
- Docker采用 NAT 方式,将容器内部的服务监听的端口与宿主机的某一个端口port 进行“绑定”,使得宿主机以外的世界可以主动将网络报文发送至容器内部
- 外界访问容器内的服务时,需要访问宿主机的 IP 以及宿主机的端口 port
- NAT 模式由于是在三层网络上的实现手段,故肯定会影响网络的传输效率。
- 容器拥有独立、隔离的网络栈;让容器和宿主机以外的世界通过NAT建立通信
- 关于容器通过 NAT 连接外网的原理,请参考我的另一篇文章 Netruon 理解(11):使用 NAT 将 Linux network namespace 连接外网。
iptables 的 SNTA 规则,使得从容器离开去外界的网络包的源 IP 地址被转换为 Docker 主机的IP地址:
Chain POSTROUTING (policy ACCEPT) target prot opt source destination MASQUERADE all -- 172.17.0.0/16 0.0.0.0/0 MASQUERADE all -- 172.18.0.0/16 0.0.0.0/0
效果是这样的:
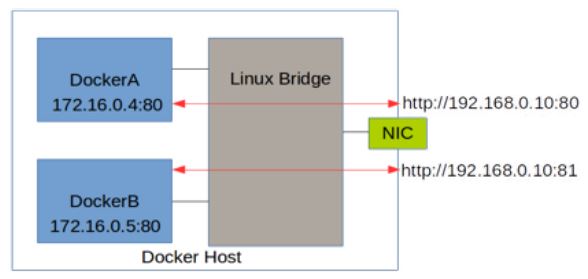 (图片来源)
(图片来源)
示意图:
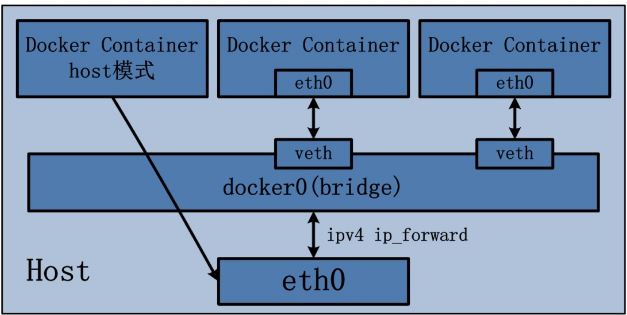
2.2 Host 模式
定义:
Host 模式并没有为容器创建一个隔离的网络环境。而之所以称之为host模式,是因为该模式下的 Docker 容器会和 host 宿主机共享同一个网络 namespace,故 Docker Container可以和宿主机一样,使用宿主机的eth0,实现和外界的通信。换言之,Docker Container的 IP 地址即为宿主机 eth0 的 IP 地址。其特点包括:
-
- 这种模式下的容器没有隔离的 network namespace
- 容器的 IP 地址同 Docker host 的 IP 地址
- 需要注意容器中服务的端口号不能与 Docker host 上已经使用的端口号相冲突
- host 模式能够和其它模式共存
实验:
(1)启动一个 host 网络模式的容器
docker run -d --name hostc1 --network host -p 5001:5001 training/webapp python app.py
(2)检查其 network namespace,其中可以看到主机上的所有网络设备

root@docker2:/home/sammy# ln -s /proc/28353/ns/net /var/run/netns/hostc1 root@docker2:/home/sammy# ip netns hostc1 root@docker2:/home/sammy# ip netns exec hostc1 No command specified root@docker2:/home/sammy# ip netns exec hostc1 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 08:00:27:d4:66:75 brd ff:ff:ff:ff:ff:ff inet 192.168.1.20/24 brd 192.168.1.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::a00:27ff:fed4:6675/64 scope link valid_lft forever preferred_lft forever
......
示意图:
2.3 container 模式
定义:
Container 网络模式是 Docker 中一种较为特别的网络的模式。处于这个模式下的 Docker 容器会共享其他容器的网络环境,因此,至少这两个容器之间不存在网络隔离,而这两个容器又与宿主机以及除此之外其他的容器存在网络隔离。
实验:
(1)启动一个容器:
docker run -d --name hostcs1 -p 5001:5001 training/webapp python app.py
(2)启动另一个容器,并使用第一个容器的 network namespace
docker run -d --name hostcs2 --network container:hostcs1 training/webapp python app.py
注意:因为此时两个容器要共享一个 network namespace,因此需要注意端口冲突情况,否则第二个容器将无法被启动。
示意图:
2.4 none 模式
定义:
网络模式为 none,即不为 Docker 容器构造任何网络环境。一旦Docker 容器采用了none 网络模式,那么容器内部就只能使用loopback网络设备,不会再有其他的网络资源。Docker Container的none网络模式意味着不给该容器创建任何网络环境,容器只能使用127.0.0.1的本机网络。
实验:
(1)创建并启动一个容器: docker run -d --name hostn1 --network none training/webapp python app.py
(2)检查其网络设备,除了 loopback 设备外没有其它设备
root@docker2:/home/sammy# ip netns exec hostn1 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever
3. 多节点 Docker 网络
Docker 多节点网络模式可以分为两类,一类是 Docker 在 1.19 版本中引入的基于 VxLAN 的对跨节点网络的原生支持;另一种是通过插件(plugin)方式引入的第三方实现方案,比如 Flannel,Calico 等等。
3.1 Docker 原生overlay 网络
Docker 1.19 版本中增加了对 overlay 网络的原生支持。Docker 支持 Consul, Etcd, 和 ZooKeeper 三种分布式key-value 存储。其中,etcd 是一个高可用的分布式 k/v存储系统,使用etcd的场景默认处理的数据都是控制数据,对于应用数据,只推荐数据量很小,但是更新访问频繁的情况。
3.1.1 安装配置
准备三个节点:
- devstack 192.168.1.18
- docker1 192.168.1.21
- docker2 192.168.1.19
在 devstack 上使用Docker 启动 etcd 容器:
export HostIP="192.168.1.18" docker run -d -v /usr/share/ca-certificates/:/etc/ssl/certs -p 4001:4001 -p 2380:2380 -p 2379:2379 \ --name etcd quay.io/coreos/etcd \
/usr/local/bin/etcd \ -name etcd0 \ -advertise-client-urls http://${HostIP}:2379,http://${HostIP}:4001 \ -listen-client-urls http://0.0.0.0:2379,http://0.0.0.0:4001 \ -initial-advertise-peer-urls http://${HostIP}:2380 \ -listen-peer-urls http://0.0.0.0:2380 \ -initial-cluster-token etcd-cluster-1 \ -initial-cluster etcd0=http://${HostIP}:2380 \ -initial-cluster-state new
使用 Docker 启动 etcd 请参考 https://coreos.com/etcd/docs/latest/docker_guide.html。不过,应该是因为制造镜像所使用的Dockerfile 原因,官网上的命令因为少了上面红色字体部分而会造成启动失败:
b847195507addf4fb5a01751eb9c4101416a13db4a8a835e1c2fa1db1e6f364e docker: Error response from daemon: oci runtime error: exec: "-name": executable file not found in $PATH.
添加红色部分后,容器可以被正确创建:
root@devstack:/# docker exec -it 179cd52b494d /usr/local/bin/etcdctl cluster-health member 5d72823aca0e00be is healthy: got healthy result from http://:2379 cluster is healthy
root@devstack:/home/sammy# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 179cd52b494d quay.io/coreos/etcd "/usr/local/bin/etcd " 8 seconds ago Up 8 seconds 0.0.0.0:2379-2380->2379-2380/tcp, 0.0.0.0:4001->4001/tcp etcd root@devstack:/home/sammy# netstat -nltp | grep 2380 tcp6 0 0 :::2380 :::* LISTEN 4072/docker-proxy root@devstack:/home/sammy# netstat -nltp | grep 4001 tcp6 0 0 :::4001 :::* LISTEN 4047/docker-proxy
在docker1 和 docker2 节点上修改 /etc/default/docker,添加:
DOCKER_OPTS="--cluster-store=etcd://192.168.1.18:2379 --cluster-advertise=192.168.1.20:2379"
然后分别重启 docker deamon。注意,要使用IP地址;要是使用 hostname 的话,docker 服务将启动失败:
root@docker2:/home/sammy# docker ps An error occurred trying to connect: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json: read unix @->/var/run/docker.sock: read: connection reset by peer
3.1.2 使用 Docker overlay 网络
(1)在docker1上运行下面的命令创建一个 overlay 网络:
root@docker1:/home/sammy# docker network create -d overlay overlaynet1 1de982804f632169380609b9be7c1466b0064dce661a8f4c9e30d781e79fc45a root@docker1:/home/sammy# docker network inspect overlaynet1 [ { "Name": "overlaynet1", "Id": "1de982804f632169380609b9be7c1466b0064dce661a8f4c9e30d781e79fc45a", "Scope": "global", "Driver": "overlay", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "10.0.0.0/24", "Gateway": "10.0.0.1/24" } ] }, "Internal": false, "Containers": {}, "Options": {}, "Labels": {} } ]
在 docker2 上你也会看到这个网络,说明通过 etcd,网络数据是分布式而不是本地的了。
(2)在网络中创建容器
在 docker2 上,运行 docker run -d --name over2 --network overlaynet1 training/webapp python app.py
在 docker1 上,运行 docker run -d --name over1 --network overlaynet1 training/webapp python app.py
进入容器 over2,发现它有两块网卡:
root@docker2:/home/sammy# ln -s /proc/23576/ns/net /var/run/netns/over2 root@docker2:/home/sammy# ip netns over2 root@docker2:/home/sammy# ip netns exec over2 ip a 22: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default link/ether 02:42:0a:00:00:02 brd ff:ff:ff:ff:ff:ff inet 10.0.0.2/24 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:aff:fe00:2/64 scope link valid_lft forever preferred_lft forever 24: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff inet 172.19.0.2/16 scope global eth1 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe13:2/64 scope link valid_lft forever preferred_lft forever
其中 eth1 的网络是一个内部的网段,其实它走的还是普通的 NAT 模式;而 eth0 是 overlay 网段上分配的IP地址,也就是它走的是 overlay 网络,它的 MTU 是 1450 而不是 1500.
进一步查看它的路由表,你会发现只有同一个 overlay 网络中的容器之间的通信才会通过 eth0,其它所有通信还是走 eth1.
root@docker2:/home/sammy# ip netns exec over2 route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 172.19.0.1 0.0.0.0 UG 0 0 0 eth1 10.0.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 172.19.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth1
先看此时的网络拓扑图:
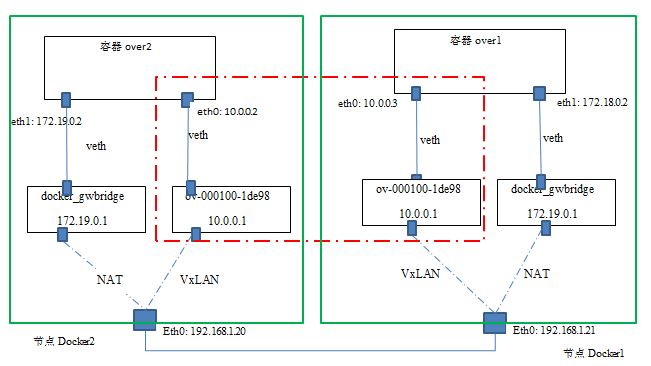
可见:
- Docker 在每个节点上创建了两个 linux bridge,一个用于 overlay 网络(ov-000100-1de98),一个用于非 overlay 的 NAT 网络(docker_gwbridge)
- 容器内的到overlay 网络的其它容器的网络流量走 overlay 网卡(eth0),其它网络流量走 NAT 网卡(eth1)
- 当前 Docker 创建 vxlan 隧道的ID范围为 256~1000,因而最多可以创建745个网络,因此,本例中的这个 vxlan 隧道使用的 ID 是 256
- Docker vxlan 驱动使用 4789 UDP 端口
- overlay网络模型底层需要类似 consul 或 etcd 的 KV 存储系统进行消息同步
- Docker overlay 不使用多播
- Overlay 网络中的容器处于一个虚拟的大二层网络中
- 关于 linux bridge + vxlan 组网,请参考 Neutron 理解(14):Neutron ML2 + Linux bridge + VxLAN 组网
- 关于 linux network namspace + NAT 组网,请参考 Netruon 理解(11):使用 NAT 将 Linux network namespace 连接外网
- github 上代码在这里 https://github.com/docker/libnetwork/blob/master/drivers/overlay/
ov-000100-1de98 的初始情形:
root@docker1:/home/sammy# ip -d link show dev vx-000100-1de98 8: vx-000100-1de98: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master ov-000100-1de98 state UNKNOWN mode DEFAULT group default link/ether 22:3c:3f:8f:94:f6 brd ff:ff:ff:ff:ff:ff promiscuity 1 vxlan id 256 port 32768 61000 proxy l2miss l3miss ageing 300 root@docker1:/home/sammy# bridge fdb show dev vx-000100-1de98 22:3c:3f:8f:94:f6 vlan 0 permanent
这里很明显的一个问题是,vxlan dev vx-000100-1de98 的 fdb 表内容不全,导致从容器1 ping 容器2 不通。待选的解决方式不外乎下面几种:
- 使用一个中央数据库,它保存所有容器的 IP 地址和所在节点的 IP 地址的映射关系
- 使用多播
- 使用比如 BGP 的特殊协议来广告(advertise)容器的 IP 和所在节点的 IP 的映射关系
Docker 从某种程度上利用了第一种和第三种方式的组合,首先Docker 利用 consul 以及 etcd 这样的分布式 key/value 存储来保存IP地址映射关系,另一方面个Docker 节点也通过某种协议来直接广告映射关系。
为了测试,中间重启了 docker1 节点,发现 over1 容器无法启动,报错如下:
docker: Error response from daemon: network sandbox join failed: could not get network sandbox (oper true): failed get network namespace "": no such file or directory.
根据 https://github.com/docker/docker/issues/25215,这是 Docker 的一个bug,fix 刚刚推出。一个 workaround 是重新创建 overlay network。
回到容器之间无法ping通对方的问题,尚不知道根本原因是什么(想吐槽Docker目前的问题真不少)。要使得互相 ping 能工作,至少必须具备下面的条件:
在 docker1 上,
- 为 vxlan dev 添加一条 fdb entry:02:42:14:00:00:03 dst 192.168.1.20 self
- 在容器中添加一条 arp entry:ip netns exec over1 arp -s 20.0.0.3 02:42:14:00:00:03
在 docker 2 上,
- 为 vxlan dev 添加一条 fdb entry:02:42:14:00:00:02 dst 192.168.1.21 self permanent
- 在容器中添加一条 arp entry:ip netns exec over4 arp -s 20.0.0.2 02:42:14:00:00:02
3. 网络性能对比
3.1 在我的测试环境中的数据
使用 iperf 工具检查测试了一下性能并做对比:
| 类型 | TCP | UDP |
| Overlay 网络中的两个容器之间 (A) | 913 Mbits/sec | 1.05 Mbits/sec |
| Bridge/NAT 网络中的两个容器之间 (B) | 1.73 Gbits/sec | |
| 主机间 (C) | 2.06 Gbits/sec | 1.05 Mbits/sec |
| 主机到另一个主机上的 bridge 网络模式的容器 (D) | 1.88 Gbits/sec | |
| 主机到本主机上的容器 (E) | 20.5 Gbits/sec | |
| 主机到另一个主机上的 host 网络模式的容器 (F) | 2.02 Gbits/sec | 1.05 Mbits/sec |
| 容器 Overlay 效率 (A/C) | 44% | 100% ? |
| 单个 NAT 效率 (D/C) | 91% | |
| 两个 NAT 效率 (B/C) | 83% | |
| Host 网络模式效率 (F/C) | 98% | 100% |
两台主机是同一个物理机上的两个虚机,因此,结果的绝对值其实没多少意义,相对值有一定的参考性。
3.2 网上文章中的对比数据
文章 Testing Docker multi-host network performance 对比了多种网络模式下的性能,结果如下:

看起来这个表里面的数据和我的表里面的数据差不了太多。
3.3 关于Docker 网络模式选择的简单结论
- Bridge 模式的性能损耗大概为10%
- 原生 overlay 模式的性能损耗非常高,甚至达到了 56%,因此,在生产环境下使用这种模式需要非常谨慎。
- 如果一定要使用 overlay 模式的话,可以考虑使用 Cisco 发起的 Calico 模式,它的性能和 bridge 相当。
- Weave overlay 模式的性能数据非常可疑,按理说应该不可能这么差。
参考链接:
- http://kangkai.net.cn/etcd-cluster-guide/
- https://www.singlestoneconsulting.com/~/media/files/whitepapers/dockernetworking2.pdf


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端